深入解析HashMap:从原理到实践的全方位指南
目录
一、核心概念:什么是HashMap?
核心特性:
二、底层实现原理:数组+链表+红黑树
1. JDK 1.7及之前:数组 + 链表
2. JDK 1.8及之后:数组 + 链表 + 红黑树(重要优化!)
三、关键操作源码级分析
1. PUT操作流程(JDK 8+)
2. GET操作流程
3. RESIZE扩容机制
四、核心参数与影响
五、经典问题与最佳实践
1. 为什么容量总是2的幂次方?
2. HashMap为什么是线程不安全的?
3. 如何正确使用HashMap?
HashMap是Java集合框架中最核心的类之一,它提供了基于键值对(Key-Value)的高效数据存储和检索。本文将带你从入门到精通,全面剖析HashMap的设计哲学、实现原理和最佳实践。
一、核心概念:什么是HashMap?
HashMap实现了Map接口,基于哈希表结构实现。它允许使用null作为键或值,并且不保证元素的顺序(特别是,它不保证顺序会随时间保持不变)。
核心特性:
-
键值对存储:存储的数据单位是键值对(Entry/K-V Node)。
-
快速访问:通过键(Key)可以快速定位到对应的值(Value),理想情况下时间复杂度为O(1)。
-
非线程安全:多个线程同时修改HashMap可能导致数据不一致,必要时需使用
Collections.synchronizedMap或ConcurrentHashMap。
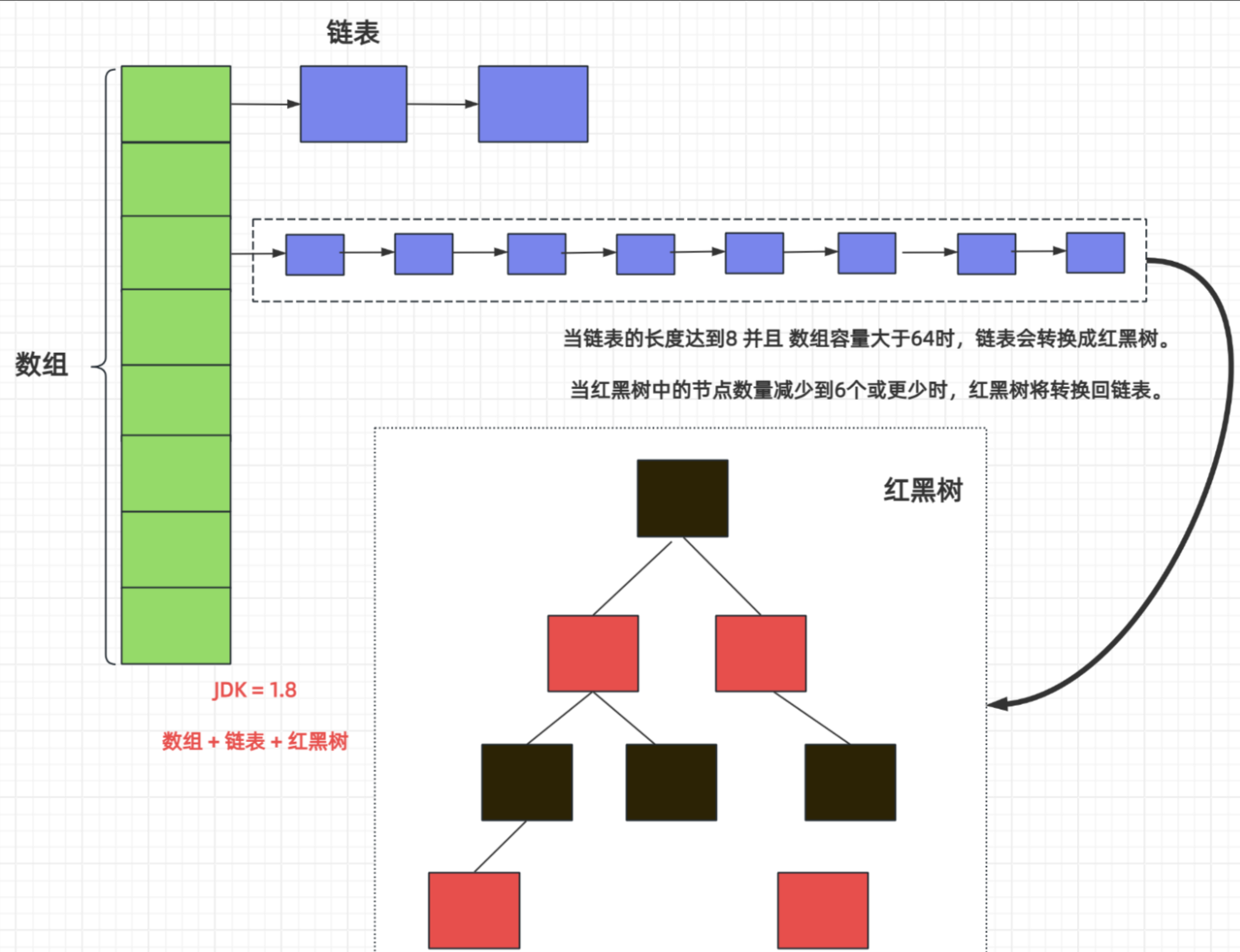
二、底层实现原理:数组+链表+红黑树
HashMap的卓越性能来源于其精妙的底层数据结构设计,其演进也体现了Java对性能的不懈追求。
1. JDK 1.7及之前:数组 + 链表
-
数组(Bucket):HashMap内部维护一个
Node<K,V>[] table数组。数组的每个位置被称为一个"桶"(Bucket)或"槽"(Slot)。 -
哈希函数:当插入一个键值对时,首先调用键的
hashCode()方法,再通过扰动函数(防止质量差的哈希码冲突)计算出一个哈希值。 -
确定桶位:通过
(n - 1) & hash(n为数组长度)计算出键值对应放入的数组下标。 -
链表(解决哈希冲突):不同的键可能计算出相同的数组下标,这种现象称为哈希冲突。HashMap采用链地址法解决冲突:将发生冲突的键值对组成一个单向链表,存储在同一个数组桶中。
