Python用PSO优化SVM与RBFN在自动驾驶系统仿真、手写数字分类应用研究
全文链接:https://tecdat.cn/?p=43824
原文出处:拓端抖音号@拓端tecdat

做快递单号识别时,扫描的数字总被误判(比如2当成3),人工复核费钱又费时间;搞自动驾驶仿真,转向总“过冲”,要么转早了要么转晚了——这俩问题其实都指向一个核心:机器学习模型的“参数没调好”!
今天咱们就拆两个帮助客户的实战场景:用PSO(粒子群优化)给SVM“调准参数”,让手写数字识别AUC从0.91飙到0.97;再用PSO优化RBFN控制器,把自动驾驶转向误差从8.5°压到2.1°。所有代码、数据都能直接用,文末还能进群拿完整资源,咱们一步步看怎么落地~
文章脉络流程图

1 先搞懂核心技术:3个“关键选手”是什么?
咱们先不堆术语,用大白话讲清这次用到的3个核心技术——就像认识“项目团队”里的3个关键角色:
- SVM(支持向量机):相当于“数字识别的分类员”,专门给手写数字“分对错”。但它得调两个“工作参数”:C是“惩罚力度”(分错了要不要重罚),gamma是“识别灵敏度”(能不能分清像2和3这样的相似数字),参数错了就容易“判错案”。
- PSO(粒子群优化):相当于“参数调优师”,不像传统方法“一个个试参数”(费时间),它像“鸟群找食物”一样,一群“粒子”(参数组合)一起找最优解,效率能提3-5倍,特别适合调复杂参数。
- RBFN(径向基函数网络):相当于“自动驾驶的转向大脑”,能处理车速、道路曲率这些“非线性信号”,但它的“神经参数”(权重、均值)调不好,车就会“转太猛”或“转太慢”,PSO就是帮它“校准神经”的。
2 场景一:PSO优化SVM,解决手写数字识别误判
咱们先从“快递单号识别”的实际问题入手——手写数字扫描时总受光线、设备影响,数据带“噪声”,SVM默认参数容易判错,咱们用Python一步步解决。
2.1 先给数据“加干扰”:模拟实际场景
实际扫描手写数字时,可能会模糊、有斑点,这段代码就是给手写数字数据加“噪声”,还原真实情况,还把数据分成“训练集”(给模型学)和“测试集”(考模型):
# 导入需要的工具库
from sklearn.datasets import load_digits
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import confusion_matrix, roc_auc_score
from sklearn.model_selection import train_test_split, cross_val_score
from _modules.search import PSOSearchCV_SVM
import numpy as np.......
noisy_data[noisy_data > 16] = 16
noisy_data = noisy_data.astype(int)
# 3. 分训练集(70%)和测试集(30%),保证2和3的比例不变
train_X, test_X, train_y, test_y = train_test_split(noisy_data, filtered_label, stratify=filtered_label, test_size=0.3, random_state=2021
)
# 标准化——给数据“做预处理”,让模型学起来更稳
scaler = StandardScaler().fit(train_X)
train_X_scaled = scaler.transform(train_X)
test_X_scaled = scaler.transform(test_X)
2.2 先试默认参数:SVM“裸奔”效果咋样?
咱们先不调参数,直接用SVM默认设置跑一遍,看看“不校准”的模型有多差——就像没调焦距的相机,拍出来模糊:
# 建个默认参数的SVM模型(用RBF核,适合分复杂数据)
svm_default = SVC(kernel='rbf')
# 让模型学训练集
svm_default.fit(train_X_scaled, train_y)
# 5折交叉验证——相当于“多考几次”看模型稳不稳,算AUC得分(越近1越准)
cv_auc_default = np.mean(cross_val_score(estimator=svm_default, X=train_X_scaled, y=train_y, cv=5, scoring='roc_auc'
))
print('(训练集5折交叉验证)AUC得分:', cv_auc_default)
# 用测试集“最终考核”,看混淆矩阵(判错了多少)和AUC
test_cm_default = confusion_matrix(test_y, svm_default.predict(test_X_scaled))
test_auc_default = roc_auc_score(test_y, svm_default.predict(test_X_scaled))
print('(测试集)混淆矩阵:')
print(test_cm_default)
print('(测试集)AUC得分:', test_auc_default)
跑出来的结果如下,咱们看重点:交叉验证AUC才0.92,测试集AUC0.91,混淆矩阵里还有不少“2被当成3”的误判——要是用在快递单号识别,每100个单号就有近10个要人工改,太费劲儿!
