thrust cub cccl 安装与应用示例
0. cccl/thrust/cub 安装
下载源码:
git clone https://github.com/NVIDIA/cccl.git配置安装:
0.1. header file library
不用安装就可以用:
git clone https://github.com/NVIDIA/cccl.git
nvcc -Icccl/thrust -Icccl/libcudacxx/include -Icccl/cub main.cu -o main0.2. 缺省安装方式
The default CMake options generate only installation rules, so the familiar cmake . && make install workflow just works:
git clone https://github.com/NVIDIA/cccl.git
cd cccl
cmake . -DCMAKE_INSTALL_PREFIX=/usr/local
make install0.3. 同时安装试验阶段的功能
CMake presets are also available with options for including experimental libraries:
cmake --preset install -DCMAKE_INSTALL_PREFIX=/home/hipper/ex_cccl/tmp2/local
cmake --build --preset install --target install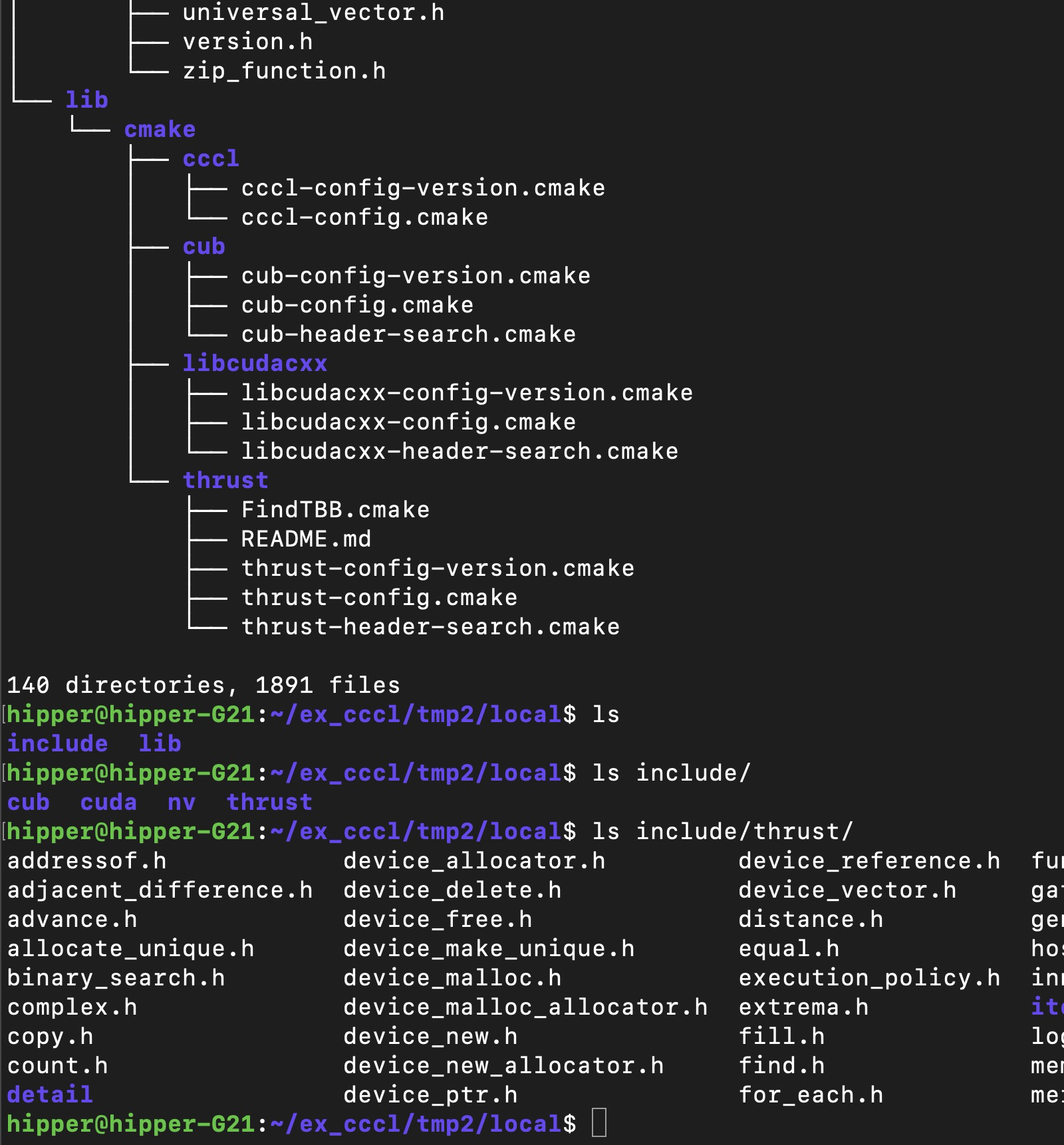
或者:
cmake --preset install -DCMAKE_INSTALL_PREFIX=/home/hipper/ex_cccl/tmp1/usr/local
cd build/install/
ninja install0.4. 验证安装
示例:
hello_cub_thrust.cu
#include <thrust/execution_policy.h>
#include <thrust/device_vector.h>
#include <cub/block/block_reduce.cuh>
#include <cuda/atomic>
#include <cuda/cmath>
#include <cuda/std/span>
#include <cstdio>template <int block_size>
__global__ void reduce(cuda::std::span<int const> data, cuda::std::span<int> result) {using BlockReduce = cub::BlockReduce<int, block_size>;__shared__ typename BlockReduce::TempStorage temp_storage;int const index = threadIdx.x + blockIdx.x * blockDim.x;int sum = 0;if (index < data.size()) {sum += data[index];}sum = BlockReduce(temp_storage).Sum(sum);if (threadIdx.x == 0) {cuda::atomic_ref<int, cuda::thread_scope_device> atomic_result(result.front());atomic_result.fetch_add(sum, cuda::memory_order_relaxed);}
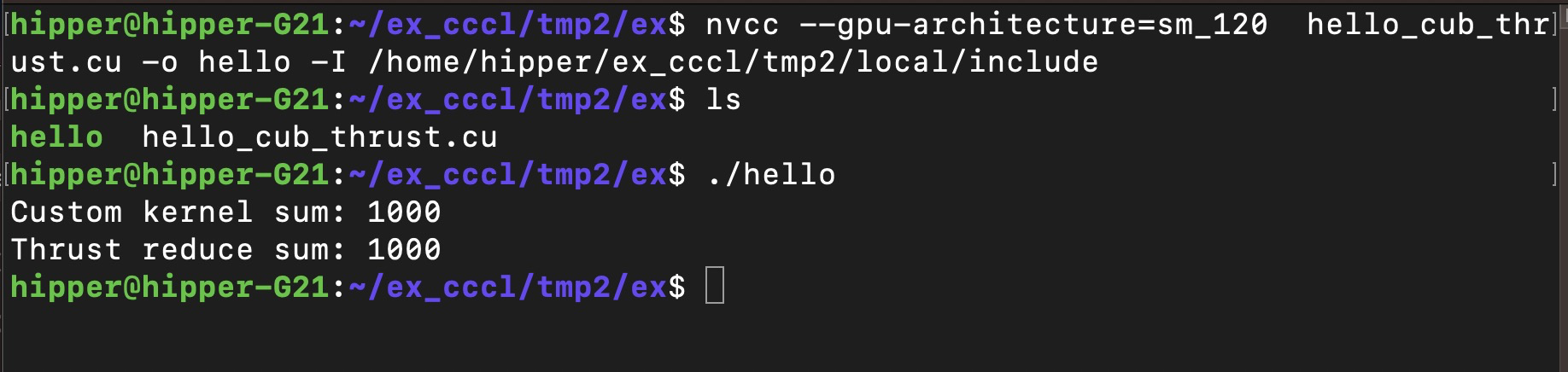
