HashMap高频面试题目
1:hashmap底层的数据结构是什么?
答:在jdk1.7之前,hashmap的底层是数组(主体)+链表,jdk1.8之后采用数组+链表+红黑树。
链表和红黑树是解决哈希冲突的。
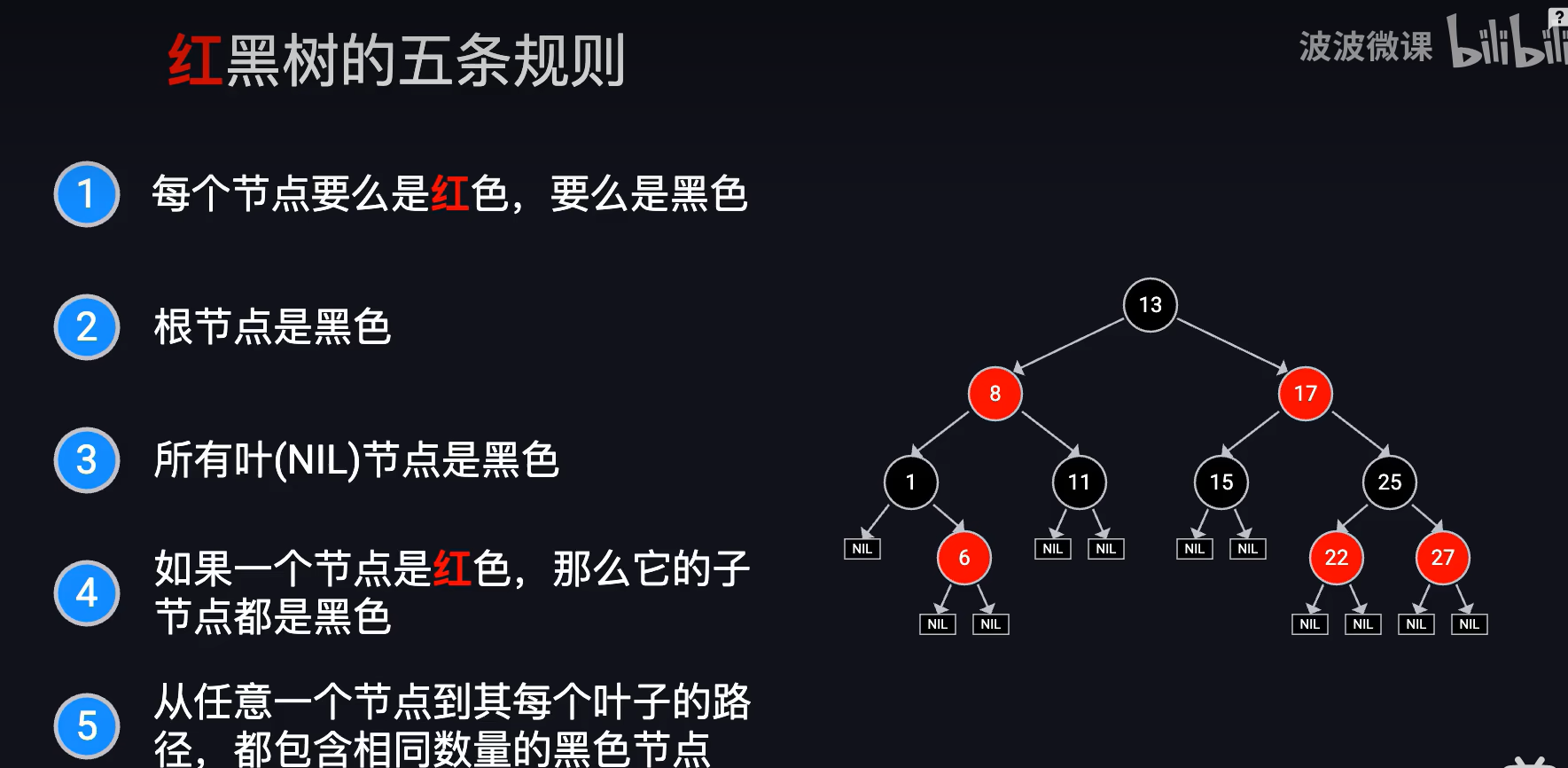
