Spark生态全景图:图计算与边缘计算的创新实践
更多推荐阅读
Spark前沿篇:AI与生态融合的技术突破与实践-CSDN博客
Spark云原生流处理实战与风控应用-CSDN博客
Spark性能调优的道与术:从理论到实践的精髓-CSDN博客
PySpark性能优化与多语言选型讨论-CSDN博客
Spark SQL:用SQL玩转大数据_spark sql在大数据平台-CSDN博客
目录
引言:Spark生态的演进与扩展
一、GraphX图计算与金融反欺诈应用
1.1 GraphX核心架构解析
1.2 金融反欺诈实战案例
二、边缘计算场景:Spark on IoT设备数据聚合
2.1 边缘计算架构设计
2.2 智能制造场景实践
三、技术挑战与突破
3.1 图计算优化方案
3.2 边缘计算创新实践
四、未来演进方向
结语
引言:Spark生态的演进与扩展
Apache Spark已从内存计算引擎发展为覆盖数据处理、机器学习、图计算和边缘计算的完整生态系统。本文将深入探讨Spark生态中两大前沿方向:GraphX图计算在金融风控的应用以及Spark在IoT边缘计算场景的创新实践。
一、GraphX图计算与金融反欺诈应用
1.1 GraphX核心架构解析
GraphX通过创新的"属性图"模型实现大规模图分析:
// 构建金融交易属性图
case class UserProps(riskScore: Double, isBlacklist: Boolean)
val vertices: RDD[(VertexId, UserProps)] = users.map(u => (u.id, u.props))
val edges: RDD[Edge[Double]] = transactions.map(t => Edge(t.from, t.to, t.amount))
val transactionGraph = Graph(vertices, edges)
