小杰机器学习(five)——PyTorch、Tensor(torch库)、Tensor的基本属性、连续性、张量、随机树种子(seed)。
1. PyTorch是什么?
PyTorch是一个开源的深度学习框架,由Meta公司(原名:Facebook)的人工智能团队开发和维护。它提供了一个灵活、动态的计算图计算模型,使得在深度学习领域进行实验和开发变得更加简单和直观。
pytorch网址
PyTorch documentation — PyTorch 2.8 documentation

2. PyTorch的特点
- 动态计算图
PyTorch使用动态计算图,这意味着计算图在运行时构建的,而不是在编译时静态定义的。
- 自动求导(微分)
PyTorch提供了自动求导机制,称为Autograd。它能够自动计算张量(Tensor)的梯度,这对于训练神经网络和其他深度学习模型非常有用。
- 丰富的神经网络库
PyTorch 提供了丰富的神经网络库,包括各种各样的层,损失函数、优化器等。这些库使得构建和训练神经网络变得更加容易。
- 支持GPU加速
PyTorch 充分利用了GPU的并行计算能力,能够在GPU上高效地进行计算,加速模型训练过程。
3. Tensor是什么?
tensor是一种多维数组,类似于NumPy的ndarray。它是Pytorch中最基本的数据结构,用于存储和操作数据。
tensor可以是标量、向量、矩阵或者更高维度的数组,可以包含整数、浮点数或者其他数据类型的元素。
PyTorch的Tensor和NumPy的ndarray非常相似,但在设计和功能上有一些不同之处。主要的区别包括:GPU加速、自动求导、动态计算图。

4. 安装
手动安装:
pip install torch==2.5.1 -i https://pypi.tuna.tsinghua.edu.cn/simpleimport torch# 标量
scalar_tensor = torch.tensor(4.14)
print(scalar_tensor)# 向量
vec_tensor = torch.tensor([1, 2, 4, 5, 6])
print(vec_tensor)# 矩阵
mat_tensor = torch.tensor([[1, 2],[3, 4]])
print(mat_tensor)5. Tensor的存储机制
(1) tensor
