KDD 2025 | TIDFormer:针对时序交互动态机制,构建动态图 Transformer 模型
得益于自注意力机制(SAM)在序列建模中捕捉依赖关系的卓越能力,现有多种动态图神经网络(DGNN)采用具有不同编码设计的 Transformer 架构,以捕捉动态图的序列演化特征。然而,这些基于 Transformer 的 DGNN 在效能与效率上存在显著差异,这凸显了正确定义动态图上的自注意力机制、以及在不引入额外复杂模块的前提下全面编码时序动态与交互动态的重要性。
中国人民大学与华为研究团队提出 TIDFormer,这是一种高效利用时序动态与交互动态的动态图 Transformer 模型。研究者阐明并验证了所提出自注意力机制的可解释性,解决了以往研究中动态图注意力定义不可解释的开放性问题。为分别建模时序动态与交互动态,研究者采用基于日历的时间划分信息,并仅通过采样一阶邻域为二分图与非二分图提取信息丰富的交互嵌入表示。此外,还通过简单分解捕获历史交互模式的潜在变化,实现了时序特征与交互特征的联合建模。研究者在多个动态图数据集上进行了广泛实验,验证了 TIDFormer 的有效性与高效性。实验结果表明,TIDFormer 在大多数数据集和实验设置下均优于现有最优模型,表现出卓越性能。同时,与先前基于 Transformer 的方法相比,TIDFormer 展现出显著的效率优势。

【论文标题】
TIDFormer: Exploiting Temporal and Interactive Dynamics Makes A Great Dynamic Graph Transformer
【论文地址】
https://arxiv.org/abs/2506.00431
论文背景
由于 SAM 在序列建模中捕捉依赖关系的卓越能力,现有的几种动态图神经网络(DGNN)采用具有各种编码设计的 Transformer 架构来捕捉动态图的序列演化。然而,这些基于 Transformer 的 DGNN 的有效性和效率差异显著,突显了在动态图上正确定义 SAM 以及在不增加额外复杂模块的情况下全面编码时间和交互动态的重要性。本文研究者提出了 TIDFormer,这是一种以高效方式充分利用时间和交互动态的动态图 Transformer。该工作阐明并验证了所提出 SAM 的可解释性,解决了先前工作中在动态图上定义不明确的问题。
