自动驾驶中的传感器技术38——Lidar(13)
本文对Lidar的后端感知算法进行总结:Lidar Perception Agorithms
1、Lidar 感知任务分类
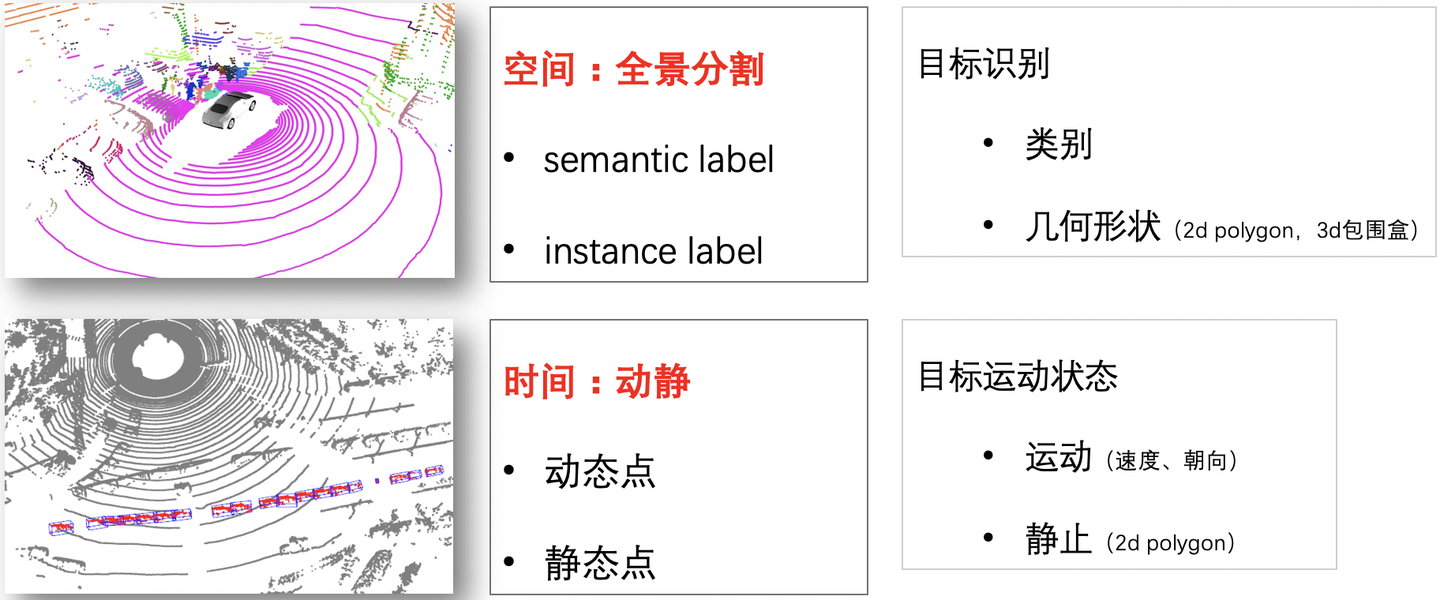
激光雷达感知,以空间的视角来看单帧点云,是在做全景分割:即每个点有一个语义类别,同时有instance label。能够区分地面、植被、建筑物等背景,也能检测出车辆、行人、自行车等目标。
以时间的视角来看多帧连续的点云,是在动静态的分析。浅层的信息:得到每个点在(x,y,z)三个方向在t时间的运动距离,得到每个点是静止还是运动。深层信息:得到目标的运动状态,例如位置、速度、朝向、角速度、加速度等。
Ref:第三章:激光雷达感知功能开发_Apollo开发者社区
Ref:https://www.researchgate.net/publication/349835478_A_Simple_and_Efficient_Multi-task_Network_for_3D_Object_Detection_and_Road_Understanding?_tp=eyJjb250ZXh0Ijp7ImZpcnN0UGFnZSI6Il9kaXJlY3QiLCJwYWdlIjoiX2RpcmVjdCJ9fQ
归纳以上:Lidar感知任务主要分为两大类
A. 基于激光雷达的物体检测
B. 道路理解
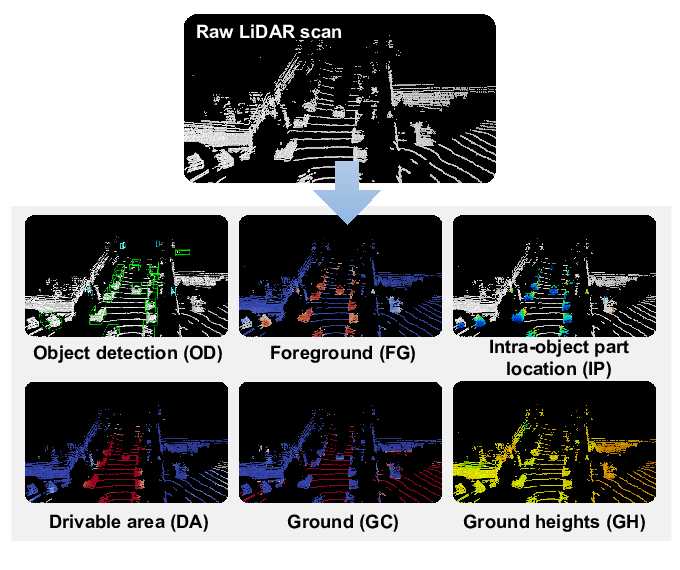
细分后,即 3D 物体检测 (Object Detection)、前景分类 (Foreground Classification)、可行驶区域分类 (Drivable Aera/Space)、地面区域分类 (Ground Area Classification) 和地面高度回归 (Ground Height Regression)。
