【从零开始编写数据库系统】基于Python语言实现存储引擎
【从零开始编写数据库系统】基于Python语言实现存储引擎
- 一、存储引擎简介
-
- 1. 核心组件及功能
- 2. 存储引擎的核心作用
- 二、基于Python实现存储引擎代码结构
- 三、存储系统原理图与数据流程分析
-
- 系统原理图
- 数据流程图
- 详细解释与说明
-
- 1. 系统架构分析
- 2. 核心组件功能
-
- 2.1 缓冲区管理器 (BufferPool)
- 2.2 磁盘管理器 (DiskManager)
- 2.3 页结构 (Page)
- 2.4 记录序列化器 (RecordSerializer)
- 3. 数据流程说明
- 4. 设计特点与优势
- 5. 潜在改进方向
一、存储引擎简介
数据库存储引擎,其核心功能是负责数据的物理存储、管理与高效访问,是数据库与底层存储介质(如磁盘)交互的核心模块。以下是其核心组件及整体作用的简介:
1. 核心组件及功能
-
页(Page):数据存储的基本单位
由page.py实现,以固定大小(4KB)为单位组织数据,分为页头(存储页ID、类型、空闲空间偏移量、校验和等元数据)和数据区(存储实际记录)。支持记录的添加、读取、逻辑删除(标记记录长度为负值)及校验和验证(确保数据完整性),是数据在磁盘和内存中的基本载体。 -
磁盘管理器(DiskManager):物理存储的直接管理者
由disk_manager.py实现,负责数据库文件的创建、打开、关闭,以及页的物理读写(通过页ID计算磁盘偏移量)。维护页缓存(减少磁盘IO)和空闲页集合(复用已释放的页),是内存数据与磁盘文件之间的桥梁。 -
缓冲区池(BufferPool):提升访问效率的缓存层
由buffer_manager.py实现,基于LRU(最近最少使用)策略管理内存中的页缓存,减少直接磁盘IO操作。跟踪“脏页”(内存中修改但未写入磁盘的页),负责缓存的命中、淘汰(缓存满时移除最久未使用的页)和刷盘(将脏页写入磁盘),是提升存储引擎性能的关键组件。 -
记录序列化器(RecordSerializer):数据格式的转换器
由record.py实现,负责将用户级记录(字典形式)与字节流互转,支持INT、VARCHAR、BOOL、FLOAT等数据类型。处理字符串截断(确保UTF-8字符完整性)、类型转换和格式校验,保证数据在页中按统一格式存储和解析。
2. 存储引擎的核心作用
- 数据持久化:通过页和磁盘管理器,将数据以结构化的方式存储在磁盘文件中,确保数据库重启后数据不丢失。
- 高效IO管理:通过缓冲区池的缓存机制,减少磁盘读写次数,平衡内存与磁盘的访问速度差异,提升数据访问效率。
- 数据完整性:通过页的校验和机制,验证数据在传输或存储过程中是否损坏,保证数据可靠性。
- 抽象存储接口:向上层提供统一的页操作、记录存取接口,屏蔽底层磁盘存储的细节(如文件偏移、格式转换等),简化上层模块(如查询引擎)的实现。
简言之,该存储引擎通过“页管理-磁盘交互-缓存优化-数据转换”的协同,实现了数据的可靠存储与高效访问,是数据库系统的“基石”。
二、基于Python实现存储引擎代码结构