2. JDK 1.8及之后:数组 + 链表 + 红黑树(重要优化!)
JDK 8对HashMap进行了重大优化,核心是引入红黑树。
-
优化动机:在极端情况下(如所有键的哈希值都冲突),链表会变得非常长,此时查询性能会退化为O(n)。
-
树化条件:当链表的长度超过阈值(默认为8) 且当前数组的长度大于等于64时,该桶位的链表会自动转换为红黑树。
-
优势:红黑树的查询时间复杂度为O(log n),即使发生大量哈希冲突,也能保持良好的查询性能。
-
退化条件:当树中的节点数由于删除或扩容小于等于6时,红黑树会退化为链表。
三、关键操作源码级分析
1. PUT操作流程(JDK 8+)
-
计算哈希:调用
key.hashCode(),并经过高16位异或低16位的扰动计算,得到最终哈希值。扰动目的是让哈希的高位也参与运算,减少哈希冲突。 -
初始化表:如果数组
table为null或长度为0,则调用resize()方法进行初始化(懒加载)。 -
定位桶位:通过
(n - 1) & hash计算下标i。 -
插入节点:
-
情况1:桶
i为空,直接新建Node节点放入。 -
情况2:桶
i不为空,判断第一个节点的key是否与待插入key相同。-
相同则覆盖value。
-
不同则遍历:
-
如果是树节点,调用红黑树的
putTreeVal方法插入。 -
如果是链表,则遍历到尾端插入,并判断链表长度是否≥8,是则调用
treeifyBin尝试树化。
-
-
-
-
判断扩容:插入成功后,判断size是否超过
threshold(容量*负载因子),超过则调用resize()扩容。
2. GET操作流程
-
计算key的哈希值(同样的扰动函数)。
-
通过
(n - 1) & hash定位到数组下标。 -
检查该桶位的第一个节点:
-
若key匹配,直接返回。
-
若不匹配,则根据该节点是树节点还是链表节点,调用
getTreeNode或遍历链表查找。
-
3. RESIZE扩容机制
扩容是HashMap性能的关键点之一。
-
触发条件:当
size > threshold(容量 * 负载因子)时触发。 -
过程:
-
创建一个新的数组,其容量是原来的两倍(保持2的幂次方)。
-
遍历旧数组的每一个桶位,将节点重新哈希到新数组中。
-
JDK 8优化:由于新数组长度是2次幂,节点在新数组的位置要么是原位置
i,要么是i + oldCap。这个优化避免了重新计算哈希,大大提升了扩容效率。
-
四、核心参数与影响
-
初始容量(Initial Capacity):默认16。创建HashMap时可指定,如果预先知道数据量,应设置合适的初始容量以避免多次扩容。
-
负载因子(Load Factor):默认0.75。决定了HashMap在多少满时进行扩容。0.75是时间(查询性能)和空间(数组利用率)的一个折中权衡。值越小,空间开销越大,但哈希冲突概率低;值越大,空间利用率高,但冲突概率增加。
-
扩容阈值(Threshold):
容量 * 负载因子。当size超过此值时触发扩容。
五、经典问题与最佳实践
1. 为什么容量总是2的幂次方?
为了高效计算桶下标和优化扩容过程。(n - 1) & hash 等价于 hash % n,但位运算的效率远高于取模运算。同时,扩容时节点的新位置可以通过位运算快速确定。
2. HashMap为什么是线程不安全的?
-
场景1:PUT导致数据覆盖。两个线程同时执行PUT,且计算出的桶位相同,可能发生后一个操作覆盖前一个操作的结果。
-
场景2:JDK 7下扩容导致死循环。扩容时采用头插法转移链表,多线程并发扩容可能导致链表形成环,后续GET操作遍历链表时出现无限循环。JDK 8已改为尾插法,解决了死循环问题,但数据覆盖问题依然存在。
3. 如何正确使用HashMap?
-
设置合适的初始容量:避免频繁扩容。例如,预计存储1000个元素,可设置
new HashMap<>(2048)(1000/0.75≈1333,取最近的2的幂次2048)。 -
使用不可变对象作为Key:如String、Integer。如果Key的对象 hashCode() 依赖于可变字段,修改后会导致无法再次找到该键值对,造成内存泄漏。
-
在高并发场景使用ConcurrentHashMap:切勿在多线程环境中直接使用HashMap。