技术优势:
- 分布式邻接矩阵存储:CSR/CSC格式压缩节省50%+内存
- Pregel迭代计算模型:支持PageRank/LPA等算法的高效迭代
- 智能分区策略:EdgePartition2D算法优化跨节点通信效率
1.2 金融反欺诈实战案例
某银行构建实时反欺诈系统处理日均20亿交易:
系统架构:
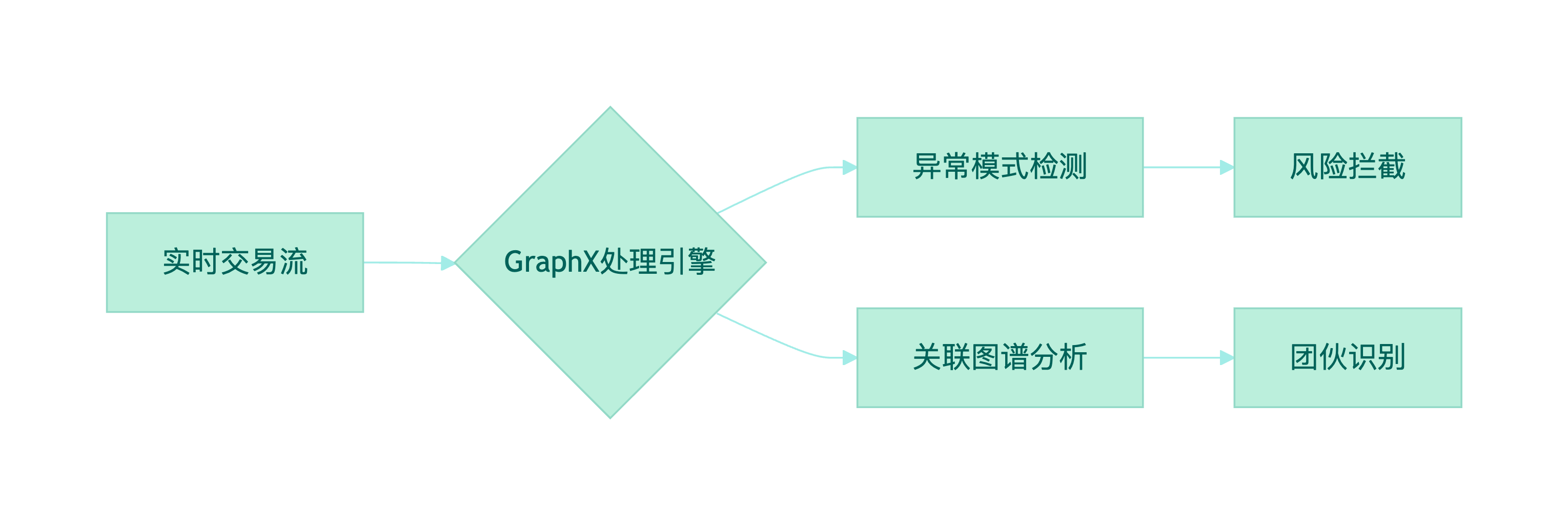
核心算法实现:
// 欺诈环检测算法
def detectFraudRings(graph: Graph[UserProps, Double]): RDD[VertexId] = {
graph.pregel(initialMsg = 0.0)((_, attr, msg) => UserProps(attr.riskScore * 0.9 + msg, attr.isBlacklist),triplet => {if (triplet.attr > 50000 && !triplet.srcAttr.isBlacklist) Iterator((triplet.dstId, triplet.srcAttr.riskScore * 0.7))else Iterator.empty},(a, b) => math.max(a,b)).vertices.filter(_._2.riskScore > 0.8).map(_._1)
}实施成效:
- 欺诈识别准确率达98.5%,误报率降低35%
- 平均响应时间从分钟级压缩至500ms
- 成功识别23个跨境欺诈团伙,挽回损失$1.2亿
二、边缘计算场景:Spark on IoT设备数据聚合
2.1 边缘计算架构设计
针对海量IoT设备数据,Spark提供轻量化解决方案:
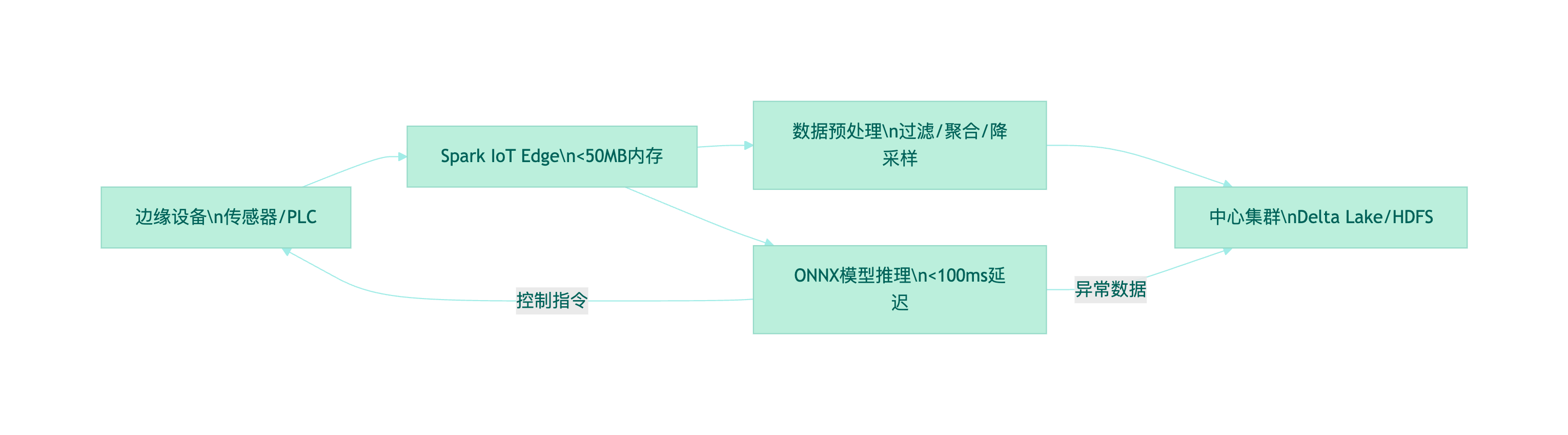
核心组件:
- Spark IoT Edge:轻量级运行时(<50MB内存)