本文将动态图学习方法分为离散时间动态图(DTDG)和连续时间动态图(CTDG)两类,并选择聚焦于 CTDG 研究,因其能提供更精细的时间演化表示。现有 CTDG 方法存在三大核心问题:首先是 SAM 在动态图上的定义缺乏解释性,特别是 DyGFormer 等模型混合源节点和目标节点序列的做法破坏了原始时序关系;其次是时间动态建模不足,现有方法如余弦编码无法捕捉时间数据的阶段性和周期性特征,而 FreeDyG 的频域方法又带来过高计算成本;最后是交互动态建模的缺陷,现有方法大多忽略节点对间交互信息,且在二分图场景下表现不佳。
针对这些问题,TIDFormer 实现三大创新:
设计了解释性强的交互级别 SAM,解决了先前工作中 SAM 定义不明确的问题;
开发了混合粒度时间编码(MTE)、双向交互编码(BIE)和季节趋势编码(STE)三个模块来全面建模动态特征;
构建了高效架构,仅用一阶邻居采样就实现了性能提升。
这些创新使 TIDFormer 在保持高效率的同时,显著提升了模型性能,为动态图 Transformer 提供了明确的设计准则,特别是在处理二分图场景和时间序列图数据方面展现出独特优势。
TIDFormer方法
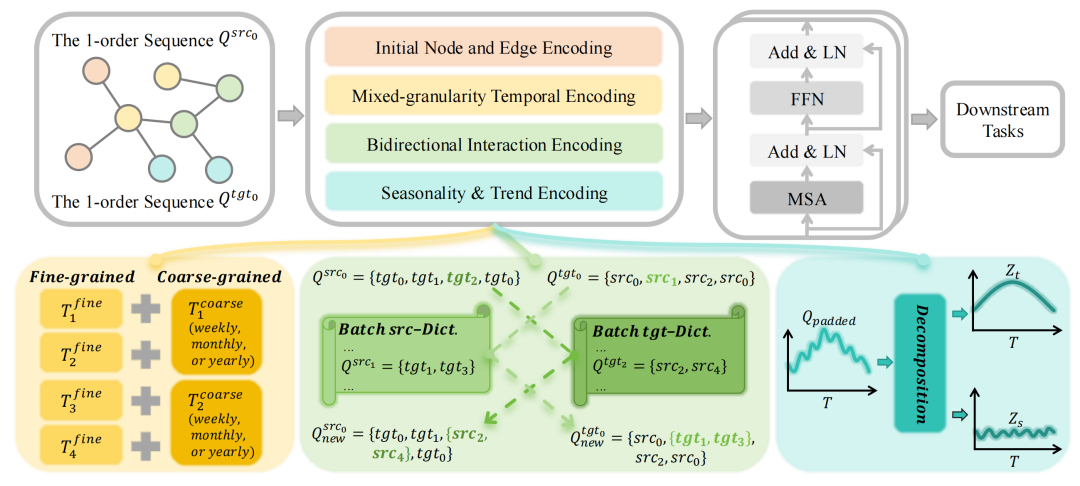
图1:TIDFormer 模型架构图
01/可解释的自注意力机制(IL-SAM)
研究者创新性地提出了"交互级别"(Interaction Level)的 SAM 定义,相比传统的"单节点级别"(SL)和"多节点级别"(ML)具有显著优势:
保持时序完整性:不混合源节点和目标节点序列,维护原始交互时序
增强解释性:如图3所示,IL-SAM 能更准确地学习高频交互节点的注意力权重
任务适配性:特别适合链接预测等需要成对节点交互信息的任务

图2:不同层级动态图上三种类型 SAM 的示意图

图3:展示在MOOC数据集上从训练开始到结束时,三种类型 SAM 关键节点的注意力权重情况
02/三重动态编码模块
(1)混合粒度时间编码(MTE)