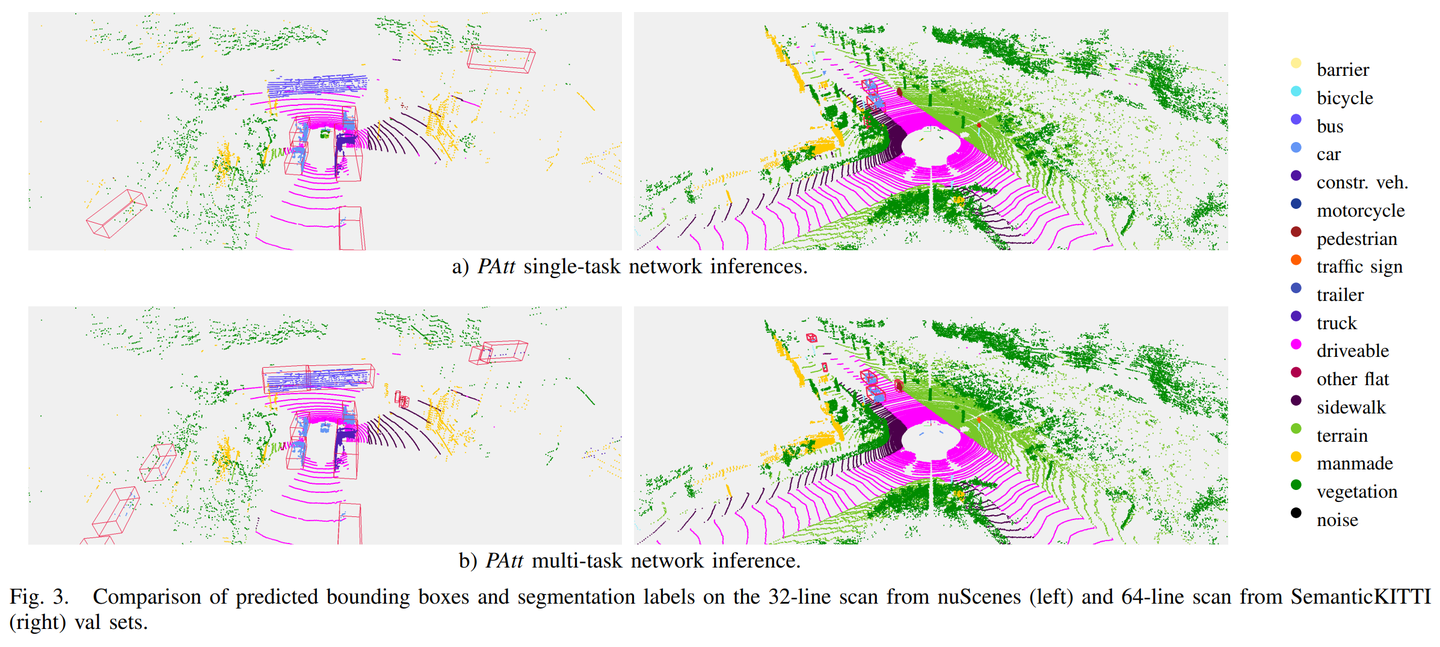
Ref:https://arxiv.org/pdf/2404.12798
2、Lidar Perception General Pipeline
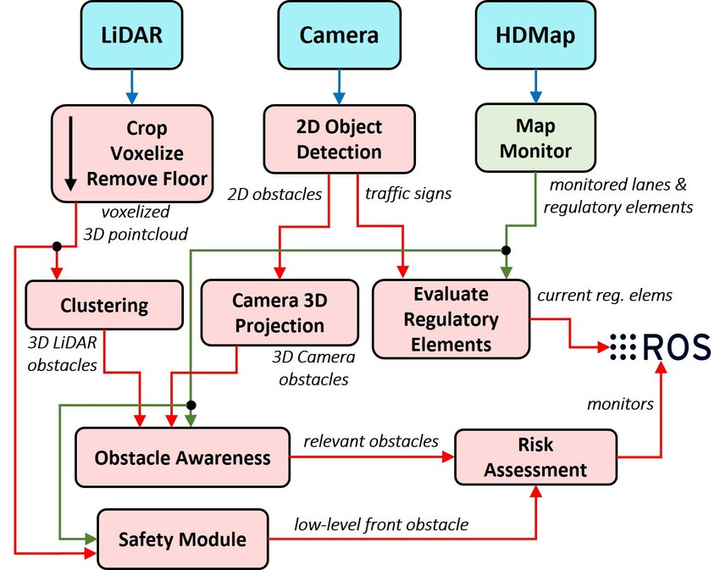
Lidar Perception Pipeline可以参考下图的Lidar部分,以及Lidar和Camera融合的一小部分,当然各家的后端感知算法不尽相同,这里只给出了一个General Pipeline。
Ref:https://www.researchgate.net/publication/362964840_How_to_build_and_validate_a_safe_and_reliable_Autonomous_Driving_stack_A_ROS_based_software_modular_architecture_baseline?_tp=eyJjb250ZXh0Ijp7ImZpcnN0UGFnZSI6Il9kaXJlY3QiLCJwYWdlIjoiX2RpcmVjdCJ9fQ
另外还有基于BEV算法的Lidar感知Pipeline如下
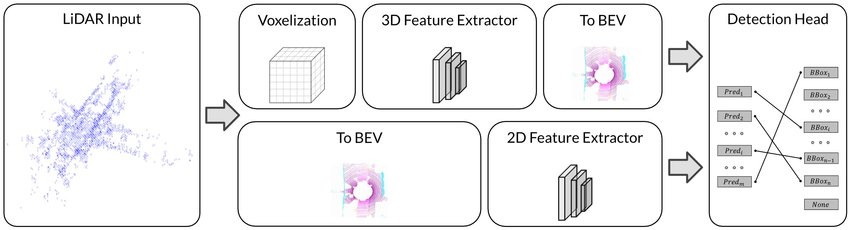
