[网络入侵AI检测] 纯卷积神经网络(CNN)模型 | CNN处理数据
第5章:纯卷积神经网络(CNN)模型
欢迎回来
在第1章:分类任务配置(二分类 vs. 多分类)中,我们学习了如何提出正确的问题;
在第2章:数据加载与预处理中,我们准备好了数据"食材";
在第3章:经典机器学习模型中,我们探索了传统工具;
在第4章:深度前馈神经网络(DNN)模型中,我们首次使用多层神经网络深入研究了深度学习
DNN非常擅长发现复杂模式,但想象一下,如果安全专家不只是查看单个特征,而是尝试在事件流中发现特定的序列或形状
例如,某些网络标志的快速连续出现可能表明扫描攻击,而较慢、更谨慎的模式则暗示另一种入侵类型
这正是纯卷积神经网络(CNN)模型的用武之地
虽然CNN以图像识别(检测边缘、形状和物体)而闻名,但它们也非常擅长在数据序列中发现局部模式,即使这些数据不是图像。
在我们的网络入侵检测(NID)项目中,CNN就像专门的"模式检测器",在做出决策前系统地扫描网络流量特征中的重要局部序列或"签名"。
CNN解决了什么问题?
CNN旨在直接从输入数据中自动学习层次化特征和模式。
与DNN平等对待每个输入特征并一次性混合它们不同,CNN使用"过滤器"扫描数据,首先挑选出小的特定模式,然后将这些小模式组合成更大、更复杂的模式。
我们使用CNN的核心用例是从41个网络特征序列(来自第2章:数据加载与预处理的input_shape=(41, 1))中自动提取这些局部有意义的模式,将网络连接分类为"正常"或"攻击"(二分类),或精确定位"攻击类型"(多分类)。它们特别擅长发现可能出现在特征序列中任何位置的"签名"。
CNN的关键概念
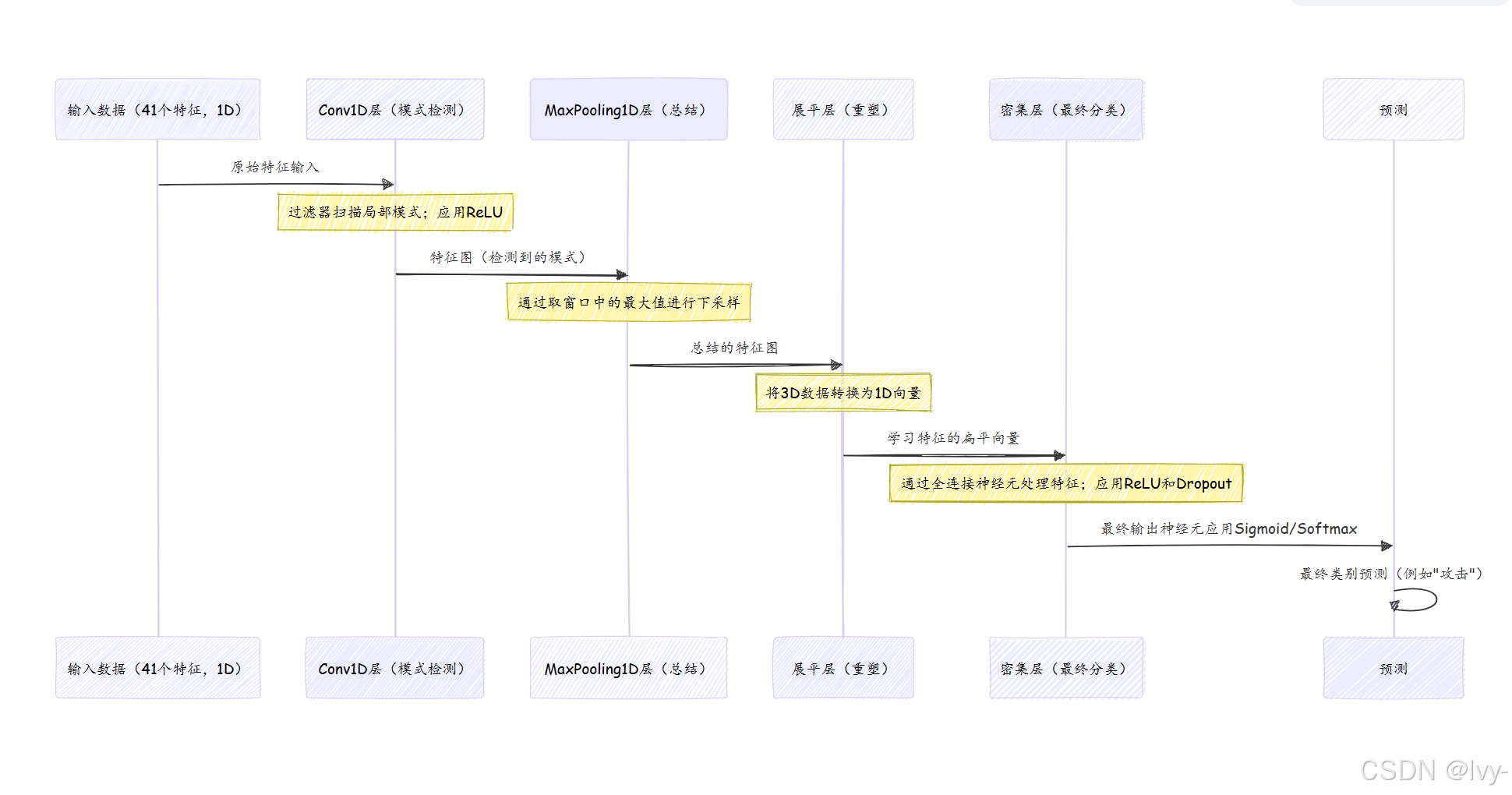
纯卷积神经网络(针对我们的一维网络数据)主要使用三种类型的层:卷积层、池化层,然后是展平后的密集层。
让我们分解这些核心部分:
1. 卷积层(Conv1D):模式检测器
这是CNN的核心。
- 过滤器(核):想象一个小的"放大镜"或迷你模式检测器。这个过滤器是一个小窗口,在输入数据(我们的41个特征)上滑动。当它滑动时,它会与看到的数字进行数学运算(卷积),寻找特定模式。例如,一个过滤器可能被训练来检测数据中的"尖峰",另一个可能寻找"低谷"。
- 特征图:卷积层的输出。每个过滤器创建自己的"特征图",显示它在输入数据中检测到其特定模式的位置。如果一个过滤器擅长检测"尖峰",其特征图将在发现尖峰的地方有高值。
- 1D卷积:由于我们的网络数据是41个特征的序列,我们使用
Convolution1D。这意味着我们的"放大镜"沿单一维度滑动,扫描我们的特征序列。 activation='relu':就像在DNN中一样,在卷积之后应用relu激活(第4章:深度前馈神经网络(DNN)模型)以引入非线性,使模型能够学习复杂关系。
2. 池化层(MaxPooling1D):总结器
在卷积层检测到模式后,池化层有助于简化信息并使模型更鲁棒。
- 下采样:
MaxPooling1D层通过在特征图上滑动窗口并取每个窗口中的最大值来工作。这有效地缩小了特征图,减少了数据量,同时保留了最重要的信息(最强的模式检测)。 - 鲁棒性:通过取最大值,它使模型对模式的确切位置不那么敏感。如果"尖峰"模式稍微移动,
MaxPooling层仍然可能捕捉到它的存在。 pool_length:这定义了池化层使用的窗口大小。pool_length为2意味着它查看2个值的组并选择最大的。
3. 展平层:为决策做准备
卷积和池化层以"网格状"或"序列状"格式(例如[samples, new_length, new_features])输出数据。然而,做出分类决策的最终密集(全连接)层需要一个简单的数字扁平列表。
展平层完全如其名:它将卷积/池化层的3D输出"展平"为一个长的1D向量(就像展开地毯)。这为数据输入标准密集分类层做好准备。
4. 密集层:最终分类器
