Redis 主从复制、哨兵与 Cluster 集群部署
文章摘要
本文基于 VMware 虚拟机环境,详细讲解 Redis 高可用架构的核心组件与部署流程,涵盖三大核心模块:Redis 主从复制(实现数据备份与读写分离)、Redis 哨兵(基于主从复制实现故障自动转移,保障服务高可用)、Redis Cluster 集群(去中心化架构,实现数据分片与横向扩展)。
一、redis主从复制
Redis 主从复制是 Redis 高可用架构的基础,通过将主节点(Master)的数据同步到从节点(Slave),实现数据备份(避免单点数据丢失)和读写分离(主节点写、从节点读,减轻主节点压力)。
1. 原理
Redis主从复制是将主节点数据同步到从节点的机制,核心流程分三步:
- 建立连接:从节点通过
REPLICAOF指定主节点,发起连接并完成认证。 - 数据同步:
- 首次同步或主节点重启时,触发全量复制:主节点生成RDB快照发给从节点,同时缓存期间的写命令,随后将缓存命令发送给从节点。
- 从节点断线重连后,若条件满足(主节点未变、偏移量在积压缓冲区范围内),触发部分复制:仅同步断线期间的增量数据。
- 命令传播:同步完成后,主节点实时将新写命令发给从节点,保持数据一致。
核心作用:实现数据备份、读写分离,是高可用架构的基础。
2. 配置主从同步
环境说明:
| 主机名 | ip | 作用 |
|---|---|---|
| redis-master | 192.168.2.10/24 | master |
| redis-slave1 | 192.168.2.11/24 | slave1 |
| redis-slave2 | 192.168.2.12/24 | slave2 |
(1)master上配置
#关闭防火墙以及SELinux
[root@master ~]# systemctl disable --now firewalld
[root@master ~]# getenforce
Disabled
#安装redis并且启动
[root@master ~]# yum install redis -y
[root@master ~]# systemctl start redis
#编辑配置文件
[root@master ~]# vim /etc/redis/redis.conf
bind 0.0.0.0
protected-mode no
daemonize no #后台运行[root@redis-master ~]# redis-cli -p 6379
#有效响应
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> info replication
role:master #当前角色为主
connected_slaves:0
master_failover_state:no-failover
master_replid:b765b9a92e508c2b912f56d2f496e34d1431818f
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
(2)slave1配置
[root@slave1 ~]# systemctl disable --now firewalld
[root@slave1 ~]# setenforce 0
setenforce: SELinux is disabled
[root@slave1 ~]# yum install redis -y
[root@slave1 ~]# systemctl start redis
[root@slave1 ~]# redis-cli -p 6379
127.0.0.1:6379> info replication
# Replication
role:master #可以看到此时从的角色也是主
connected_slaves:0
master_failover_state:no-failover
master_replid:be4ca2f5431d5ced9f6fec13fb45111d00a15fb2
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6379> replicaof 192.168.2.10 6379 #临时添加主
OK
127.0.0.1:6379> info replication
# Replication
role:slave #当前从的角色调整为slave
master_host:192.168.168.20
master_port:6379
master_link_status:down
master_last_io_seconds_ago:-1
master_sync_in_progress:0
slave_read_repl_offset:0
slave_repl_offset:0
master_link_down_since_seconds:-1
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:be4ca2f5431d5ced9f6fec13fb45111d00a15fb2
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
#如果想要slave1永久成为192.168.2.10的从需要写配置文件
[root@redis-slave1 ~]# vim /etc/redis/redis.conf
bind 0.0.0.0
protected-mode no
daemonize no
replicaof 192.168.2.10 6379
[root@redis-slave1 ~]# systemctl restart redis
(3)slave2配置
[root@slave2 ~]# setenforce 0
setenforce: SELinux is disabled
[root@slave2 ~]# systemctl restart redis
[root@slave2 ~]# yum install redis -y
[root@slave2 ~]# vim /etc/redis/redis.conf
bind 0.0.0.0
protected-mode no
daemonize no
replicaof 192.168.2.10 6379
[root@slave2 ~]# systemctl disable --now firewalld
(4)主从复制验证
#主上查看
[root@master ~]# redis-cli
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.2.11,port=6379,state=online,offset=472520,lag=0
slave1:ip=192.168.2.12,port=6379,state=online,offset=472520,lag=1
master_failover_state:no-failover
master_replid:8d6ad7deb54af3875d40da49acb6e57b0225f63b
master_replid2:d301ad130006c0539408fe1c69b9b2d677a7d479
master_repl_offset:472520
second_repl_offset:10827
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:99
repl_backlog_histlen:472422#主上可以写入数据,从上只能读数据
[root@master ~]# redis-cli
127.0.0.1:6379> set s 1
OK
127.0.0.1:6379> get s
"1"
#从上查看
127.0.0.1:6379> get s
"1"
127.0.0.1:6379> DEL s
(error) READONLY You can't write against a read only replica.