Ref:https://www.researchgate.net/publication/363501404_Delving_into_the_Devils_of_Bird's-eye-view_Perception_A_Review_Evaluation_and_Recipe?_tp=eyJjb250ZXh0Ijp7ImZpcnN0UGFnZSI6Il9kaXJlY3QiLCJwYWdlIjoiX2RpcmVjdCJ9fQ
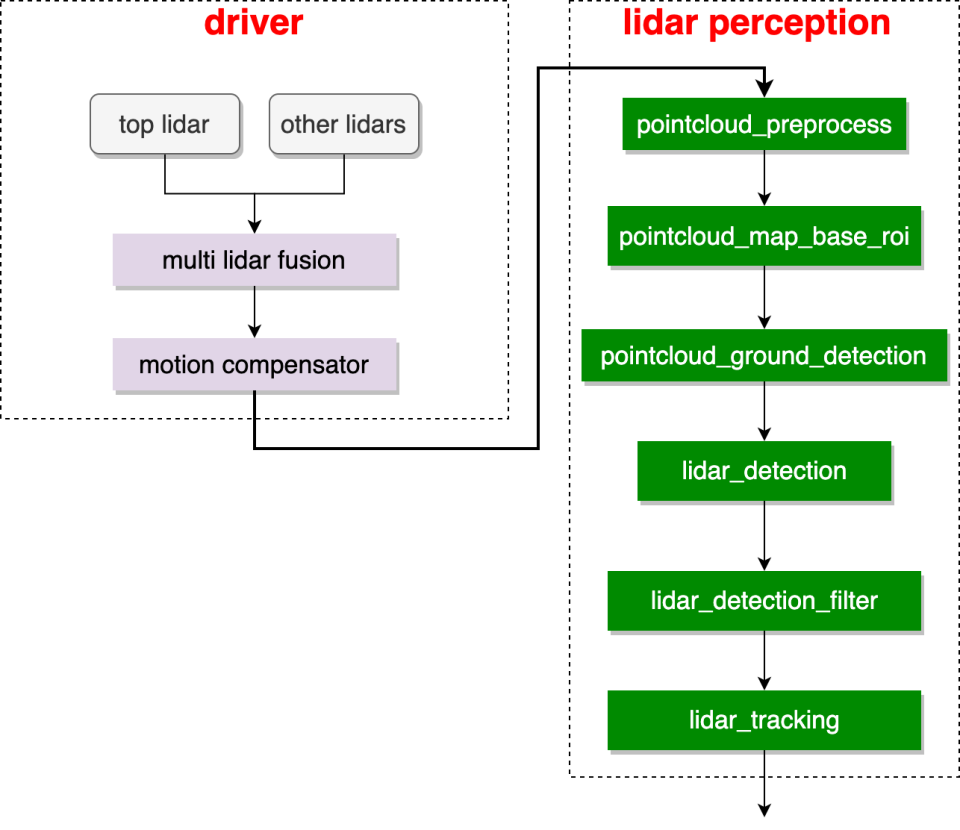
Ref:第三章:激光雷达感知功能开发_Apollo开发者社区
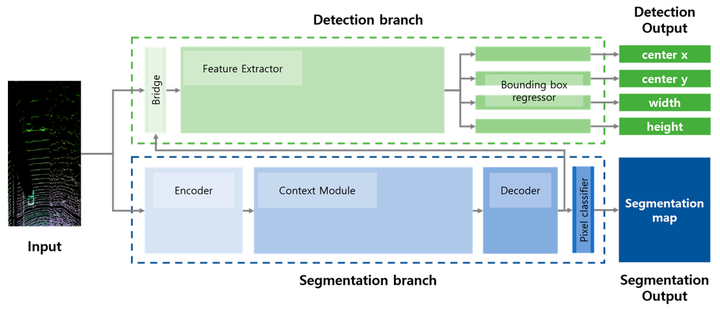
Ref:https://www.mdpi.com/2076-3417/10/13/4486
归纳以上,主要流程节点如下
1、Raw Point Cloud的Crop、Voxelize
原因如下:在复杂环境中,点云的密度可能在不同区域(如开阔区域和狭窄区域)存在显著差异。例如,在开阔区域,点云密度较低,而在狭窄区域,点云密度较高。这种不规则性使得直接处理和分析点云数据变得复杂。所以首选要进行Crop和Voxelize
点云裁剪通常用于去除冗余或不相关的区域,以提高处理效率和精度。例如:
-
去除冗余区域:在自动驾驶或机器人导航中,可能只关注特定区域(如道路、障碍物),而忽略其他区域(如天空、背景)。
-
减少计算负担:通过裁剪,可以减少点云数据量,降低计算复杂度,提高处理速度。
-
提高特征提取效果:在某些情况下,裁剪可以避免噪声或异常点对模型性能的影响。
体素化是将点云数据转换为规则网格(体素)的过程,其主要目的是:
-
统一表示:将不规则的点云转换为规则的体素网格,便于后续处理和分析。
-
减少计算复杂度:通过将点云划分为体素,可以减少计算量,提高处理效率。例如,体素化可以避免对每个点进行单独处理,而是通过体素内的聚合操作(如聚合、采样)来提取特征。
-