在展平层之后,我们添加一个或多个密集层,就像在DNN中一样(第4章:深度前馈神经网络(DNN)模型)。这些层利用卷积和池化层提取的抽象特征做出最终分类决策。
5. Dropout层:防止过拟合
与DNN一样,添加Dropout层(第4章:深度前馈神经网络(DNN)模型)以防止模型对训练数据记忆得太好。这确保它可以泛化到新的、未见过的网络流量。
如何构建用于入侵检测的纯CNN
我们将使用Keras构建我们的CNN。基本步骤如下:
- 启动一个
Sequential模型。 - 添加
Convolution1D层:定义过滤器数量、核大小和激活。 - 添加
MaxPooling1D层:对特征图进行下采样。 - 添加
展平层:将输出转换为密集层。 - 添加
密集层:用于最终分类,使用relu激活。 - 添加
Dropout层:防止过拟合。 - 添加最终的
密集输出层:根据第1章:分类任务配置(二分类 vs. 多分类)配置为二分类或多分类。 - 编译模型:定义损失函数、优化器和指标。
记住,我们的输入数据需要重塑为[samples, time_steps, features],对于我们的KDD数据集是[number_of_connections, 41, 1]。
这在第2章:数据加载与预处理中已经介绍过。
让我们看一个简化示例。假设X_train包含我们归一化和重塑的网络特征,y_train包含标签,如第2章和第1章所述。
示例代码:用于二分类的简单CNN
以下是构建一个带有一个卷积块的基本CNN用于二分类入侵检测的方法:
from keras.models import Sequential
from keras.layers import Convolution1D, MaxPooling1D, Flatten, Dense, Dropout
import numpy as np # 用于数据创建示例# --- 假设 X_train 和 y_train 已准备好并重塑 ---
# 为了演示,我们创建一些虚拟数据(1000个样本,41个时间步,每个1个特征)
X_train_dummy = np.random.rand(1000, 41, 1)
y_train_dummy = np.random.randint(0, 2, 1000) # 二分类标签# 1. 开始定义网络(层的堆叠)
model = Sequential()# 2. 添加第一个卷积层
# - 64个过滤器:64个不同的小模式检测器
# - kernel_size=3:每个过滤器一次查看3个连续特征
# - activation='relu':如前所述
# - input_shape=(41, 1):告诉Keras我们的输入形状(41个时间步,每个时间步1个特征)
model.add(Convolution1D(64, 3, activation="relu", input_shape=(41, 1)))# 3. 添加一个最大池化层
# - pool_size=2:在2的窗口上取最大值
model.add(MaxPooling1D(pool_size=2))# 4. 展平输出以用于密集层
model.add(Flatten())# 5. 添加一个密集层(全连接)进行更多处理
# - 128个神经元
# - activation='relu'
model.add(Dense(128, activation="relu"))# 6. 添加一个Dropout层以防止过拟合
# - 0.5表示训练期间随机关闭50%的神经元
model.add(Dropout(0.5))# 7. 添加输出层(用于二分类,如第1章所述)
# - 1个神经元用于二分类输出
# - activation='sigmoid':将输出压缩为0到1之间的概率
model.add(Dense(1, activation="sigmoid"))# 8. 编译模型
