面向生产环境的大模型应用开发
思维导图
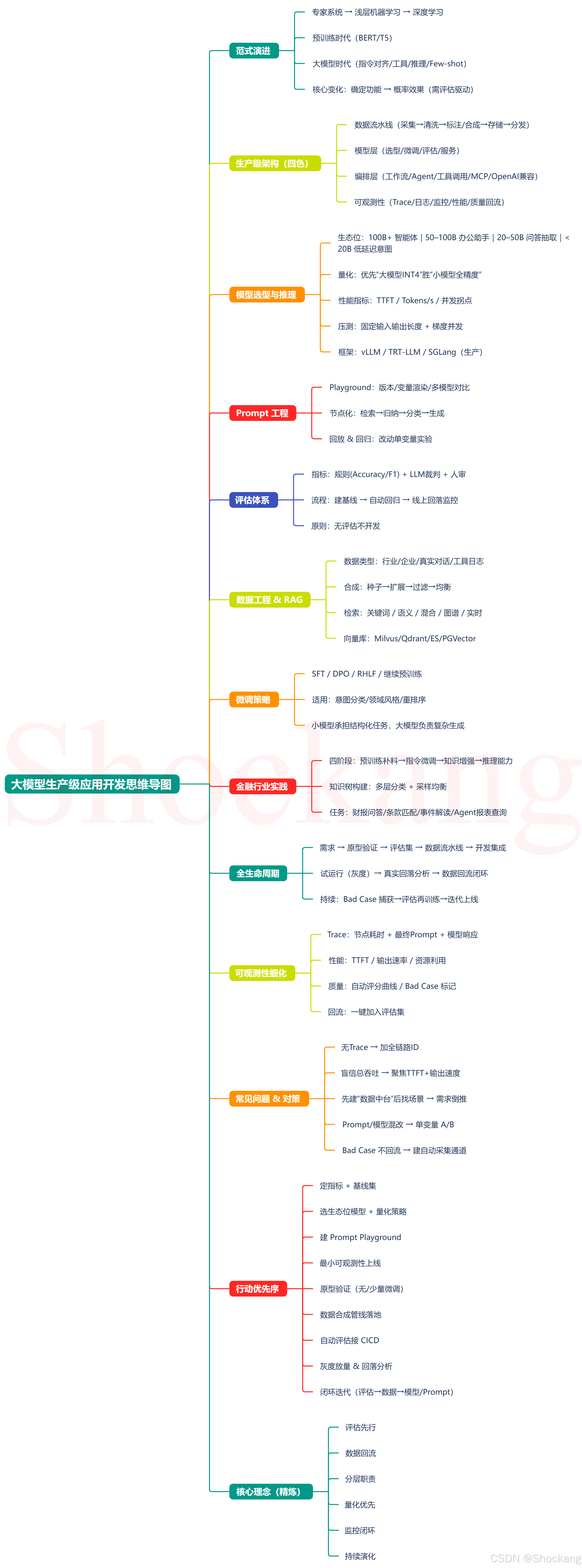
正文
1. 大模型应用开发与传统软件开发的本质差异
- 本质属性:属于机器学习工程(效果概率性)而非确定性的传统软件功能开发。
- 关键区别:
- 传统软件:功能=确定;验收=是否完成。
- 大模型应用:效果=统计分布(如 [Accuracy=85%]),需持续评估与迭代。
- 开发原则:无法量化评估(缺少指标与数据集)→ 不进入实施。
- 典型错误:直接“写功能”而缺少 原型验证 → 评估体系 → 数据基线 → 迭代循环。
- 评估驱动(Evaluation First):评估数据集与指标体系要先于工程落地。
1.1 技术范式演进
| 时代 | 主要特征 | 应用范式 |
|---|---|---|
| 专家系统 | 规则驱动 | 手工规则维护 |
| 机器学习(浅层) | 特征工程 + 任务数据 | 一任务一模型 |
| 深度学习(2012–2018) | 大量任务数据 + 深层网络 | 大规模监督训练 |
| 预训练模型时代(BERT/GPT-2/T5) | 通用语义表示 + 任务微调 | 适量样本微调(千~万条) |
| 大模型时代(ChatGPT 2022+) | 指令对齐 + 泛化 + 工具使用 + 推理 | Few-shot / Prompt 直接调用或少参适配器微调 |
1.2 现代大模型新增能力(课程强调)
- 接受自然语言指令(指令对齐)
- 泛化至未显式训练任务
- 工具/插件/外部 API 交互
- 推理与多步规划能力
