ViGAS、RAF、DiFF-RIR论文解读
目录
一、ViGAS
1、概述
2、方法
3、实验
二、RAF
1、概述
2、方法
3、实验
三、DiFFRIR
1、概述
2、方法
这三个论文都是在神经声场上探索稀疏数据下如何高质量重建,真实场景下的进展,ViGAS定义了新视角声学合成(NVAS)工作,构建了大规模多视角视听数据集Replay-NVAS和SoundSpaces-NVAS。RAF则是建立更高精度的真实数据集RAF,先在仿真数据集上预训练,再通过少量真实样本微调。DiffRIR是探索极稀疏下的声场重建。
这三个论文均不涉及光场合成,ViGAS(单视图+音频),RAF(多视图+密集RIR)视觉数据仅仅是作为输入辅助声学建模,DiFFRIR甚至无需图像输入。
一、ViGAS
1、概述
motivation:传统新视角合成(NVS)仅关注视觉重建,忽略声音的空间化问题。NVAS任务旨在通过单视角的视听输入,合成目标新视角的空间音频,解决AR/VR中沉浸式听觉体验的缺失。
contribution:提出新视角声学合成(NVAS),构建了大规模多视角视听数据集Replay-NVAS和SoundSpaces-NVAS,均包括说话人物动作,人物运动,而不是只用音响或仿真音响模拟,一个是真实录制,一个是虚拟场景。
2、方法
数据集
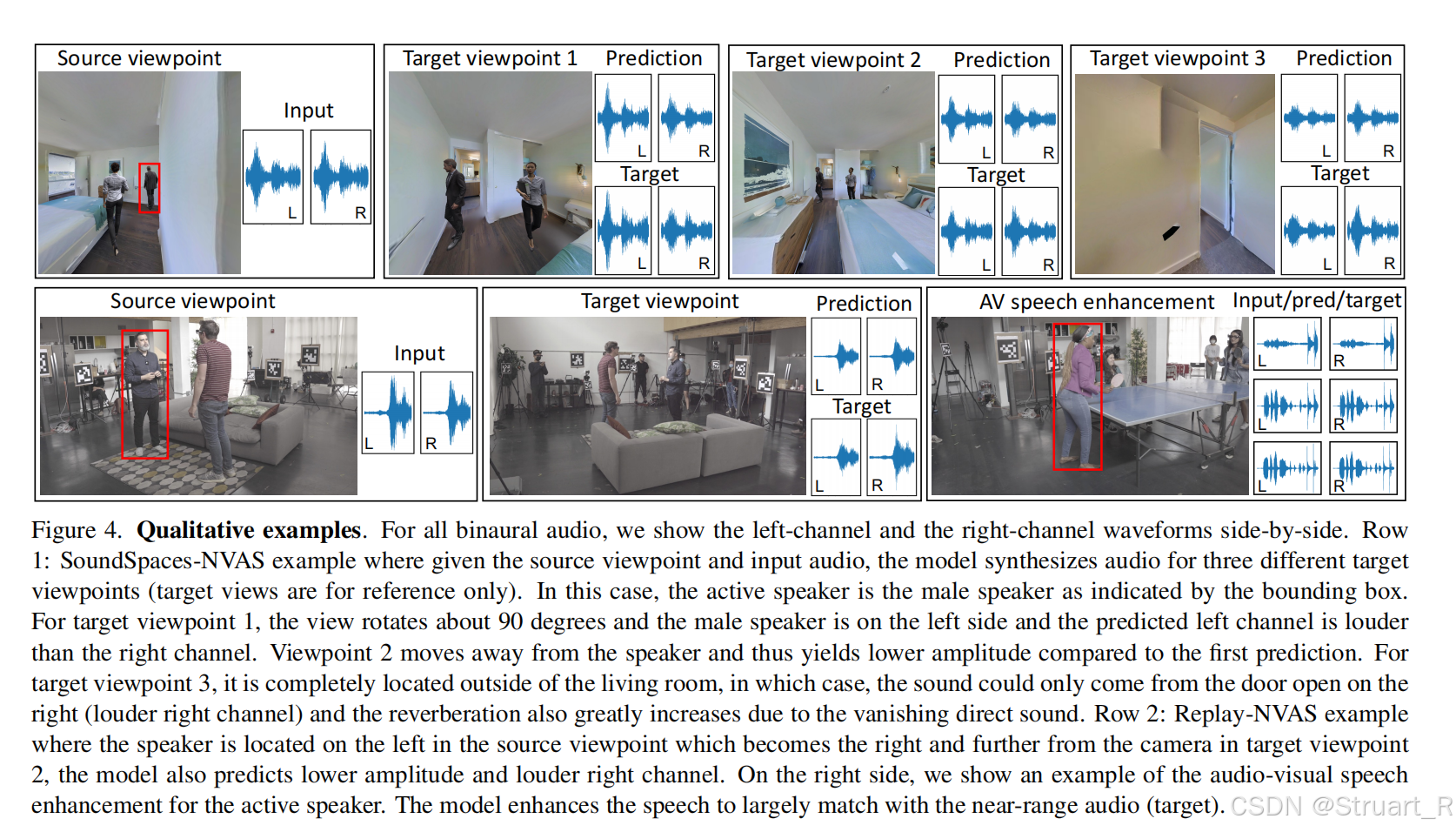
Replay-NVAS数据集:真实场景采集的多视角音视频数据集,包含 46 种社交情境(如对话、晚餐、瑜伽等),由 32 名参与者演绎。录制于公寓环境,模拟日常生活互动。设备为8台DSLR相机,双耳麦克风。数据总时长 37 小时,覆盖 8 个不同视角,每个片段1秒。训练时随机选取两个视角(源视角→目标视角),共 56 种视角组合。
SoundSpaces-NVAS数据集:合成生成的多视角音视频数据集。基于 SoundSpaces 2.0 平台,在 120 个真实扫描的 3D 环境(Gibson 数据集)中渲染。模拟物理级声学现象。录制说话人为1,000 名虚拟说话人(性别平衡),语音来自 LibriSpeech 语料库。场景布局随机放置 2 个虚拟人偶(1 男 1 女),间距 ≤3 米。每个场景随机生成 4 个视角(高度 1.5 米,朝向说话人中心)。