# - loss='binary_crossentropy':用于二分类
# - optimizer='adam':流行的优化算法
# - metrics=['accuracy']:跟踪性能
model.compile(loss="binary_crossentropy", optimizer="adam", metrics=['accuracy'])print("CNN模型创建并编译完成!")
model.summary() # 打印模型层和参数的摘要
解释:
Sequential():初始化我们的模型为层的堆叠。Convolution1D(64, 3, activation="relu", input_shape=(41, 1)):这是第一层。它使用64个过滤器,每个查看3个相邻特征的窗口。input_shape对第一层至关重要。MaxPooling1D(pool_size=2):该层通过保留最重要的信息(最强的模式检测)来减小特征图的大小。Flatten():这将卷积/池化层的输出准备好用于后续的常规密集层。Dense(128, activation="relu"):一个标准的隐藏层,用于进一步处理展平的特征。Dropout(0.5):帮助防止模型过拟合。Dense(1, activation="sigmoid"):用于二分类的最终输出层,给出0到1之间的概率。model.compile(...):使用适当的损失函数和优化器配置模型进行训练。
扩展到多个卷积块和多分类
通过堆叠更多的Convolution1D和MaxPooling1D块,可以使CNN"更深"。对于多分类,只有输出层和损失函数会改变,如第1章:分类任务配置(二分类 vs. 多分类)所述。
from keras.models import Sequential
from keras.layers import Convolution1D, MaxPooling1D, Flatten, Dense, Dropout
# ...(数据准备和重塑如前所述)...# 多分类示例:假设 num_classes = 5(正常、DoS、Probe、R2L、U2R)
num_classes = 5
# y_train_dummy 应为 one-hot 编码,例如 to_categorical(y_train_raw, num_classes=5)model_multiclass_deep_cnn = Sequential()
# 第一个卷积块
model_multiclass_deep_cnn.add(Convolution1D(64, 3, activation="relu", input_shape=(41, 1)))
model_multiclass_deep_cnn.add(MaxPooling1D(pool_size=2))# 第二个卷积块(更深的网络)
model_multiclass_deep_cnn.add(Convolution1D(128, 3, activation="relu")) # 更多过滤器用于更复杂的模式
model_multiclass_deep_cnn.add(MaxPooling1D(pool_size=2))model_multiclass_deep_cnn.add(Flatten())
model_multiclass_deep_cnn.add(Dense(128, activation="relu"))
model_multiclass_deep_cnn.add(Dropout(0.5))# 对于多分类(如第1章所述):
model_multiclass_deep_cnn.add(Dense(num_classes, activation="softmax"))model_multiclass_deep_cnn.compile(loss="categorical_crossentropy", optimizer="adam", metrics=['accuracy'])print("\n用于多分类的深度CNN模型创建并编译完成!")