二、redis高可用(哨兵)
Redis 主从复制仅能实现数据备份,若主节点故障,需手动切换从节点为主节点,无法满足高可用需求。哨兵(Sentinel) 通过分布式集群监控主从节点,实现故障自动检测与转移,确保服务不中断。
1. 原理
Redis哨兵是基于主从复制的高可用机制,核心是通过分布式哨兵集群实现主节点故障的自动处理,关键流程如下:
-
哨兵集群部署:通常3-5个哨兵节点(奇数,避免投票平局),既监控主从节点,也互相监控,防止哨兵自身单点故障。
-
分层故障检测:
- 单个哨兵定期给主节点发
PING,超时未响应则标记为“主观下线”(可能误判); - 该哨兵向其他哨兵发起投票,若超过
quorum(法定票数,如3个哨兵需2票)同意主节点下线,则标记为“客观下线”(确认故障)。
- 单个哨兵定期给主节点发
-
自动故障转移:
- 哨兵集群用Raft算法选一个“领头哨兵”负责执行转移;
- 从健康从节点中选新主:优先挑数据最完整(复制偏移量最大)、优先级高的从节点;
- 新主升级(
SLAVEOF NO ONE),其他从节点改同步新主,原主恢复后变从节点。
-
客户端适配:客户端通过哨兵的
SENTINEL get-master-addr-by-name命令获取当前主节点地址,故障转移后自动拿到新地址,无需手动改配置。
这套机制让Redis在主节点故障时,能10-30秒内自动恢复服务,实现高可用。
2. 哨兵部署与实操
(1)前提条件:确保主从复制正常
哨兵依赖主从复制,需先确保主从节点正常运行并完成数据同步:
- 主节点(master)配置:默认配置即可(redis.conf),确保 port 6379 等基础配置正确。
- 从节点(slave)配置:在 redis.conf 中添加(或通过命令临时设置):
replicaof 192.168.2.10 6379
启动主节点和从节点,通过 info replication 命令确认主从关系正常(主节点 role:master,从节点 role:slave)。
[root@master ~]# redis-cli
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.2.11,port=6379,state=online,offset=473528,lag=1
slave1:ip=192.168.2.12,port=6379,state=online,offset=473528,lag=0
master_failover_state:no-failover
master_replid:6970a8c24b0da9d60549f73916e90b50128c40e8
master_replid2:8d6ad7deb54af3875d40da49acb6e57b0225f63b
master_repl_offset:473528
second_repl_offset:473515
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:454346
repl_backlog_histlen:19183(2) 哨兵配置文件(sentinel.conf)
每个哨兵节点需一份sentienl.conf配置文件,3 个哨兵节点(Master、Slave1、Slave2 各部署 1 个)的配置需一致。。核心配置项如下:
[root@master ~]#vim /etc/redis/sentinel.conf
port 26379 #监听端口
daemonize no #后台运行
pidfile /var/run/redis-sentinel.pid
logfile /var/log/redis/sentinel.log
#格式:sentinel monitor <主节点名称> <主节点IP> <主节点端口> <quorum法定票数>
sentinel monitor mymaster 192.168.2.10 6379 2
#monitor:监控
#mymaster为监控对象起的服务名称
#2表示只有2个或2个以上的哨兵认为主节点不可用的时候,才会把 master 设置为客观下线状态,然后进行 failover 操作。
# 若主节点超过30秒未响应哨兵的PING,哨兵会标记其为“主观下线”
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1 #发生故障转移后,同时开始同步新master数据的slave数量
sentinel failover-timeout mymaster 180000 #整个故障切换的超时时间为3分钟
[root@master ~]# scp /etc/redis/sentinel.conf root@192.168.2.11:/etc/redis/
root@192.168.2.11's password:
sentinel.conf 100% 14KB 25.7MB/s 00:00
[root@master ~]# scp /etc/redis/sentinel.conf root@192.168.2.12:/etc/redis/
root@192.168.2.12's password:
sentinel.conf 100% 14KB 16.1MB/s 00:00
[root@master ~]# systemctl start redis-sentinel.service
(3)启动哨兵(3 个节点均需执行)
systemctl start redis-sentinel
(4)验证哨兵配置
[root@master ~]# redis-cli -p 26379
127.0.0.1:26379> info sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
#主节点名称、状态、从节点数量、哨兵数量
master0:name=mymaster,status=ok,address=192.168.2.10:6379,slaves=2,sentinels=3
(5)故障转移测试
模拟主节点(192.168.2.10)故障,验证哨兵是否自动切换主节点:
[root@master ~]# redis-cli
127.0.0.1:6379> SHUTDOWN
not connected> exit
[root@master ~]# tail -5 /var/log/redis/sentinel.log
33602:X 07 Sep 2025 17:31:08.192 # +vote-for-leader ca35a05386937b45caa68d35c00a68f37aff1c3e 1
33602:X 07 Sep 2025 17:31:08.788 # +config-update-from sentinel ca35a05386937b45caa68d35c00a68f37aff1c3e 192.168.2.12 26379 @ mymaster 192.168.2.10 6379
33602:X 07 Sep 2025 17:31:08.788 # +switch-master mymaster 192.168.2.10 6379 192.168.2.11 6379
33602:X 07 Sep 2025 17:31:08.789 * +slave slave 192.168.2.12:6379 192.168.2.12 6379 @ mymaster 192.168.2.11 6379
33602:X 07 Sep 2025 17:31:08.789 * +slave slave 192.168.2.10:6379 192.168.2.10 6379 @ mymaster 192.168.2.11 6379
33602:X 07 Sep 2025 17:31:38.843 # +sdown slave 192.168.2.10:6379 192.168.2.10 6379 @ mymaster 192.168.2.11 6379