在PyTorch中,tensor包含了两个部分,即Storage和metadata。
Storage(存储):
存储是tensor中包含的实际的底层缓冲区,它是一维数组,存储了tensor的元素值。不同tensor可能共享相同的存储,即使它们具有不同的形状和步幅。存储是一块连续的内存区域,实际上存储了tensor中的数据。
Metadata(元数据):
元数据是tensor的描述性信息,包括tensor的形状、数据类型、步幅、存储偏移量、设备等。元数据提供了关于tensor的结构和属性信息,但并不包括tensor中的实际数据。元数据允许PyTorch知道如何正确地解释存储中的数据以及如何访问它们。

import torch# 标量
scalar_tensor = torch.tensor(4.14)
print(scalar_tensor)# 向量
vec_tensor = torch.tensor([1, 2, 4, 5, 6])
print(vec_tensor)# 矩阵
mat_tensor = torch.tensor([[1, 2],[3, 4]])
mat_tensor = torch.tensor([[1.0, 2],[3, 4]])
print(mat_tensor)
print(mat_tensor.shape) # torch.Size([2, 2])
print(mat_tensor.dtype) # torch.float32# 存储的内容,未来版本会更加底层和抽象
print(mat_tensor.storage())
# 取出一维数据
print(mat_tensor.storage().tolist())
# 偏移量
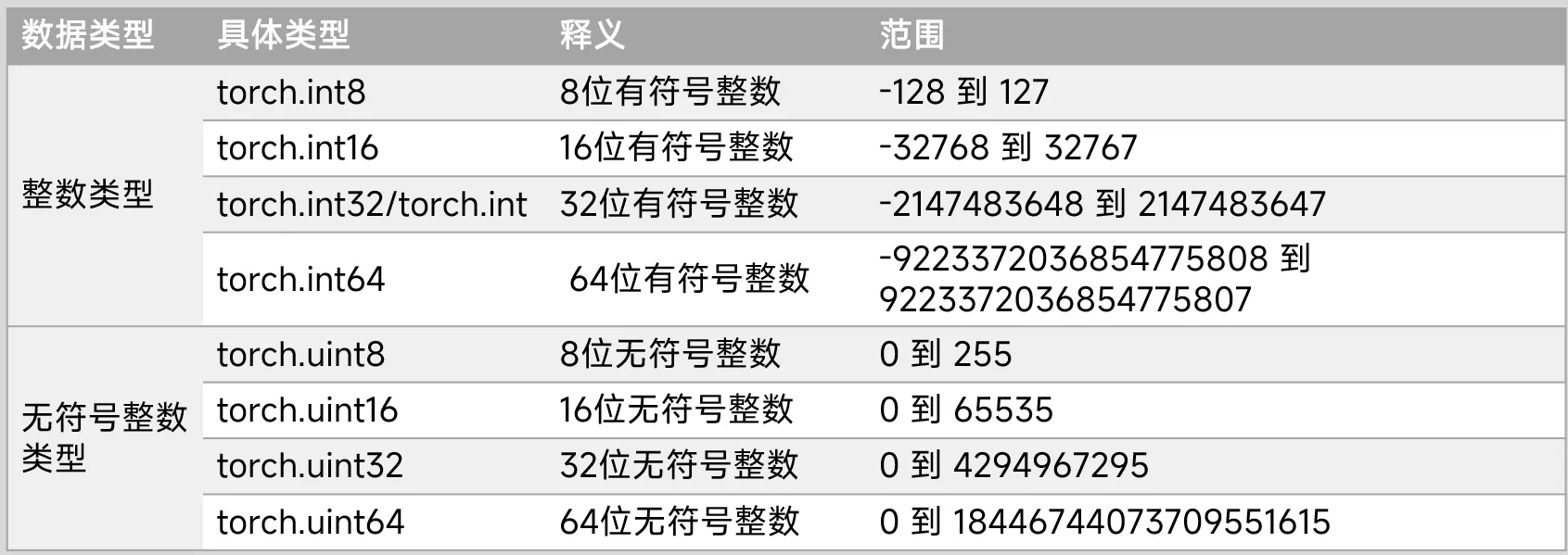
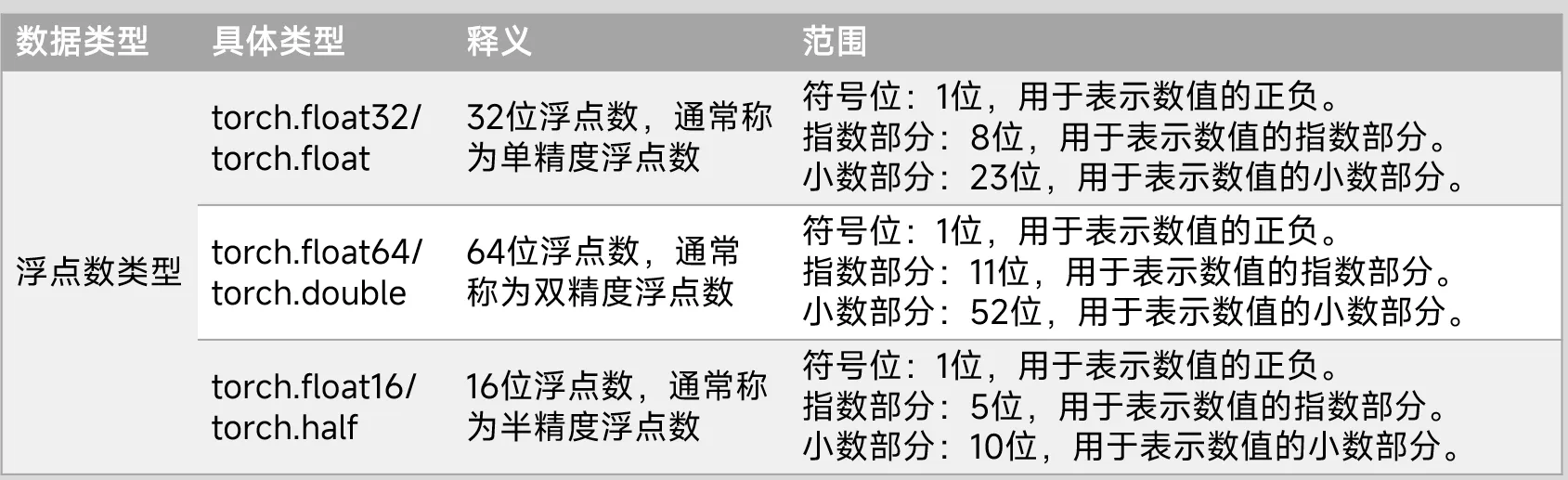
print(mat_tensor.storage_offset())(2) 数据类型dtype
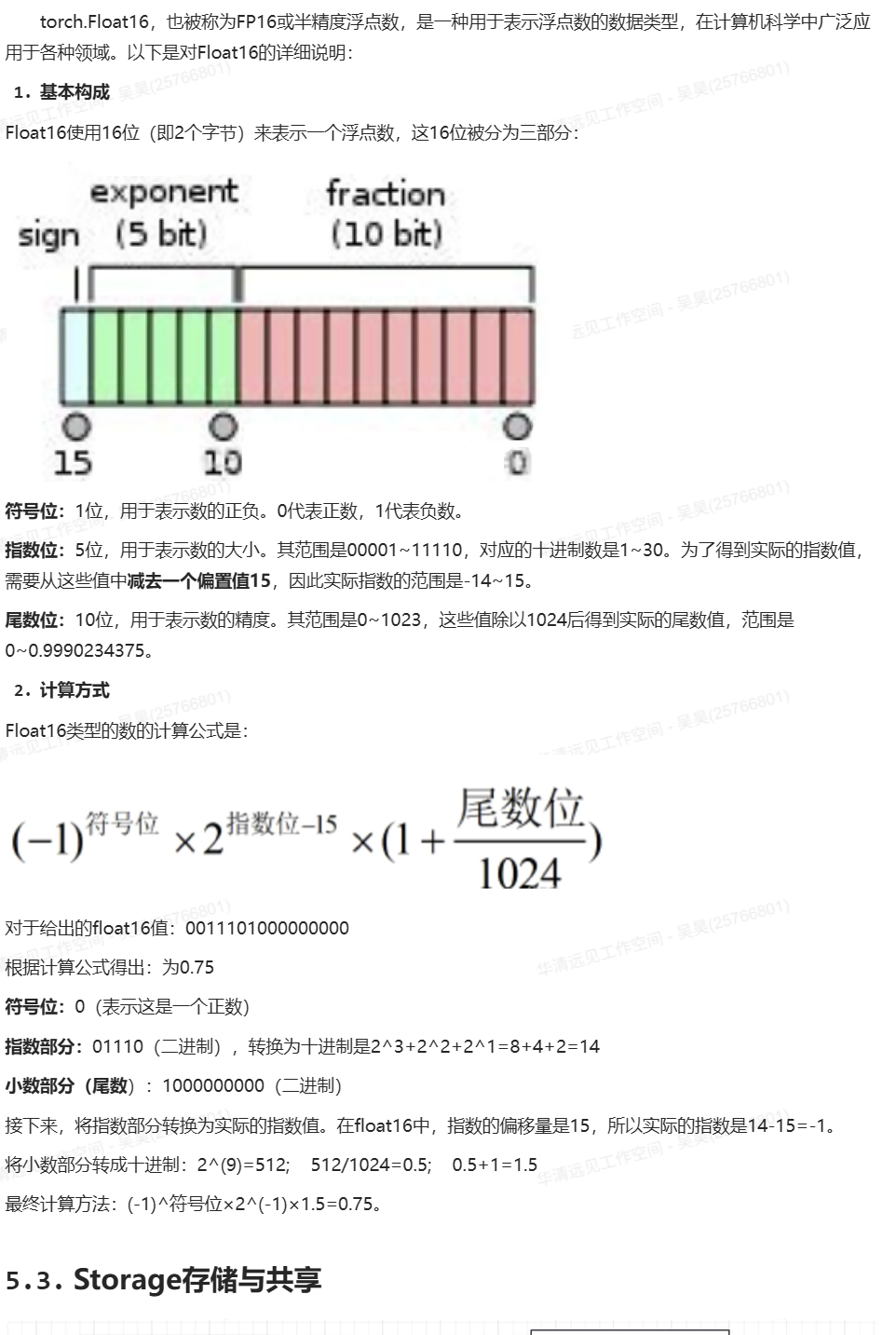
课外阅读:
(3) 存储与共享Storage
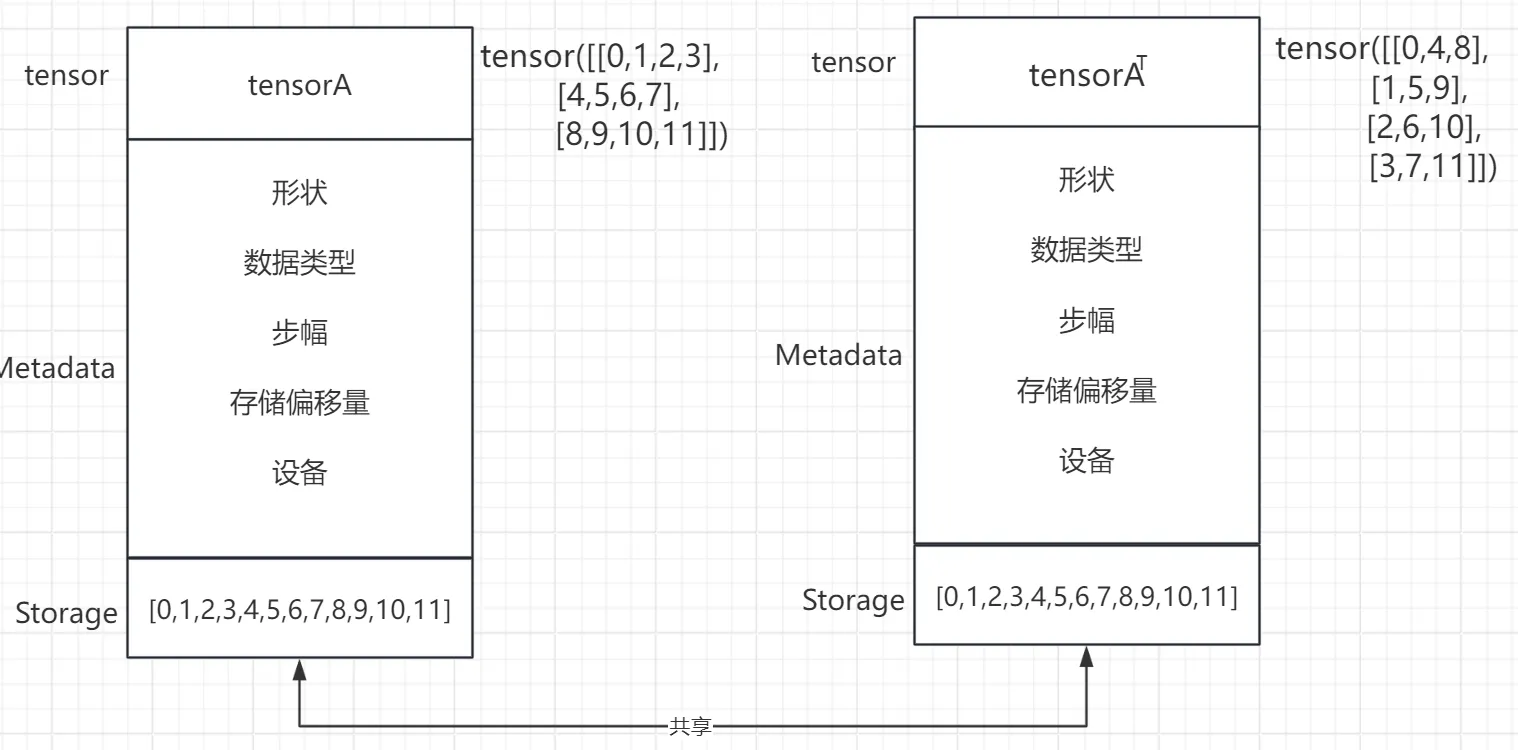
对张量进行操作时(比如使用view而非reshape调整形状,转置等),它不会创建一个新的张量,而是返回一个指向相同数据的视图。即PyTorch通常会共享相同的存储对象,以节省内存和提高效率。