}int main() {// Allocate and initialize input dataint const N = 1000;thrust::device_vector<int> data(N);thrust::fill(data.begin(), data.end(), 1);// Allocate output datathrust::device_vector<int> kernel_result(1);// Compute the sum reduction of `data` using a custom kernelconstexpr int block_size = 256;int const num_blocks = cuda::ceil_div(N, block_size);reduce<block_size><<<num_blocks, block_size>>>(cuda::std::span<int const>(thrust::raw_pointer_cast(data.data()), data.size()),cuda::std::span<int>(thrust::raw_pointer_cast(kernel_result.data()), 1));auto const err = cudaDeviceSynchronize();if (err != cudaSuccess) {std::cout << "Error: " << cudaGetErrorString(err) << std::endl;return -1;}int const custom_result = kernel_result[0];// Compute the same sum reduction using Thrustint const thrust_result = thrust::reduce(thrust::device, data.begin(), data.end(), 0);// Ensure the two solutions are identicalstd::printf("Custom kernel sum: %d\n", custom_result);std::printf("Thrust reduce sum: %d\n", thrust_result);assert(kernel_result[0] == thrust_result);return 0;
}编译:
$ nvcc --gpu-architecture=sm_120 hello_cub_thrust.cu -o hello -I /home/hipper/ex_cccl/tmp2/local/include运行:
./hello
接下来介绍一下 NVIDIA CUDA 生态中的 CCCL,特别是其中的 CUB 和 Thrust 这两个至关重要的库。
1. 总览:CCCL 是什么?