#可以看到主已经自动切换为slave1,从节点slave2已同步新主#从slave1上查看
[root@slave1 ~]# redis-cli
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=192.168.2.12,port=6379,state=online,offset=118748,lag=1
master_failover_state:no-failover
master_replid:8276820d549a2bf011159dd785a500abce05a1ed
master_replid2:46ef1e258850bfd3b53b5b5ad3474728a2089638
master_repl_offset:118887
second_repl_offset:78970
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:118887
重启原主节点(验证是否自动变为从节点)
[root@master ~]# systemctl start redis
[root@master ~]# redis-cli
127.0.0.1:6379> info replication
# Replication
role:slave #身份已经变为了slave1的从
master_host:192.168.2.11 #主为slave1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:0
master_sync_in_progress:0
slave_read_repl_offset:162850
slave_repl_offset:162850
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:8276820d549a2bf011159dd785a500abce05a1ed
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:162850
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:161146
repl_backlog_histlen:17053.总结
注意事项!!!!
- 哨兵数量:至少 3 个(奇数),避免投票平局(如 3 个哨兵可容错 1 个故障)。
- 配置一致性:所有哨兵的 sentinel monitor 配置需一致(主节点名称、IP、端口、quorum 值相同)。
- 独立部署:哨兵节点与主从节点尽量部署在不同机器,避免单点硬件故障导致整体不可用。
- 端口开放:确保主从节点端口(如 6379)和哨兵端口(如 26379)在防火墙中开放,允许节点间通信。
三、redis cluster(去中心化集群)
Redis 主从 + 哨兵虽能实现高可用,但无法解决 “单主节点性能瓶颈” 和 “数据容量上限” 问题。Redis Cluster 是去中心化架构,通过将数据分片(Sharding)到多个主节点,实现横向扩展(扩容)与高可用。
1. 集群核心特性
- 数据分片:将 Redis 的 16384 个 Slot(哈希槽)均匀分配到多个主节点,每个主节点负责一部分 Slot;客户端根据key的哈希值计算所属 Slot,直接访问对应主节点。
- 去中心化:无中心节点,每个节点都保存整个集群的拓扑信息,客户端可连接任意节点访问数据(自动重定向到目标节点)。
- 高可用:每个主节点对应至少 1 个从节点,主节点故障时,从节点自动升级为主节点(类似哨兵的故障转移)。
2. 配置集群
按照如下示例,需要准备6台服务器:
说明:条件有限,本次使用三台服务器,每台服务器上运行一主一从
| 主机说明 | 主机IP | 端口 |
|---|---|---|
| master1 | 192.168.2.10 | 6379 |
| slave1 | 192.168.2.10 | 6380 |
| master2 | 192.168.2.11 | 6379 |
| slave2 | 192.168.2.11 | 6380 |
| master3 | 192.168.2.12 | 6379 |
| slave3 | 192.168.2.12 | 6380 |
下·(1)单节点 Redis 实例配置(以 Master1 所在机器为例)
需为每台机器配置 2 个 Redis 实例(6379 为主、6380 为从),步骤如下:
#修改如下配置
[root@master1 ~]# vim /etc/redis/redis.conf
port 6379 # 修改端口号
pidfile /var/run/redis_6379.pid # 修改pid文件名
dir /var/lib/redis # 持久化文件存放目录
dbfilename dump_6379.rdb # 修改持久化文件名
bind 0.0.0.0 # 绑定地址
daemonize yes # 让redis后台运行
protected-mode no # 关闭保护模式
logfile /var/log/redis/redis_6379.log # 指定日志
cluster-enabled yes # 开启集群功能
cluster-config-file nodes-6379.conf #设定节点配置文件名,不需要我们创建,由redis自己维护
cluster-node-timeout 10000 # 节点心跳失败的超时时间,超过该时间(毫秒),集群自动进行主从切换
#启动第一个redis实例
[root@master1 ~]# systemctl restart redis
[root@master1 ~]# ss -lntup | grep redis
tcp LISTEN 0 511 0.0.0.0:6379 0.0.0.0:* users:(("redis-server",pid=28535,fd=6))#在该主机上启动另外一个6380端口的实例
[root@master1 ~]# cp /etc/redis/redis.conf /etc/redis/redis-6380.conf
[root@master1 ~]# vim /etc/redis/redis-6380.conf
bind 0.0.0.0
protected-mode no
port 6380
daemonize no
pidfile /var/run/redis_6380.pid
logfile /var/log/redis/redis_6380.log
dbfilename dump_6380.rdb
dir /var/lib/redis
cluster-enabled yes
cluster-config-file nodes-6380.conf
cluster-node-timeout 15000
[root@master1 ~]# redis-server /etc/redis/redis-6380.conf#使用命令启动6380实例并将其放在后台
[root@master1 ~]# redis-server /etc/redis/redis-6380.conf &
[1] 28610
#查看是否有两个redis实例
[root@master1 ~]# ss -lntup | grep redis
tcp LISTEN 0 511 0.0.0.0:16379 0.0.0.0:* users:(("redis-server",pid=1841,fd=8))
tcp LISTEN 0 511 0.0.0.0:16380 0.0.0.0:* users:(("redis-server",pid=1876,fd=8))
tcp LISTEN 0 511 0.0.0.0:6379 0.0.0.0:* users:(("redis-server",pid=1841,fd=6))