import torch# 先创建了一个tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
# 再变形为3*4
tensorA = torch.arange(12).reshape(3, 4)
print(tensorA)# 查看tensorA的Storage
print(tensorA.storage().tolist())
# 查看tensorA的Storage的存储地址
print(tensorA.storage().data_ptr()) # 地址1# 转置tensorA:把第一维和第二维做转置
tensorA_T = tensorA.transpose(0, # 第一维1 # 第二维
)print(tensorA_T)
# 查看tensorA_T的Storage
print(tensorA_T.storage().tolist())
# 查看tensorA的Storage的存储地址
print(tensorA_T.storage().data_ptr()) # 地址1Storage存储的具体过程
在PyTorch中,张量的存储是通过torch.Storage类来管理的。张量的值被分配在连续的内存块中,这些内存块中,这些内存块是大小可变的一维数组,可以包含不同类型的数据,如float或int32。
具体来说,当我们创建一个张量时,PyTorch会根据我们提供的数据和指定的数据类型来分配一块连续的内存空间。这块内存空间由torch.Storage对象管理,而张量本身则提供了一种视图,让我们可以通过索引来访问这些数据。
此外,PyTorch还提供了一系列的函数和方法来操作张量,包括改变形状,获取元素、拼接和拆分等。这些操作通常不会改变底层的存储,而是返回一个新的张量视图,这个视图指向相同的数据但是可能有不同的形状或索引方式。
总的来说,张量的存储实现是PyTorch能够高效进行张量运算的关键。通过管理一块连续的内存空间,并提供了丰富的操作方法,使得用户可以方便地对多维数组进行各种计算和变换。
(4) 步长stride
步长指的是在每个维度上移动一个元素时在底层存储中需要跨越的元素数。
import torch# 先创建了一个tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