CCCL 全称是 Common Companions for CUDA Libraries。可以将它理解为一个官方集合,它把几个核心的、为 CUDA C++ 设计的现代 C++ 库捆绑在一起,并提供统一的开发、测试和发布流程。
CCCL 包含的三个主要库是:
Thrust: 一个类似于 C++ STL 的高层算法库;
CUB: 一个针对 CUDA 线程块(Block)和线程束(Warp)级别的底层原语库;
libcudacxx: 一个为设备端代码(__device__ 函数)实现的 C++ Standard Library;
核心目标 CCCL 旨在为 CUDA C++ 开发者提供一套高性能、可移植、且符合现代 C++ 标准的工具集,从而可以极大地简化并行编程。
2. CUB (CUDA Unbound)
简介
CUB 是一个底层、高性能的模板库,它提供了针对 CUDA 线程束(Warps)、线程块(Blocks)和整个设备(Devices) 的可复用软件组件。
设计哲学
CUB 追求极致的性能。它不提供像 vector 这样的容器,而是提供算法原语,让你可以精细地控制 GPU 上不同层级(Warp/Block/Device)的并行操作。它通常用于需要极致优化或 Thrust 无法直接满足的特殊需求的场景。
核心功能与特性
分层并行原语
Warp-Level, 例如,线程束内的规约(Reduction)、扫描(Scan)、排序等。这些操作利用 warp 的硬件特性(如 __shfl_sync 指令)实现极低的开销。
Block-Level, 例如,线程块内的规约、扫描、排序、归并等。它使用共享内存(Shared Memory)来实现块内线程的协作。
Device-Level, 例如,整个 GPU 设备上的并行规约、扫描、排序、稀疏矩阵压缩等。这些原语会自动启动一个或多个内核来完成工作。
迭代器抽象 与 Thrust 类似,CUB 也使用迭代器来操作数据,使其非常灵活。
性能极致 CUB 的算法经过高度优化,通常是你能在 GPU 上获得的最高性能实现,被广泛应用于其他高层库(包括 Thrust)和深度学习框架(如 PyTorch、TensorFlow)的底层实现中。
灵活性 允许开发者手动管理临时存储(分配/重用设备内存),以减少内存分配开销。
简单代码示例:Block-Level 求和规约
#include <cub/cub.cuh>__global__ void kernel(const int* d_in, int* d_out) {// 为每个线程块声明共享内存和临时存储using BlockReduce = cub::BlockReduce<int, 256>; // 256 threads per block__shared__ typename BlockReduce::TempStorage temp_storage;int thread_data = d_in[threadIdx.x];// 在块内执行规约求和int aggregate = BlockReduce(temp_storage).Sum(thread_data);// 让第一个线程将结果写回全局内存if (threadIdx.x == 0) {d_out[blockIdx.x] = aggregate;}
}3. Thrust
简介
Thrust 是一个高层的、类似于 C++ STL 的并行算法库。如果你熟悉 STL,那么学习 Thrust 会非常容易。它的目标是让并行编程像串行编程一样简单。
设计哲学
Thrust 强调开发效率和可读性。它通过提供强大的泛型抽象(如容器、迭代器、算法)来隐藏 CUDA 内核启动、内存管理等底层细节,让开发者专注于算法逻辑本身。
核心功能与特性