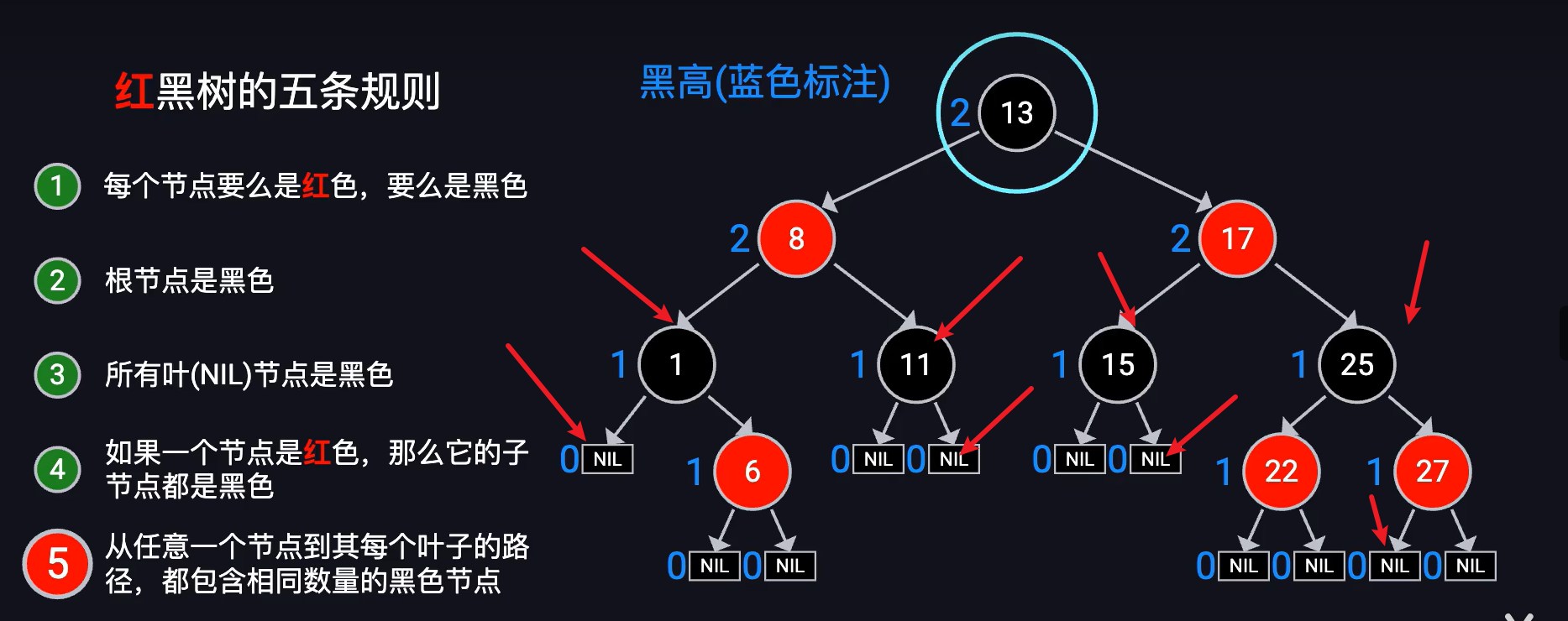
包含nil节点 不包含13本身。
hashmap图片
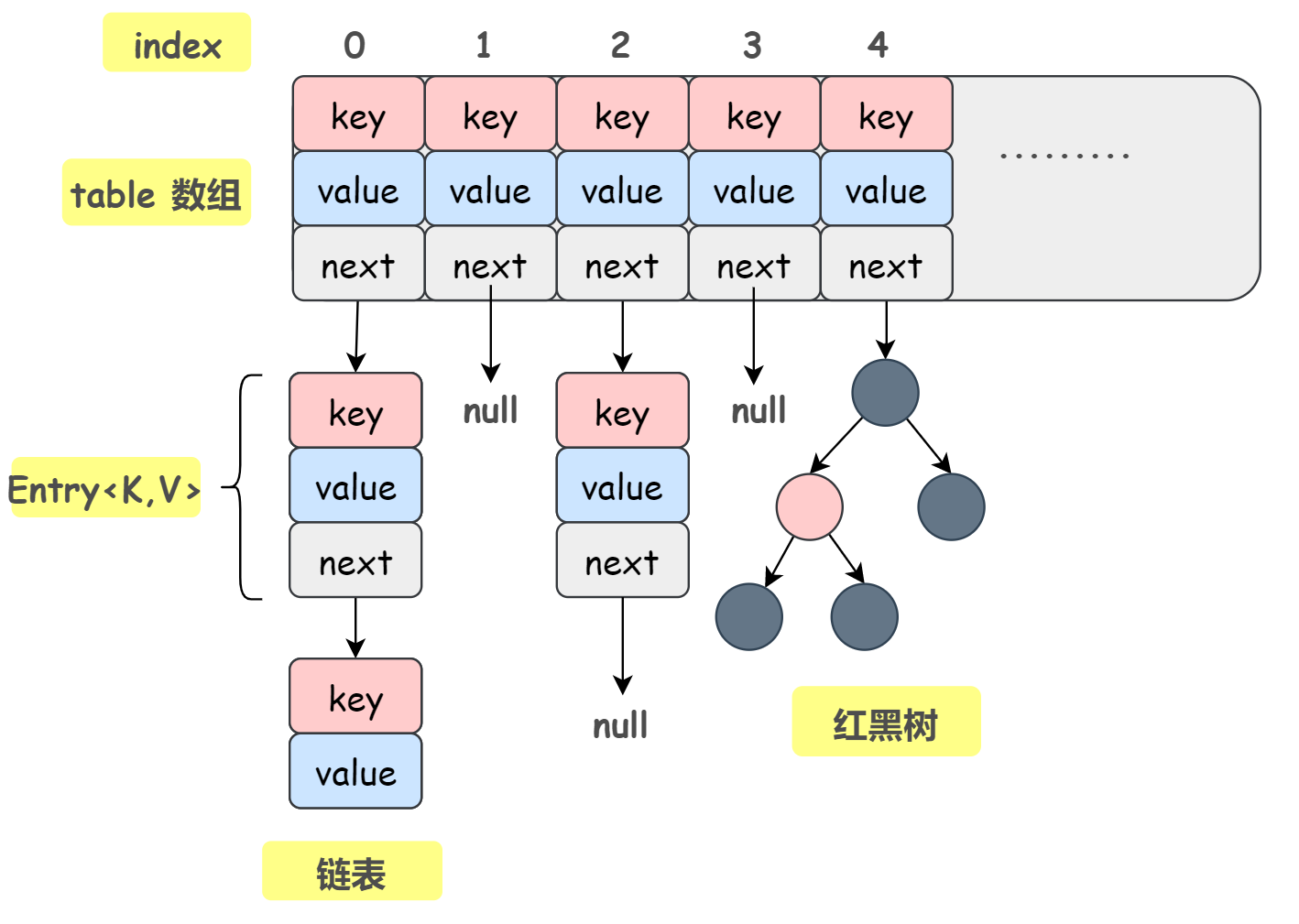
2:为什么既要链表又要红黑树?
