解决推理能力瓶颈,用因果推理提升LLM智能决策
从ChatGPT到现在的智能体AI这个跨越说明了一个关键转变。ChatGPT本质上是个聊天机器人,生成文本回应;而AI智能体能够自主完成复杂任务——销售、旅行规划、航班预订、找装修师傅、点外卖,这些都在它的能力范围内。
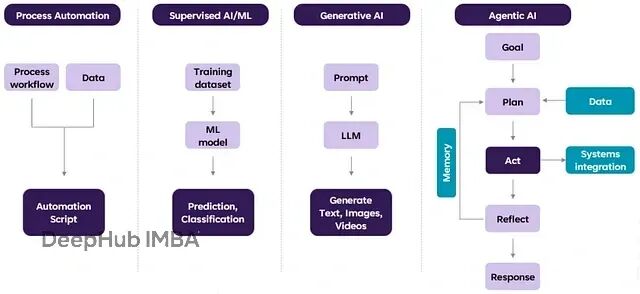
目前我们解决用户任务时,主要是让大语言模型(LLM)做任务分解,这也是和生成式AI重叠的地方。但问题就出在这里:
今天的智能体AI系统被LLM的推理能力限制住了——这个问题在苹果的两篇论文1、2里讨论得很深入。
核心问题来自智能体AI系统的非确定性特征。看看下面这个电商场景:
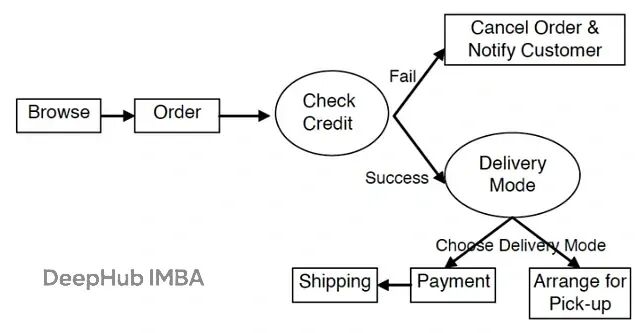
执行计划里有两个非确定性操作:“检查信用"和"配送模式”。配送模式意味着用户既可以自提也可以送货上门,所以配送这个任务可能根本不会执行。这种非确定性带来一个问题:
我们需要一个多步推理模型来理解底层智能体组件之间的因果关系。
这里涉及一个经典问题:相关性不等于因果关系。不管LLM规模多大,它们本质上只能抓住训练数据中特征之间的统计相关性,然后做预测。因果关系虽然暗示相关性,但这种影响可能微弱到可以忽略。
当前LLM缺少的正是因果关系理解。
接下来我们看看如何通过因果关系和内省来解决智能体工作流中的非确定性问题,前者用于LLM训练阶段,后者用于推理阶段。
因果推理的作用机制
因果关系研究的是事物"为什么"发生。它能够规范性地解释为什么某些行动比其他行动效果更好,从而影响未来结果。正如亚里士多德说的:“如果你证明了原因,你就立即证明了结果;反之,没有任何事物可以在没有其原因的情况下存在。”
人类天生具有因果思维。我们依靠因果关系做决策、制定计划、解释行为、适应变化,基本上所有决策都是基于对后果的考量。
Gartner在2024年AI技术成熟度曲线中把因果AI放在"创新触发"阶段,分析师的评价是:
因果AI识别并利用因果关系,超越基于相关性的预测模型,让AI系统能够更有效地给出行动建议并更自主地执行。当我们需要更稳健的预测能力,以及更精准地确定影响特定结果的最佳行动时,因果AI就显得至关重要。
因果AI能够影响智能体AI生命周期的多个环节,特别是推理、可观察性和可解释性这几个方面。
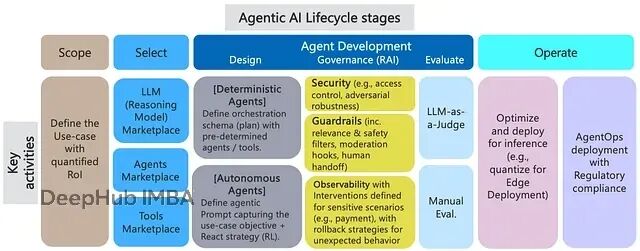
LLM推理能力的现实困境
苹果最近的研究(论文1)深入分析了LLM的推理局限性。研究发现,当面对以下情况时,最先进的LLM准确率会显著下降:同一问题的不同表述版本、包含多个条件的复杂问题、以及看起来相关但实际无关的干扰信息。
这些限制导致准确率下降高达65%,主要是因为模型难以分辨相关信息和处理复杂问题。
另一篇论文2进一步揭示,前沿的大型推理模型(LRM)在问题复杂度超过某个阈值时会出现准确率完全崩溃。更反直觉的是,这些模型表现出奇怪的扩展限制:推理努力程度会随问题复杂度增加到某个点,然后即使token预算充足也会下降。就算提供明确的人类输入(实际解决方案描述或算法),在这个阶段也无济于事。
这些发现暴露了依赖LLM解决问题的风险。LLM看起来无法进行真正的逻辑推理,只是在模仿训练数据中观察到的推理步骤。
要让AI真正具备推理和问题解决能力,它必须在算法层面理解因果关系。
换句话说,需要理解事物发生的动态机制,这样才能探索各种"假设"情况。这类似于人脑的新皮层功能,负责高阶推理,比如决策、规划和感知。
为了达到这个目标,我们建议在LLM/LRM的训练和微调过程中加入因果AI作为核心组件,同时结合知识图谱。
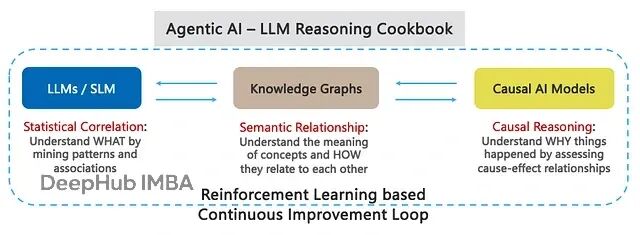
LLM推理——在LLM/LRM训练中提供WHAT、HOW和WHY成分
