PostgreSQL 内机器学习的关键智能算法研究
演讲嘉宾:崔鹏,海能达数据库团队负责人、PostgreSQL ACE、PG 分会哈尔滨用户组主席。
随着人工智能与机器学习的快速发展,数据库不仅作为数据存储与管理的核心基础设施,也逐渐成为机器学习任务执行的重要支撑平台。然而,传统数据库在存储结构选择、样本数据筛选、连接顺序优化等方面仍存在不足,难以满足机器学习在效率与精度方面的要求。为此,本文围绕 PostgreSQL 内的机器学习应用展开,提出了一系列关键智能算法。
研究绪论
研究背景和意义
- 人工智能时代的机遇与挑战:随着人工智能时代的到来,机器学习应用的领域越来越广泛。然而,伴随着数据爆炸的时代,机器学习在训练数据规模和计算等问题上正面临诸多严峻的挑战。
- 数据管理技术的局限性:现有的数据管理技术无法直接为机器学习数据提供智能的存储,现有数据选择方法不能很好地满足机器学习样本数据的概要提取需求,目前尚无高效的连接顺序选择算法等。
- 数据库内机器学习的优势:为了推动数据库内机器学习的发展,使智能数据管理技术赋能机器学习,提出了支撑数据库内机器学习的关键智能算法,包括基于集成学习的样本数据行列存储决策算法、基于聚类抽样的样本数据选择算法和基于强化学习的连接顺序推荐算法。
国内外研究现状
- 数据存储技术研究现状:现有研究重点关注多类型和多版本数据的存储,而存储结构对于机器学习任务的执行也会产生很大影响。
- 数据选择技术研究现状:现有方法通常采用抽样或者聚类等方式,虽能缩小原始数据集的尺寸,但极有可能漏掉许多与模型有关的数据,造成模型精度下降。
- 数据表连接技术研究现状:现有研究为实现智能连接提供了思路,即使用机器学习优化的数据库技术来赋能机器学习任务,同时轻量级编码和快速的模型训练也是需要纳入考虑的问题。
主要研究内容
- 基于集成学习的样本数据行列存储决策算法:研究支撑数据库内机器学习的存储结构智能决策算法,解决存储结构自动选择问题。
- 基于聚类抽样的样本数据选择算法:研究支撑数据库内机器学习的智能数据选择算法,解决机器学习训练前的数据选择问题。
- 基于强化学习的数据表连接顺序推荐算法:研究支撑数据库内机器学习的智能连接顺序推荐算法解决特征选择问题。
人工智能数据库的作用
人工智能数据库不仅仅是信息的存储库,也是一个动态的、专门的系统,它精心设计,以满足人工智能和机器学习应用程序的复杂需求。人工智能数据库具有高效存储、组织和检索数据的能力为构建、完善和部署开创性的人工智能模型提供了基础。
机器学习在数据库中的应用需求
- 数据处理需求:随着数据量的增长,机器学习需要高效的数据处理和存储。数据库可提供稳定的数据存储和快速的数据读写能力。
- 模型训练需求:实时预测要求快速响应,数据库可结合机器学习模型实现实时数据处理和预测,满足业务的及时性要求。
- 实时预测需求:机器学习需要有效的数据管理,包括数据清洗、特征提取和版本控制等。数据库可提供全面的数据管理解决方案。
- 数据管理需求:数据库内进行模型训练可减少数据传输开销,提高训练效率,同时,利用数据库的并行计算能力加速训练过程。
现有技术在 PostgreSQL 内机器学习中的局限性
