LRU 算法和 LFU 算法有什么区别?
核心区别:淘汰依据不同
这是最根本的区别,决定了它们在不同场景下的适用性
LRU (Least Recently Used - 最近最少使用)
淘汰依据:访问时间。它认为最近被访问过的数据,在将来被再次访问的可能性更大。因此,它淘汰的是“最久未被访问”的数据。
LFU (Least Frequently Used - 最不经常使用)
淘汰依据:访问频率。它认为过去被访问次数越多的数据,在将来被再次访问的可能性更大。因此,它淘汰的是“历史访问次数最少”的数据。
对比表格
| 特性 | LRU (最近最少使用) | LFU (最不经常使用) |
|---|---|---|
| 淘汰依据 | 访问时间 (最后一次访问距今多久) | 访问频率 (历史访问总次数) |
| 优点 | 对突发性的、偶尔的访问敏感,能快速反应最新的访问模式。 | 能更好地识别出真正的热点数据,长期来看更稳定。 |
| 缺点 | 无法应对缓存污染。一次性的大量扫描会使旧的热点数据被挤出。 | 对突发流量不敏感。一个新热点数据需要累积足够多的访问才能不被淘汰。可能存在“历史包袱”,即过去很热但现在不用的数据长期占据缓存。 |
| 适用场景 | 访问模式相对随机,近期访问的数据更可能被再次访问。 | 有明确热点数据,访问模式相对稳定,需要区分高频和低频访问。 |
| 类比 | “记性差”:只记得谁最近来过。 | “记性好”:记得谁来得最多。 |
Redis 中的实现与优化
传统的链表式LRU实现有性能问题,所以Redis进行了优化。
Redis 的 LRU 实现
typedef struct redisObject {...// 24 bits,用于记录对象的访问信息unsigned lru:24; ...
} robj;问题:为所有数据维护一个全局LRU链表,每次访问都要移动节点,性能开销巨大。
解决方案:近似LRU + 随机采样。
在每个对象的
lru字段中记录其最后一次访问的时间戳。当需要淘汰数据时,随机抽取
N个key(maxmemory-samples配置,默认5),而不是遍历所有key。从这N个key中淘汰掉lru字段值最小(即最久未被访问)的那个key。
优点:
性能极高,接近O(1)。
缺点:
可能无法淘汰掉真正最久未使用的key,但通过增大采样数N可以接近真实LRU的效果。
Redis 的 LFU 实现
为了解决LRU的“缓存污染”问题,Redis 4.0引入了LFU算法。
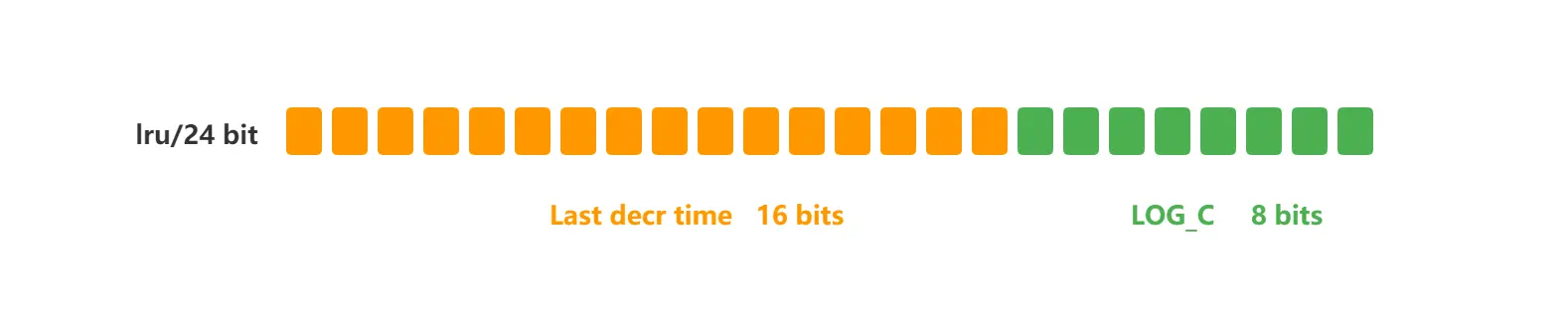
核心挑战:如何在一个有限的字段(24 bits的
lru)里同时存储访问频率和访问时间?解决方案:将24 bits的
lru字段拆分成两部分:高16位:存储最近一次访问的时间戳(分钟级精度)。
低8位:存储一个访问频次计数器(counter)。最大值255,所以它不是一个绝对次数,而是一个概率增长的相对值。
计数器的增长策略(概率递增):
计数器不是每次访问都+1,而是遵循一个概率规则:计数器值越大,增长越困难。
公式类似于:
概率 = 1 / (counter当前值 * lfu_log_factor + 1)。lfu_log_factor是可配置因子。这样设计是因为8位空间有限,必须谨慎使用。一个key访问1次和1000次应该有明显区别,但访问10000次和10001次可能就没必要区分了。
计数器的衰减机制:
为了解决“历史包袱”问题(一个曾经很热但现在冷的数据长期不被淘汰),LFU设计了衰减机制。
它会根据当前时间与
lru高16位记录的时间的差值来减少计数器值。通过
lfu-decay-time配置一个衰减周期,如果某个key经过N个周期都没有被访问,那么它的计数器值就会减半(或按规则减少)。这样,一个不再受欢迎的老热点,其频率值会逐渐降低,最终被淘汰掉。
总结:
- LRU vs LFU:本质是 “时间” 与 “频率” 的权衡。LRU更适合判断“最近谁有用”,LFU更适合判断“谁一直有用”。
- Redis的实现:两者都使用了
lru字段,但用途截然不同。LRU用它存时间戳,LFU用它高存时间戳、低存频率值,并辅以概率递增和时间衰减机制,在有限的空间内巧妙地实现了高效的LFU算法。 - 如何选择:如果你的业务模式是“最新访问的就是最热的”(如新闻feed),用LRU。如果你的业务有稳定的长效热点(如热门商品、明星资讯),用LFU能更好地抵抗扫描式查询带来的缓存污染。