数据集总时长 1,300 小时,包含 20 万个合成视角,通过 卷积双耳脉冲响应(HRTF) 生成目标音频。训练时随机选取两个视角(源→目标),且随机激活一名说话人。
NVAS任务
对于给定源视角S处录制的视频V_S和音频A_S,以及目标视角的麦克风位姿P_T,目标是合成目标位置T处的声音A_T。
其中目标视角的图像不参与输入与输出。
因为只有单一视角下的声音,所以无法三角定位到声源,所以需要依赖视觉补全空间信息。
后续的网络架构,就是为了实现这一任务。
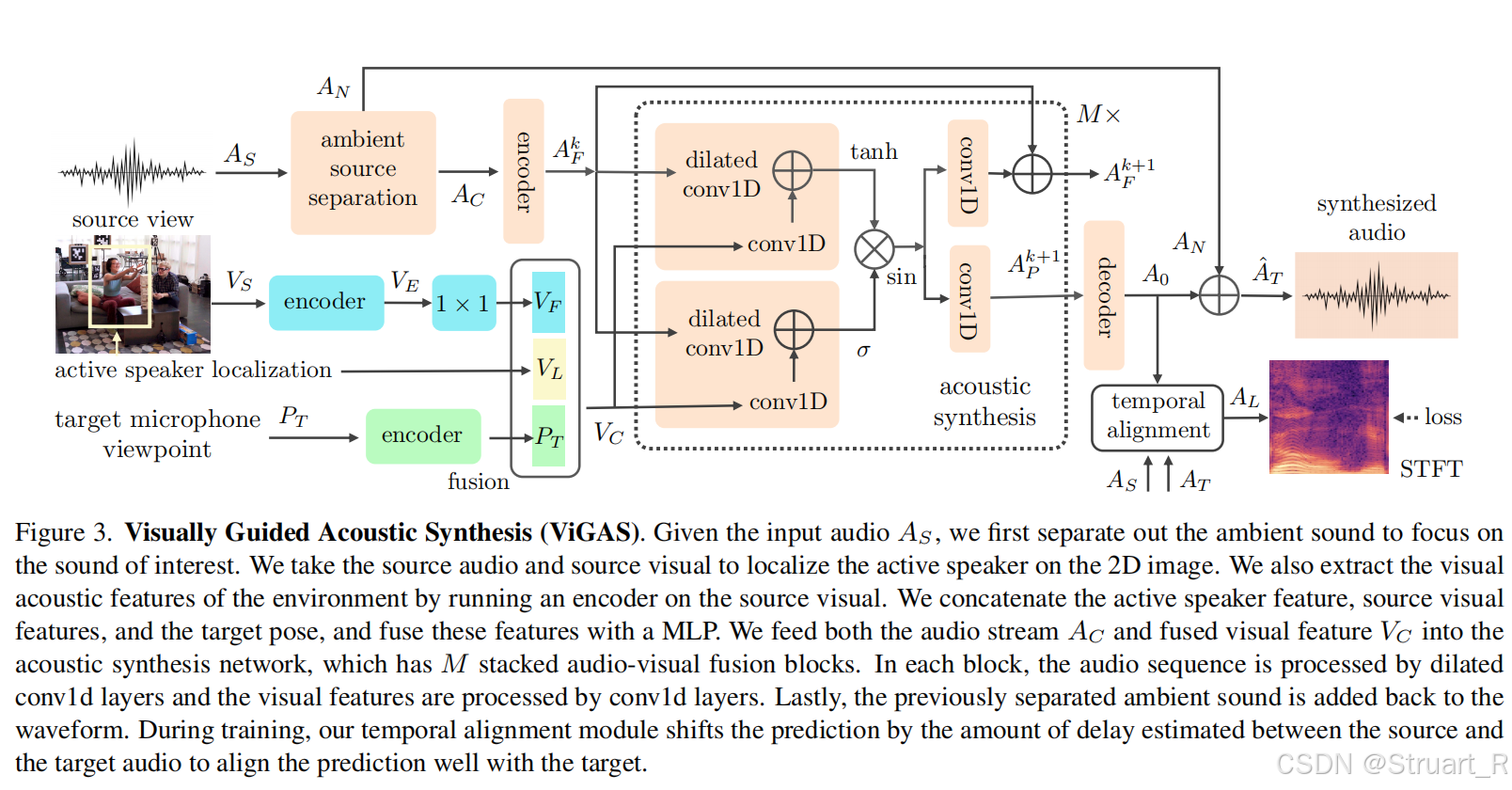
ViGAS方法
ViGAS方法包括五个部分,环境音分离,主动扬声器定位,视觉声学网络,声学合成,时间对齐。
环境音分离:避免环境噪声干扰主声音建模。利用一个带通滤波器(过滤掉SoundSpaces-NVAS: <80Hz;Replay-NVAS: <150Hz),处理后纯净声音为A_C,环境噪声为A_N。
主动说话者定位:识别出声源在给定图像中什么位置。对SoundSpaces-NVAS:采用基于语音性别与视觉外观训练分类器。对Replay-NVAS:使用近场麦克风能量最大值确定活跃说话者。最后在图像中均利用目标检测器,输出归一化边界框V_L。
