Apache Flink 从流处理基础到恰好一次语义
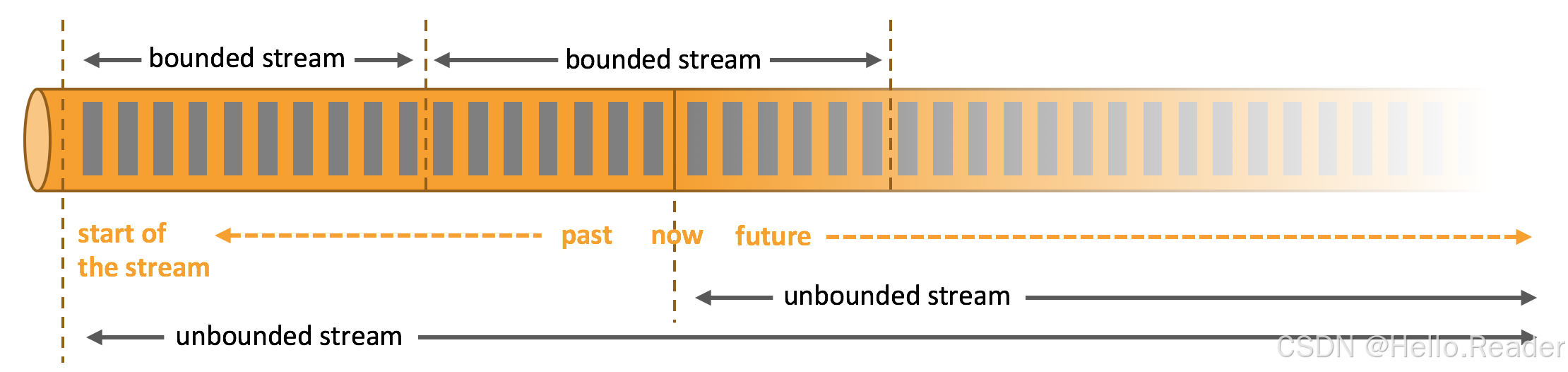
1. 为什么是流:有界 vs 无界
- 批处理(有界):数据“先到齐,再处理”。你能做全量排序、全局统计和“最终报告”。
- 流处理(无界):数据“永不停止”,必须边到边算。
- 现实世界的数据(点击、交易、传感器)天生是流。能统一跑实时与回放(重处理历史)且产出一致结果,是现代数据系统的关键诉求。
在 Flink 中,一切皆是流式数据流(streaming dataflow):从一个或多个 Source 流入,经一系列 Operator 转换,流向一个或多个 Sink。
2. Flink 程序模型与数据流图
一个 Flink 作业可视为有向图:节点是算子(map/filter/keyBy/window/process),边是数据流。常见来源/去向:
- Source:Kafka、Kinesis、文件、数据库 CDC、对象存储等
- Sink:Kafka、Elastic、Iceberg/Hudi、JDBC、Data Warehouse、OLAP 引擎等
示意(Mermaid):
实践中,程序中的“一个转换”可能会在运行时被优化为“多个算子”。
3. 并行与数据重分发:one-to-one vs redistributing
-
并行度(parallelism):同一算子可有 N 个子任务(subtask),各自独立、不同线程/机器运行。
-
one-to-one:保序、分区不变(如
Source -> map())。 -
redistributing:改变分区/路由(如
keyBy()按 Key 哈希分发,rebalance()随机打散,broadcast()广播)。- 注意:重分发后,仅发送子任务与接收子任务这一对之间的相对顺序被保留;跨 Key 的全局顺序不可保证。
4. 事件时间与水位线:让“时间”说了算
-
处理时间(Processing Time):算子机器的时钟。简单但不稳定。
-
事件时间(Event Time):事件本身携带的时间戳。可按真实发生顺序计算,适合乱序、重放场景。
-
水位线(Watermark):系统对“截至某时刻,应该已经看到所有早于它的事件”的一种进度宣告。
- 常见策略:有界乱序(允许最大延迟,如 5s),或基于观测的 自适应 策略。
要点:用事件时间 + 合理水位线,才能在“实时 + 历史重放”两种模式下得到一致、可复算的结果。
5. 有状态流处理:本地状态、KeyBy 与算子并行实例
- Flink 的很多算子是有状态的:当前事件的处理依赖于之前所有事件的累积影响。
keyBy()将同一 Key 的事件路由到同一并行子任务,从而让每个子任务维护“自己那份 Key 的本地状态”。- 本地状态(JVM 堆或托管到 RocksDB 等持久化结构)带来高吞吐、低延迟。
- 从系统视角看,有状态算子的并行实例集合,像一个分片的 KV 存储。
6. 容错与恰好一次:检查点与回放
-
检查点(Checkpoint):周期性、异步地捕获作业全局状态(包含 Source 的偏移和各算子本地状态)。
-
失败恢复:从最近检查点恢复状态,同时让 Source 回退到检查点时的偏移,继续处理。
-
Exactly-Once 语义:对状态更新与Source 偏移的一致快照 + 对 Sink 的幂等/两阶段提交支持,可实现“计算端恰好一次”。
- 端到端 Exactly-Once 还取决于外部系统的事务/幂等等支持(如 Kafka 事务写、支持两阶段提交的 JDBC/文件写入等)。
示意(Mermaid):
7. 实战一:实时订单统计(Java DataStream)
场景:从 Kafka 消费订单事件,按用户
userId的事件时间做滚动窗口汇总(1 分钟订单数与金额),同时打开检查点实现容错与“恰好一次”。
依赖(Maven 核心):
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version>
</dependency>
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>${flink.version}</version>
</dependency>
示例代码(精简版):
import org.apache.flink.api.common.eventtime.*;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.time.Duration;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.runtime.state.hashmap.HashMapStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.*;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;public class OrdersJob {public static void main(String[] args) throws Exception {final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 1) 开启检查点(每 10s,一次性语义)env.enableCheckpointing(10_000, CheckpointingMode.EXACTLY_ONCE);env.getCheckpointConfig().setMinPauseBetweenCheckpoints(5_000);env.setStateBackend(new HashMapStateBackend());env.getCheckpointConfig().setCheckpointStorage("file:///tmp/flink-ckpt"); // 示例:本地存储// 2) Kafka SourceKafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers("localhost:9092").setTopics("orders").setGroupId("orders-consumer").setStartingOffsets(OffsetsInitializer.latest()).setValueOnlyDeserializer(new SimpleStringSchema()).build();DataStream<String> raw = env.fromSource(source, WatermarkStrategy.noWatermarks(), "kafka-orders");// 3) 解析 JSON 并抽取事件时间(假设字段 ts 为毫秒)DataStream<Order> orders = raw.map(Order::fromJson) // 自行实现:String -> Order(userId, amount, ts).assignTimestampsAndWatermarks(WatermarkStrategy.