- 少量增量微调(Adapter/LoRA 等)或纯 Prompt 使用
2. 生产级大模型应用总体架构(四色分层)
架构核心由四类组件协作:数据(黄)、模型(红)、编排(蓝)、可观测性(绿)。
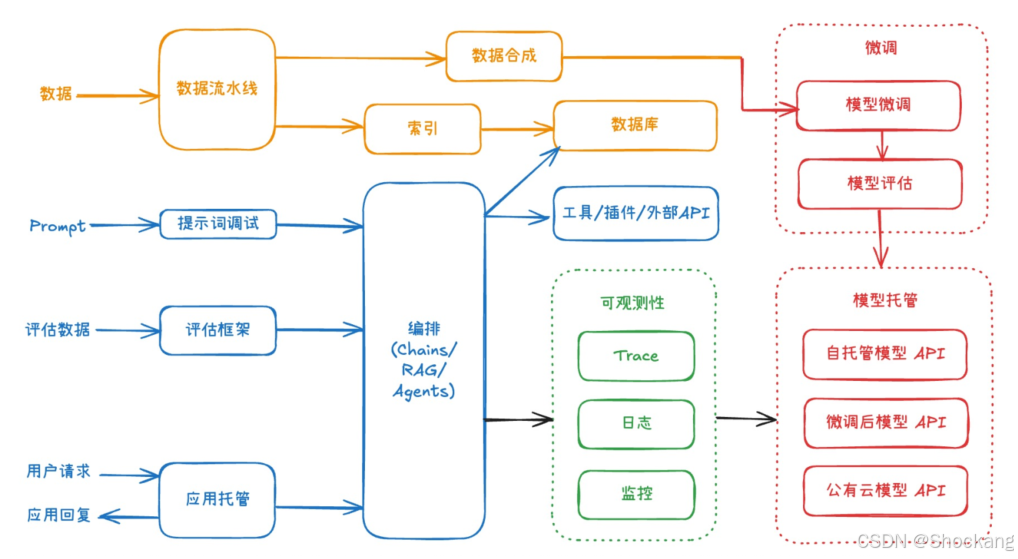
2.1 数据流水线(黄)
- 输入源:行业语料 / 企业业务数据(结构化 + 非结构化)
- 处理:采集 → 清洗 → 转格式(含 OCR)→ 标注/合成 → 存储 → 分发
- 适用:预训练补料 / 微调(SFT、RHLF、DPO)/ 评估集 / RAG 知识库 / Agent 数据
2.2 模型层(红)
- 包含:模型选择、轻量或全参微调、效果评估、推理服务托管
- 即便“不微调”亦需:在特定提示词集合或任务集上做离线/对比评估
2.3 编排层(蓝)
- 作用:工作流 / Agent / 多工具调用 / API 抽象
- 现状:模型 API 已高度统一(OpenAI 兼容);编排更多集中于内部逻辑 DSL、节点依赖、工具协议(含 MCP)
2.4 可观测性(绿)
- 必要性:复杂工作流(可达 100+ 节点)若无 Trace 难以定位延迟与错误
- 需记录:每阶段 输入/输出/耗时/模型响应/提示词最终渲染版本
- 故障案例:ES 索引未优化 → 查证延迟,被 Trace 定位而非误判为“模型慢”
- 三层要素:
- Trace(调用链、节点级耗时、提示词最终文本)
- Logging(结构化日志、有问题 Case 复现能力)
- Monitoring(TTFT、Tokens/s、吞吐、错误率、资源利用率、线上效果评估趋势)