保留空间信息:体素化可以保留点云的空间结构信息,同时减少内存占用。
-
适应不同算法需求:许多深度学习模型(如VoxelNet、PointNet++)依赖于体素化表示来提取特征。
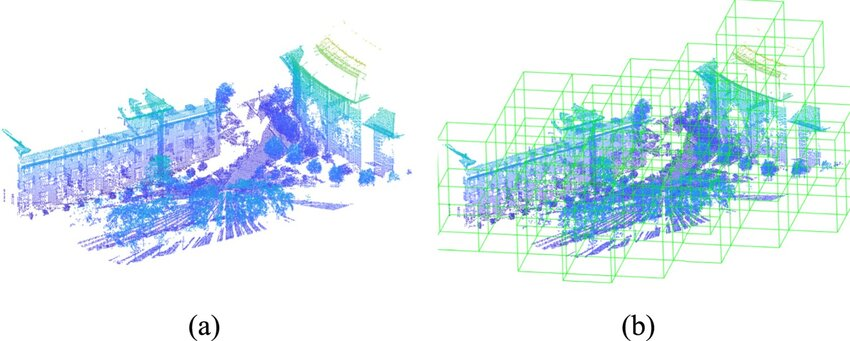
2、Ground Detection and Filtering
自动驾驶中,LiDAR(激光雷达)的地面检测和滤波(Ground Detection and Filtering)是关键步骤,其主要目的是从激光雷达点云数据中分离出地面点,以便后续的障碍物检测和环境感知。
-
去除噪声和冗余数据
-
提高障碍物检测的准确性
-
优化计算效率
-
支持地形建模和环境感知
-
应对复杂环境和挑战
-
提升算法性能

Ref:https://www.mdpi.com/1424-8220/23/2/601
3、动目标检测:详见后文
4、静态检测:详见后文
3、Dynamic Detection
3.1 动态目标检测模型
目前已有多种架构致力于使用激光雷达进行目标检测,尤其是在PointNet之后。PointNet 是第一篇提出稳健模型的论文,该模型可以直接处理激光雷达数据,而无需像其他研究那样将数据转换为其他形式。该模型主要适用于较小激光雷达帧(每帧约 100 个点)的分类和分割任务,而不太适用于大型激光雷达帧,例如近期自动驾驶数据集中使用的激光雷达提供的帧(每帧约 10 万个点)。但它提供了一种直观的理解,以便未来的模型能够将其方法应用于更大的帧,并创建一些目标检测模型。
VoxelNet紧随其后,它提出了一种出色的架构,可以逐个体素地处理大量激光雷达数据,而无需一次处理整个激光雷达帧。它在此“体素处理”步骤中利用 PointNet 的架构,直接从点云中提取特征,然后再通过卷积进行高分辨率特征提取。其检测器是一个两阶段检测器 RPN(区域提议网络)。