因果AI能够提供几个关键的推理组件:根本原因分析(检测和排序导致结果的因果驱动因素),假设场景和反事实分析(确定替代行动相对于当前状态的后果),可解释性(解释为什么某些行动比其他行动更优),混杂因子识别(找出无关、误导或隐藏的影响因素),以及路径分析(理解相互关联的行动和达成结果的行动序列)。
实现方式是将传统神经网络架构与因果推理技术结合,在神经网络内部推断因果路径。这意味着在训练数据集中建模因果关系,理解特征间的关系、相互影响方式以及对预测的作用。
举个例子,下面的图5展示了一个用于评估贷款申请信用风险的推断因果模型。红色箭头表示特征与信用度呈负相关,绿色箭头表示正面的因果驱动因素,箭头粗细代表因果关系的强度。
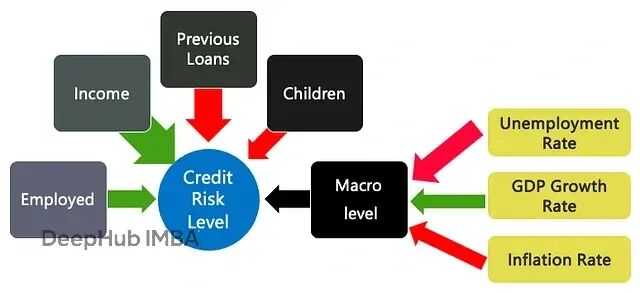
这通过因果组件模型来实现,这些模型可以逐步集成来达成特定用例的目标(类似模型微服务的概念)。因果组件模型把系统拆分成不同的、可管理的组件,每个组件代表特定的因果关系,然后将这些组件连接起来形成完整的系统因果模型。
随着时间推移,通过将强化学习(RL)和自学推理方法(比如STaR)集成到相互连接的模型和智能体系统中,可以创建自学习循环。这些系统通过管理转移学习过程,基于彼此的行动、知识、奖励和策略进行集体学习。
因果模型能够逐步发现按影响力排序的复杂因果关系,从而增强LLM的推理过程。
因果推理还能帮助限制幻觉问题。领域特定的小语言模型(SLM)被广泛认为是智能体AI的未来方向。它们可以作为智能体AI系统的"基础事实",提供可靠数据,防止基于错误或虚构信息的行动。像howso这样的公司正在通过集成因果AI、数据水印和归因推理来创建新的推理模型,目标是降低风险并提升准确性。
内省机制增强推理过程
从LLM训练转到推理阶段,我们来看看如何通过添加"内省"步骤来进一步改善智能体推理。
智能体AI的核心架构
一个完整的智能体AI平台包含几个关键模块。推理模块负责分解复杂任务并调整执行策略来达成目标;智能体市场提供现有和可用的智能体资源;编排模块负责协调和监控多智能体系统的执行;集成模块与企业系统对接,比如SCADA系统和知识库;共享内存管理处理智能体间的数据和上下文共享;治理层涵盖可解释性、隐私、安全等方面。

智能体AI平台参考架构
给定用户任务后,智能体AI平台的目标是找到(或组合)能够执行这个任务的智能体。所以首先需要一个推理模块,能够把任务分解成子任务,然后由编排引擎协调相应智能体的执行。
解决复杂任务的基本思路包括两步:先把复杂任务分解成简单任务的层次结构或工作流,然后组合能够执行这些简单任务的智能体。这可以用动态或静态方式实现。动态方式下,系统根据运行时可用智能体的能力来制定计划;静态方式下,在设计时就手动定义好复合智能体,组合它们的能力。
思维链(CoT)是目前最广泛使用的分解框架,它把复杂任务转换成多个可管理的任务,同时让模型的思考过程变得可解释。
ReAct(reasoning and acting)框架让智能体能够批判性地评估自己的行动和输出,从中学习,然后改进计划和推理过程。
智能体组合需要一个智能体市场或注册表,里面有智能体能力和限制的明确描述。比如Agent2Agent(A2A)协议定义了智能体卡概念,这是一个JSON文档,相当于智能体的数字"名片"。包含的关键信息有:
Identity: name, description, provider information. Service Endpoint: The url where the A2A service can be reached. A2A Capabilities: Supported protocol features like streaming or pushNotifications. Authentication: Required authentication schemes (e.g., "Bearer", "OAuth2") to interact with the agent. Skills: A list of specific tasks or functions the agent can perform (AgentSkill objects), including their id, name, description, inputModes, outputModes, and examples.