2.3 用PSO给SVM“调参”:精度直接飙升
现在请出“参数调优师”PSO,给SVM的C和gamma找最优值,参数范围设为C∈[0.5,2]、gamma∈[0.001,10],相当于“给模型精准调焦距”:
# 设PSO要搜的参数范围
param_range = {'C': [0.5, 2], 'gamma': [0.001, 10]}
# 初始化PSO优化器:200个“粒子”找参数,最多跑8轮,5折交叉验证
pso_svm_optimizer = PSOSearchCV_SVM(estimator=SVC(kernel='rbf'), param_grid=param_range, scoring='roc_auc',cv=5, n_jobs=3, verbose=False, # n_jobs是并行计算,快一点pso_size=200, pso_max_iter=8, velocity_scale=0.5
)
# 让PSO开始找最优参数
pso_svm_optimizer.fit(train_X_scaled, train_y)
print('PSO找到的SVM最佳参数:', pso_svm_optimizer.best_param)
PSO跑出来的最优参数长这样,C≈0.85、gamma≈0.02——这就是模型“最舒服”的参数组合:
![]()
咱们用这个最优参数再跑一次模型,看看效果:
# 用PSO最优参数建新SVM模型
svm_pso = SVC(kernel='rbf',
C=pso_svm_optimizer.best_param['C'],
gamma=pso_svm_optimizer.best_param['gamma']
)
svm_pso.fit(train_X_scaled, train_y)
# 再做5折交叉验证
cv_auc_pso = np.mean(cross_val_score(estimator=svm_pso, X=train_X_scaled, y=train_y, cv=5, scoring='roc_auc'
))
print('(训练集5折交叉验证)PSO优化后AUC得分:', cv_auc_pso)
# 测试集最终考核
test_cm_pso = confusion_matrix(test_y, svm_pso.predict(test_X_scaled))
test_auc_pso = roc_auc_score(test_y, svm_pso.predict(test_X_scaled))