tcp LISTEN 0 511 0.0.0.0:6380 0.0.0.0:* users:(("redis-server",pid=1876,fd=6))
(2)复制配置到其他节点(192.168.2.11、192.168.2.12)
将 Master1 的 2 个配置文件(redis.conf、redis-6380.conf)复制到 master2(192.168.2.11)和 master3(192.168.2.12),并启动实例:
[root@master1 ~]# scp /etc/redis/redis* root@192.168.2.11:/etc/redis
[root@master1 ~]# scp /etc/redis/redis* root@192.168.2.12:/etc/redis
#在master1和master2上分别启动6379和6380端口服务
systemctl restart redis 6379
redis-server /etc/redis/redis-6380.conf & 6380
#查看端口,确保服务启动
[root@master2 ~]# ss -lntup | grep redis
tcp LISTEN 0 511 0.0.0.0:16380 0.0.0.0:* users:(("redis-server",pid=1885,fd=8))
tcp LISTEN 0 511 0.0.0.0:16379 0.0.0.0:* users:(("redis-server",pid=1848,fd=8))
tcp LISTEN 0 511 0.0.0.0:6380 0.0.0.0:* users:(("redis-server",pid=1885,fd=6))
tcp LISTEN 0 511 0.0.0.0:6379 0.0.0.0:* users:(("redis-server",pid=1848,fd=6))
启动好全部 Redis 服务器后,接下来就是如何把这 6 个服务器按预先规划的结构来组合成集群了。在做接下来的操作之前,一定要先确保所有 Redis 实例都已经成功启动,并且对应实例的节点配置文件都已经成功生成。
#使用如下命令在所有主机上都可以看到所有实例生成的rdb文件和nodes文件
ls /var/lib/redis/
dump_6380.rdb dump.rdb nodes-6379.conf nodes-6380.conf
注意:如果没看到dump_6380.rdb,前面无错误的话,是因为还没有数据,属于正常现象
准备工作做完就可以开始创建集群了
创建集群命令格式:
redis-cli --cluster create --cluster-replicas 副本数 主机IP:端口号 主机IP:端口号
#create 创建集群
#`节点总数 ÷ (replicas + 1)` 得到的就是master的数量。节点列表中的前n个就是master,其它节点都是slave节点,随机分配到不同master。(Redis 的分配原则是:尽量保证每个主数据库运行在不同的IP地址,每个从库和主库不在一个IP地址上。)
(3)创建 Redis Cluster 集群
所有实例启动后,通过redis-cli --cluster create命令创建集群,指定 “每个主节点对应 1 个从节点”:
# 前3个为候选主节点,后3个为候选从节点
[root@master1 ~]# redis-cli --cluster create --cluster-replicas 1 192.168.2.10:6379 192.168.2.11:6379 192.168.2.12:6379 192.168.2.10:6380 192.168.2.11:6380 192.168.2.12:6380
# 命令解释:
# --cluster-replicas 1:每个主节点分配1个从节点
# Redis会自动分配主从关系(原则:从节点与主节点不在同一IP,避免单点故障)
# 执行后会提示“是否接受该配置”,输入yes确认#查看集群状态
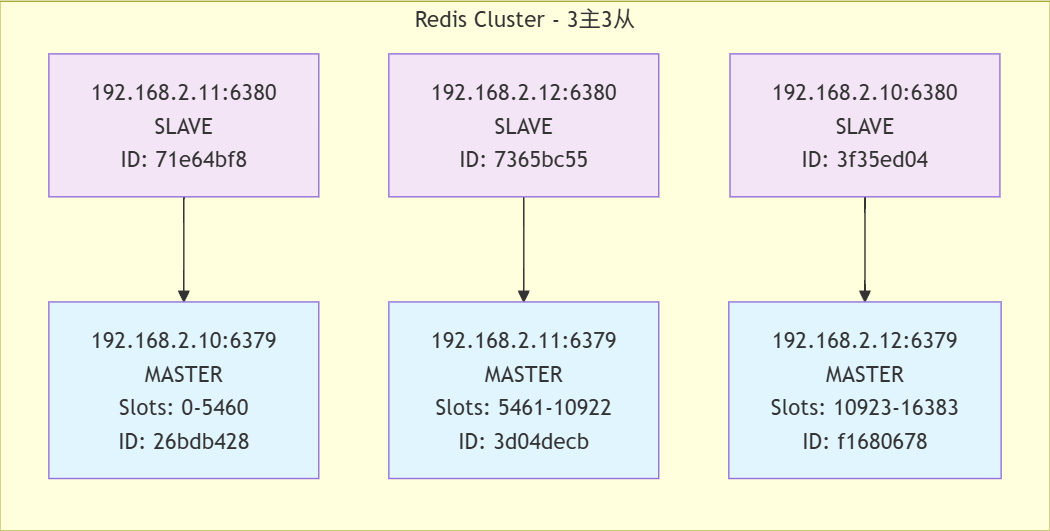
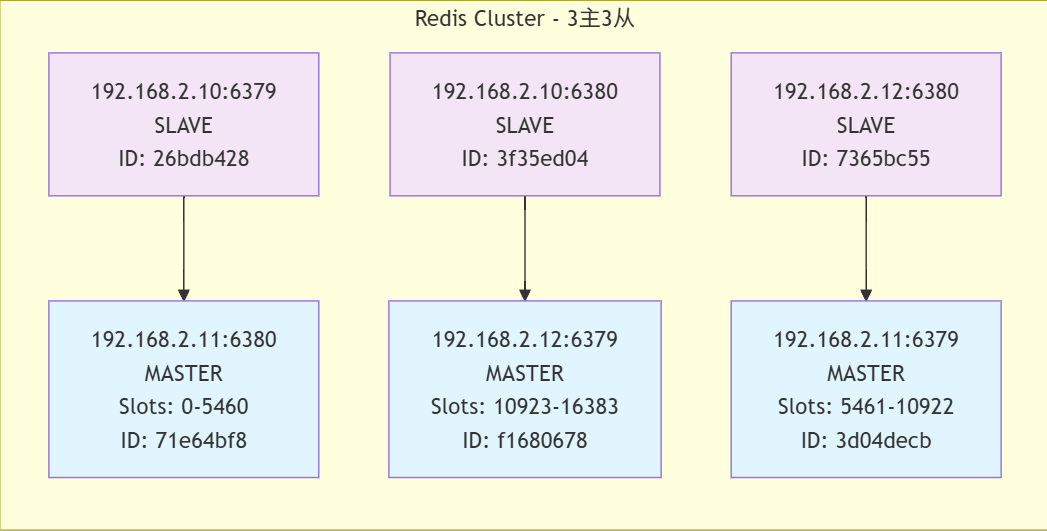
[root@master1 ~]# redis-cli -p 6379 cluster nodes
3f35ed04b4e207904a3f4251c169a4e7b48f5900 192.168.2.10:6380@16380 slave f16806788448f2dd7b7d2cb64104a3a6c783a2a6 0 1757319959184 3 connected
26bdb428b70a027af429bfd3fe040a79987bfb3c 192.168.2.10:6379@16379 myself,master - 0 1757319958000 1 connected 0-5460
7365bc55c093847e1fce701dfa72b9fe2c65bbcd 192.168.2.12:6380@16380 slave 3d04decb42d25b78266ce19ebc3e9dac67932330 0 1757319959000 2 connected
f16806788448f2dd7b7d2cb64104a3a6c783a2a6 192.168.2.12:6379@16379 master - 0 1757319958000 3 connected 10923-16383
71e64bf81ae2d0e667b3321911a04ba730926640 192.168.2.11:6380@16380 slave 26bdb428b70a027af429bfd3fe040a79987bfb3c 0 1757319958000 1 connected
3d04decb42d25b78266ce19ebc3e9dac67932330 192.168.2.11:6379@16379 master - 0 1757319957172 2 connected 5461-10922
通过拓扑图可以更加清晰的看出结构
(4)集群功能验证(数据分片与重定向)
通过-c参数启用集群模式连接 Redis,验证数据自动分片与重定向:
#加上-c表示启用集群模式
[root@master1 ~]# redis-cli -p 6379 -c
127.0.0.1:6379> set a 9527
-> Redirected to slot [15495] located at 192.168.2.12:6379
OK
192.168.2.12:6379> set b WuYanZu
-> Redirected to slot [3300] located at 192.168.2.10:6379
OK
192.168.2.10:6379> set c hellokitty
-> Redirected to slot [7365] located at 192.168.2.11:6379
OK
192.168.2.11:6379> get a
-> Redirected to slot [15495] located at 192.168.2.12:6379
"9527"
192.168.2.12:6379> get b
-> Redirected to slot [3300] located at 192.168.2.10:6379
"WuYanZu"
192.168.2.10:6379> get c
-> Redirected to slot [7365] located at 192.168.2.11:6379
"hellokitty"
由此我们可以看出
这个 Redis 集群表现出以下关键特性:
- 数据分片:数据均匀分布在多个节点
- 一致性哈希:键到节点的映射稳定且一致
- 透明访问:客户端无需知道数据具体位置