# 再变形为3*4
tensorA = torch.arange(12).reshape(3, 4)
print(tensorA)
print(tensorA.stride()) # (4, 1)上面程序的运行结果如下
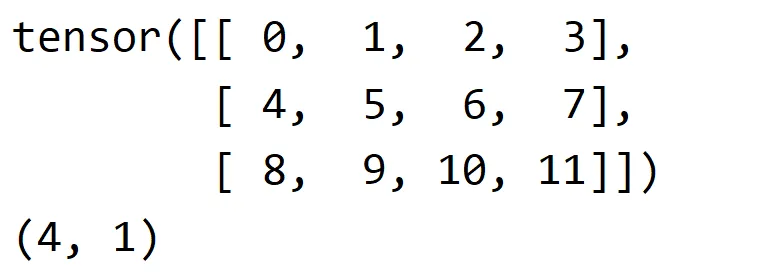
第一个数字4表示矩阵的行(第一个维度)上移动一个元素时需要跨越的存储单元数。因为矩阵的每行包含4个元素,所以每次沿着行移动一个元素需要跨越4个存储单元。
第二个数字1表示在矩阵的列(第二个维度)上移动一个元素时需要跨越的存储单元数,因为矩阵的列数是1,所以在列上移动一个元素时只需要跨越一个存储单元。在PyTorch中,列的步长始终为1,这也符合绝大多数编程语言和框架的设计,这种存储方式使得在列方向上的访问非常高效,因为不需要跳过任何元素。这也是为什么在处理二维数组时,列操作通常比行操作更快的原因之一。
(5)偏移offset
偏移是指从张量的第一个元素开始的索引位置。
import torch# 先创建了一个tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
# 再变形为3*4
tensorA = torch.arange(12).reshape(3, 4)
print(tensorA)# 选取第2行到第3行、第1列到第2列的元素,得到一个新的张量B
tensorB = tensorA[1:3, 0:2]
print(tensorB)
print(tensorB.storage_offset()) # 偏移4(6)连续性
Tensor的连续性指的是其元素在内存中按照其在张量中的顺序紧密存储,没有间隔。
import torch# 先创建了一个tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
# 再变形为3*4
tensorA = torch.arange(12).reshape(3, 4)
print(tensorA)
print(tensorA.flatten()) # 展平
print(tensorA.storage().tolist())
print(tensorA.is_contiguous()) # 是否连续:True tensor也可以不连续存储,当对Tensor进行某些操作,如转置(transpose)时,可能会导致Tensor变得不连续。