<Order>forBoundedOutOfOrderness(Duration.ofSeconds(5)).withTimestampAssigner((e, ts) -> e.ts));// 4) 按 userId 做 1 分钟滚动窗口统计DataStream<UserAgg> result = orders.keyBy(o -> o.userId).window(TumblingEventTimeWindows.of(Time.minutes(1))).reduce((a, b) -> new Order(a.userId, a.amount + b.amount, Math.max(a.ts, b.ts)),(key, window, it, out) -> {Order agg = it.iterator().next();out.collect(new UserAgg(key.getKey(), window.getStart(), window.getEnd(), 1, agg.amount));});// 5) Sink(示例打印;生产环境请用支持事务/幂等的 Sink)result.print();env.execute("orders-1min-aggregation");}static class Order {public String userId;public double amount;public long ts;static Order fromJson(String s) { /* TODO: 解析实现 */ return null; }public Order() {}public Order(String userId, double amount, long ts) {this.userId = userId; this.amount = amount; this.ts = ts;}}static class UserAgg {public String userId;public long windowStart;public long windowEnd;public long cnt;public double amount;public UserAgg(String userId, long ws, long we, long cnt, double amount) {this.userId = userId; this.windowStart = ws; this.windowEnd = we; this.cnt = cnt; this.amount = amount;}@Override public String toString() {return String.format("user=%s, win=[%d,%d), cnt=%d, amount=%.2f",userId, windowStart, windowEnd, cnt, amount);}}
}
要点回顾
- 事件时间 + 有界乱序 5s 水位线。
keyBy(userId)将同一用户的事件路由到同一子任务,窗口聚合依赖本地状态。- 打开 EXACTLY_ONCE 检查点;生产环境搭配事务性 Sink获得端到端“恰好一次”。
8. 实战二:Flink SQL 统计 10 分钟 UV
场景:统计近 10 分钟的去重访客数(UV),按事件时间滑动。
-- 1) 定义 Kafka 源(简化示意)
CREATE TABLE page_view (user_id STRING,url STRING,ts BIGINT,WATERMARK FOR ts_rowtime AS ts_rowtime - INTERVAL '5' SECOND
) WITH ('connector' = 'kafka','topic' = 'pv','properties.bootstrap.servers' = 'localhost:9092','format' = 'json','scan.startup.mode' = 'latest-offset'
);-- 2) 计算 10 分钟滑动 UV,每 1 分钟出一次结果
SELECTwindow_start,window_end,COUNT(DISTINCT user_id) AS uv
FROM TABLE(TUMBLE(TABLE page_view, DESCRIPTOR(ts_rowtime), INTERVAL '10' MINUTES)
)
GROUP BY window_start, window_end;
说明
- 通过
WATERMARK声明事件时间列,设定乱序容忍度。 - 使用窗口 TVF 进行聚合,语义清晰、易于维护。
9. 常见坑与最佳实践清单
-
端到端 Exactly-Once ≠ 仅开启检查点
- Source 偏移 + 算子状态 + Sink 写入三者需要原子一致。选择支持两阶段提交/事务/幂等的 Sink(如 Kafka 事务、支持 XA/2PC 的 JDBC Sink、文件写入的临时+原子 rename 策略等)。
-
水位线过于保守或激进
- 过小:容忍不了真实乱序,导致早关窗、丢失迟到数据;过大:延迟增大、状态胀大。基于数据分布观测合理设置。
-
Key 倏地倾斜
- 热 Key 导致单个子任务背压。方案:拆分热 Key、基于“二级 Key + 后聚合”的 Key 拆分(salting),或使用分层聚合。
-
状态体量不可控
- 定期 TTL、合理的窗口策略、布隆过滤/近似去重结构、外部维表缓存策略;必要时选择 RocksDB 状态后端并调优。
-
反压与资源
- 监控背压链路、合理设置并行度与重分发策略;Source 拉取速率、Sink 刷写批次、网络缓冲都影响端到端吞吐。
-
历史重放一致性
- 必须使用事件时间语义 + 稳定的水位线策略;避免处理时间驱动的逻辑影响可复算性。
10. 进一步学习与参考路线
-
优先打牢四件事:事件时间、水位线、有状态算子、检查点。
-
实践优先:先跑通一个 Kafka→Flink→Sink 的端到端流水线,再逐步引入窗口、状态与容错。
-
升级路径:
- 单流 ETL/聚合 →
- 多流 Join/会话窗口 →
- 事务性 Sink 与端到端恰好一次 →
- 复杂事件驱动(ProcessFunction/CEP)与侧输出流 →
- 生产级部署(资源隔离、HA、监控告警、滚动升级、Savepoint 运维)。