- buffer_manager.py: 实现了缓冲区池管理器,用于缓存磁盘页,提高读写效率。
- disk_manager.py: 磁盘管理器,负责实际的文件I/O操作,包括页的分配、读取、写入和释放。
- page.py: 定义了页的数据结构,包括页头信息和记录存储方法。
- record.py: 记录序列化器,负责将记录序列化为字节流和反序列化。
- 首先,我们分析各个模块的功能和关系:1. RecordSerializer (record.py): 负责将记录(字典形式)与字节流之间进行转换。2.Page (page.py): 代表一个数据库页,可以存储多条记录。它负责管理页内的记录,包括添加记录、读取记录等。3. DiskManager (disk_manager.py): 负责管理数据库文件,包括分配页、读取页、写入页、释放页等操作。它使用文件系统来存储页。4. BufferPool (buffer_manager.py): 缓冲区池,缓存从磁盘读取的页,减少磁盘I/O。当需要读取页时,首先检查缓冲区,如果不存在则从磁盘读取并放入缓冲区。当页被修改时,标记为脏页,并在适当的时候写回磁盘。
其次,代码之间的关系:1.RecordSerializer 被上层模块(如表、索引等)使用,将记录序列化后,通过Page的add_record方法添加到页中。
2.Page 通过DiskManager从磁盘读取或写入磁盘。
3.BufferPool 在DiskManager之上,缓存页,提供更快的访问。
但是注意:在提供的代码中,BufferPool直接使用DiskManager来读取页,而DiskManager自己也有一个页缓存(page_cache)。这在实际系统中可能不是这样设计的,因为通常磁盘管理器只负责直接磁盘I/O,而缓冲区管理则由缓冲区池负责。但这里DiskManager的缓存可能是为了减少实际文件I/O,而BufferPool则是为了在内存中缓存页以提供更快的访问。实际上,我们可以将DiskManager的缓存视为操作系统级别的缓存,而BufferPool是数据库级别的缓存。但为了简化,我们通常只在数据库级别做缓存。因此,这里DiskManager的缓存可能是不必要的,或者可以视为另一种形式的缓冲。
4. 考虑到代码结构,我们绘制原理图如下:
原理图(模块关系图):
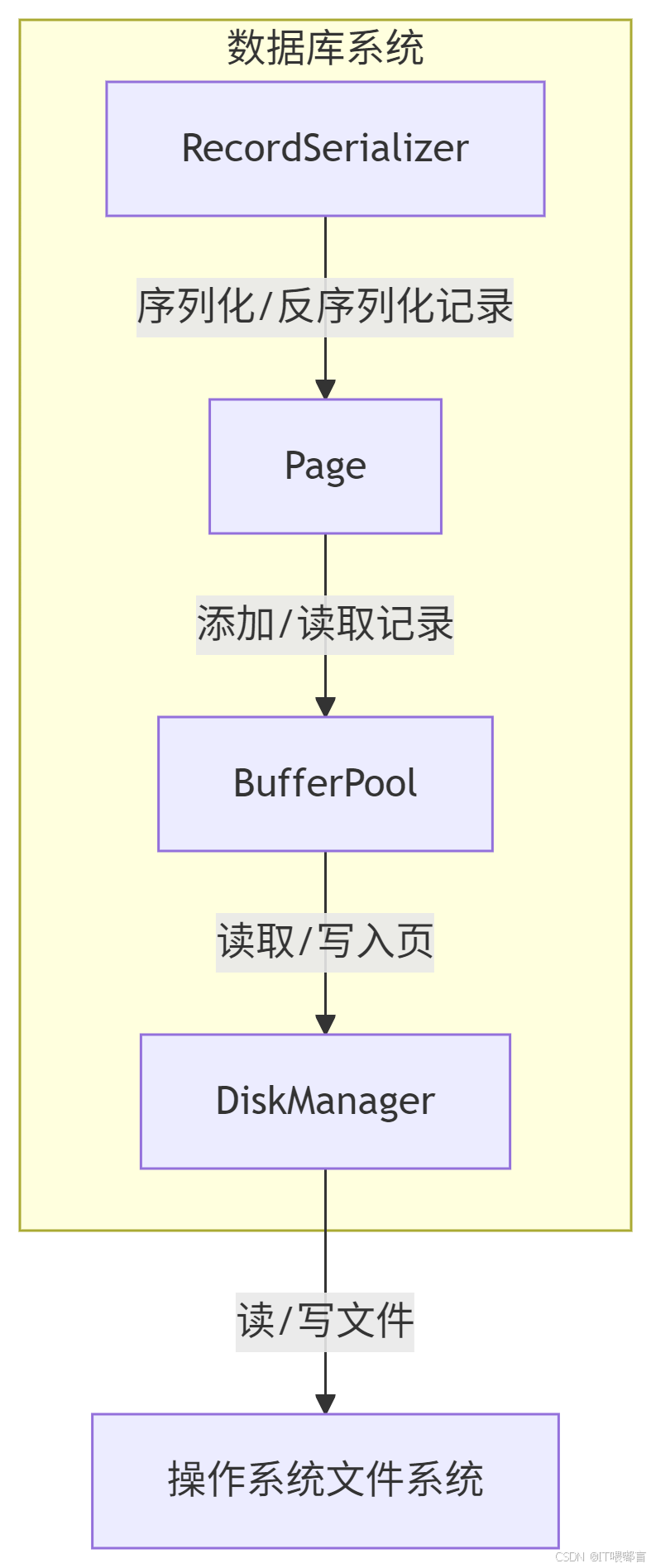
1.RecordSerializer模块负责记录的序列化和反序列化,它与Page模块交互,因为Page中存储的是序列化后的记录。
2.Page模块代表一个数据库页,它负责管理页内的记录存储布局。
3.BufferPool模块是缓冲区池,它缓存了多个页,上层模块通过缓冲区池来获取页,减少了直接磁盘访问。
4.DiskManager模块直接与操作系统文件系统交互,负责将页读写到数据库文件中。
数据流程图(从记录到磁盘):
1.插入记录:记录 -> RecordSerializer序列化 -> Page添加记录 -> Page标记为脏 -> BufferPool缓存页 -> 当刷脏时,BufferPool调用DiskManager写入磁盘。
2.读取记录:BufferPool获取页(如果不在缓冲则从磁盘读取) -> Page读取记录 -> RecordSerializer反序列化 -> 得到记录。
我们可以用两个流程图来描述读写过程。我们使用两个独立的流程图。
写入记录的数据流程:

1.记录首先被RecordSerializer序列化成字节数据。
2.序列化后的数据被添加到Page中,Page会检查是否有足够空间。
3.如果添加成功,Page被标记为脏。
4.通过BufferPool的unpin_page方法标记页为脏(在取消固定时告诉缓冲区此页已被修改)。
5.缓冲区池在适当的时机(如页淘汰或刷脏)将脏页通过DiskManager写入磁盘。
读取记录的数据流程:

读取过程:
1.请求记录时,首先通过BufferPool获取页。
2.如果页在缓冲区中,直接获取;否则通过DiskManager从磁盘读取。
3.从Page中获取记录的字节数据(通过get_records方法)。
4.通过RecordSerializer反序列化字节数据得到记录字典。
注意:在读取过程中,BufferPool会使用LRU策略缓存页,并且会记录命中次数和未命中次数用于统计。