- 数据存储问题:现有的数据管理技术无法直接为机器学习数据提供智能存储,不能根据工作负载推荐合适的存储结构,影响执行效率。
- 数据选择问题:现有数据选择方法不能很好地满足机器学习样本数据的概要提取需求,可能遗漏重要信息,导致模型精度下降。
- 连接顺序问题:目前尚无高效的连接顺序选择算法,多表连接操作效率低下,增加了机器学习任务的执行时间。
- 性能优化问题:现有技术在 PostgreSQL 内机器学习的性能优化方面存在不足,不能充分利用数据库的资源,影响系统整体性能。
PostgreSQL 内机器学习的发展机遇
- 技术融合机遇:在金融、医疗、交通等领域,PostgreSQL 内机器学习可拓展应用场景,为各行业提供更智能的解决方案。
- 研究创新机遇:数据库技术与机器学习技术的融合为 PostgreSQL 内机器学习带来机遇。结合两者优势,可提高数据处理和模型训练效率。
- 应用拓展机遇:吸引了更多研究者关注,推动相关技术的创新和发展。如开发新的算法和模型,提高数据库内机器学习的性能。
- 市场需求机遇:随着人工智能的发展,市场对数据库内机器学习的需求不断增加。PostgreSQL 可满足这一需求,提升市场竞争力。
解决 PostgreSQL 内机器学习挑战的思路
- 数据管理优化:优化数据存储结构,为机器学习数据推荐合适的存储方式,采用智能数据选择算法,提取最有代表性的数据。
- 算法创新设计:设计高效的连接顺序推荐算法,提高多表连接效率。结合强化学习等方法,优化机器学习任务的执行流程。
- 系统集成开发:开发集成数据库和机器学习功能的系统,实现数据的无缝流动和高效处理。利用数据库的并发控制和安全管理机制。
- 试验验证评估:通过实验验证算法和系统的有效性,评估性能指标。根据实验结果不断优化和改进,提高 PostgreSQL 内机器学习的性能。
机器学习驱动的样本数据行列存储决策算法
数据存储决策问题的提出
- 问题背景:目前相关研究较少,现有的存储方法不能很好地满足机器学习的需求。本次分享提出的算法具有创新性和实用性。
- 问题定义:存储结构决策是利用数据及存储结构特征训练代价模型,选择存储代价小的结构。目标是最小化数据存储代价提高执行效率。
- 研究意义:有效的存储决策算法可加速机器学习执行时间,提高系统性能。为数据库内机将学习的数据存储提供智能解决方案。
- 研究现状:在数据库内机器学习中,不同的存储结构对执行效率有显著影响。现有的存储选择方法缺乏智能性,需要新的决策算法。
问题定义
- 存储结构决策的目标:最小化数据的存储代价,即在行存储和列存储两种存储结构中,选择存储代价最小的。
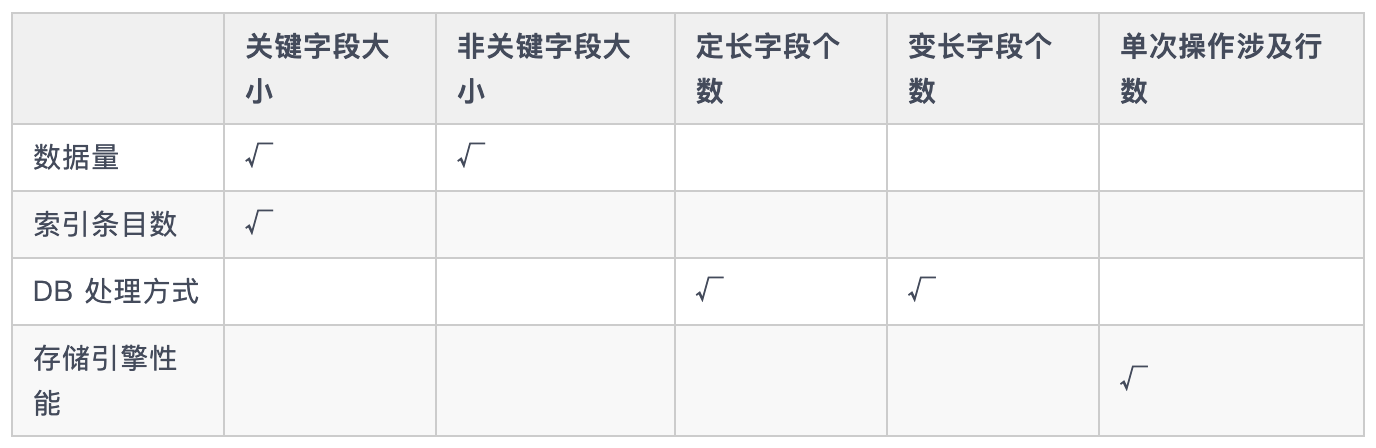
- 工作负载的特征:包括键字段大小、非键字段大小、定长字段个数、变长字段个数、单次操作涉及行数等。
- 存储结构的代价模型:利用数据及存储结构的特征训练存储代价模型,得到存储结构预测的代价后,选择存储代价较小的作为数据集的存储结构并执行机器学习任务。
这里举一个例子:
假设 T 的数据模式为 S,工作负载 Workload ={N_Inser,N_Select},其中 N_Insert 代表工作负载中插入数据的数量,N_Select 代表工作负载中查询数据的数量。分别在行存储结构 row 与列存储结构 column 下执行 workload,可得:
- 行存储结构的代价为:
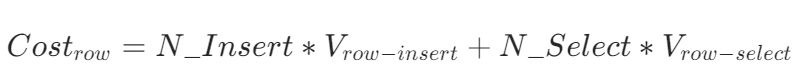
- 列存储结构的代价为:
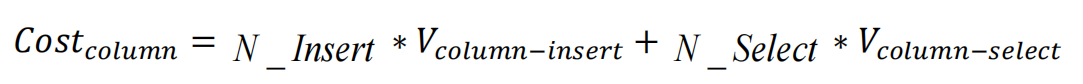
由上述问题定义可知,行列存储决策的目标是最小化数据的存储代价,即在行存储和列存储两种存储结构中选择存储代价最小的。
行列决策过程
在数据库系统中,行存储与列存储的选择常依赖于人工经验。因此为实现自动化决策,设计了一个轻量级的集成学习框架。
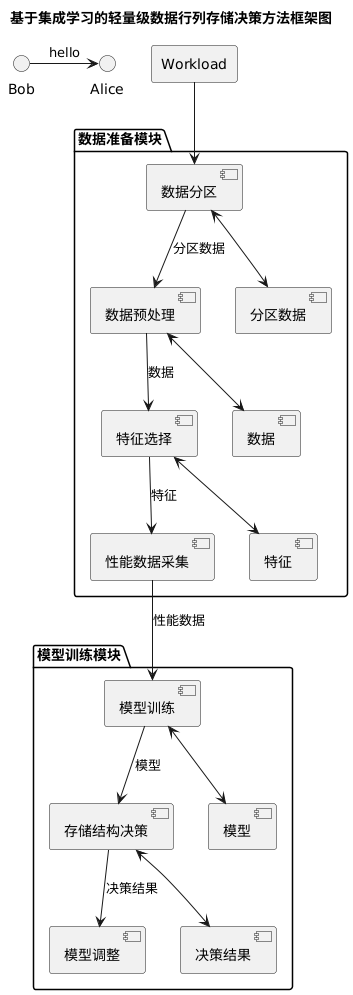
该框架的工作流清晰分为两个阶段:
- 数据准备模块:通过数据分区和特征提取,将原始数据和工作负载转化为带有性能标签的特征数据集。
- 模型训练模块:基于该数据集训练集成学习模型,从而能够根据数据特征自动做出行存储或列存储的推荐决策。
特征选择对性能预测影响
集成学习方法的选择
- 集成学习原理:集成学习将多个弱学习器组合成强学习器,提高模型的性能和稳定性。通过训练多个弱学习器并结合其结果减少误差。
- 常用集成模型:如 Boosting 和 Bagging 等。XGBoost 是基于 Boosting 的迭代决策树算法,具有高效和准确的特点。
- 选择原因:XGBoost 能最大化增强学习效果,自动利用 CPU 多线程并行计算。在处理复杂问题时表现出色,适用于存储决策任务。
- 应用优势:应用 XGBoost 可提高存储结构决策的准确性,为机器学习工作负载提供自动化的存储选择,减少资源浪费。
行列存储决策算法的设计
- 整体框架:算法分为数据准备和模型训练两个模块。数据准备模块处理负载数据,模型训练模块训练回归树模型,实现存储结构的智能决策。
- 数据分区算法:为解决大数据量处理效率问题,提出数据分区算法。对大规模数据进行分区,便于交叉验证和特征提取,提高模型精度。
- 特征选择与采集:选择数据模式和工作负载相关特征,如键字段大小、非键字段大小等。采用存储引擎性能数据采集算法,高效采集特征数据。
- 模型构建与训练:使用 XGBoost 对行存储和列存储的读写操作分别训练回归树模型。根据模型预测结果推荐合适的存储结构。
实验结果与分析
- 实验设置:采用 OpenGauss 6.0.0 数据库,基于 PostgreSQL 开发。选取 TPC-H 公开测试集,通过 pyodbc 接口连接数据库。
- 模型精度评估:对比行/列存储模型适用的工作负载,发现存储结构智能决策技术能使各类机器学习执行时间缩短约 5%,提高执行效率。
- 性能对比分析:从模型精度、特征选取有效性等方面评估算法。实验结果表明,提出的模型精度较高,所选特征能有效影响性能预测。
- 不同任务验证:在分类、回归和聚类任务中验证算法效果。结果显示,存储决策模型能为不同任务推荐低代价存储方案,提升任务执行效率。
基于聚类抽样的数据筛选算法