SECOND进行了进一步的改进,与 VoxelNet 相比,它只有一个显著的变化。它使用了稀疏 CNN(卷积神经网络),而不是通常只对“非稀疏”数据进行卷积运算的神经网络。考虑到激光雷达帧的数据高度稀疏,这类 CNN 在提高模型速度甚至准确率方面非常有效,因为该模型试图仅从稀疏数据(例如,重要数据)中提取高分辨率特征。
最后一个模型是 Pointpillar,它的方法与 VoxelNet 类似。主要区别在于,该模型不是将点云划分为体素,而是通过仅在 x 轴和 y 轴上(而非 z 轴上)分离整个激光雷达帧来划分柱状图。因此,Pointpillar不是像 VoxelNet 那样将 3D 卷积层应用于 4D 张量输出,而是将 2D 卷积层应用于 3D 张量输出,这可以有效提高模型速度。
为方便进一步学习与阅读,这里将Lidar detection method timeline给出

Ref:https://www.researchgate.net/figure/Chronological-overview-of-the-LiDAR-based-3D-object-detection-methods_fig3_370330738
3.2 跟踪模型架构
Ref:https://arxiv.org/pdf/2012.13755
跟踪机制是利用检测模型如SECOND 多头目标检测模型逐帧得出的结果实现的,模型由三个主要部分组成:
-
卡尔曼滤波器
-
马氏距离计算
-
贪婪匹配算法
使用恒速卡尔曼滤波器计算来自帧 t 的跟踪器在帧 t+1 中的位置,状态向量为 [x, y, z, theta, l, w, h, dx, dy, dz, da],还有一个Box Category,没有在跟踪中体现