model_multiclass_deep_cnn.summary()
多分类的关键区别:
Dense(num_classes, activation="softmax"):输出层现在有num_classes(例如5)个神经元,softmax激活确保输出是每个类的概率,总和为1。loss="categorical_crossentropy":当标签是one-hot编码时(多分类问题中应该如此),这是合适的损失函数。
幕后:CNN如何处理数据
将CNN想象为一个专业的安全团队。
首先,有许多初级官员(Convolution1D过滤器),每个都训练来发现特定的细节(例如"数据包的突然爆发")。然后,主管(MaxPooling1D)总结初级官员的发现,只记录最显著的检测。这个过程重复进行,更高级别的官员(Convolution1D层)寻找这些总结细节的更复杂组合。最后,所有总结的发现交给首席分析师(展平和密集层)做出最终决定。
在训练期间,这个流程会反复进行。每次传递后,模型将其预测与真实标签进行比较,计算loss,然后微妙地调整内部参数(过滤器的权重、密集层)以尝试在下一次减少loss。
深入项目代码参考
让我们看看实际项目代码文件,了解纯CNN是如何实现的。你可以在KDDCup 99/CNN/文件夹(以及NSL-KDD、UNSW-NB15等其他数据集的类似文件夹)中找到这些内容。
1. 简单CNN(1个卷积+池化块)- 二分类
查看KDDCup 99/CNN/binary/cnn1.py或NSL-KDD/CNN/binary/cnn1.py。在数据加载、归一化和重塑步骤(如第2章:数据加载与预处理所述)之后:
# 来自 KDDCup 99/CNN/binary/cnn1.py(简化版)
from keras.models import Sequential
from keras.layers import Convolution1D, MaxPooling1D, Flatten, Dense, Dropout
import numpy as np # 用于np.reshape(如果尚未导入)# ...(X_train, y_train, X_test, y_test 已准备好并重塑)...cnn = Sequential()
# 卷积层:64个过滤器,核大小3,relu激活,输入形状(41,1)
cnn.add(Convolution1D(64, 3, border_mode="same", activation="relu", input_shape=(41, 1)))
# 池化层:池长度2
cnn.add(MaxPooling1D(pool_length=(2)))
# 展平层
cnn.add(Flatten())
# 密集层:128个神经元,relu激活
cnn.add(Dense(128, activation="relu"))
# Dropout层:0.5(50%)的丢弃率
cnn.add(Dropout(0.5))
# 输出层:1个神经元,用于二分类的sigmoid激活
cnn.add(Dense(1, activation="sigmoid"))print(cnn.summary()) # 查看模型的架构
# cnn.compile(...) # 编译代码在原代码片段中被注释掉
观察:
input_shape=(41, 1)正确指定了第一个Convolution1D层的输入维度。Convolution1D中的border_mode="same"意味着输出特征图将与输入长度相同,必要时填充边缘。Convolution1D、MaxPooling1D、Flatten、Dense、Dropout和最终Dense层的堆叠构成了完整的CNN。- 输出层(
Dense(1, activation="sigmoid"))和相关的binary_crossentropy损失(在注释掉的编译部分中)与我们在第1章中的二分类设置一致。
2. 更深CNN(多个卷积+池化块)- 二分类
现在,我们来看KDDCup 99/CNN/binary/cnn3.py。这个文件通过堆叠更多的卷积和池化层展示了"更深"的CNN:
# 来自 KDDCup 99/CNN/binary/cnn3.py(简化版)
from keras.models import Sequential
from keras.layers import Convolution1D, MaxPooling1D, Flatten, Dense, Dropout# ...(X_train, y_train, X_test, y_test 已准备好并重塑)...cnn = Sequential()
# 第一个卷积块
cnn.add(Convolution1D(64, 3, border_mode="same", activation="relu", input_shape=(41, 1)))