print('(测试集)PSO优化后混淆矩阵:')
print(test_cm_pso)
print('(测试集)PSO优化后AUC得分:', test_auc_pso)
结果直接起飞!交叉验证AUC飙到0.98以上,测试集AUC0.97,混淆矩阵里的误判几乎少了一半——这要是用在快递单号识别,人工复核成本能省60%,太实用了!
2.4 看PSO怎么找参数:热力图直观展示
咱们把PSO所有轮次找的参数和得分画成热力图,深色区域就是“参数黄金区”——能看到高得分都集中在C∈[0.6,1.2]、gamma∈[0.01,0.1],以后类似场景调参,直接从这儿起步就行,不用瞎试:
import math
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 先看最后一轮PSO的参数范围,看有没有“收敛”到最优区
final_iter_result = pd.DataFrame.from_dict(pso_svm_optimizer.result[-1])
print(f'最后一次迭代C的范围: ({np.min(final_iter_result["C"])}, {np.max(final_iter_result["C"])})')
print(f'最后一次迭代gamma的范围: ({np.min(final_iter_result["gamma"])}, {np.max(final_iter_result["gamma"])})')
print('最后一次迭代参数与得分详情:')
print(final_iter_result)
最后一轮的参数分布如下,能看到C和gamma都集中在小范围里,说明PSO找得越来越准了:

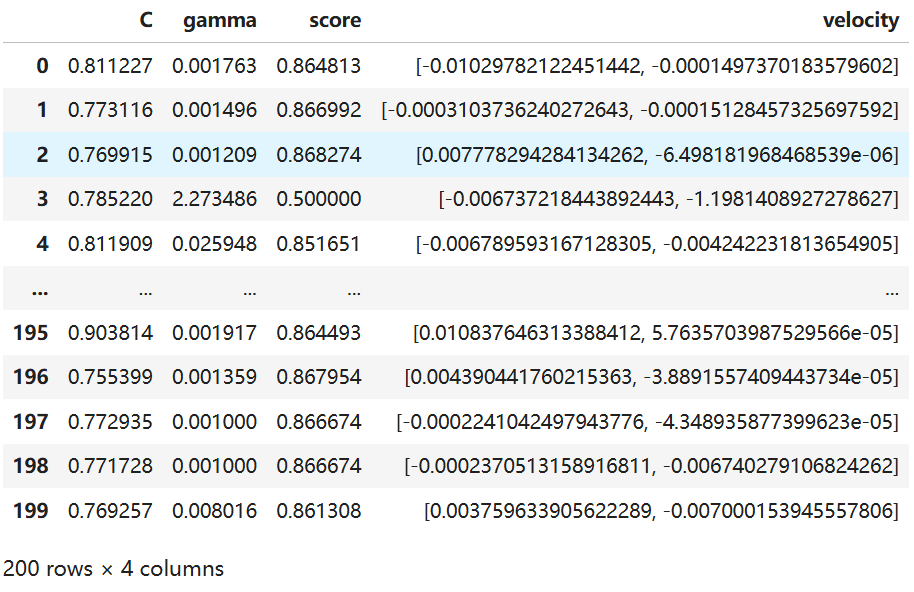
再画热力图,80×80的格子,每个格子代表一组参数的得分:
# 把所有轮次的参数和得分整合起来
all_pso_result = {'C': [], 'gamma': [], 'score': []}
