LangChain RetrievalQA
RetrievalQA 是 LangChain 中最核心的组件之一,它结合了检索(Retrieval)和问答(QA) 功能,能够从大量文档中查找相关信息并生成精准答案。下面我将全面解析 RetrievalQA 的工作原理、配置方法和最佳实践。
核心概念图解
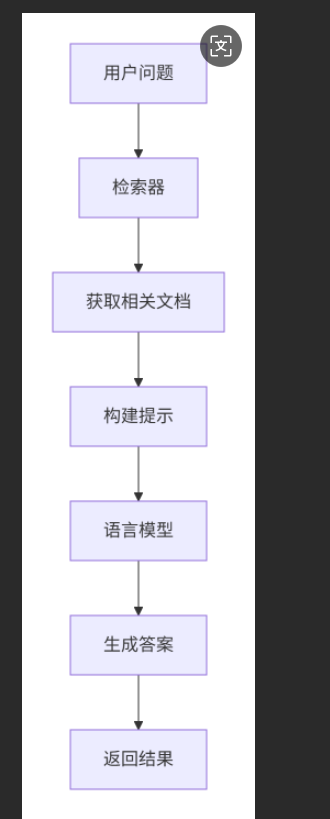
基本工作原理
RetrievalQA 的工作流程可以分为两个主要阶段:
- 检索阶段:从知识库中查找与问题相关的文档片段
- 生成阶段:基于检索到的内容生成自然语言答案
完整代码示例
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import TextLoader# 1. 加载文档
loader = TextLoader("state_of_the_union.txt")
documents = loader.load()# 2. 分割文本
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)# 3. 创建向量存储
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(texts, embeddings)# 4. 创建检索器
retriever = vectorstore.as_retriever(search_kwargs={"k": 4})# 5. 创建RetrievalQA链
qa = RetrievalQA.from_chain_type(llm=OpenAI(),chain_type="stuff",retriever=retriever,return_source_documents=True,verbose=True
)# 6. 提问
query = "总统在国情咨文中提到了哪些主要议题?"
result = qa({"query": query})print("答案:", result["result"])
print("来源文档:", result["source_documents"])关键参数详解
1. chain_type 参数
| 类型 | 描述 | 适用场景 |
|---|---|---|
"stuff" | 将所有相关文档合并到单个提示中 | 文档较少、内容简短 |
"map_reduce" | 先映射处理每个文档,再汇总结果 | 大量或长文档 |
"refine" | 迭代细化答案,逐步完善 | 复杂问题,需要深入分析 |
"map_rerank" | 对每个文档评分,选择最佳答案 | 需要置信度评估 |
2. 检索器配置
retriever = vectorstore.as_retriever(search_type="similarity", # 相似度搜索search_kwargs={"k": 6, # 返回6个最相关文档"score_threshold": 0.7 # 相似度阈值}
)3. 高级配置选项
qa = RetrievalQA.from_chain_type(llm=llm,chain_type="stuff",retriever=retriever,chain_type_kwargs={"prompt": custom_prompt, # 自定义提示模板"document_separator": "\n\n" # 文档分隔符},input_key="question", # 自定义输入键名output_key="answer", # 自定义输出键名return_source_documents=True, # 返回源文档verbose=True # 显示详细过程
)四种chain_type深度解析
1. "stuff" 策略

- 优点:简单高效,一次LLM调用
- 缺点:文档量大时可能超出token限制
- 适用:文档少、内容简洁的场景
2. "map_reduce" 策略
qa = RetrievalQA.from_chain_type(llm=llm,chain_type="map_reduce",retriever=retriever,map_prompt=map_prompt, # 可选:自定义映射提示combine_prompt=combine_prompt # 可选:自定义汇总提示
)3. "refine" 策略
qa = RetrievalQA.from_chain_type(llm=llm,chain_type="refine",retriever=retriever,question_prompt=question_prompt, # 初始问题提示refine_prompt=refine_prompt # 细化提示
)4. "map_rerank" 策略
qa = RetrievalQA.from_chain_type(llm=llm,chain_type="map_rerank",retriever=retriever,return_intermediate_steps=True # 返回中间步骤
)自定义提示模板
1. 创建自定义提示
from langchain.prompts import PromptTemplatetemplate = """使用以下上下文信息回答問題。
如果你不知道答案,就說你不知道,不要編造答案。
答案應該詳細且全面。
上下文:{context}
問題:{question}
答案:"""QA_PROMPT = PromptTemplate(template=template, input_variables=["context", "question"]
)qa = RetrievalQA.from_chain_type(llm=llm,chain_type="stuff",retriever=retriever,chain_type_kwargs={"prompt": QA_PROMPT}
)2. 多语言支持
chinese_template = """请根据以下上下文信息回答问题。
如果上下文没有提供足够信息,请回答"根据已知信息无法回答该问题"。
请用中文回答,保持回答专业且准确。上下文:{context}
问题:{question}
答案:"""CHINESE_PROMPT = PromptTemplate(template=chinese_template,input_variables=["context", "question"]
)高级功能与技巧
1. 添加对话历史
from langchain.memory import ConversationBufferMemorymemory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
qa = RetrievalQA.from_chain_type(llm=llm,chain_type="stuff",retriever=retriever,memory=memory
)2. 使用不同检索器
# 1. 最大边际相关性(MMR)检索器
retriever = vectorstore.as_retriever(search_type="mmr",search_kwargs={"k": 6, "lambda_mult": 0.5}
)# 2. 相似度阈值检索器
retriever = vectorstore.as_retriever(search_type="similarity_score_threshold",search_kwargs={"k": 6, "score_threshold": 0.8}
)3. 混合搜索