xt = [x, y, z, theta, l, w, h, dx, dy, dz] 其中
-
x = 盒子在 x 轴上的中心点
-
y = 盒子在 y 轴上的中心点
-
z = 盒子在 z 轴上的中心点
-
a = 物体面向方向与 x 轴之间的角度
-
l = 盒子的长度
-
w = 盒子的宽度
-
h = 盒子的高度
-
dx, dy, dz = 表示当前帧和前一帧之间 (x, y, z) 的差值。
在此预测步骤之后,再次从目标检测模型中获取第 t+1 帧的测量值。这些检测结果以 1×7 矢量的形式表示为 3D 框位置: detection = [x, y, z, a, l, w, h] 其中 x = 框在 x 轴上的中心点 y = 框在 y 轴上的中心点 z = 框在 z 轴上的中心点 a = 物体朝向与 x 轴之间的角度 l = 框的长度 w = 框的宽度
最后一步是用适当的测量值更新卡尔曼预测位置。为此,需要计算每个卡尔曼预测值和测量值之间的马氏距离。使用贪婪匹配,如果距离最小的检测值尚未被选择,则将测量值与该检测值关联。
如果测量结果不匹配,则会创建一个新的跟踪器对象来存储进入帧 t+1 的这个可能的新对象。
除了这 3 个主要组件之外,还有 3 个重要参数决定跟踪器是否应可视化、存储在系统后台或删除:
hits:统计跟踪器在其整个生命周期内匹配的次数
time_since_last_update :计数跟踪器上次匹配的时间
最大年龄:确定跟踪器在没有匹配的情况下可以存活多长时间的阈值
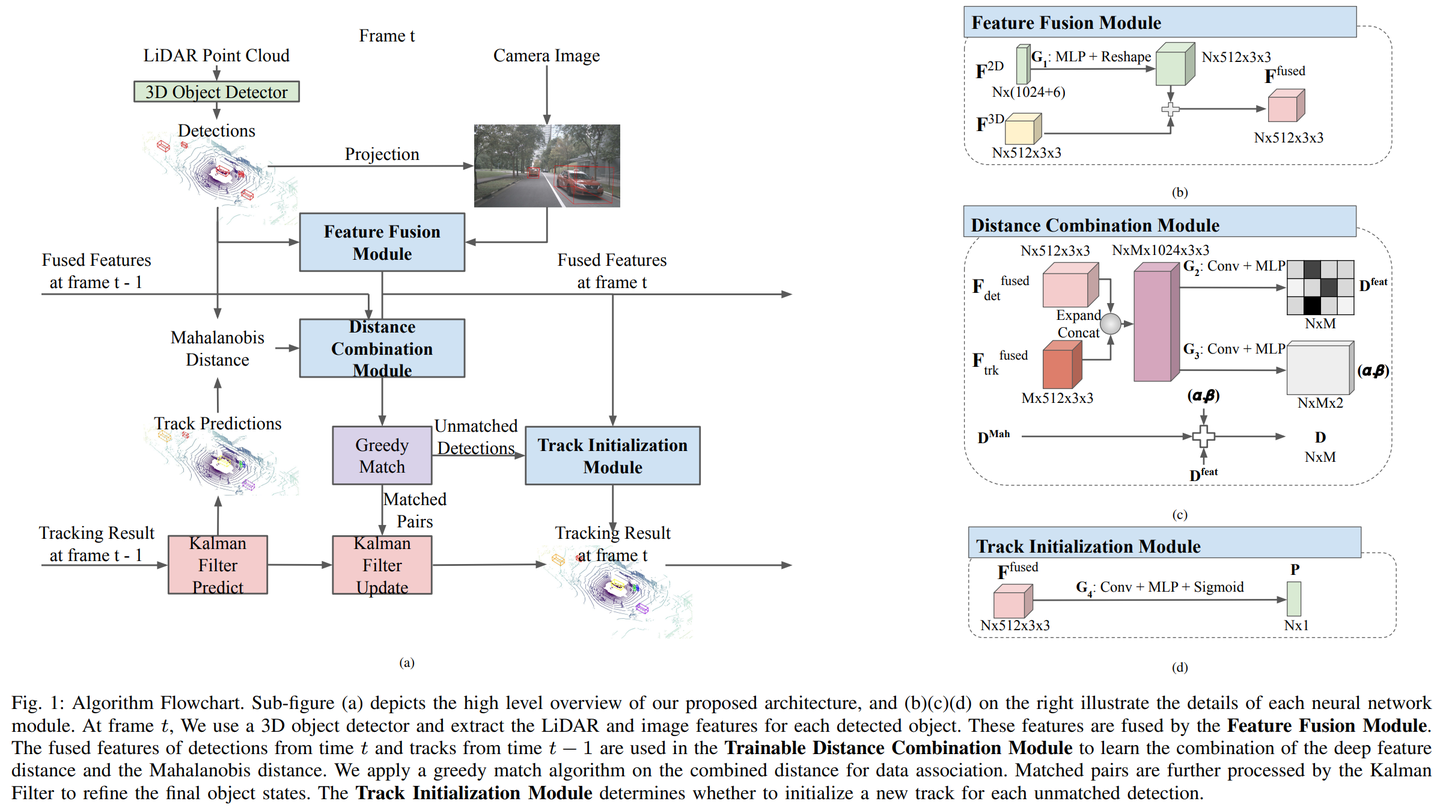