- 高可用性:所有节点正常运行,数据可访问
- 高性能:快速的重定向和响应
3. 集群故障转移测试
(1)模拟 Master1(192.168.2.10:6379)故障,验证从节点是否自动升级为主节点:
[root@master1 ~]# redis-cli -p 6379
127.0.0.1:6379> SHUTDOWN
not connected> exit
[root@master1 ~]# redis-cli -p 6380
127.0.0.1:6380> cluster nodes
7365bc55c093847e1fce701dfa72b9fe2c65bbcd 192.168.2.12:6380@16380 slave 3d04decb42d25b78266ce19ebc3e9dac67932330 0 1757321186609 2 connected
3d04decb42d25b78266ce19ebc3e9dac67932330 192.168.2.11:6379@16379 master - 0 1757321187616 2 connected 5461-10922
71e64bf81ae2d0e667b3321911a04ba730926640 192.168.2.11:6380@16380 master - 0 1757321186000 7 connected 0-5460
26bdb428b70a027af429bfd3fe040a79987bfb3c 192.168.2.10:6379@16379 master,fail - 1757321174513 1757321172000 1 disconnected
3f35ed04b4e207904a3f4251c169a4e7b48f5900 192.168.2.10:6380@16380 myself,slave f16806788448f2dd7b7d2cb64104a3a6c783a2a6 0 1757321185000 3 connected
f16806788448f2dd7b7d2cb64104a3a6c783a2a6 192.168.2.12:6379@16379 master - 0 1757321184594 3 connected 10923-16383
可以看到192.168.2.10:6379变为了fail,而他的从192.168.2.11:6380变为了现在的主,如图:
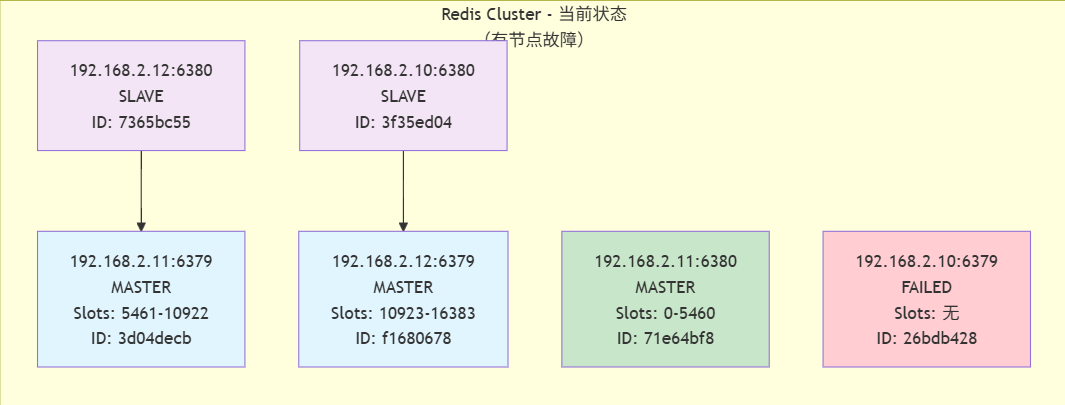
集群状态分析
-
故障情况
故障节点: 192.168.2.10:6379 (原主节点,负责slots 0-5460)
故障时间: 1757321174513 (Unix时间戳,约2025年9月8日) -
故障转移
新的主节点: 192.168.2.11:6380 (原为192.168.2.10:6379的从节点)
接管slot范围: 0-5460
故障转移成功: 集群自动完成了主从切换 -
当前集群结构
- 正常工作的主节点: 3个
192.168.2.11:6379 (slots 5461-10922)
192.168.2.12:6379 (slots 10923-16383)
192.168.2.11:6380 (slots 0-5460,故障转移后晋升) - 从节点: 2个
192.168.2.12:6380 (复制192.168.2.11:6379)
192.168.2.10:6380 (复制192.168.2.12:6379)
- 正常工作的主节点: 3个
(2)再次启动master1,可以发现master1变成了从
[root@master1 ~]# systemctl start redis
[root@master1 ~]# redis-cli -p 6379
127.0.0.1:6379> cluster nodes
3f35ed04b4e207904a3f4251c169a4e7b48f5900 192.168.2.10:6380@16380 slave f16806788448f2dd7b7d2cb64104a3a6c783a2a6 0 1757321484000 3 connected
3d04decb42d25b78266ce19ebc3e9dac67932330 192.168.2.11:6379@16379 master - 0 1757321484923 2 connected 5461-10922
71e64bf81ae2d0e667b3321911a04ba730926640 192.168.2.11:6380@16380 master - 0 1757321485929 7 connected 0-5460
f16806788448f2dd7b7d2cb64104a3a6c783a2a6 192.168.2.12:6379@16379 master - 0 1757321484000 3 connected 10923-16383
26bdb428b70a027af429bfd3fe040a79987bfb3c 192.168.2.10:6379@16379 myself,slave 71e64bf81ae2d0e667b3321911a04ba730926640 0 1757321484000 7 connected
7365bc55c093847e1fce701dfa72b9fe2c65bbcd 192.168.2.12:6380@16380 slave 3d04decb42d25b78266ce19ebc3e9dac67932330 0 1757321484000 2 connected
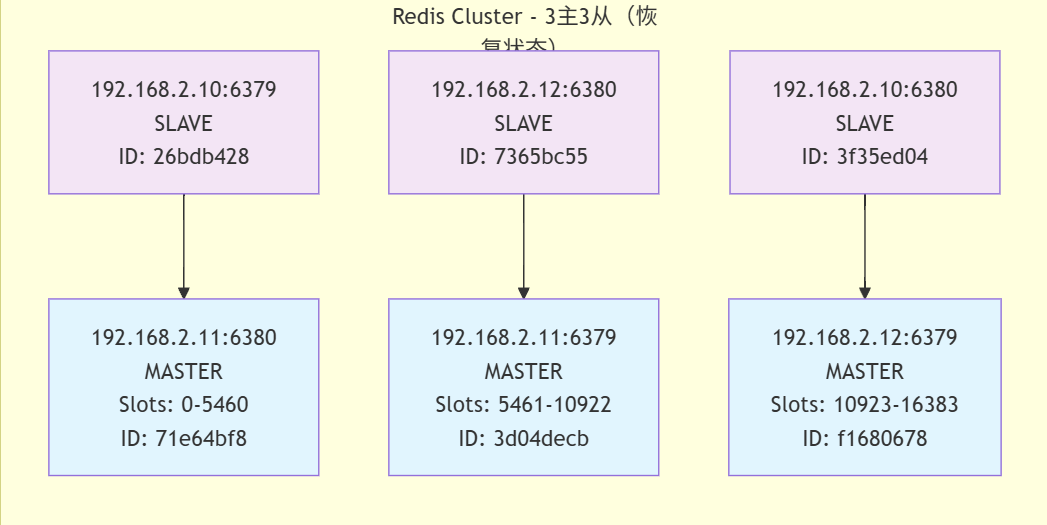
集群状态分析
-
恢复后的集群结构
主节点: 3个
192.168.2.11:6380 (slots 0-5460) - 原从节点晋升
192.168.2.11:6379 (slots 5461-10922) - 保持不变
192.168.2.12:6379 (slots 10923-16383) - 保持不变
从节点: 3个
192.168.2.10:6379 (复制192.168.2.11:6380) - 原故障主节点恢复为从节点
192.168.2.12:6380 (复制192.168.2.11:6379) - 保持不变
192.168.2.10:6380 (复制192.168.2.12:6379) - 保持不变 -
故障恢复过程
原故障节点192.168.2.10:6379已恢复
但它没有恢复为主节点,而是作为从节点加入了集群
它现在复制的是192.168.2.11:6380(故障转移期间晋升的节点)
集群保持了3主3从的完整结构
注意:如果所有某段插槽的主从节点都宕机了,Redis 服务是否还能继续?
答:当发生某段插槽的主从都宕机后,如果在 redis.conf 配置文件中的 cluster-require-full-coverage 参数的值为 yes ,那么整个集群都挂掉;如果参数的值为 no ,那么该段插槽数据全都不能使用,也无法存储,其他段可以正常运行。
4.集群扩容(添加主从节点)
当集群容量不足时,可添加新的主从节点并重新分片。我们向现有集群中添加两个节点,这两个节点做一主一从。主节点的端口号为 6381,从节点的端口号为 6382。
(1)添加新实例配置
# 1. 创建6381(主)和6382(从)的配置文件
[root@master1 ~]# cp /etc/redis/redis.conf /etc/redis/redis-6381.conf
[root@master1 ~]# cp /etc/redis/redis.conf /etc/redis/redis-6382.conf
# 2. 修改6381配置(主节点)
[root@master1 ~]# sed -n 's/6379/6381/gp' /etc/redis/redis-6381.conf # 将所有6379替换为6381