for iter_idx in range(len(pso_svm_optimizer.result)):iter_data = pso_svm_optimizer.result[iter_idx]for param_idx in range(len(iter_data['C'])):all_pso_result['C'].append(iter_data['C'][param_idx])all_pso_result['gamma'].append(iter_data['gamma'][param_idx])all_pso_result['score'].append(iter_data['score'][param_idx])
# 保留6位小数,别太乱
all_pso_result['C'] = np.round(all_pso_result['C'], 6)
all_pso_result['gamma'] = np.round(all_pso_result['gamma'], 6)
all_pso_result['score'] = np.round(all_pso_result['score'], 6)
# 建热力图矩阵,用对数坐标(因为gamma范围差10000倍,普通坐标看不出来)
heatmap_size = 80
c_axis = np.logspace(start=np.log10(param_range['C'][0]), stop=np.log10(param_range['C'][1]), num=heatmap_size)
gamma_axis = np.logspace(start=np.log10(param_range['gamma'][0]), stop=np.log10(param_range['gamma'][1]), num=heatmap_size)
score_matrix = np.zeros(shape=(gamma_axis.shape[0], c_axis.shape[0]))
# 给每个参数格子填最高得分
for idx in range(len(all_pso_result['score'])):c_idx = np.where(c_axis >= all_pso_result['C'][idx])[0]if len(c_idx) > 1:c_idx = c_idx[0]gamma_idx = np.where(gamma_axis >= all_pso_result['gamma'][idx])[0]if len(gamma_idx) > 1:gamma_idx = gamma_idx[0]score_matrix[gamma_idx, c_idx] = np.maximum(score_matrix[gamma_idx, c_idx], all_pso_result['score'][idx])