视觉声学网络:利用预训练ResNet18,提取空间信息,然后用1D卷积压缩特征,得到特征V_F。对于目标听筒的位姿进行正弦编码得到P_T。拼接,经过多层感知机,生成融合特征
声学合成:利用一个门控多模态融合模块,将声音特征A_F^k,和空间特征V_C作为两个模态信息输入,最终解码得到受视觉特征影响的新目标位置的纯净声音信息A_O,并添加之前解耦出来的环境噪声A_N,得到合成声音输出\hat{A}_T。
时间对齐:由于声速会导致源音频与目标音频错位,所以利用广义互相关相位变换GCC-PHAT,来对齐目标音频。
监督:完全利用幅度谱的L1损失。
3、实验
二、RAF
1、概述
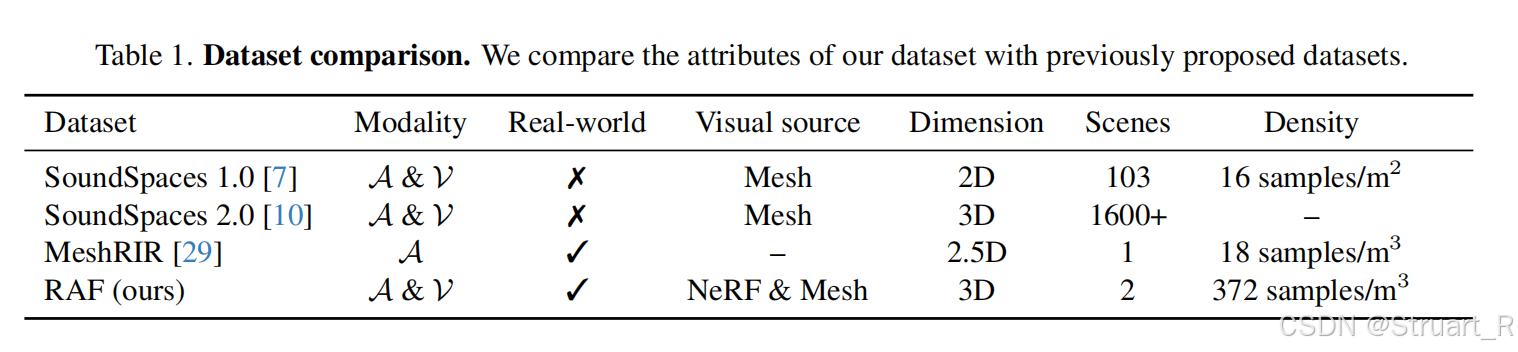
motivation:提到现有声场(SoundSpaces)依赖仿真数据,无法捕捉真实场景的复杂声学特性。
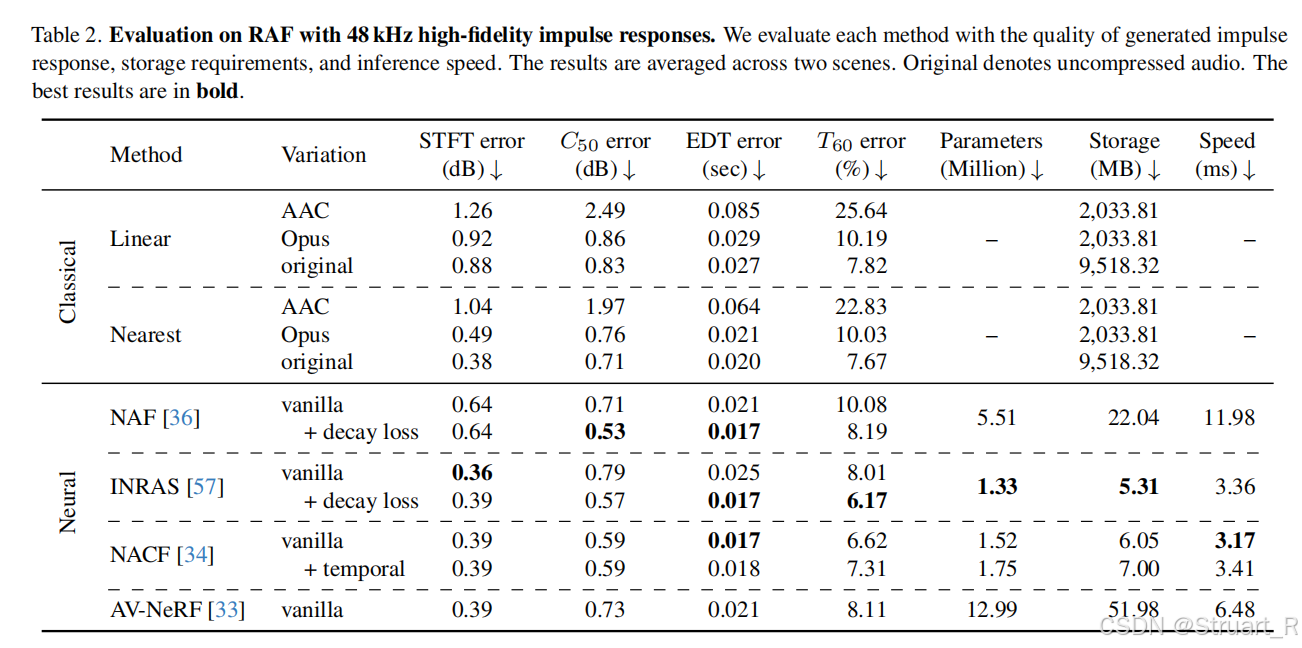
