Redis之分布式锁与缓存设计
1、分布式锁
1.1、超卖问题
/*** 存在库存超卖的不安全问题*/private void deductStock() {int stockTotal = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));if (stockTotal > 0) { // 这里存在多个线程、进程同时判断通过,然后超买的问题int realStock = stockTotal - 1;stringRedisTemplate.opsForValue().set("stock", realStock + "");System.out.println("扣减成功,剩余库存:" + realStock);} else {System.out.println("扣减失败,库存不足");}}
1.2、线程锁
/*** 单进程线程安全,但是多进程不安全(分布式不安全)*/private void threadStock() {synchronized (this) { // 同一进程内串行执行,因此仅在同一个进程内线程安全int stockTotal = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));if (stockTotal > 0) {int realStock = stockTotal - 1;stringRedisTemplate.opsForValue().set("stock", realStock + "");System.out.println("扣减成功,剩余库存:" + realStock);} else {System.out.println("扣减失败,库存不足");}}}
1.3、分布式锁
1.3.1、基础版
借用setnx(set if not exists)实现分布式锁
setnx的作用是:当目标key不存在时才会设置成功,否则设置失败。这样的话当多个进程同时尝试set同一个key时,同一时刻只能有一个成功。
/*** 一般添加分布式锁的方式*/private void stockLock1() {// id为10086的商品String lockKey = "stock:10086";// setIfAbsent其实就是setnx的实现Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, "locked");// 设置成功才会返回trueif (!result) {throw new RuntimeException("该商品正在被其他买家扣减库存,请稍后再试~");}try {int stockTotal = Integer.parseInt(stringRedisTemplate.opsForValue().get(lockKey));if (stockTotal > 0) {int realStock = stockTotal - 1;stringRedisTemplate.opsForValue().set(lockKey, realStock + "");System.out.println("扣减成功,剩余库存:" + realStock);} else {System.out.println("扣减失败,库存不足");}} finally {// 释放锁stringRedisTemplate.delete(lockKey);}}
这种方式存在一个死锁问题,如果进程还没执行到finally代码块中释放分布式锁的逻辑时就宕机了,会导致分布式锁一直无法释放。
1.3.2、带过期时间
/*** 带超时时间的分布式锁的方式*/private void stockLock2() {// id为10086的商品String lockKey = "stock:10086";// 设置10秒的超时时间,10秒后自动释放锁// 这里需要注意,这里是通过一行命令执行的加锁 + 超时,而不是2行。 因为如果放开为2行也会有刚加上锁,还没来得及设置超时就宕机成为死锁的情况。Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, "locked", 10, TimeUnit.SECONDS);// 设置成功才会返回trueif (!result) {throw new RuntimeException("该商品正在被其他买家扣减库存,请稍后再试~");}try {int stockTotal = Integer.parseInt(stringRedisTemplate.opsForValue().get(lockKey));if (stockTotal > 0) {int realStock = stockTotal - 1;stringRedisTemplate.opsForValue().set(lockKey, realStock + "");System.out.println("扣减成功,剩余库存:" + realStock);} else {System.out.println("扣减失败,库存不足");}} finally {// 释放锁stringRedisTemplate.delete(lockKey);}}
这里也有一个问题,如果业务在10s内没执行完,锁也释放了。这样也会出现不安全的问题。
1.3.3、锁续命(watch dog)