同时利用细粒度时间戳和粗粒度日历信息(周/月/年),解决了传统余弦编码无法捕捉阶段性特征的问题。
MTE模块的创新之处在于同时利用两种时间信息:
细粒度时间戳:采用计算相对时间间隔,使用进行编码。
粗粒度日历分区:根据数据集时间跨度选择周/月/年分区,计算并通过编码。
这种双粒度设计能同时捕捉短期波动和长期趋势,相比单一时间编码显著提升了时间动态建模能力。
(2)双向交互编码(BIE)
BIE模块通过创新的双向重构机制解决了二分图场景下的信息瓶颈:
动态字典设计:维护 src-Dict 和 tgt-Dict 两个动态字典存储批次内节点的一阶邻居。
双向检索:对源节点序列 和目标节点序列 进行双向转换,通过检索获取二阶邻居信息。
高效重构:仅使用一阶采样即可获得高阶邻居信息,计算成本显著低于显式的高阶采样。
该模块在保持高效率的同时,大幅提升了模型对交互动态的建模能力,特别是在用户-物品等二分图场景下表现突出。
(3)季节趋势编码(STE))
通过简单的平均池化分解,将交互模式分离为季节性部分和趋势部分,联合建模时间和交互动态。
这种分解策略为理解动态图中复杂的交互演化模式提供了新视角。
实验结果
01/性能分析
在7个真实动态图数据集上评估模型性能,包括 Wikipedia、Reddit、MOOC、LastFM、Enron、Social Evolution 和 UCI 数据集。
在链接预测任务上,TIDFormer 在大多数数据集上超越现有 SOTA 模型;
在节点分类任务上 TIDFormer 在多个数据集上的分类准确率显著优于基线模型,特别是在 Social Evolution 数据集上达到97.44%的 AP 值,比原 SOTA 提升0.9个百分点,验证了模型的通用性。
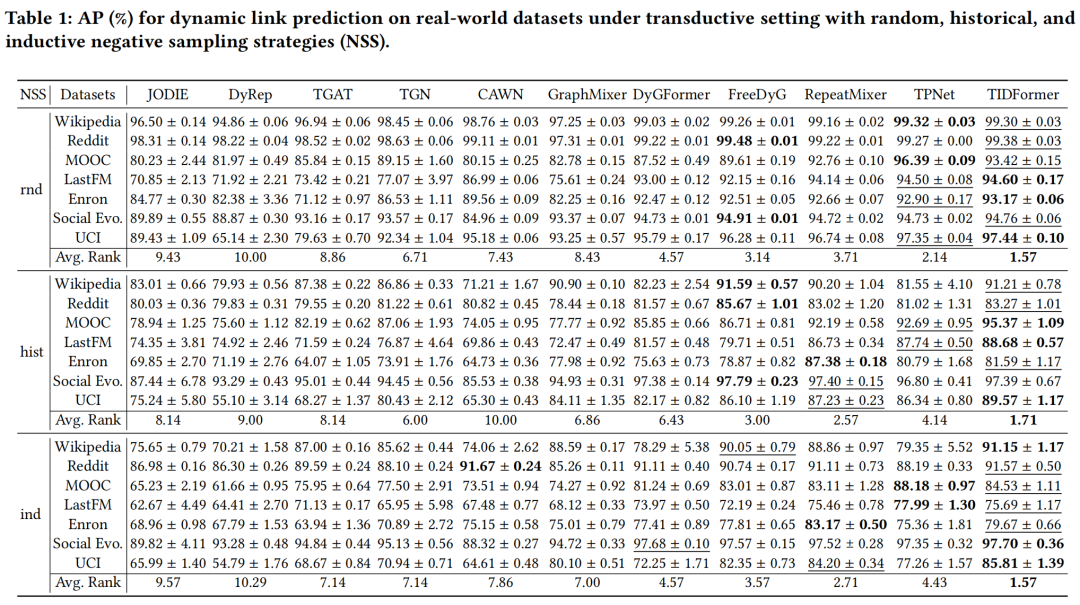
02/消融研究
如图4(橙色)所示,研究者系统比较了三种 SAM 结构的效果:在 MOOC 数据集上,IL-SAM 相比 ML-SAM 和 SL-SAM 分别带来5.2%和8.7%的性能提升,这种差距在数据稀疏时更为明显。
图4(黄色/绿色/青色部分)还展示了各编码模块的贡献度:完整模型组合的效果显著优于任何单一模块或简化版本,证明了整体架构设计的协同效应。