contribution:首先创建了一个高精度真实数据集,通过定制麦克风和运动捕捉系统,采集37.2万真实RIR数据。另外创建了一个Sim2Real优化范式,先用仿真数据预训练,用少量真实样本微调,提升稀疏数据的泛化性。最后对于NAF和INRAS模型引入了能量衰减损失,改进为NAF++和INRAS++,验证Sim2Real的优势。
2、方法
RAF dataset
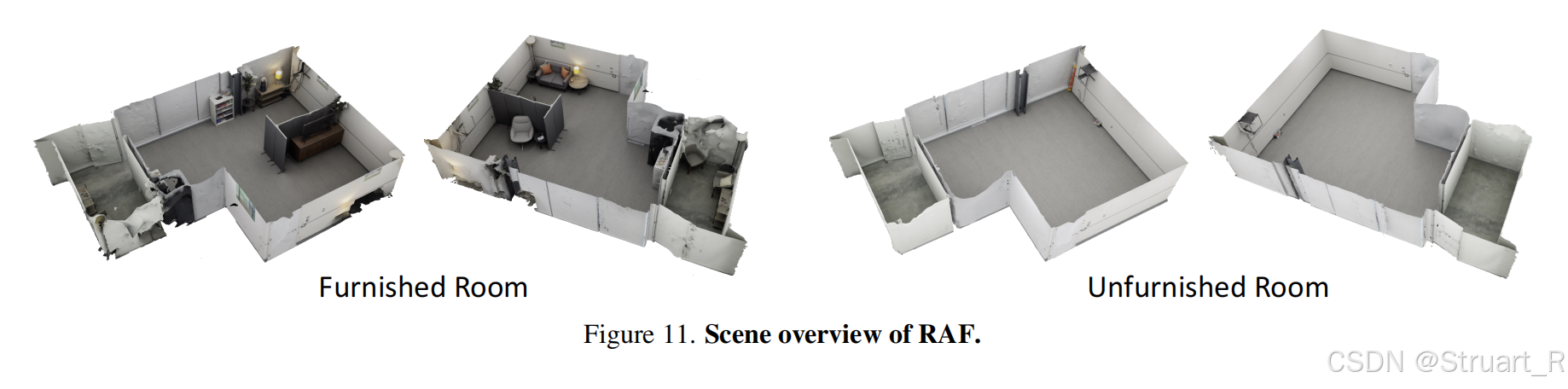
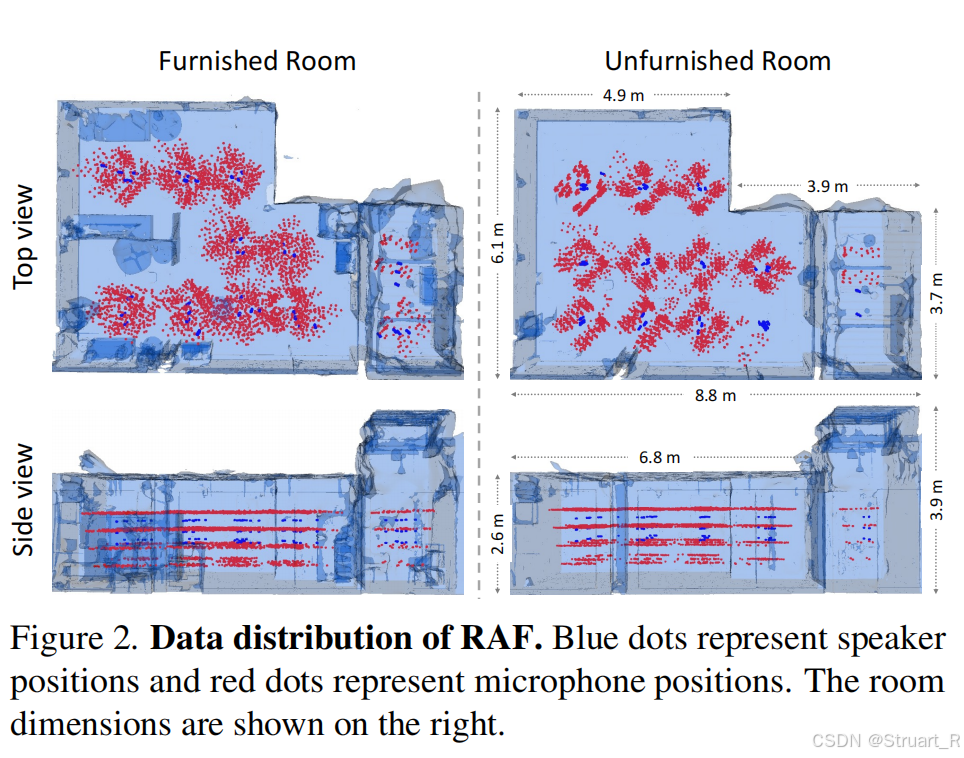
首个提供密集3D真实声场的多模态数据集,高密度采集,但是场景只有两个(空房间和家具房),图像信息采集11418张多视角图像,并用VR-NeRF进行重建,获得纹理网格和深度图。
声音采集,利用Earful Tower,36麦克风塔,效仿人耳高度密集采集。

场景overview如下:
OptiTrack是用来高精度运动捕捉的,保证图像都是统一坐标系下,这些不需要考虑,是光场数据采集系统的东西。
对比其他数据集来说,优势在于真实,密度高,音频+视觉。
NAF++&INRAS++