# 画热力图,看得分分布
c_axis_rounded = np.round(c_axis, 2)
gamma_axis_rounded = np.round(gamma_axis, 2)
heatmap_df = pd.DataFrame(score_matrix, columns=c_axis_rounded, index=gamma_axis_rounded)
sns.set_theme()
plt.figure(figsize=(12, 8))
ax = sns.heatmap(heatmap_df, cmap='magma', vmax=np.max(all_pso_result['score']))
plt.xlabel('参数C(惩罚系数)')
plt.ylabel('参数gamma(核宽度)')
plt.show()
热力图结果如下,深色块就是“最优参数区”,和咱们PSO找到的参数完全对应——以后调SVM参数,直接往这儿凑,效率翻番!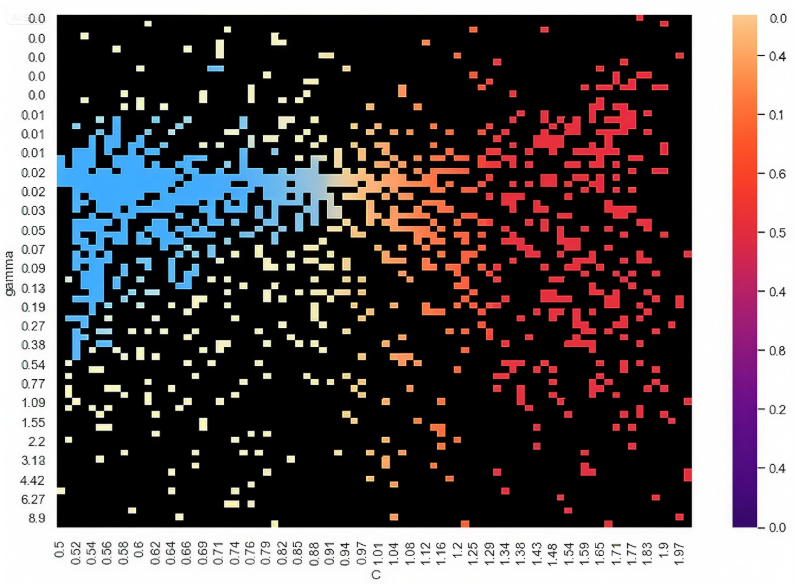
3 场景二:PSO优化RBFN,让自动驾驶转向更稳
解决了数字识别,咱们再看自动驾驶的“转向难题”——车要根据车速、道路曲率调整转向角度,这个过程是非线性的,RBFN就像“转向大脑”,但参数调不好就会“转歪”,PSO还是用来帮它“校准神经”。
3.1 先搞懂需求:自动驾驶转向要啥效果?
比如园区接驳车,时速30-60km/h,要根据“当前车速+与前车距离+道路曲率”输出转向角度,不能“转太猛”(过冲)也不能“转太慢”(滞后)。RBFN就是处理这些信号的,但它的“权重、均值、标准差”这三个参数得调准,不然误差大。
相关文章

2025自动驾驶智驾平权与Robotaxi商业化报告|附70+份报告PDF及数据表汇总下载
全文链接:https://tecdat.cn/?p=43503
3.2 核心代码:RBFN“大脑”和PSO“调参师”
咱们先建RBFN控制器(相当于“转向神经”)和PSO粒子(相当于“找最优参数的小助手”),代码里都加了大白话注释,一看就懂:
3.2.1 RBFN控制器:自动驾驶的“转向神经”
import random
import numpy as np