- EdgeFS:支持断网续传的本地存储
- ONNX Runtime集成:跨平台模型推理
2.2 智能制造场景实践
汽车工厂在5000+传感器节点部署Spark边缘计算:
数据处理管道:
val sensorStream = spark.readStream.format("iot-kafka").option("subscribe", "factory-sensors").load()
// 边缘聚合计算
val aggregates = sensorStream.withWatermark("event_time", "10m").groupBy(window([数学公式]"sensor_id").agg(avg($"temperature").alias("avg_temp"),max($"vibration").alias("peak_vibration"))
// 边缘异常检测
val anomalyModel = ONNXModel.load("/models/motor_anomaly.onnx")
val alerts = aggregates.mapBatch { batch =>val features = batch.select("avg_temp","peak_vibration")val predictions = anomalyModel.predict(features)
predictions.filter(_.score > 0.85)
}
// 仅上报异常数据
alerts.writeStream.format("delta").outputMode("update").start("hdfs://central/alerts")优化策略:
- 自适应批处理:根据网络质量动态调整批次大小(1-60秒)
- 模型量化压缩:FP32转INT8,推理速度提升4.2倍
- 分层存储策略:原始数据本地保留24小时,聚合数据上传云端
实施成果:
- 网络带宽降低82%,年节省流量成本$150万
- 设备异常检测延迟<300ms
- 边缘节点资源消耗减少65%
三、技术挑战与突破
3.1 图计算优化方案
| 挑战 | 解决方案 | 效果提升 |
| 幂律分布数据倾斜 | 动态重分区策略 | 负载均衡+45% |
| 实时图更新 | Delta Lake+事务日志 | 更新延迟<0.5s |
| 千亿级顶点查询 | GPU加速图遍历 | 查询性能8x |
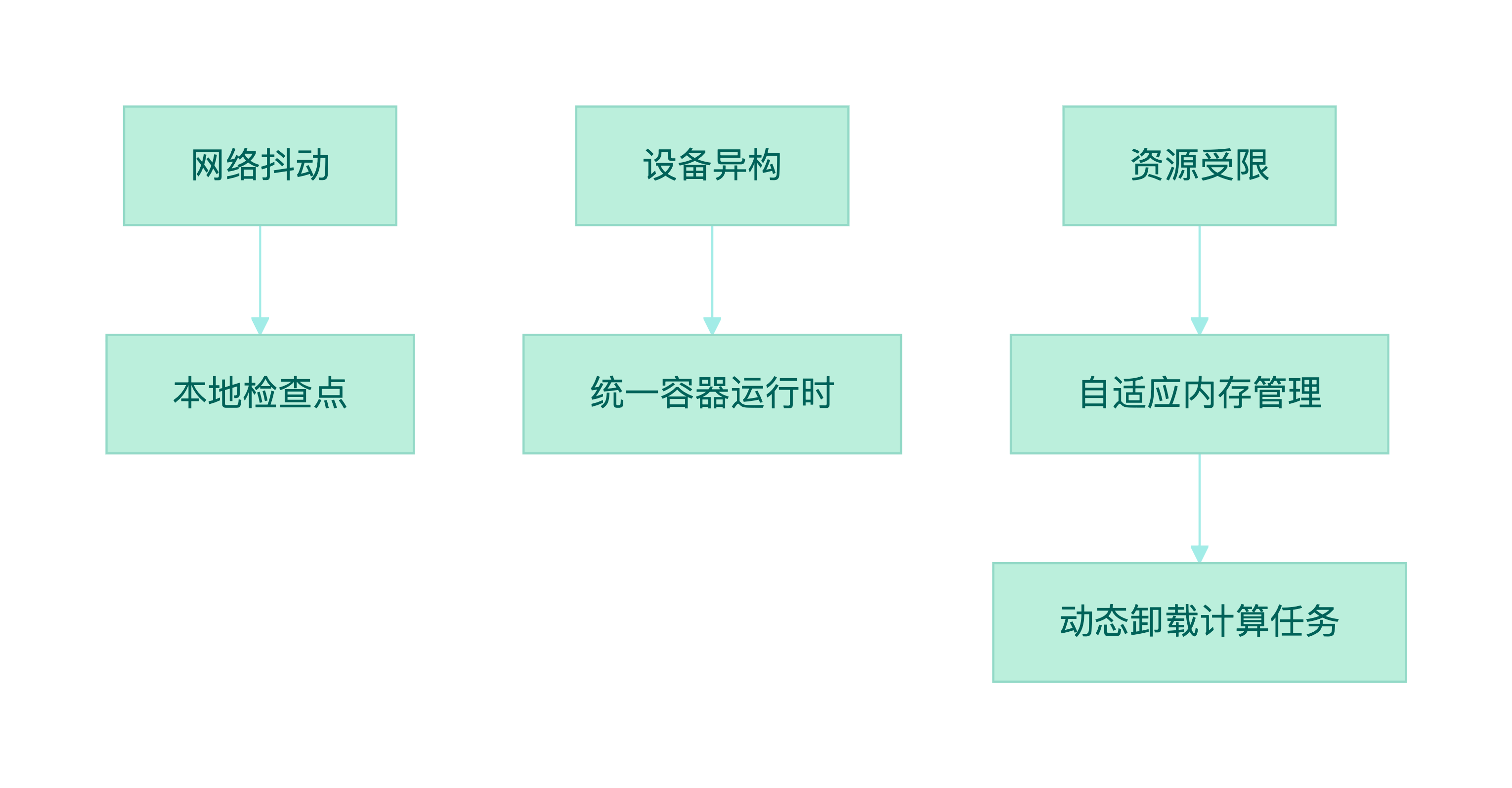
3.2 边缘计算创新实践
四、未来演进方向
- 图神经网络融合:GraphX集成GNN框架实现端到端欺诈检测
- 联邦学习支持:在保护隐私前提下实现边缘模型协同训练
- 硬件加速生态:集成NPU/GPU支持边缘AI推理
- 跨域数据治理:Project Nessie实现中心-边缘统一元数据管理
据IDC预测,到2027年:
- 70%的边缘计算场景将采用Spark架构
- 金融风控图计算市场规模将突破$200亿
- Spark边缘节点部署量将达3000万台
结语
Spark生态在GraphX图计算和边缘计算领域的深度扩展,彰显了其作为全域计算平台的强大生命力:
- GraphX 通过关联图谱分析实现金融风险的深度穿透
- Spark IoT Edge 在边缘端实现"数据智能过滤,价值精准上传"
- 核心技术共性:减少数据移动、提升处理时效、降低总体成本
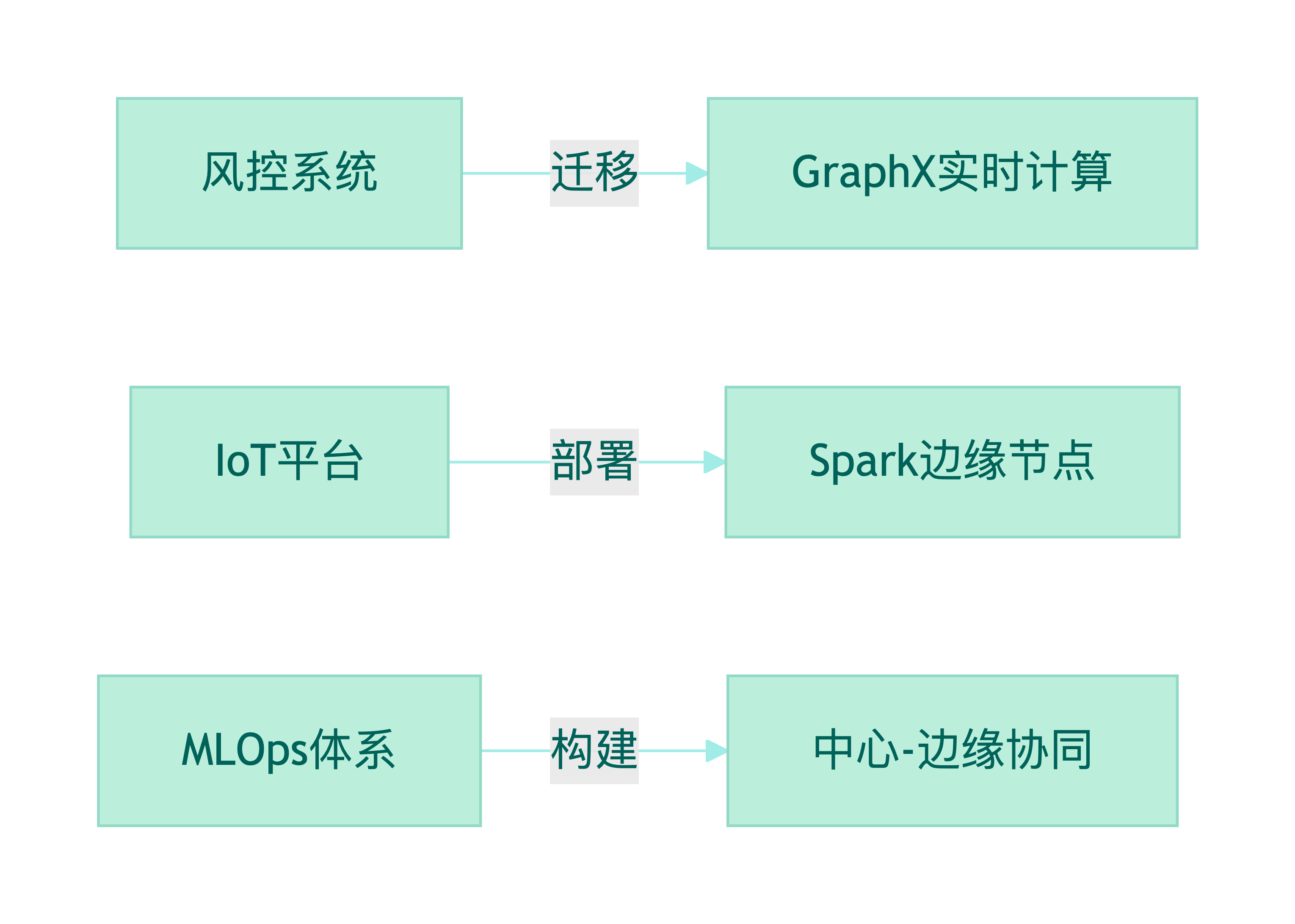
建议企业从三方面布局:
随着Spark 3.5对边缘场景的深度优化及图神经网络的融合,开发者将获得更强大的工具应对数字化挑战。Spark正从"数据中心框架"蜕变为连接云端与边缘的"全域智能计算中枢"。
作者:道一云低代码
作者想说:喜欢本文请点点关注~
更多资料分享