原来的NAF和INRAS虽然算法上是支持3D坐标的,但是训练的数据集SoundSpaces(完全2D),MeshRIR(2.5D,2.5D指的是声源虽然有上下之分,但是听者高度不变)所以他们学到的并非真实的3D,也无法学习到真实场景中的垂直方向声学变化,而且MeshRIR都是空房间,没有家具摆放,也就无法学习声波遮挡散射问题。
相比之下,RAF数据在采集的时候Z轴密集采集,覆盖人耳高度变化,并且包含家具房和空房间两个场景。(下图红色点为采集塔采集,蓝色点为说话人位置)
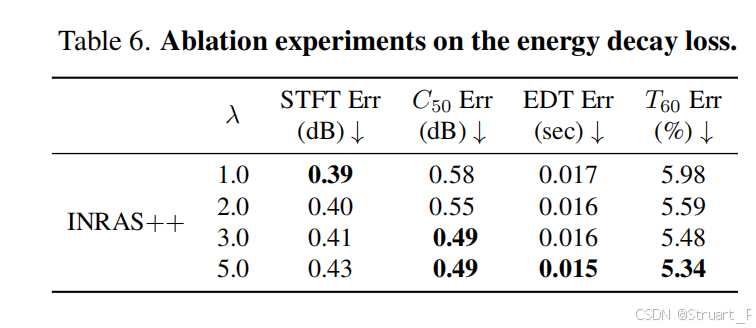
NAF++,一是引入了NACF中的decay衰减损失,NAF是mag幅度损失,NAF++是mag+decay损失。二是利用RAF+sim2Real的3D数据作为输入。
INRAS++一是同样引入了decay衰减损失,INRAS是mag幅度损失,sc全局能量损失,phase相位损失,mse均方差损失(这个应该INRAS++和对比INRAS论文的损失)。二是利用RAF+sim2Real的3D数据作为输入。三是对于INRAS中的2D bounce点上升到3D点。做法是先对真实数据集利用VR-NeRF生成场景mesh后,通过3D泊松采样,获得3D bounce点,这样更加贴近全空间的真实场景几何分布。