背景与挑战
- 数据选择的重要性:
- 例子:训练一个识别猫狗的模型,若直接用 10 万张图,电脑可能跑一天;若挑 1 万张有代表性的,计算时间由数十小时缩短至数小时,精度更高。
- 传统方法的不足:
- 随机抽样:随机抽样可能导致代表性不足,可能漏掉关键样本(比如没抓到“折耳猫”这种特殊类型);
- 单一聚类:简单分组可能把“哈士奇”和“狼”硬塞进一组,忽略细微差异。
- 现实挑战:
- 数据量大到上亿条时,传统方法要么耗时几天,要么选完数据模型精度暴跌。
问题定义与数学白话版
- 用生活例子理解问题:
- 原始数据集 T:比如 10 万张动物照片,每张照片是 xi,标签 pi 是“猫”“狗”等;
- 目标 T*:从 10 万张里挑出 1 万张,保证剩下的 9 万张里任意一张,都能在这 1 万张里找到“长得很像”的(距离(D(xi,xj))小于容忍度 Σ。
- 数学公式翻译:
- (D(xi,xj)):比如两张照片的“相似度”,可以是颜色、形状的差异;
- Σ:允许的“不像”程度,比如“只要有 70% 像就算同类”。
算法核心流程与相似性度量“公平秤”
- 两步走流程:
- 第一步聚类:把数据按“长相”分组,比如把所有“猫”的照片先聚成一大类,再细分“短毛猫”“长毛猫”;
- 第二步抽样:从每个组里挑“典型代表”,比如短毛猫里选最常见的花纹、体型的样本。
- 修正余弦相似度:让比较更公平
- 传统余弦相似度:直接比“长相”,但可能因“光线不同”(数据尺度差异)误判;
- 修正版:先把“光线调一致”(减去每组数据的平均值),再比相似度,就像给照片统一调色后再比较。
聚类与抽样算法“实操指南”
- 不相似点分裂聚类:找“最不像”的起点
- 怎么分组?先挑出整个数据里“最不像”的两个样本(比如猫和狗)当“组长”,然后让其他样本选跟谁更像,分成两组;
- 递归分裂:如果某组里样本还是太杂(比如“狗”组里有哈士奇和吉娃娃),再在组内重复挑“最不像”的继续分,直到每组够纯。
- 自适应抽样:按需“补样本”
- 算平衡度 d:比如某组里“折耳猫”只有 100 只,“普通猫”有 1000 只,(d=100/1000=0.1)(少数类占比少);
- 补样本:对少数类,在附近“虚构”一些类似样本(比如在折耳猫周围生成虚拟样本),让抽样时不被多数类淹没。
实验验证结果
用真实数据测试:
数据集:
- 分类任务:Spam 垃圾邮件(4601 封)、lris 鸢尾花(150 朵);
- 回归任务:Concrete 混凝土强度数据(1030 条);
- 聚类任务:Abalone 鲍鱼年龄数据(4177 条)。
关键效果:
- 分类更准更快:识别垃圾邮件时,用我们的算法选数据后,SVM 模型精度从 88.3% 涨到 90.7%,训练时间从 750ms 缩短到 454ms(快了 39.5%);
- 回归更稳:预测混凝土强度时,多项式回归的精度(R2)提升 4.2%,时间缩短 17.5%;
- 聚类更高效:对鲍鱼数据聚类,K 均值算法的评价指标 DBI 提升 11.6%,时间缩短 33.3%。
小结与展望:不止于此的“数据魔法”
-
我们做了什么?