针对上面的情况,可以在加锁成功后,进程单独开启一个线程,每隔几秒的时间检测一下锁是否还持有,如果持有就去将锁的过期时间重置。这样就不会出现进程还持有锁,但是Redis中这个锁已经过期被强制被动释放掉的情况。
伪代码
/*** 带锁续命的分布式锁的方式*/private void stockLock3() {// id为10086的商品String lockKey = "stock:10086";// 设置10秒的超时时间,10秒后自动释放锁// 这里需要注意,这里是通过一行命令执行的加锁 + 超时,而不是2行。 因为如果放开为2行也会有刚加上锁,还没来得及设置超时就宕机成为死锁的情况。Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, "locked", 10, TimeUnit.SECONDS);// 设置成功才会返回trueif (!result) {throw new RuntimeException("该商品正在被其他买家扣减库存,请稍后再试~");}// 开启一个线程(watch dog)专门去扫描锁是否还持有new Thread(watch dog).start();try {int stockTotal = Integer.parseInt(stringRedisTemplate.opsForValue().get(lockKey));if (stockTotal > 0) {int realStock = stockTotal - 1;stringRedisTemplate.opsForValue().set(lockKey, realStock + "");System.out.println("扣减成功,剩余库存:" + realStock);} else {System.out.println("扣减失败,库存不足");}} finally {// 释放锁stringRedisTemplate.delete(lockKey);}}
watch dog的逻辑实现比较复杂,现在已经有现成的开源框架实现,直接用即可,不需要重复造比较复杂的轮子,因为容易出错。
1.3.4、redisson
这是一个类似jedis的客户端,它就实现了带watch dog很完善的分布式锁功能。
pom
<dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.6.5</version>
</dependency>
参考代码
/*** redisson*/private void stockLock4() {// id为10086的商品String lockKey = "stock:10086";//获取锁对象RLock redissonLock = redisson.getLock(lockKey);//加分布式锁redissonLock.lock(); // .setIfAbsent(lockKey, clientId, 30, TimeUnit.SECONDS);try {int stockTotal = Integer.parseInt(stringRedisTemplate.opsForValue().get(lockKey));if (stockTotal > 0) {int realStock = stockTotal - 1;stringRedisTemplate.opsForValue().set(lockKey, realStock + "");System.out.println("扣减成功,剩余库存:" + realStock);} else {System.out.println("扣减失败,库存不足");}} finally {// 释放锁redissonLock.unlock();}}
1.3.4.1、核心加锁流程
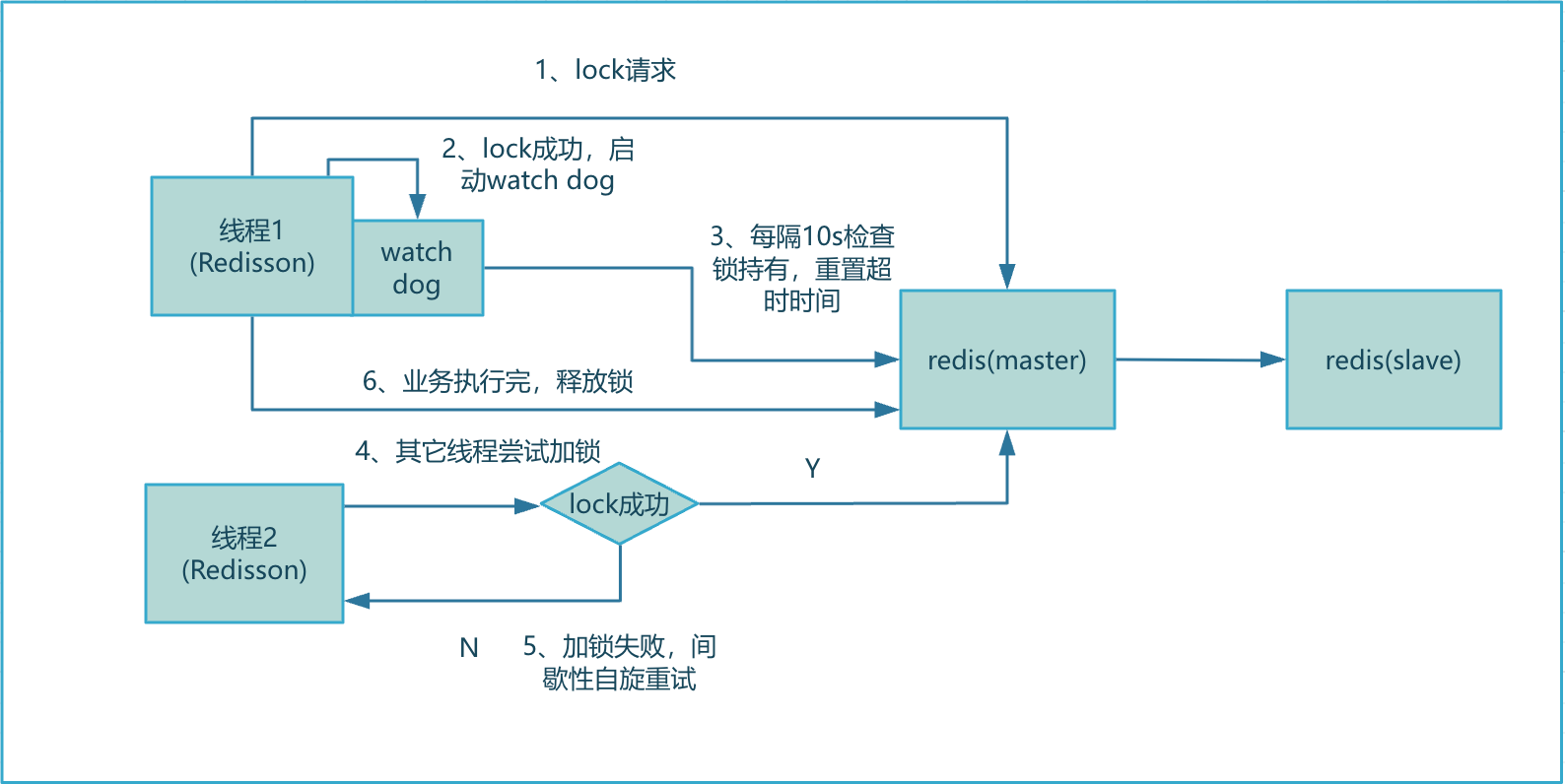
这里补充一下,锁超时时间默认30s
1.3.4.2、核心源码
加锁
<T> RFuture<T> tryLockInnerAsync(long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {internalLockLeaseTime = unit.toMillis(leaseTime);return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, command,"if (redis.call('exists', KEYS[1]) == 0) then " +"redis.call('hset', KEYS[1], ARGV[2], 1); " +"redis.call('pexpire', KEYS[1], ARGV[1]); " +"return nil; " +"end; " +"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +"redis.call('pexpire', KEYS[1], ARGV[1]); " +"return nil; " +"end; " +"return redis.call('pttl', KEYS[1]);",Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));}