另外decay损失的权值增加时,从INRAS++中能看出来STFT error()误差上升,
误差下降,说明decay损失优化了物理特性,但代价是频谱结构受损。
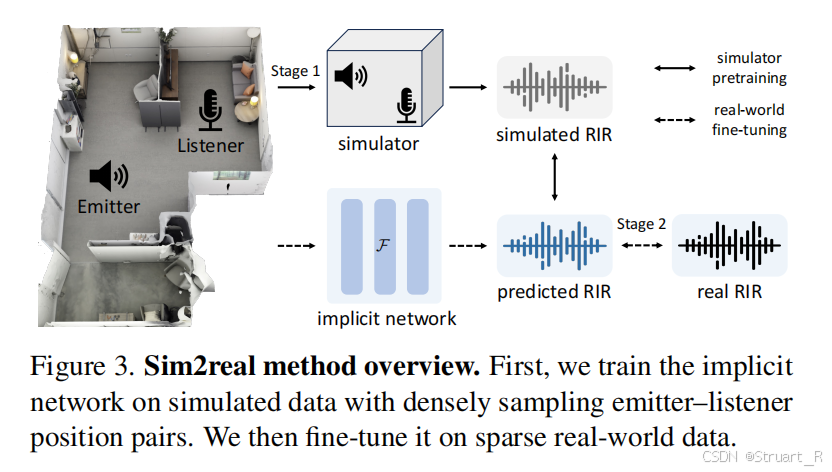
Sim2Real
motivation:降低声学建模成本,无需采集海量真实RIR和场景数据。
这里基于NAF++或INRAS++进行实验,首先利用RAF真实测量数据,来参数化一个模拟器参数,利用几何声学模拟器Pyroomacoustics,模拟一组合成数据集。
其中参数化过程包括:真实数据集利用VR-NeRF来生成3D场景网格,这就有了房间大小相关信息,同时对真实数据进行声学参数提取,获得混响时间T_{60},吸音系数等参数,利用这两者的信息,参数化一个声学模拟器。
从而由真实的RAF数据集获得了一组基于真实RAF数据集参数的同一场景的合成数据集(图像由NeRF渲染,声音由声学模拟器模拟)