jdk1.8开始,如果链表太长,就会转化成红黑树,因为红黑树可以在最坏查找情况下,将复杂度从O(n)降低至O(logn) 提升效率。
3:为什么使用红黑树,不使用avl树(完全意义的平衡)
因为avl树是严格平衡的二叉树,维护代价较高,而红黑树相比之下,代价较小,是最佳的折中实践。
4:红黑树这么厉害,为什么还留着链表?
因为红黑树比链表,需要占用更多的空间,红黑树节点大小是普通节点大小的两倍,能省则省。
5:那链表什么时候转化为红黑树?
当链表长度大于等于8并且数组长度大于等于64的时候。
6:为什么数字要大于等于64?
主要是为了避免频繁的树化和减少内存占用,数组容量少的时候,扩容自然会减少哈希冲突,且容量小的时候更容易扩容,如果过早树化,可能里面又扩容了。那白树化了,同时为了减少内存(红黑树节点大小是普通节点大小的两倍)
7:那当链表长度大于等于8并且数组长度小于64的时候会怎么样?
扩容。
8:为什么是8作为链表转化红黑树的其中一个条件?
源码中好像是跟泊松分布有关,因为红黑树占用内存大,能不用就不用,在默认负载因子0.75下,链表冲突刚刚好,到8的几率其实很低,基本上不会触发,这其实是一个时间效率和空间占用平衡之间的最佳的折中实践。
9:如果链表 转为了红黑树,还会转回来吗?
会的,当红黑树的节点小于6的时候,会从红黑树转化为链表。节点少的花,链表遍历也很快,没必要使用红黑树。
当链表长度超过 TREEIFY_THRESHOLD (默认8)且满足 MIN_TREEIFY_CAPACITY 时,会触发红黑树转换。而当红黑树节点数量因删除操作降至 UNTREEIFY_THRESHOLD (默认6)以下时,则恢复为链表。 23
10:为什么定了6而不是直接小于等于8就变回链表?
留一个缓存余地,避免反复横跳,减少树化和反树化的开销。(防止在节点处继续持续的增删)
11:为什么默认的负载因子是0.75?
为了时间和空间的平衡,
设置的比0.75低,那么冲突少,查的快,但是扩容频繁。
设置的比0.75高,省空间,但查得慢。
0.75是实践下来的比较折中的选择。
12:你说为什么是插入到尾部,而不是头部?那尾插法就不会成环了吗?
1.7之前使用的是头插法,18使用尾插法。如果多线程实施put操作,可能会导致链表成环,导致死循环。
红黑树也还会成环,本来就不应该在多线程下使用hashmap。
13:那你说说hashmap的扩容机制。
初始容量是16,默认负载因子是0.75,因此默认扩容阈值是
16*0.75=12。理论上插入第13个元素就会扩容,扩容就是新建一个两倍大小的数组,然后把原来元素重新hash迁移。
14:为什么扩容是扩容前的两倍?
容量始终保持为2的幂,这样可以通过(n-1)& 上hash 运算,快速定位到数组下标,减少冲突,比直接取余运算效率高。
15:如何解决hash冲突
哈希冲突的通用解决方式
- 开放地址法:是指当发生冲突时,在数组中寻找下一个可用的空位。常见的探测方式有线性探测、二次方探测等。
- 链地址法(拉链法):是指在冲突位置拉出一个数据结构(通常是链表),然后将所有冲突的元素都存放在这个数据结构中。
HashMap对于哈希冲突的解决方案
- HashMap采用的是链地址法。并且在 JDK 1.8 中进行了优化:当链表的长度超过树化阈值 8 时,会自动将链表转换为红黑树,以将极端冲突情况下的查询时间复杂度从 O(n) 降低到 O(log n)。