核心是使用lua脚本依靠hset进行加锁 和 支持重入锁
这里提一下,lua脚本其中某个指令执行失败时不会回滚数据,但是会中断后续指令执行。 – 因此如果要回滚数据,需要lua自身保证
redis.call('set', 'key1', 'value1') -- 成功
redis.call('incr', 'key1') -- 失败(key1为字符串)
redis.call('set', 'key2', 'value2') -- 不会执行
锁续命
private void scheduleExpirationRenewal(final long threadId) {if (expirationRenewalMap.containsKey(getEntryName())) {return;}Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {@Overridepublic void run(Timeout timeout) throws Exception {RFuture<Boolean> future = commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +"redis.call('pexpire', KEYS[1], ARGV[1]); " +"return 1; " +"end; " +"return 0;",Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));future.addListener(new FutureListener<Boolean>() {@Overridepublic void operationComplete(Future<Boolean> future) throws Exception {expirationRenewalMap.remove(getEntryName());if (!future.isSuccess()) {log.error("Can't update lock " + getName() + " expiration", future.cause());return;}if (future.getNow()) {// reschedule itself 这里就是循环续命逻辑scheduleExpirationRenewal(threadId);}}});}}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);if (expirationRenewalMap.putIfAbsent(getEntryName(), task) != null) {task.cancel();}}
核心lua
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +"redis.call('pexpire', KEYS[1], ARGV[1]); " +"return 1; " +"end; " +"return 0;",
如果没过期,直接重置超时时间。
加锁失败时自旋重试
public void lockInterruptibly(long leaseTime, TimeUnit unit) throws InterruptedException {long threadId = Thread.currentThread().getId();Long ttl = tryAcquire(leaseTime, unit, threadId);// lock acquiredif (ttl == null) {return;}RFuture<RedissonLockEntry> future = subscribe(threadId);commandExecutor.syncSubscription(future);try {while (true) {ttl = tryAcquire(leaseTime, unit, threadId);// lock acquiredif (ttl == null) {break;}// waiting for messageif (ttl >= 0) {// 等待上一把锁超时,这里会阻塞ttl超时的时间,这里使用的Semaphore,会阻塞时会让出CPU时间片// 这里有一个巧妙的地方,如果目标锁提前释放,这里就会提前退出阻塞。不会固定等ttl时间getEntry(threadId).getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);} else {getEntry(threadId).getLatch().acquire();}}} finally {unsubscribe(future, threadId);}
// get(lockAsync(leaseTime, unit));}
锁释放
本质上是用到了Redis的发布订阅功能,也就是Stream流类型。