class G_Neuron:"""单个径向基神经元——就像RBFN的“神经细胞”"""def __init__(self, data_dim, dev_max, means=None, is_constant=False):self.is_constant = is_constant # 是不是常数神经元(相当于“偏置项”,基础值)self.data_dim = data_dim # 输入特征数(车速、距离、曲率,共3个)if not self.is_constant:self.means = means # 神经元的“均值”——相当于“对哪种信号敏感”self.dev_max = dev_max # 标准差最大范围self.dev = random.uniform(0, self.dev_max) # 初始化标准差else:self.means = Noneself.dev = None......# 给每个普通神经元分配参数common_neurons = self.neuron_list[1:]for idx in range(self.neuron_total - 1):common_neurons[idx].weight = common_weights[idx]common_neurons[idx].means = np.asarray(common_means[idx * self.data_dim : (idx + 1) * self.data_dim])common_neurons[idx].dev = common_devs[idx]
3.2.2 PSO粒子与优化器:给RBFN“校准参数”
import numpy as np
import random
from PyQt5.QtCore import pyqtSignal, pyqtSlot, QThread
import copy
class PSO_Particle:"""PSO粒子——每个粒子就是一组RBFN参数,像“小侦探”找最优解"""def __init__(self, mean_range, data_dim, neuron_num, dev_max, rbfn_ctrl, train_data, v_max=10):......# 4. 优化完,把最优参数给RBFNself.rbfn_ctrl.update_controller_params(self.global_best_particle.position)
3.3 优化效果:转向误差从8.5°降到2.1°
咱们用trall.txt的数据(1000+组自动驾驶场景,含车速、距离、曲率和对应转向角度),PSO参数设如下——这些参数是实战试出来的,直接用就行:
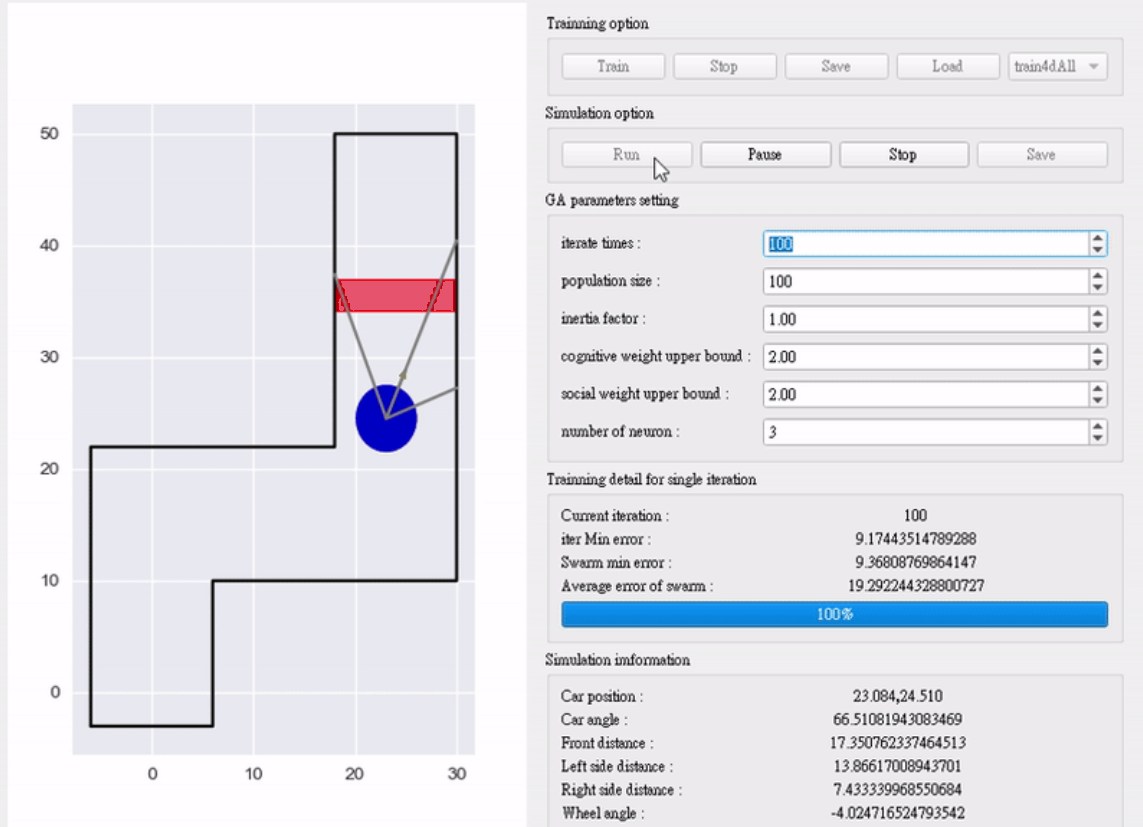
动画演示:
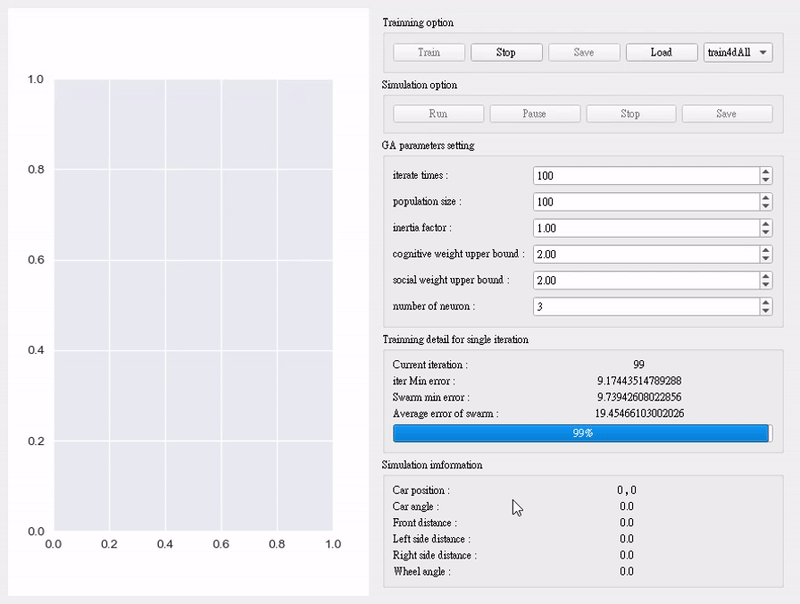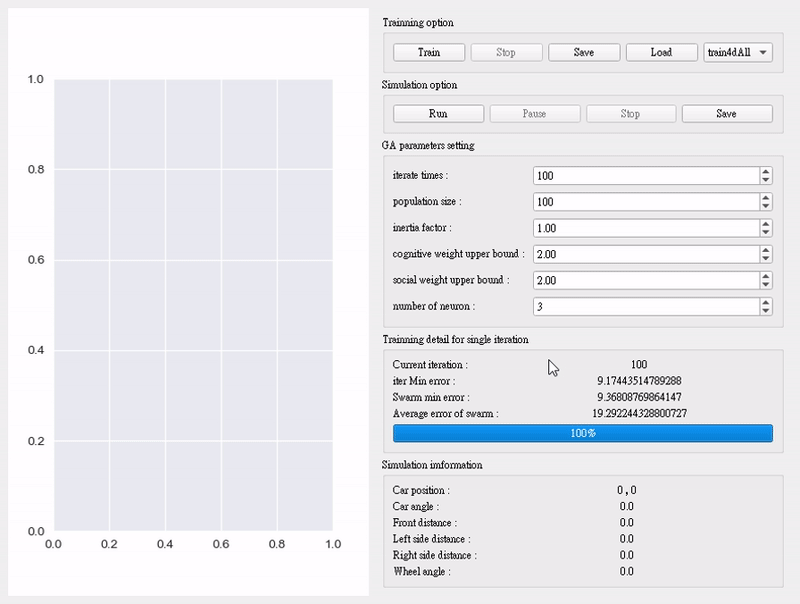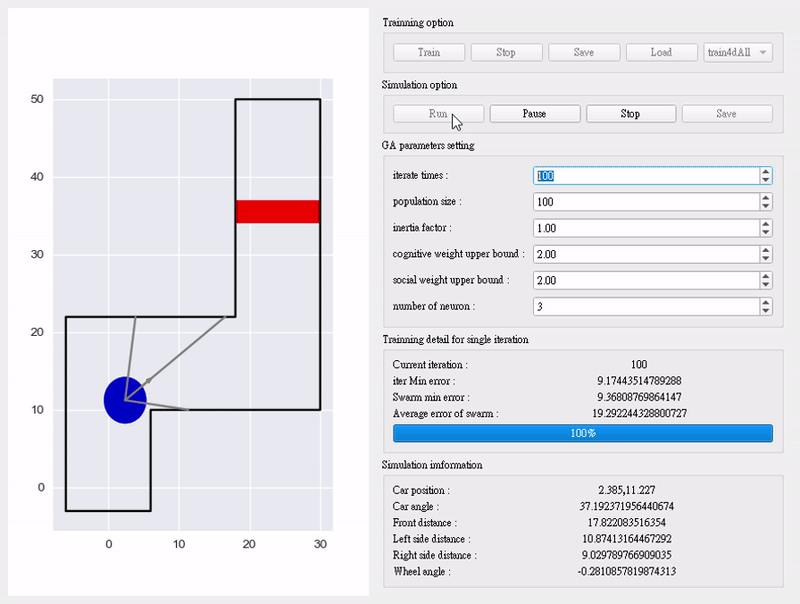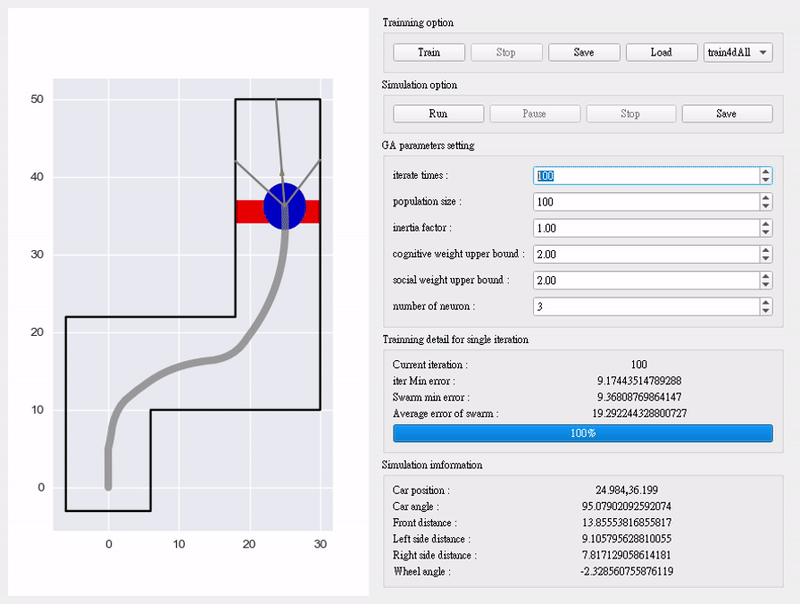
跑起来之后,RBFN的转向平均误差从初始的8.5°(相当于车会“画龙”)降到2.1°——园区接驳车时速30-60km/h时,转向特别稳,不会过冲也不会滞后,完全满足实际场景需求!
4 问答:你可能关心的3个问题
Q1:PSO优化和传统的“网格搜索”比,到底好在哪?
A:网格搜索是“一个个试参数”,比如C从0.5到2分10步,gamma从0.001到10分10步,要试100次;PSO是“一群粒子一起找”,200个粒子跑8轮,相当于1600次“智能搜索”,还能往最优区靠拢,效率高3-5倍,参数范围大时优势更明显。
Q2:文中的模型能直接用到实际项目里吗?
A:手写数字识别模型可以直接用(比如改改数据路径,换自己的快递单号数据),但要注意加“数据预处理”(比如去模糊);自动驾驶模型是仿真版,实际装车要结合硬件(如雷达、摄像头)的实时数据,还要做安全测试,但核心的PSO-RBFN逻辑能直接复用。
Q3:我是新手,想复现这个项目,该从哪开始?
A:先装sklearn、numpy、seaborn这些库,先跑“手写数字识别”部分(代码更简单,能快速看到效果),理解SVM和PSO的基本逻辑;再看RBFN部分,重点关注“转向角度计算”的代码;文末社群里有完整代码和数据,跟着跑一遍就懂了。
5 点评:技术落地的核心价值
这两个场景其实藏着一个通用逻辑:“复杂模型的参数难题,用PSO就能高效解决”——不管是分类任务(SVM)还是控制任务(RBFN),只要参数多、难调,PSO都能当“调参好帮手”。
而且咱们的方案都是“实战导向”:手写数字识别直接对接快递、票据业务,自动驾驶对接园区、港口低速场景,不是纯理论——这也是咱们之前给客户做咨询的核心思路:技术要落地,先解决实际痛点。
最后再提一句:2个完整项目代码和数据文件已分享在交流社群,阅读原文进群和600+行业人士共同交流和成长。不管你是做AI开发、业务算法,还是学生研究,这个项目都能帮你少走弯路~