内省增强的ReAct推理
标准的ReAct智能体在网络检索任务上表现不错,但在工业物联网环境中就不够用了,经常出现这些问题:领域特定推理的缺失(比如无法把冷却器单元吨位和能效联系起来,这在工业物联网中是重要关联),推理不一致(特别是日期偏移推理,比如"上个月"这种表达),过早结束任务、重复调用工具、多步组合失败等。
为了解决这些问题,我们用迭代的ReAct + 内省策略来增强智能体,让智能体系统能够处理复杂的工业领域查询。
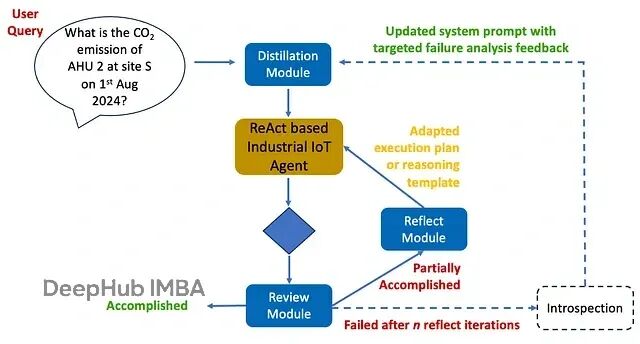
distillation模块作为预处理器,把复杂查询分解成结构化的语义单元:变量、约束和目标。ReAct继续作为底层编排框架,根据用户查询生成执行计划。
为了提升推理准确度,特别是在实体消歧方面,编排器会在开始执行前发出内部子查询来指导后续推理。
这个预期查询也会由LLM回答,能够改善计划一致性、任务执行准确度和工具调用精度。下面是系统提示的例子:
You are an advanced reasoning agent that can improve based on introspection.
You will be given a previous reasoning trial in which you were given access to
multiple agents and tools and a query to answer. You were unsuccessful in resolving the query correctly either because
you misunderstood the query, or you used up your set number of reasoning steps. In a few sentences, diagnose a possible reason for failure and devise a new
high-level execution plan that aims to mitigate the same failure.
Use complete sentences. Here are some examples:
{examples} Previous trial:
Query: {query} {plan}
review模块作为LLM-as-a-Judge验证器,把最终推理步骤的输出分为已完成、部分完成或失败三类,判断标准是生成的输出是否解决了用户查询。这会触发reflect模块对执行计划进行内省,评估推理步骤、智能体和工具调用等。
输出的是针对性反馈,以执行计划调整或推理模板的形式,这些反馈会加入到系统提示中指导未来的执行。
总结
当前LLM的推理局限性已成为制约智能体AI企业级应用的核心瓶颈。由于智能体系统在任务规划阶段高度依赖LLM能力,这种局限性直接影响了AI智能体的自主决策水平。
通过深入分析基于统计相关性的传统模型架构,可以识别出"因果关系理解"这一关键缺失环节。在推理阶段,通过引入"内省机制"对ReAct框架进行扩展,显著改善了智能体在实体消歧、领域特定推理等复杂场景下的表现。
论文:
https://avoid.overfit.cn/post/3a400ca049a14aa187a39f57f3caeacc
作者:Debmalya Biswas