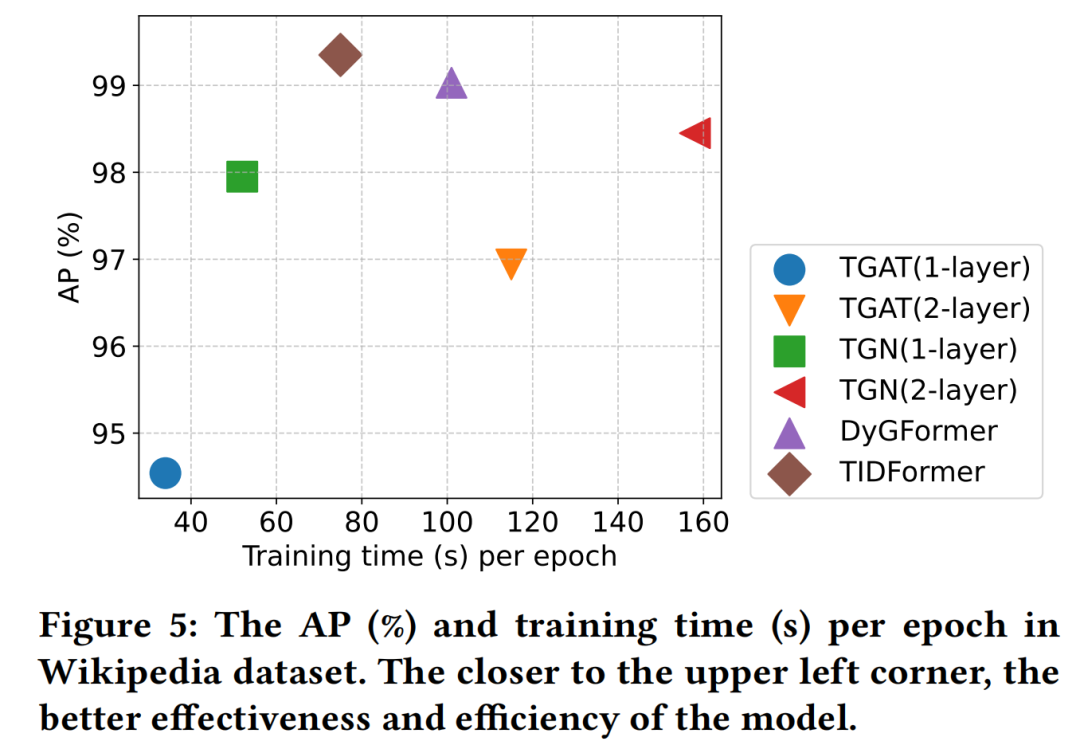
03/效率分析
如图5所示,TIDFormer 在保持高性能的同时展现出卓越的效率:
训练速度:比 DyGFormer 快1.7倍,比 FreeDyG 快2.3倍;
内存占用:仅为一阶采样基线(TGAT 1-layer)的1.2倍,远低于二阶采样方法;
可扩展性:在 Wikipedia 数据集上处理百万级边仅需0.8小时,适合大规模应用。
这种效率优势主要源于:(1)避免显式高阶采样;(2)编码模块的轻量级设计;(3)优化的Transformer实现。
总结
本文提出了一种基于 Transformer 的动态图模型 TIDFormer,该模型能够充分挖掘时序动态和交互动态。针对动态图中自注意力机制模块(SAM)定义难以解释这一开放性问题,首先在交互层面明确了其具体结构,并通过实验验证了其可解释性。本文提出的 TIDFormer 配备了三个简单而有效的编码模块:多时序嵌入(MTE)模块、双向交互嵌入(BIE)模块和结构时序嵌入(STE)模块。这些模块仅利用采样的一阶邻居,就能全面捕捉时序动态和交互动态。研究者在多个动态图数据集上进行了大量实验,以验证 TIDFormer 的有效性和高效性。实验结果表明,TIDFormer 表现出色,在大多数数据集和实验设置下均优于现有 SOTA 模型。
另外我们打磨了一套的 AI人工智能入门到实战学习路线(已经迭代过13次),包含计算机视觉、机器学习、深度学习和自然语言处理等等,还会新增热门技术点,根据规划好的路线学习只需4-6个月左右(很多同学通过学习已经发表了 sci 二区及以下、ei会议等级别论文)【也能带着打天池、kaggle等竞赛】
能够提升大家这些科研能力:
- AI+项目的认知能力
- 编程基础(环境基础、语言基础、各种数据库的调用基础)
- AI+相关机器学习/深度学习的底层原理
- 其中针对你的方向的算法的搭建、训练和优化能力
- 就是结合你自己的任务场景做项目的复现能力
- 最后就是做自己项目的能力以及实现独立实现项目提升能力




另外如果你想发高区论文的话我们也有对应的指导方式,大家需要的话可以添加助教老师,通过后咨询即可!欢迎大家前来咨询!
