RabbitMQ之死信队列
RabbitMQ之死信队列
死信队列(Dead Letter Queue, DLQ)是 RabbitMQ 中处理失败消息的核心容灾机制,但若处理不当,它本身可能成为新的问题源。以下是系统化的 DLQ 处理策略:
一、DLQ 触发原因与识别
消息进入死信队列通常由以下条件触发:
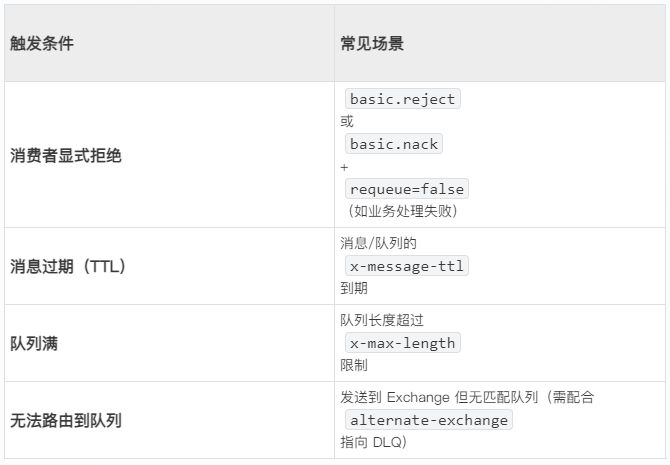
二、DLQ 处理核心原则
1.DLQ 不是终点,而是起点错误认知:把 DLQ 当作“垃圾堆”正确做法:DLQ 是消息修复的缓冲区,必须闭环处理
2.核心目标✅ 定位故障原因 → 修复业务逻辑 → 安全重试消息
三、DLQ 处理流程(四步法)
图片代码消费者拒绝TTL过期队列满监控DLQ深度分析死信原因检查消费者日志/错误调整TTL或处理逻辑扩容消费者或削峰C/F/G修复代码安全重试消息确认业务恢复
步骤 1:监控告警(预防积压)
通过RabbitMQ API监控DLQ深度
curl -u user:pass http://rabbitmq:15672/api/queues/%2F/dlq-orders | jq ‘.messages’
- 关键指标:
- DLQ 深度 > 0 时触发告警
- 深度增长速率异常(如突然飙升)
- 工具建议:
- Prometheus + Grafana(RabbitMQ Exporter)
- Datadog/Elasticsearch 日志分析
步骤 2:死因分析(定位根源)
从DLQ消费消息并提取死信原因(Python示例)
def callback(ch, method, properties, body):
dead_reason = properties.headers.get(‘x-death’)[0][‘reason’]
if dead_reason == ‘rejected’:
print(f"被拒绝: {body}, 原始队列: {method.routing_key}“)
elif dead_reason == ‘expired’:
print(f"TTL过期: {body}, 存活时间: {properties.expiration}ms”)
步骤 3:修复逻辑(代码层)
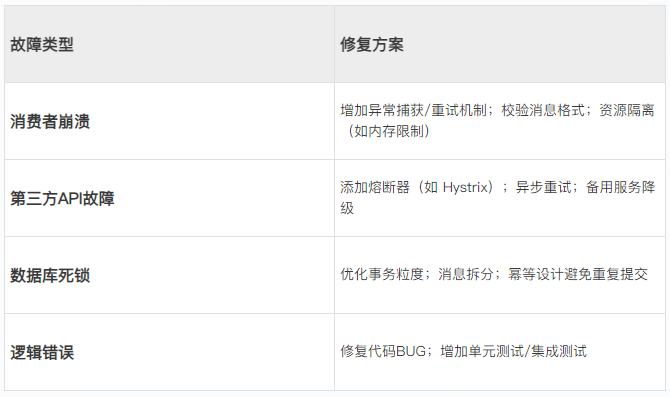
步骤 4:安全重试(3种方案)
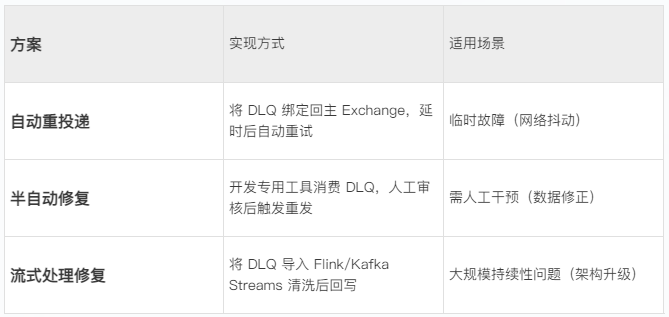
自动重试工具示例:
// 将死信重新发布到原始队列(带延时)
channel.basicPublish(
“dlx-repair-exchange”, // 专用修复Exchange
originalRoutingKey, // 从死信Header提取原始路由键
new AMQP.BasicProperties.Builder()
.headers(properties.getHeaders())
.expiration(“30000”) // 延时30秒重试
.build(),
body
);
四、进阶:防雪崩设计
1.独立消费者组DLQ 消费者需与主业务隔离(避免占用正常资源)
2.渐进重试策略
markdown复制第1次重试 → 立即
第2次重试 → 5分钟后
第3次重试 → 30分钟后
第4次及以上 → 人工介入
3.熔断机制若重试成功率 < 10%,暂停重试并发出告警
五、处理永远无法消费的消息
1.归档死信
将消息转储到持久化存储
rabbitmqadmin get queue=dlq-orders count=100
requeue=false > /backup/dlq_$(date +%s).json
2.设置最终失效期对死信队列声明 TTL:x-message-ttl: 2592000000 (30天)到期后自动删除
最佳实践总结
1.监控先行:DLQ 深度 >0 即告警
2.闭环处理:分析 → 修复 → 重试 → 验证
3.安全重试:渐进延时 + 重试次数控制
4.防止污染:隔离 DLQ 消费者资源
5.最终清理:归档/自动删除不可修复消息
⚠️ 切记:DLQ 暴露的是系统脆弱点。超过 5% 的消息进入 DLQ 即表明架构存在严重缺陷,需彻底排查而非简单重试。