cnn.add(Convolution1D(64, 3, border_mode="same", activation="relu")) # 另一个Conv1D
cnn.add(MaxPooling1D(pool_length=(2)))
# 第二个卷积块
cnn.add(Convolution1D(128, 3, border_mode="same", activation="relu")) # 更多过滤器用于更复杂的模式
cnn.add(Convolution1D(128, 3, border_mode="same", activation="relu"))
cnn.add(MaxPooling1D(pool_length=(2)))
# 展平和密集层用于分类
cnn.add(Flatten())
cnn.add(Dense(128, activation="relu"))
cnn.add(Dropout(0.5))
cnn.add(Dense(1, activation="sigmoid"))# cnn.compile(...) # 编译代码
# cnn.fit(...) # 训练代码
观察:
- 这个模型使用了两个
Convolution1D层后跟一个MaxPooling1D层,然后用更多过滤器(128而不是64)重复这个模式。这使得网络能够学习逐渐更复杂和抽象的模式。 - 过滤器的数量通常在更深的层中增加,因为它们学习将更简单的特征组合成更复杂的特征。
- 输出层和损失函数与
cnn1.py相同,因为它仍然是二分类任务。
3. 简单CNN(1个卷积+池化块)- 多分类
最后,我们来看KDDCup 99/CNN/multiclass/cnn1.py。它使用类似的CNN结构,但适应了多分类:
# 来自 KDDCup 99/CNN/multiclass/cnn1.py(简化版)
from keras.models import Sequential
from keras.layers import Convolution1D, MaxPooling1D, Flatten, Dense, Dropout
from keras.utils.np_utils import to_categorical # 用于标签准备
import numpy as np# ...(X_train, y_train1, X_test, y_test1 已准备好)...
# 数据准备:对多分类标签进行one-hot编码
y_train = to_categorical(y_train1)
y_test = to_categorical(y_test1)cnn = Sequential()
# 卷积和池化层保持不变用于特征提取
cnn.add(Convolution1D(64, 3, border_mode="same", activation="relu", input_shape=(41, 1)))
cnn.add(MaxPooling1D(pool_length=(2)))
cnn.add(Flatten())
cnn.add(Dense(128, activation="relu"))
cnn.add(Dropout(0.5))
# 输出层:5个神经元(用于5个类别),softmax激活
cnn.add(Dense(5, activation="softmax"))# cnn.compile(...) # 编译代码
# cnn.fit(...) # 训练代码
观察:
- 关键的是,
y_train和y_test标签在输入模型前使用to_categorical(one-hot编码)转换,如第1章所述。 - 特征提取部分(
Convolution1D和MaxPooling1D层)与二分类版本相同。 - 输出层使用
Dense(5)(假设多分类数据集中有5个类别)和activation="softmax"。 - 损失函数现在是
categorical_crossentropy,适用于one-hot编码标签。
这些示例清楚地展示了使用Convolution1D和MaxPooling1D层提取模式是CNN的核心,而输出层和损失函数则根据具体分类任务进行调整。
结论
现在,已经了解了纯卷积神经网络(CNN)模型在网络入侵检测中的基础知识
理解了Convolution1D层如何作为模式检测器,MaxPooling1D层如何总结这些检测,以及展平层如何将这些见解准备好用于传统的密集分类层。你还看到了如何使用Keras构建这些模型,并为二分类和多分类入侵检测任务配置它们,这些建立在前面章节的基础知识之上。
CNN在自动学习网络流量特征中的"签名"方面非常有效,这对于发现复杂和不断演变的威胁至关重要。
接下来,我们将探索另一种强大的深度学习模型:循环神经网络(RNN)。虽然CNN擅长发现局部模式,但RNN设计用于记住较长序列中的信息,这对于理解网络流量的时间性质特别有用。
第6章:循环神经网络(RNN)模型(LSTM/GRU/SimpleRNN)