# Accept connections on the specified port, default is 6381 (IANA #815344).
port 6381
# tls-port 6381
pidfile /var/run/redis_6381.pid
logfile /var/log/redis/redis_6381.log
dbfilename dump_6381.rdb
cluster-config-file nodes-6381.conf
# cluster-announce-tls-port 6381
[root@master1 ~]# sed -i 's/6379/6381/g' /etc/redis/redis-6381.conf
修改6382配置(从节点)
[root@master1 ~]# sed -i 's/6379/6382/g' /etc/redis/redis-6382.conf
[root@master1 ~]# redis-server /etc/redis/redis-6381.conf
[root@master1 ~]# redis-server /etc/redis/redis-6382.conf
# 5. 验证新实例启动
[root@master1 ~]# ss -lntup | grep redis
tcp LISTEN 0 511 0.0.0.0:16379 0.0.0.0:* users:(("redis-server",pid=1981,fd=8))
tcp LISTEN 0 511 0.0.0.0:16381 0.0.0.0:* users:(("redis-server",pid=2046,fd=8))
tcp LISTEN 0 511 0.0.0.0:16380 0.0.0.0:* users:(("redis-server",pid=1876,fd=8))
tcp LISTEN 0 511 0.0.0.0:16382 0.0.0.0:* users:(("redis-server",pid=2052,fd=8))
tcp LISTEN 0 511 0.0.0.0:6379 0.0.0.0:* users:(("redis-server",pid=1981,fd=6))
tcp LISTEN 0 511 0.0.0.0:6381 0.0.0.0:* users:(("redis-server",pid=2046,fd=6))
tcp LISTEN 0 511 0.0.0.0:6380 0.0.0.0:* users:(("redis-server",pid=1876,fd=6))
tcp LISTEN 0 511 0.0.0.0:6382 0.0.0.0:* users:(("redis-server",pid=2052,fd=6))
添加节点到集群的语法格式为:
redis-cli --cluster add-node new_host:new_port existing_host:existing_port--cluster-slave--cluster-master-id <arg>
add-node命令用于添加节点到集群中,参数说明如下:
- new_host:被添加节点的主机地址
- new_port:被添加节点的端口号
- existing_host:目前集群中已经存在的任一主机地址
- existing_port:目前集群中已经存在的任一端口地址
- –cluster-slave:用于添加从(Slave)节点
- –cluster-master-id:指定主(Master)节点的ID(唯一标识)字符串
(2)将新实例加入集群
## 1. 添加6381为主节点(关联到现有集群)
# 192.168.2.10:6381:新主节点
# 192.168.2.10:6379:现有集群中的任意节点(用于定位集群)
[root@master1 ~]# redis-cli --cluster add-node 192.168.2.10:6381 192.168.2.10:6379
>>> Adding node 192.168.2.10:6381 to cluster 192.168.2.10:6379
>>> Performing Cluster Check (using node 192.168.2.10:6379)
S: 26bdb428b70a027af429bfd3fe040a79987bfb3c 192.168.2.10:6379slots: (0 slots) slavereplicates 71e64bf81ae2d0e667b3321911a04ba730926640
S: 3f35ed04b4e207904a3f4251c169a4e7b48f5900 192.168.2.10:6380slots: (0 slots) slavereplicates f16806788448f2dd7b7d2cb64104a3a6c783a2a6
M: 3d04decb42d25b78266ce19ebc3e9dac67932330 192.168.2.11:6379slots:[5461-10922] (5462 slots) master1 additional replica(s)
M: 71e64bf81ae2d0e667b3321911a04ba730926640 192.168.2.11:6380slots:[0-5460] (5461 slots) master1 additional replica(s)
M: f16806788448f2dd7b7d2cb64104a3a6c783a2a6 192.168.2.12:6379slots:[10923-16383] (5461 slots) master1 additional replica(s)
S: 7365bc55c093847e1fce701dfa72b9fe2c65bbcd 192.168.2.12:6380slots: (0 slots) slavereplicates 3d04decb42d25b78266ce19ebc3e9dac67932330
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node 192.168.2.10:6381 to make it join the cluster.
[OK] New node added correctly.# 2. 获取6381的节点ID(用于指定从节点关联)
[root@master1 ~]# redis-cli -p 6381
127.0.0.1:6381> cluster nodes
71e64bf81ae2d0e667b3321911a04ba730926640 192.168.2.11:6380@16380 master - 0 1757322589884 7 connected 0-5460
7365bc55c093847e1fce701dfa72b9fe2c65bbcd 192.168.2.12:6380@16380 slave 3d04decb42d25b78266ce19ebc3e9dac67932330 0 1757322590086 2 connected
65314ae3be4d4e58b0f2272108d98c878e8a3ca4 192.168.2.10:6381@16381 myself,master - 0 1757322588000 0 connected
3d04decb42d25b78266ce19ebc3e9dac67932330 192.168.2.11:6379@16379 master - 0 1757322590891 2 connected 5461-10922
3f35ed04b4e207904a3f4251c169a4e7b48f5900 192.168.2.10:6380@16380 slave f16806788448f2dd7b7d2cb64104a3a6c783a2a6 0 1757322589000 3 connected
26bdb428b70a027af429bfd3fe040a79987bfb3c 192.168.2.10:6379@16379 slave 71e64bf81ae2d0e667b3321911a04ba730926640 0 1757322589000 7 connected
f16806788448f2dd7b7d2cb64104a3a6c783a2a6 192.168.2.12:6379@16379 master - 0 1757322588000 3 connected 10923-16383
127.0.0.1:6381> exit
# --cluster-slave:标记为从节点
# --cluster-master-id:指定主节点ID(6381的ID)
[root@master1 ~]# redis-cli --cluster add-node 192.168.2.10:6382 192.168.2.10:6379 --cluster-slave --cluster-master-id 65314ae3be4d4e58b0f2272108d98c878e8a3ca4
>>> Adding node 192.168.2.10:6382 to cluster 192.168.2.10:6379
>>> Performing Cluster Check (using node 192.168.2.10:6379)
S: 26bdb428b70a027af429bfd3fe040a79987bfb3c 192.168.2.10:6379slots: (0 slots) slavereplicates 71e64bf81ae2d0e667b3321911a04ba730926640
S: 3f35ed04b4e207904a3f4251c169a4e7b48f5900 192.168.2.10:6380slots: (0 slots) slavereplicates f16806788448f2dd7b7d2cb64104a3a6c783a2a6
M: 3d04decb42d25b78266ce19ebc3e9dac67932330 192.168.2.11:6379slots:[5461-10922] (5462 slots) master1 additional replica(s)
M: 71e64bf81ae2d0e667b3321911a04ba730926640 192.168.2.11:6380slots:[0-5460] (5461 slots) master1 additional replica(s)
M: f16806788448f2dd7b7d2cb64104a3a6c783a2a6 192.168.2.12:6379slots:[10923-16383] (5461 slots) master1 additional replica(s)
M: 65314ae3be4d4e58b0f2272108d98c878e8a3ca4 192.168.2.10:6381slots: (0 slots) master
S: 7365bc55c093847e1fce701dfa72b9fe2c65bbcd 192.168.2.12:6380slots: (0 slots) slavereplicates 3d04decb42d25b78266ce19ebc3e9dac67932330
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node 192.168.2.10:6382 to make it join the cluster.
Waiting for the cluster to join>>> Configure node as replica of 192.168.2.10:6381.
[OK] New node added correctly.