高级算法 提供了大量常用的并行算法,例如:
变换:transform
规约:reduce, min_element, max_element
前缀和:inclusive_scan, exclusive_scan
排序:sort, sort_by_key
流压缩:copy_if, remove_if
容器
thrust::host_vector:分配在主机(CPU)内存中的向量。
thrust::device_vector:分配在设备(GPU)内存中的向量。这是最常用的容器,它自动管理设备内存的分配和释放。
执行策略(Execution Policies) 这是 Thrust 最强大的特性之一。它允许你通过一个简单的策略参数来指定算法在何处执行,而无需修改算法代码本身。
thrust::seq: 在主机上串行执行。
thrust::host: 在主机上并行执行(使用 TBB、OpenMP 等后端)。
thrust::device: 在设备(GPU)上执行。(最常用)
这实现了“一次编写,随处执行”的泛型编程理念。
与现有代码无缝集成 Thrust 的算法可以直接操作原始指针,因此可以轻松地与 CUDA malloc 分配的内存或甚至 STL 容器一起使用。
简单代码示例:计算向量的平方和
#include <thrust/host_vector.h>
#include <thrust/device_vector.h>
#include <thrust/transform_reduce.h>
#include <thrust/functional.h>
#include <iostream>// 平方函子
struct square {__host__ __device__float operator()(float x) const {return x * x;}
};int main() {// 在主机上创建向量thrust::host_vector<float> h_vec = {1.0f, 2.0f, 3.0f, 4.0f, 5.0f};// 将数据传输到设备thrust::device_vector<float> d_vec = h_vec;// 使用transform_reduce计算平方和// 第一个transform将每个元素平方,然后reduce求和float sum_of_squares = thrust::transform_reduce(d_vec.begin(), // 输入起始迭代器d_vec.end(), // 输入结束迭代器square(), // 一元操作:平方0.0f, // 初始值thrust::plus<float>() // 二元操作:加法);std::cout << "Original Vector: ";for (int i = 0; i < h_vec.size(); i++) {std::cout << h_vec[i] << " ";}std::cout << std::endl;std::cout << "quadratic sum: " << sum_of_squares << std::endl;// 验证结果 (1² + 2² + 3² + 4² + 5² = 55)std::cout << "expected result: " << 1*1 + 2*2 + 3*3 + 4*4 + 5*5 << std::endl;return 0;
}编译:
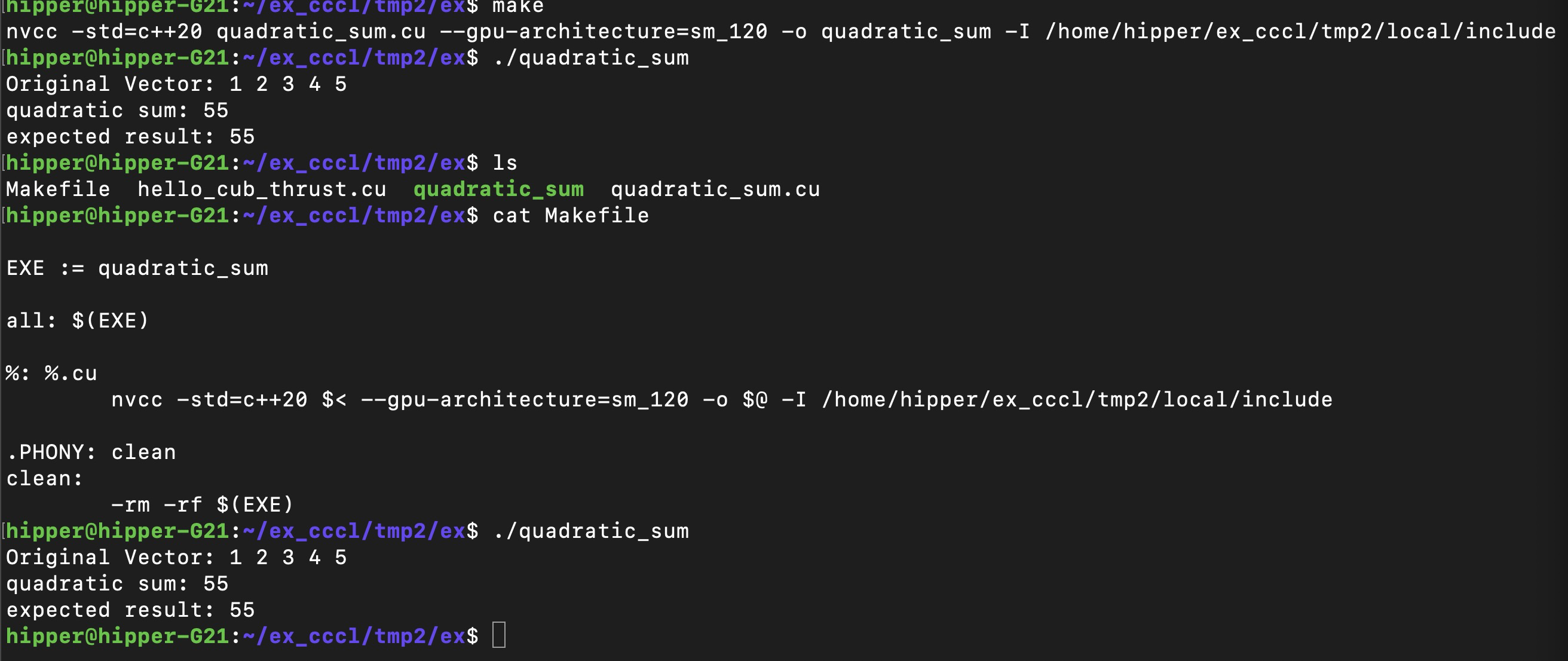
Makefile
EXE := quadratic_sumall: $(EXE)%: %.cunvcc -std=c++20 $< --gpu-architecture=sm_120 -o $@ -I /home/hipper/ex_cccl/tmp2/local/include.PHONY: clean