from langchain.retrievers import BM25Retriever, EnsembleRetriever
from langchain.vectorstores import Chroma# 创建两种检索器
vector_retriever = Chroma.from_documents(docs, embeddings).as_retriever()
bm25_retriever = BM25Retriever.from_documents(docs)
bm25_retriever.k = 4# 组合检索器
ensemble_retriever = EnsembleRetriever(retrievers=[vector_retriever, bm25_retriever],weights=[0.6, 0.4] # 权重分配
)qa = RetrievalQA.from_chain_type(llm=llm,chain_type="stuff",retriever=ensemble_retriever
)性能优化
1. 批量处理
# 批量处理问题
questions = ["问题1","问题2", "问题3"
]results = []
for question in questions:result = qa({"query": question})results.append(result)2. 异步处理
import asyncioasync def async_qa(question):return await qa.acall({"query": question})async def main():tasks = [async_qa(q) for q in questions]results = await asyncio.gather(*tasks)return resultsresults = asyncio.run(main())3. 缓存机制
from langchain.cache import SQLiteCache
from langchain.globals import set_llm_cacheset_llm_cache(SQLiteCache(database_path=".langchain.db"))评估与监控
1. 添加评估指标
from langchain.evaluation import QAEvaluate# 创建评估器
evaluator = QAEvaluate(qa)# 评估样本问题
examples = [{"query": "问题1", "answer": "期望答案1"},{"query": "问题2", "answer": "期望答案2"}
]results = evaluator.evaluate(examples)2. 日志记录
import logginglogging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)# 添加自定义回调记录详细日志
class QALogger:def on_chain_start(self, serialized, inputs, **kwargs):logger.info(f"Chain started with inputs: {inputs}")def on_chain_end(self, outputs, **kwargs):logger.info(f"Chain ended with outputs: {outputs}")qa = RetrievalQA.from_chain_type(llm=llm,chain_type="stuff",retriever=retriever,callbacks=[QALogger()]
)实际应用场景
1. 企业知识库
# 加载多种格式文档
from langchain.document_loaders import (PyPDFLoader, Docx2txtLoader, UnstructuredHTMLLoader
)loaders = [PyPDFLoader("manual.pdf"),Docx2txtLoader("policy.docx"),UnstructuredHTMLLoader("faq.html")
]documents = []
for loader in loaders:documents.extend(loader.load())2. 学术研究助手
# 处理学术论文
qa = RetrievalQA.from_chain_type(llm=llm,chain_type="map_reduce", # 适合长文档retriever=retriever,chain_type_kwargs={"document_variable_name": "papers","answer_length": "detailed" # 详细答案}
)3. 客户支持系统
# 多轮对话支持
qa = RetrievalQA.from_chain_type(llm=llm,chain_type="stuff",retriever=retriever,memory=ConversationBufferMemory(),input_key="customer_question",output_key="support_answer"
)常见问题解决
1. 处理长文档
# 使用适合长文档的chain_type
qa = RetrievalQA.from_chain_type(llm=llm,chain_type="map_reduce", # 或 "refine"retriever=retriever,max_tokens_limit=4000 # 限制token使用
)2. 提高答案质量
# 增加检索文档数量
retriever = vectorstore.as_retriever(search_kwargs={"k": 10})# 添加后处理
def post_process_answer(result):answer = result["result"]# 添加引用来源sources = "\n".join([f"[{i+1}] {doc.metadata.get('source', '')}" for i, doc in enumerate(result["source_documents"])])return f"{answer}\n\n参考资料:\n{sources}"result = qa({"query": question})
final_answer = post_process_answer(result)3. 处理专业术语
# 添加术语解释提示
specialized_template = """首先解释以下专业术语:{terms}
然后回答以下问题:{question}
使用以下上下文:{context}"""# 自动提取术语
def extract_terms(query):# 简单实现:提取名词短语return ["术语1", "术语2"]总结
RetrievalQA 是 LangChain 中最强大的组件之一,它:
核心优势:
- 结合检索与生成能力
- 支持多种处理策略
- 高度可定制化
关键选择:
- 根据文档数量选择 chain_type
- 配置合适的检索器参数
- 设计有效的提示模板
最佳实践:
- 使用 "stuff" 处理少量文档
- 使用 "map_reduce" 或 "refine" 处理长文档
- 添加记忆功能支持多轮对话
- 实施评估监控确保质量
通过合理配置 RetrievalQA,您可以构建出能够理解、检索和生成高质量答案的智能系统,适用于知识库问答、客户支持、研究助手等多种场景。