(3)重新分片(分配 Slot 给新主节点)
新主节点默认无 Slot,需从现有主节点迁移 Slot(本例迁移 612 个 Slot 给 6381):
由于集群中增加了新节点,需要对现有数据重新进行分片操作。重新分片的语法如下:
redis-cli --cluster reshard host:port--cluster-from <arg>--cluster-to <arg>--cluster-slots <arg>--cluster-yes--cluster-timeout <arg>--cluster-pipeline <arg>--cluster-replace
reshard命令用于重新分片,参数说明如下:
- host:集群中已经存在的任意主机地址
- port:集群中已经存在的任意主机对应的端口号
- –cluster-from:表示slot目前所在的master节点node ID(不能写slaveID,都必须写master唯一标识),多个ID用逗号分隔
- –cluster-to:表示需要分配节点的node ID(不能写slaveID,都必须写master唯一标识)
- –cluster-slot:分配的slot数量
- –cluster-yes:指定迁移时的确认输入
- –cluster-timeout:设置migrate命令的超时时间
- –cluster-pipeline:定义cluster getkeysinslot命令一次取出的key数量,不传的话使用默认值为10
- –cluster-replace:是否直接replace到目标节点
1.查看现有主节点ID(确定从哪个主节点迁移Slot)
[root@master1 ~]# redis-cli -p 6379
127.0.0.1:6379> cluster nodes
3f35ed04b4e207904a3f4251c169a4e7b48f5900 192.168.2.10:6380@16380 slave f16806788448f2dd7b7d2cb64104a3a6c783a2a6 0 1757323378295 3 connected
3d04decb42d25b78266ce19ebc3e9dac67932330 192.168.2.11:6379@16379 master - 0 1757323378000 2 connected 5461-10922
d092030167c5dd384922569cffcdc1768230f73a 192.168.2.10:6382@16382 slave 65314ae3be4d4e58b0f2272108d98c878e8a3ca4 0 1757323381000 0 connected
71e64bf81ae2d0e667b3321911a04ba730926640 192.168.2.11:6380@16380 master - 0 1757323381000 7 connected 0-5460
f16806788448f2dd7b7d2cb64104a3a6c783a2a6 192.168.2.12:6379@16379 master - 0 1757323381313 3 connected 10923-16383
65314ae3be4d4e58b0f2272108d98c878e8a3ca4 192.168.2.10:6381@16381 master - 0 1757323380307 0 connected
26bdb428b70a027af429bfd3fe040a79987bfb3c 192.168.2.10:6379@16379 myself,slave 71e64bf81ae2d0e667b3321911a04ba730926640 0 1757323378000 7 connected
7365bc55c093847e1fce701dfa72b9fe2c65bbcd 192.168.2.12:6380@16380 slave 3d04decb42d25b78266ce19ebc3e9dac67932330 0 1757323379000 2 connected
127.0.0.1:6379> exit
2. 执行重新分片
[root@master1 ~]# redis-cli --cluster reshard 192.168.2.10:6379 \
> --cluster-from f16806788448f2dd7b7d2cb64104a3a6c783a2a6 \ #master3的ID
> --cluster-to 65314ae3be4d4e58b0f2272108d98c878e8a3ca4 \ #6381的ID
> --cluster-slots 612 \ #分配的slot数量
> --cluster-yes \
> --cluster-timeout 5000 \
> --cluster-pipeline 10 \
> --cluster-replace
验证分片结果
[root@master1 ~]# redis-cli -p 6379
127.0.0.1:6379> cluster nodes
3f35ed04b4e207904a3f4251c169a4e7b48f5900 192.168.2.10:6380@16380 slave f16806788448f2dd7b7d2cb64104a3a6c783a2a6 0 1757324010041 3 connected
3d04decb42d25b78266ce19ebc3e9dac67932330 192.168.2.11:6379@16379 master - 0 1757324007023 2 connected 5461-10922
d092030167c5dd384922569cffcdc1768230f73a 192.168.2.10:6382@16382 slave 65314ae3be4d4e58b0f2272108d98c878e8a3ca4 0 1757324009000 8 connected
71e64bf81ae2d0e667b3321911a04ba730926640 192.168.2.11:6380@16380 master - 0 1757324010041 7 connected 0-5460
f16806788448f2dd7b7d2cb64104a3a6c783a2a6 192.168.2.12:6379@16379 master - 0 1757324008029 3 connected 11535-16383
65314ae3be4d4e58b0f2272108d98c878e8a3ca4 192.168.2.10:6381@16381 master - 0 1757324009035 8 connected 10923-11534
26bdb428b70a027af429bfd3fe040a79987bfb3c 192.168.2.10:6379@16379 myself,slave 71e64bf81ae2d0e667b3321911a04ba730926640 0 1757324008000 7 connected
7365bc55c093847e1fce701dfa72b9fe2c65bbcd 192.168.2.12:6380@16380 slave 3d、
拓扑图
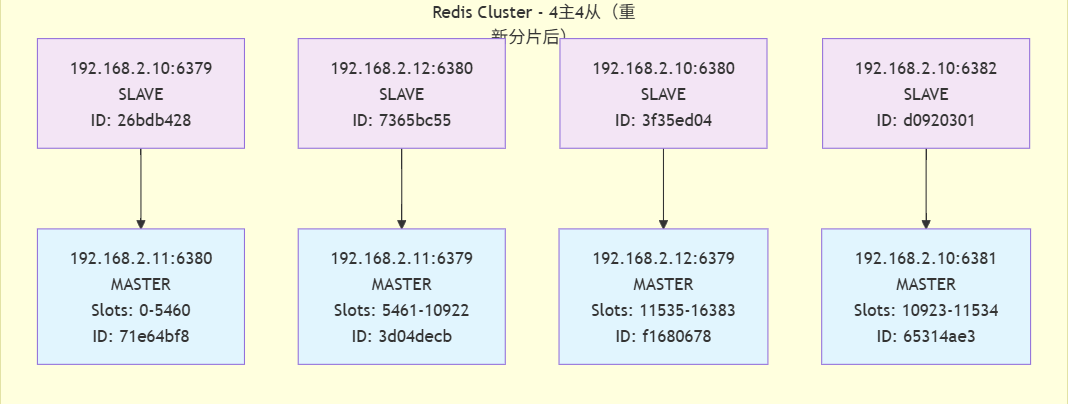
集群状态分析
- 重新分片结果
重新分片操作已成功完成,现在集群有4个主节点,每个都负责一部分slot:
-
192.168.2.11:6380: 负责 slots 0-5460 (共5461个slot)
-
192.168.2.11:6379: 负责 slots 5461-10922 (共5462个slot)
-
192.168.2.10:6381: 负责 slots 10923-11534 (共612个slot)
-
192.168.2.12:6379: 负责 slots 11535-16383 (共4849个slot)
- Slot分配变化
-
原192.168.2.12:6379节点负责的slot范围从10923-16383缩减为11535-16383
-
新节点192.168.2.10:6381获得了10923-11534范围的slot(共612个slot)
- 当前集群结构
-
主节点: 4个,分布在3台服务器上
-
192.168.2.11: 2个主节点 (6379和6380)
-
192.168.2.12: 1个主节点 (6379)
-
192.168.2.10: 1个主节点 (6381)
-
-
从节点: 4个,提供高可用性
-
每个主节点都有对应的从节点
-
从节点分布在不同的服务器上,确保容错
-
5. 集群缩容
缩容与扩容相反,需先将待删除节点的 Slot 迁移到其他主节点,再删除节点(避免数据丢失):
# 1. 查看待删除节点的Slot分布(确保Slot已迁移完毕)
[root@master1 ~]# redis-cli --cluster check 192.168.2.10:6379
192.168.2.11:6379 (3d04decb...) -> 1 keys | 5462 slots | 1 slaves.