Ref:https://www.kitware.com/3d-multi-object-tracking-using-lidar-for-autonomous-driving/
Ref:https://www.researchgate.net/publication/370330738_3D_Object_Detection_for_Autonomous_Driving_A_Comprehensive_Survey
3.3 Camera-Lidar-Fusion-Dynamic-Object-Detection
该方案可以对camera的动目标检测结果和Lidar的动目标检测结果进行交叉验证。方法很多,需要结合具体工程实践,在自动驾驶中,融合需要调用不同camera的输出进行。
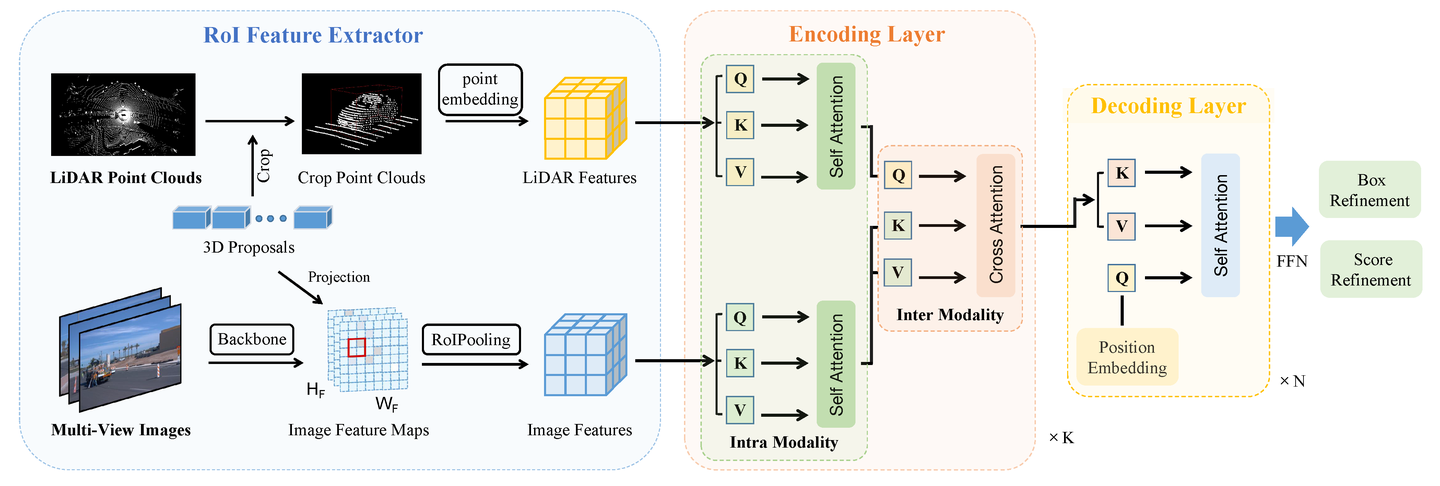
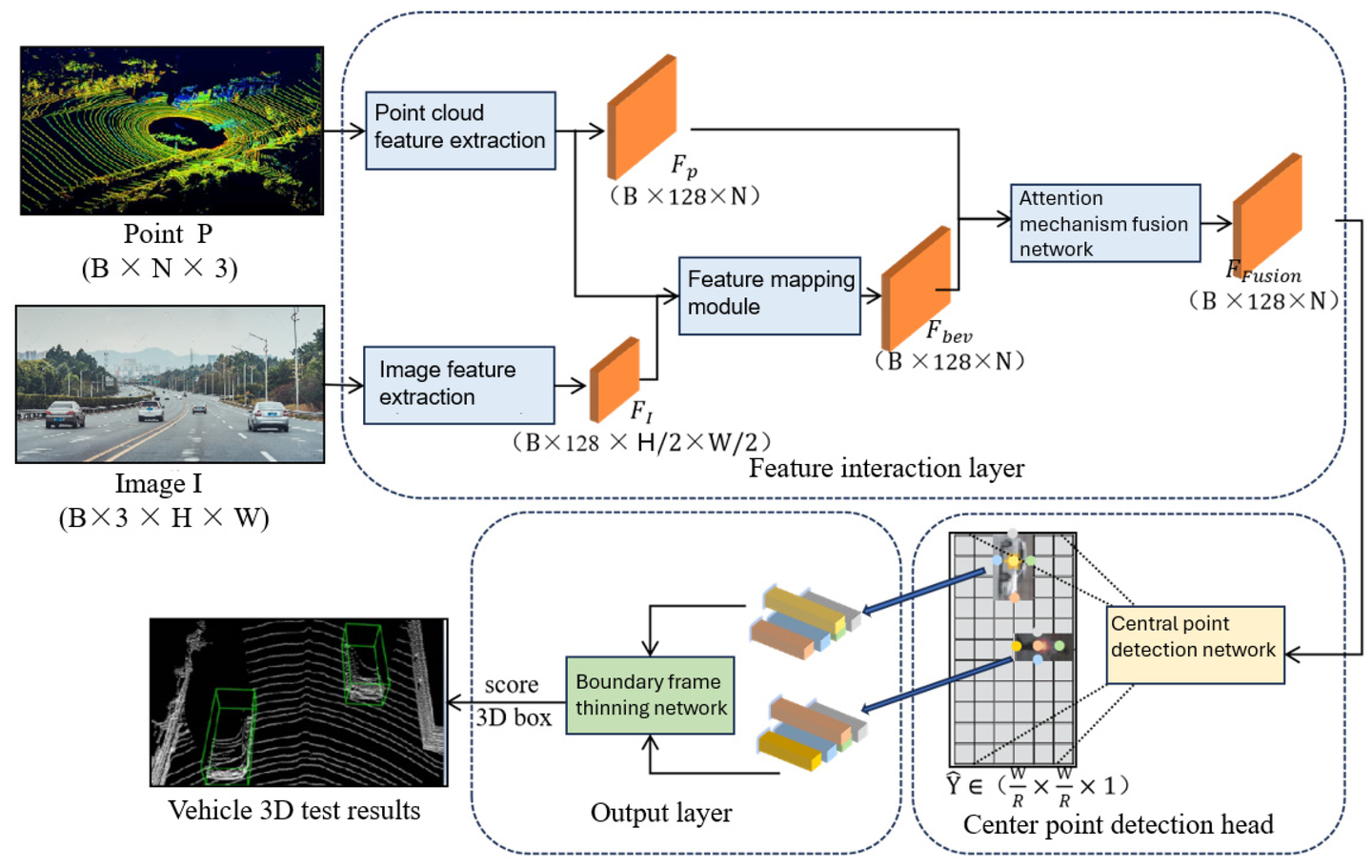
Ref:https://www.mdpi.com/2072-4292/15/7/1839
Ref:https://www.mdpi.com/2032-6653/16/6/306
4、Static Detection
4.1 可通行区域检测
Lidar Drivable Space Detection,此处涉及到几个关键的检测:
-
Detect road boundary
-
Detect common obstacles
-
Cover the bottom of Motion Object Detection
具体方法有如下几种
-
Occupancy Grid
-
Freespace-Centric
-
Polyline
-
Polygon