发明了“聚类+抽样”组合算法,像给数据做“精炼提纯”,保留关键信息,扔掉冗余;
实验证明:分类、回归、聚类任务都能用,精度平均提升 3%-11.6%,时间最多缩短 85%。 -
未来如何优化?
处理更大数据:比如上亿条数据时,优化聚类速度;
结合深度学习:让算法自动学习“什么数据更重要”不用人工调参数;
用在特殊场景:比如医疗数据(样本少但珍贵),精准选数据避免浪费。
强化学习驱动的数据表连接顺序推荐算法
数据库整体性能在很大程度上取决于查询效率,其中相当一部分性能优势源自于我们对连接查询执行计划的优化与实现。
问题定义
- 连接顺序选择的目标:找到代价最小的连接顺序,加速多源数据表连接,进而减小训练模型的时间成本。
- 连接顺序选择的方法:将连接顺序问题构建为马尔可夫决策过程,每张表在加入 join 后被看作 join 连接树的叶子结点,每个阶段 join 后的各张表的编码集合构成马尔可夫决策过程的状态集合,每张表是否加入 join 的行为构成动作集合,当全部表均加入 join,则到达终止状态,奖励是指利用代价模型估计查询计划的执行代价。
连接顺序推荐流程
- 强化学习框架:将多表查询的 join order 推荐问题视为一个马尔可夫决策过程(MDP),每张表在加入 join 后被看作 join 连接树的叶子结点;然后,每个阶段 join 后的各张表的编码集合构成马尔可夫决策过程的状态集合,对于各张表的编码采用左右值编码的方法编码成向量,每张表是否加入 join 的行为构成动作集合,当全部表均加入 join,则到达终止状态,奖励是指利用代价模型估计查询计划的执行代价,此外,本文还提出了两阶段调整模型的精度方案。
- 问题建模:状态集合、动作集合与代价函数的定义。
- 状态编码方法:对每张加入 join 的数据表编码为(left,right,layer)三维数组,特别地,对初始状态进行编码后,选择动作之后的下一状态可以由状态转移编码算法计算得出。
- 基于 Q 学习的连接顺序推荐方法:使用 Q- table 得到 Q 函数,然后通过训练不断更新函数来得到最优 state- action 值函数 Q*(s,a)。
- 基于 DQN 的连接顺序推荐方法:使用神经网络对值函数近似,此外还加入了经验回放机制与目标值网络。
- 数据表连接顺序推荐算法:每次都选择奖励最大的动作执行,最终组成最优的连接顺序。
模型收敛性
- Q- learning 模型:随着训练轮数的增加,Q- value 的和逐渐增大,在大约 3000 轮时,增长趋势逐渐平稳,证明该模型具有收敛性。
- DQN 模型:随着训练轮数的增加,reward 逐渐减小,在大约 10500 轮时,下降趋势逐渐平稳,证明该模型具有收敛性。
推荐模型与 PostgreSQL 优化器性能对比
实验结果:经过连接顺序推荐的查询时间相较于 PostgreSQL 数据库优化器有明显的减少,基于 Q 学习的模型推荐较 postgresql 数据库优化器提升 20%左右;而基于 DQN 的模型推荐的连接顺序的执行查询时间提升在 23%左右。
连接顺序推荐算法对机器学习任务的影响
在分类、回归与聚类三类典型任务中,引入基于 Q 学习 和 DQN 的模型后,相比传统的 PostgreSQL 数据库,任务执行时间均得到显著缩短:
- 分类任务:Q 学习模型缩短 8.9%,DQN 模型缩短 15.3%;
- 回归任务:Q 学习模型缩短 9.0%,DQN 模型缩短 12.1%;
- 聚类任务:Q 学习模型缩短 8.5%,DQN 模型缩短 26.5%。
总结
综上所述,本研究在样本数据存储结构智能决策、基于聚类抽样的数据筛选、以及基于强化学习的数据表连接顺序推荐等方面提出了创新性算法,并通过实验验证了其在分类、回归和聚类任务中的显著优势。研究结果表明,这些方法能够有效提升 PostgreSQL 内机器学习的执行效率与模型精度,为智能数据管理与数据库内机器学习的深度融合提供了理论基础和技术路径。未来工作将进一步面向大规模数据和复杂应用场景开展优化与扩展,推动数据库智能化的发展。