import torch# 先创建了一个tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
# 再变形为3*4
tensorA = torch.arange(12).reshape(3, 4)
tensorA = tensorA.transpose(0, 1)
print(tensorA)
print(tensorA.flatten()) # 展平
print(tensorA.storage().tolist())
print(tensorA.is_contiguous()) # 是否连续:False连续的tensor优势
高效的内存访问:
连续的张量在内存中占用一块连续的空间,这使得CPU可以高效地按顺序访问数据,减少了内存寻址的时间,从而提高了数据处理的速度。
优化的计算性能:
在进行数学运算时,连续张量可以减少数据的移动和复制,因为数据已经按照计算所需的顺序排序排列,这样可以减少计算中的延迟,提高整体的计算性能。
其它:
在不连续的tensor上进行view()操作会报错,view()可以手动创建视图,以便于内存重用。
import torch# 先创建了一个tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
# 再变形为3*4
tensorA = torch.arange(12).reshape(3, 4)
tensorA = tensorA.transpose(0, 1)
print(tensorA)
print(tensorA.flatten()) # 展平
print(tensorA.storage().tolist())
print(tensorA.is_contiguous()) # 是否连续:False# 报错!!!!!
# viewA = tensorA.view(1, 12) # 变成1行12列使用视图重用内存
# print(viewA)可以强行转换为连续存储。
import torch# 先创建了一个tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
# 再变形为3*4
tensorA = torch.arange(12).reshape(3, 4)
tensorA = tensorA.transpose(0, 1)
# 强行转换成连续
tensorA = tensorA.contiguous()