clean:-rm -rf $(EXE)make
运行:
代码说明
数据结构
使用 thrust::host_vector 和 thrust::device_vector 分别管理主机和设备内存
核心算法
thrust::transform_reduce 结合了两个操作:
square() 函子:对每个元素进行平方运算;
thrust::plus<float>():将平方后的结果累加;
体现 thrust 优势
自动管理内存传输;高度优化的并行算法;简洁的 API;
变体:使用lambda表达式(CUDA 11+)
#include <thrust/transform_reduce.h>
#include <thrust/device_vector.h>
#include <iostream>int main() {thrust::device_vector<float> d_vec = {1.0f, 2.0f, 3.0f, 4.0f, 5.0f};float sum_of_squares = thrust::transform_reduce(d_vec.begin(),d_vec.end(),[] __device__ (float x) { return x * x; }, // Lambda表达式0.0f,thrust::plus<float>());std::cout << "平方和: " << sum_of_squares << std::endl;return 0;
}这个示例可以体会到 Thrust 库的简洁性和高效性,主要面向大规模数据的并行计算任务。
4. CUB 与 Thrust 的对比与选择
| 特性 | Thrust | CUB |
|---|---|---|
| 抽象层级 | 高层(类似 STL) | 底层(构建块/原语) |
| 编程范式 | 泛型编程,强调接口和声明式 | 提供可组合的并行原语,强调控制和性能 |
| 易用性 | 高,隐藏了内核启动、内存管理等细节 | 中/低,需要更多 CUDA 知识(如共享内存、线程同步) |
| 性能 | 优秀,但对于极端优化场景可能不够 | 极致,通常是性能最高的选择 |
| 灵活性 | 通过执行策略提供灵活性 | 通过允许精细控制内存和执行提供极高灵活性 |
| 典型使用场景 | - 快速原型开发 - 数据预处理和后处理 - 不需要极致性能的通用算法 | - 自定义高性能内核的构建块 - 深度学习框架的算子实现 - 对 Thrust 无法满足的性能关键部分进行优化 |
总结与建议
CCCL 是 NVIDIA 官方维护的库集合,放在一起是为了确保了 Thrust、CUB 和 libcudacxx 之间的协同工作和高质量。
首选 Thrust 对于大多数应用场景,尤其是当你开始一个新项目或需要快速实现功能时,Thrust 应该是你的首选。它的抽象层级高,代码简洁易懂,并且性能在大多数情况下已经足够好。
必要时才使用 CUB 当你发现 Thrust 成为性能瓶颈,或者你需要实现一个非常定制化的、高性能的并行模式(例如,在自定义内核中需要一个高效的块内排序或规约)时,再深入使用 CUB。你可以将 CUB 的原语与你自己的内核混合编程。
混合使用 一个常见的模式是使用 Thrust 进行整体的数据管理和大规模操作(如排序、规约),而在自己编写的性能关键的内核中调用 CUB 的块级或线程束级原语。
总之,CCCL 为 CUDA 开发者提供了从方便易用(Thrust)到极致性能(CUB)的完整工具链,是现代 GPU 编程不可或缺的利器。在进一步结合 cutlass/cute,将在 CUDA 程序设计领域无往不利。