192.168.2.11:6380 (71e64bf8...) -> 1 keys | 5461 slots | 1 slaves.
192.168.2.12:6379 (f1680678...) -> 1 keys | 4849 slots | 1 slaves.
192.168.2.10:6381 (65314ae3...) -> 0 keys | 612 slots | 1 slaves.
[OK] 3 keys in 4 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 192.168.2.10:6379)
S: 26bdb428b70a027af429bfd3fe040a79987bfb3c 192.168.2.10:6379slots: (0 slots) slavereplicates 71e64bf81ae2d0e667b3321911a04ba730926640
S: 3f35ed04b4e207904a3f4251c169a4e7b48f5900 192.168.2.10:6380slots: (0 slots) slavereplicates f16806788448f2dd7b7d2cb64104a3a6c783a2a6
M: 3d04decb42d25b78266ce19ebc3e9dac67932330 192.168.2.11:6379slots:[5461-10922] (5462 slots) master1 additional replica(s)
S: d092030167c5dd384922569cffcdc1768230f73a 192.168.2.10:6382slots: (0 slots) slavereplicates 65314ae3be4d4e58b0f2272108d98c878e8a3ca4
M: 71e64bf81ae2d0e667b3321911a04ba730926640 192.168.2.11:6380slots:[0-5460] (5461 slots) master1 additional replica(s)
M: f16806788448f2dd7b7d2cb64104a3a6c783a2a6 192.168.2.12:6379slots:[11535-16383] (4849 slots) master1 additional replica(s)
M: 65314ae3be4d4e58b0f2272108d98c878e8a3ca4 192.168.2.10:6381slots:[10923-11534] (612 slots) master1 additional replica(s)
S: 7365bc55c093847e1fce701dfa72b9fe2c65bbcd 192.168.2.12:6380slots: (0 slots) slavereplicates 3d04decb42d25b78266ce19ebc3e9dac67932330
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
[root@master1 ~]# redis-cli --cluster reshard 192.168.2.10:6379 \
> --cluster-from 65314ae3be4d4e58b0f2272108d98c878e8a3ca4 \
> --cluster-to f16806788448f2dd7b7d2cb64104a3a6c783a2a6 \
> --cluster-slots 612
#省略输出
删除节点的语法格式为:
redis-cli --cluster del-node host:port node_id
del-node命令用于从集群中删除节点,参数说明如下:
- host:集群中已经存在的主机地址
- port:集群中已经存在的主机对应的端口号
- node_id:要删除的节点ID
- 先删除从节点,如果先删除主节点,从会故障转移
1. 删除从节点(先删从,再删主)
[root@master1 ~]# redis-cli --cluster del-node 192.168.2.10:6382 d092030167c5dd384922569cffcdc1768230f73a
>>> Removing node d092030167c5dd384922569cffcdc1768230f73a from cluster 192.168.2.10:6382
>>> Sending CLUSTER FORGET messages to the cluster...
>>> Sending CLUSTER RESET SOFT to the deleted node.
2. 删除主节点(需确保无Slot)
[root@master1 ~]# redis-cli --cluster del-node 192.168.2.10:6381 65314ae3be4d4e58b0f2272108d98c878e8a3ca4
>>> Removing node 65314ae3be4d4e58b0f2272108d98c878e8a3ca4 from cluster 192.168.2.10:6381
>>> Sending CLUSTER FORGET messages to the cluster...
>>> Sending CLUSTER RESET SOFT to the deleted node.
[root@master1 ~]# redis-cli -p 6379 cluster nodes
3f35ed04b4e207904a3f4251c169a4e7b48f5900 192.168.2.10:6380@16380 slave f16806788448f2dd7b7d2cb64104a3a6c783a2a6 0 1757325635000 9 connected
3d04decb42d25b78266ce19ebc3e9dac67932330 192.168.2.11:6379@16379 master - 0 1757325636000 2 connected 5461-10922
71e64bf81ae2d0e667b3321911a04ba730926640 192.168.2.11:6380@16380 master - 0 1757325637567 7 connected 0-5460
f16806788448f2dd7b7d2cb64104a3a6c783a2a6 192.168.2.12:6379@16379 master - 0 1757325634000 9 connected 10923-16383
26bdb428b70a027af429bfd3fe040a79987bfb3c 192.168.2.10:6379@16379 myself,slave 71e64bf81ae2d0e667b3321911a04ba730926640 0 1757325636000 7 connected
7365bc55c093847e1fce701dfa72b9fe2c65bbcd 192.168.2.12:6380@16380 slave 3d04decb42d25b78266ce19ebc3e9dac67932330 0 1757325636562 2 connected
集群拓扑分析
- 主从关系
-
主节点1 (192.168.2.11:6380) → 从节点 (192.168.2.10:6379)
-
主节点2 (192.168.2.11:6379) → 从节点 (192.168.2.12:6380)
-
主节点3 (192.168.2.12:6379) → 从节点 (192.168.2.10:6380)
- 数据分片
-
节点1 (192.168.2.11:6380): 负责 slots 0-5460
-
节点2 (192.168.2.11:6379): 负责 slots 5461-10922
-
节点3 (192.168.2.12:6379): 负责 slots 10923-16383
- 物理服务器分布
-
192.168.2.10: 运行2个从节点 (6379, 6380)
-
192.168.2.11: 运行2个主节点 (6379, 6380)
-
x192.168.2.12: 运行1个主节点 (6379) 和1个从节点 (6380)
四、总结
- 主从复制:
- 主节点专门负责写数据,从节点会跟着主节点同步数据,还能帮着处理读请求。这样一来,主节点的数据有备份(从节点存了一样的),读请求多的时候也不用都挤着主节点,能分散压力。缺点是单主故障系统就完蛋了,也不能漂移IP。
- 哨兵:
在主从复制的基础上工作,专门盯着主节点。要是主节点坏了,不用人手动操作,哨兵会自动挑个数据最全、最靠谱的从节点,让它变成新的主节点,10-30 秒就能恢复服务,不用等着停业。可以解决主节点故障,也可以漂移IP,缺点是写操作无法扩展。
- Cluster:
适合业务变大的情况,是多主多从的模式。把所有数据分成好多小块,每个主节点管一块,每个主节点再配个从节点备份数据。要是哪个主节点坏了,它的从节点能顶上;业务再变大,还能加新的主从节点(扩容),解决了单个主节点扛不动大业务的问题。它同时解决了主从复制(单点故障、容量瓶颈)和哨兵(写操作无法扩展)的缺点,是支撑大规模、高并发需求的终极方案。