protected RFuture<Boolean> unlockInnerAsync(long threadId) {return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,"if (redis.call('exists', KEYS[1]) == 0) then " +// 锁不存在时,会发布一个锁释放的Stream事件, 这样Java客户端就可以感知到,走释放逻辑,提前通知其它线程可以尝试获取锁了"redis.call('publish', KEYS[2], ARGV[1]); " +"return 1; " +"end;" +// 使用线程ID判断是否锁是自己线程加的,如果不是则不进行后续处理// 防止其它线程因为代码错误或者恶意直接释放代码// 这里需要注意,getLockName(threadId) 实际上是uuid + 线程id,能保证唯一"if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then " +"return nil;" +"end; " +// 重入锁逻辑,释放一重锁,依旧会重置超时时间"local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); " +"if (counter > 0) then " +"redis.call('pexpire', KEYS[1], ARGV[2]); " +"return 0; " +"else " +"redis.call('del', KEYS[1]); " +"redis.call('publish', KEYS[2], ARGV[1]); " +"return 1; "+"end; " +"return nil;",Arrays.<Object>asList(getName(), getChannelName()), LockPubSub.unlockMessage, internalLockLeaseTime, getLockName(threadId));}
1.3.5、锁优化
上面的方式本质上就是将请求串行化,这样的话并发会一点起不来。为了保证数据安全的同时,又要提供并发,可以从锁粒度上面去思考,例如一个商品100个库存,是否可以将这个商品拆成5个锁,每个锁管20个库存,这样的话就可以支持五个并发了(分段锁)
2、缓存设计
2.1、需要注意的问题
2.1.1、缓存穿透
一般情况下,会将从数据库中查询到的数据放到Redis缓存中,然后下次查询时在缓存中能查到该条数据,就直接返回。
但是这里存在一个特殊的情况,如果对应数据确实在Redis缓存和数据库中都不存在,那么每次空查询都会打到数据库中,导致数据库压力剧增。 - 这种情况,Redis缓存就失去了保护作用,即缓存穿透。
造成这种情况的原因:
1、业务代码本身问题,导致正常的数据一直查不到数据,或者没有放入缓存。
2、恶意攻击,或者爬虫,产生大量恶意空查询。
解决方案
1、将空对象也缓存到本地缓存之中,然后设置缓存淘汰策略。
public static String get(String key) {// 从缓存中获取数据String cacheValue = cache.get(key);// 缓存为空if (StringUtils.isBlank(cacheValue)) {// 从存储中获取String storageValue = storage.get(key);cache.set(key, storageValue);// 如果存储数据为空, 需要设置一个过期时间(300秒)if (storageValue == null) {cache.expire(key, 60 * 5);}return storageValue;} else {// 缓存非空return cacheValue;}}
本地缓存比Redis缓存还快,加上设置淘汰策略,能更好的屏蔽掉无效请求。
2、使用布隆过滤器
布隆过滤器作用:如果认为一个请求存在,那么这个请求可能不存在。但是如果认为一个请求存在,那么这个请求必然不存在。
布隆过滤器本身就是一个很大的位数组 + 一个无偏的hash函数构成。能够将对应key值通过函数分摊到位数组中的不同位。 这样仅需要检查对应key是否在位数组中存在重合,就可以判定是否存在。
使用布隆过滤器的场景:数据量大(实时性低)、数据命中率不高、数据相对固定(没有频繁增量数据)的场景。另外值得一提的是,布隆过滤器属于CPU换空间,占用的内存很低。
注意:已经加入布隆过滤器的数据不能移除,除非重构布隆过滤器。
示例(基于Redisson)
public static void main(String[] args) {Config config = new Config();config.useSingleServer().setAddress("redis://localhost:6379");//构造RedissonRedissonClient redisson = Redisson.create(config);RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");//初始化布隆过滤器:预计元素为100000000L,误差率为3%,根据这两个参数会计算出底层的bit数组大小bloomFilter.tryInit(100000L, 0.03);//将zhuge插入到布隆过滤器中bloomFilter.add("wangxiaoyi");bloomFilter.add("hh");//判断下面号码是否在布隆过滤器中System.out.println(bloomFilter.contains("wangxiaoyi"));//trueSystem.out.println(bloomFilter.contains("3"));//false}