print(tensorA)
print(tensorA.flatten()) # 展平
print(tensorA.storage().tolist())
print(tensorA.is_contiguous()) # 是否连续:TrueviewA = tensorA.view(1, 12) # 变成1行12列使用视图重用内存
print(viewA)结论:
- 通过contiguous()方法将不连续的张量转换为连续的张量。
- 如果tensor不是连续的,则会重新开辟一块内存空间保证数据是在内存中是连续的。
- 如果tensor是连续的,则contiguous()无操作
- view的性能比reshape好,如果没有性能瓶颈可以选择reshape,因为reshape不需要关注是否连续
6. 随机数种子
此代码有助于后续模型的一些复现,非常有用的小技巧。
import torchrandom_tensor = torch.rand((3, 4))
print(random_tensor)
"""
每次运行结果都不一样
tensor([[0.2924, 0.1941, 0.9465, 0.3363],[0.7984, 0.0809, 0.2171, 0.1827],[0.4552, 0.6414, 0.7593, 0.0330]])tensor([[0.0634, 0.4717, 0.2550, 0.8508],[0.4667, 0.5600, 0.5351, 0.7288],[0.7948, 0.8702, 0.3767, 0.4568]])
"""# 种下一颗种子
seed = 8
torch.manual_seed(seed) # 播种
random_tensor = torch.rand((3, 4))
print(random_tensor)
"""
播种后,每次随机都一样
tensor([[0.5979, 0.8453, 0.9464, 0.2965],[0.5138, 0.6443, 0.8991, 0.0141],[0.5785, 0.1218, 0.9181, 0.6805]])tensor([[0.5979, 0.8453, 0.9464, 0.2965],[0.5138, 0.6443, 0.8991, 0.0141],[0.5785, 0.1218, 0.9181, 0.6805]])
"""