利用上述方法搭建模型后,需要得到道路边缘,静态目标边缘,可通行区域的方向(顺时针或者逆时针)。
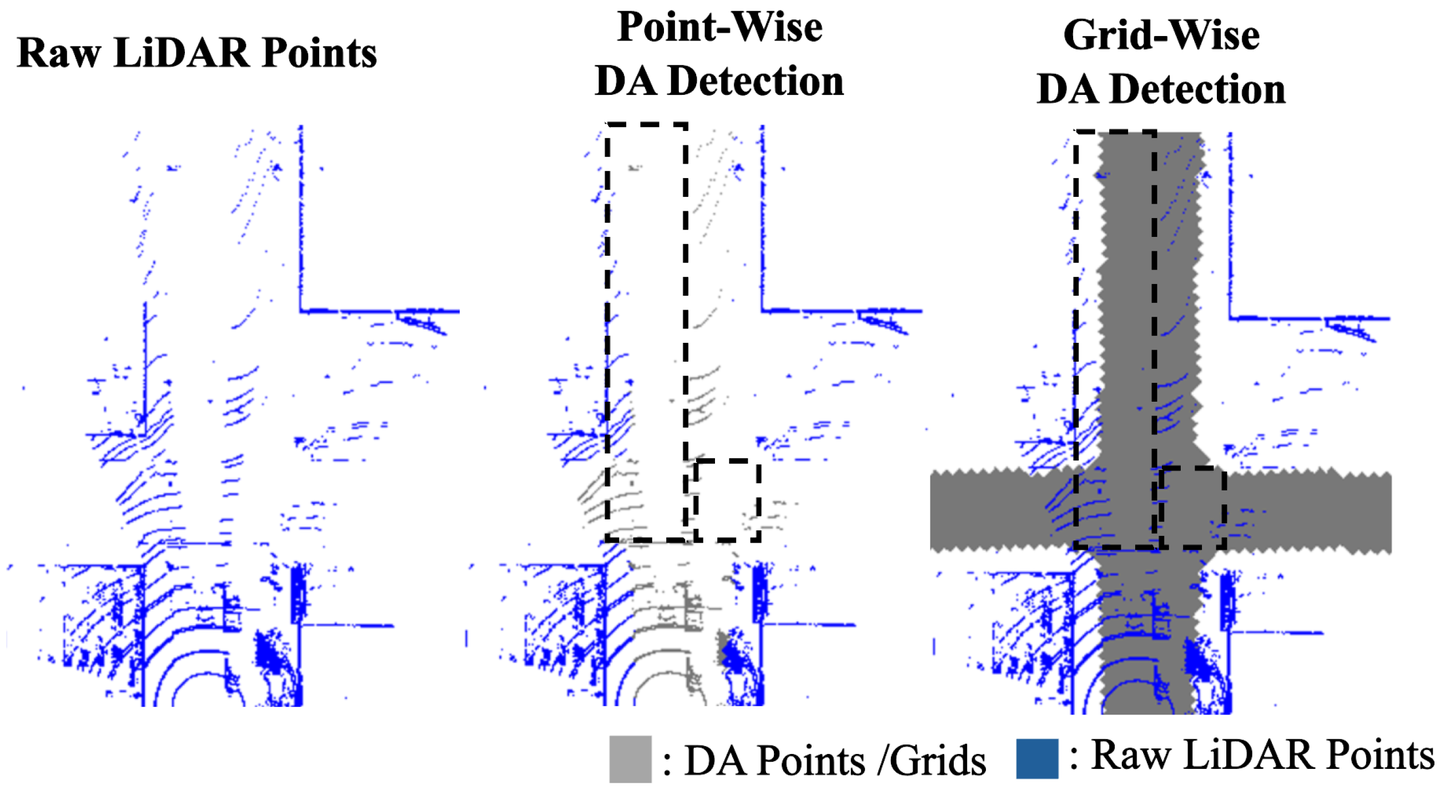
Ref:https://www.mdpi.com/2072-4292/16/20/3777
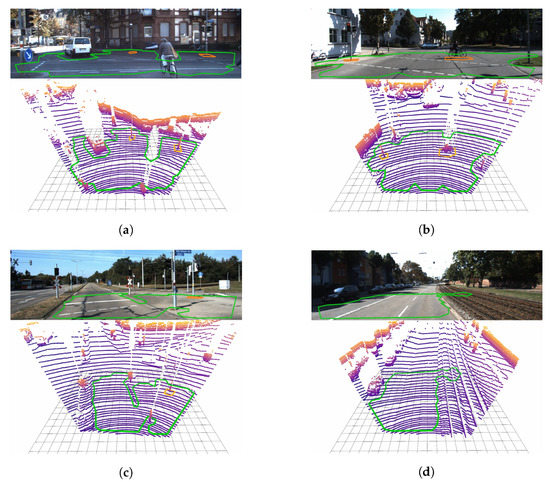
4.2 Camera-Lidar-Fusion-Static-Obstacle-Detection
这里主要是涉及到上一节中的算法和Camera图像的融合。
-
Occupancy Grid
-
Freespace-Centric
-
Polyline
-
Polygon
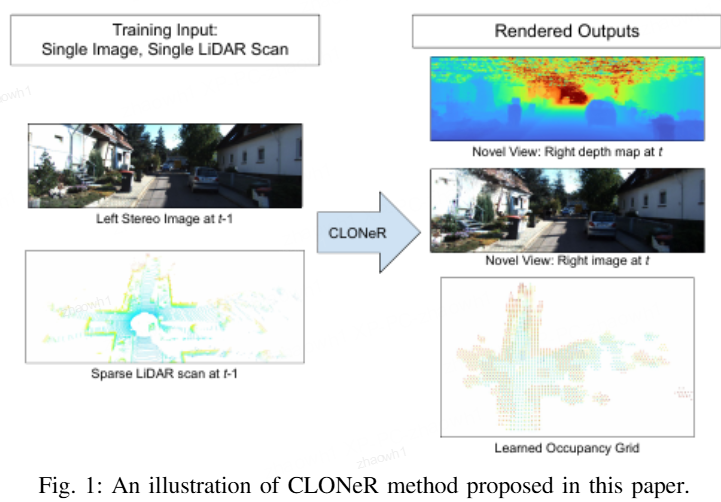
Ref:https://www.researchgate.net/publication/363269483_CLONeR_Camera-Lidar_Fusion_for_Occupancy_Grid-aided_Neural_Representations
Ref:https://www.mdpi.com/1424-8220/20/17/4819
Ref:https://www.thinkautonomous.ai/blog/lidar-and-camera-sensor-fusion-in-self-driving-cars/
5、点云密度与噪声对Detection的影响

也可以在点云中人为增加噪声,来提高算法的鲁棒性。
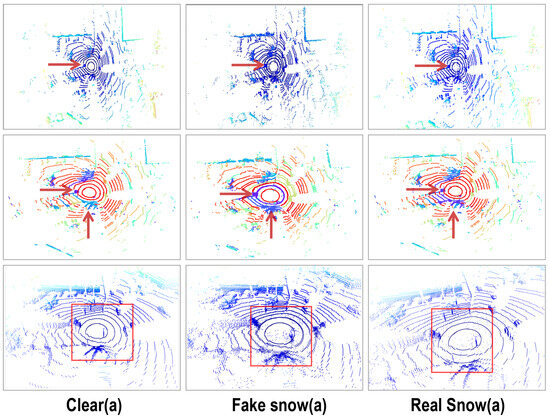
Ref:https://www.mdpi.com/2072-4292/16/12/2247
Ref:雪岭 · 激光雷达常见点云异常场景分析