即使使用布隆过滤器,也有插入数据需要删除布隆过滤器中某个key的场景。好像可以使用内存增加几倍的变种过滤器。
2.1.2、缓存击穿(失效)
一般将数据放到缓存中时会设置过期时间,这里存在一个问题,如果大量的缓存在一个集中的时间被加载,那么也会存在同一时刻大量的失效。缓存失效就意味着大量的请求会直接打到数据库,这也会导致数据库瞬间压力剧增。 这就是缓存失效造成的击穿缓存。
解决方案的话,可以给缓存的过期时间设置一个波动区间,这样的话在同一时间失效的数据量就会小很多。
另外就是,基本上热点数据相对冷数据较少,也可以在每次查询时,给对应key进行过期时间续期,这样也能更快的分离冷热数据。
示例
public static String get(String key) {// 从缓存中获取数据String cacheValue = cache.get(key);// 缓存为空if (StringUtils.isBlank(cacheValue)) {// 从存储中获取String storageValue = storage.get(key);cache.set(key, storageValue); //设置一个过期时间(300到600之间的一个随机数)int expireTime = new Random().nextInt(300) + 300;if (storageValue == null) {cache.expire(key, expireTime);}return storageValue;} else {// 缓存非空return cacheValue;}}
2.1.3、缓存雪崩
有一句话:雪崩之下,没有一篇雪花是无辜的。
在这里,对应的也就是,当redis中存在某个bigkey,或者网络波动导致响应变慢。这样就会导致第一个请求拉慢第二个请求,第二个拉慢第三个。 最终导致整体响应变慢,最后Redis被拉垮(或者说Redis直接蹦掉),服务调用链一层影响一层,最终整个系统不再响应,最终触发OOM崩掉。 – 这就是缓存雪崩,由一片超时雪花造成。
解决方向
1、保证Redis的高可用,例如主从哨兵、集群。
2、支持服务限流、熔断。比如使用Sentinel或Hystrix限流降级组件。
如果是非核心业务,例如用户信息,则可以暂时直接返回友好的提示。 如果是核心业务,则考虑限流,允许小水细流的请求直接查询数据库。
3、把本地缓存也使用起来,先查本地缓存,再查Redis,这样也可以过滤一波大流量。这里需要对本地缓存的淘汰策略有严格控制。
2.1.4、热点缓存重建
查询数据都是先查询缓存,再查询数据库。 如果突然除了一个热点key,被大量的请求同时访问,这时就会出现大量的请求都没有被缓存挡住(缓存还没被及时加载到缓存中),那么这些大量的请求就直接打到数据库中了,这样也会导致数据库压力突增。 – 这里要做的就是在key从数据库加载到缓存的操作需要控制在第一个到达的请求来做,其它请求要么阻塞,要么直接拒接。 这就是热点缓存重建策略。
示例
public static String get(String key) {// 从Redis中获取数据String value = redis.get(key);// 如果value为空, 则开始重构缓存if (value == null) {// 只允许一个线程重建缓存, 使用nx, 并设置过期时间exString mutexKey = "mutext:key:" + key;if (redis.set(mutexKey, "1", "ex 180", "nx")) {// 从数据源获取数据value = db.get(key);// 回写Redis, 并设置过期时间redis.setex(key, timeout, value);// 删除key_mutexredis.delete(mutexKey);}// 其他线程休息50毫秒后重试else {Thread.sleep(50);get(key);}}return value;}
2.1.5、缓存与数据库双写不一致
出现双写不一致的原因:先来的请求,在给Redis发请求时,不一定就先执行,存在被其他Redis请求加塞的情况,因为网络、CPU等因素都是不确定的,会造成写丢失。
解决方案
1、对于并发度很小的数据(比如个人维度的购物车,订单),可以不用考虑这个问题,按照常规的设置缓存过期时间,到时失效后,就会重新写缓存最新的数据。
2、就算并发度很高,有些数据也是能容忍短暂的数据不一致的,例如商品名称。
3、如果必须要保证一致性,就需要加Redis读写锁。
4、也可以使用阿里开源的canal通过监听数据库binlog的方式,及时去修改缓存,但是这样的话就引入了新的中间件,增加了系统的复杂度,同时在读的时候存在一定时间的延迟。
2.1.6、总结
1、使用Redis缓存的应该主要是读多写少的场景。
2、如果是写多读也多的场景,并且还有保证数据强一致性就没有必要十余年缓存了,直接使用数据库。
3、如果确实数据库抗不住,就只能将Redis作为读写主存,异步将数据同步给数据库,这时的数据库是作为一个备份的角色。 总之就是同步扛不住就只能转异步(例如RabbitMQ),或者限流。
4、总之,Redis是用来缓存,解决那些能容忍一点时间不一致的数据查询压力的,如果为了其它一致性过度设计就得不偿失了。