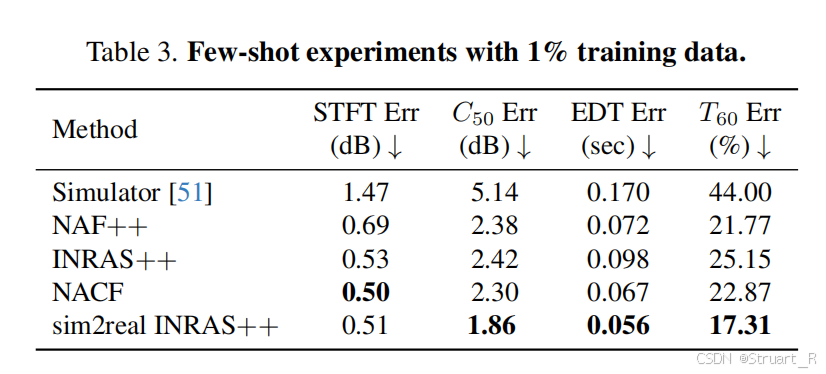
在训练过程中,用RAF的合成数据+总量1%的RAF真实数据。
通过这种方式,INRAS++,误差远小于真实数据训练的INRAS++。当然我觉得对于一些特定场景来说,效果不如真实数据,比如隧道、教堂这种不平常的场景。
3、实验
这个图没对比INRAS,NAF我多少有点没看懂这三个怎么对比的。
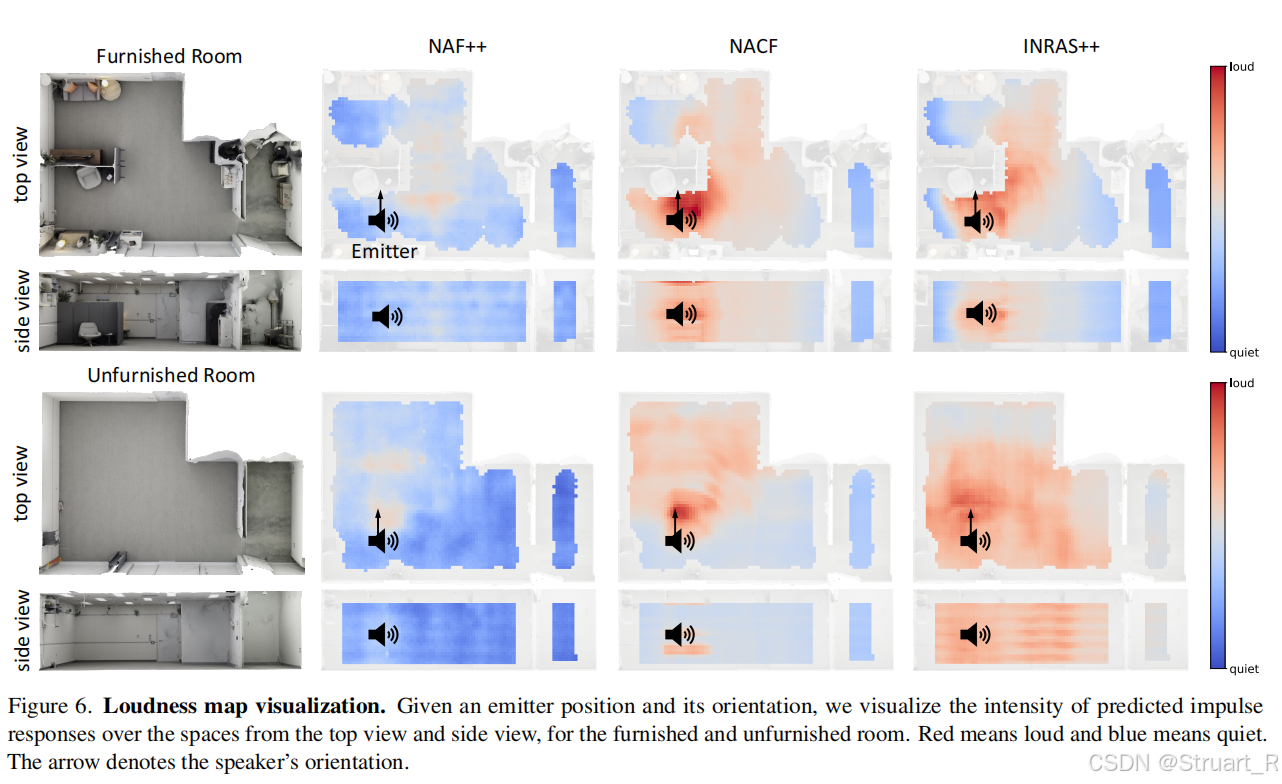
评测仍然基于RAF的验证集和测试集,并且去两个场景的平均值。
三、DiFFRIR
1、概述
这个模型完全是一个声场模型,简单介绍一下。
motivation:传统声场重建需数百麦克风,成本高昂。本文探索极稀疏测量(12个RIR) + 粗糙几何下的通用声场重建。
contribution:可微分声学渲染框架,DIFFRIR数据集。
2、方法
可微分声学渲染框架
这个框架就是利用极稀疏测量下的音频,和声源位姿,建立一个可微分的物理参数依赖的声学建模(有场景反射信息),是一个纯几何模型,白盒物理参数模型,可以动态编辑声场属性,具体原理涉及到声学设计,不太了解。
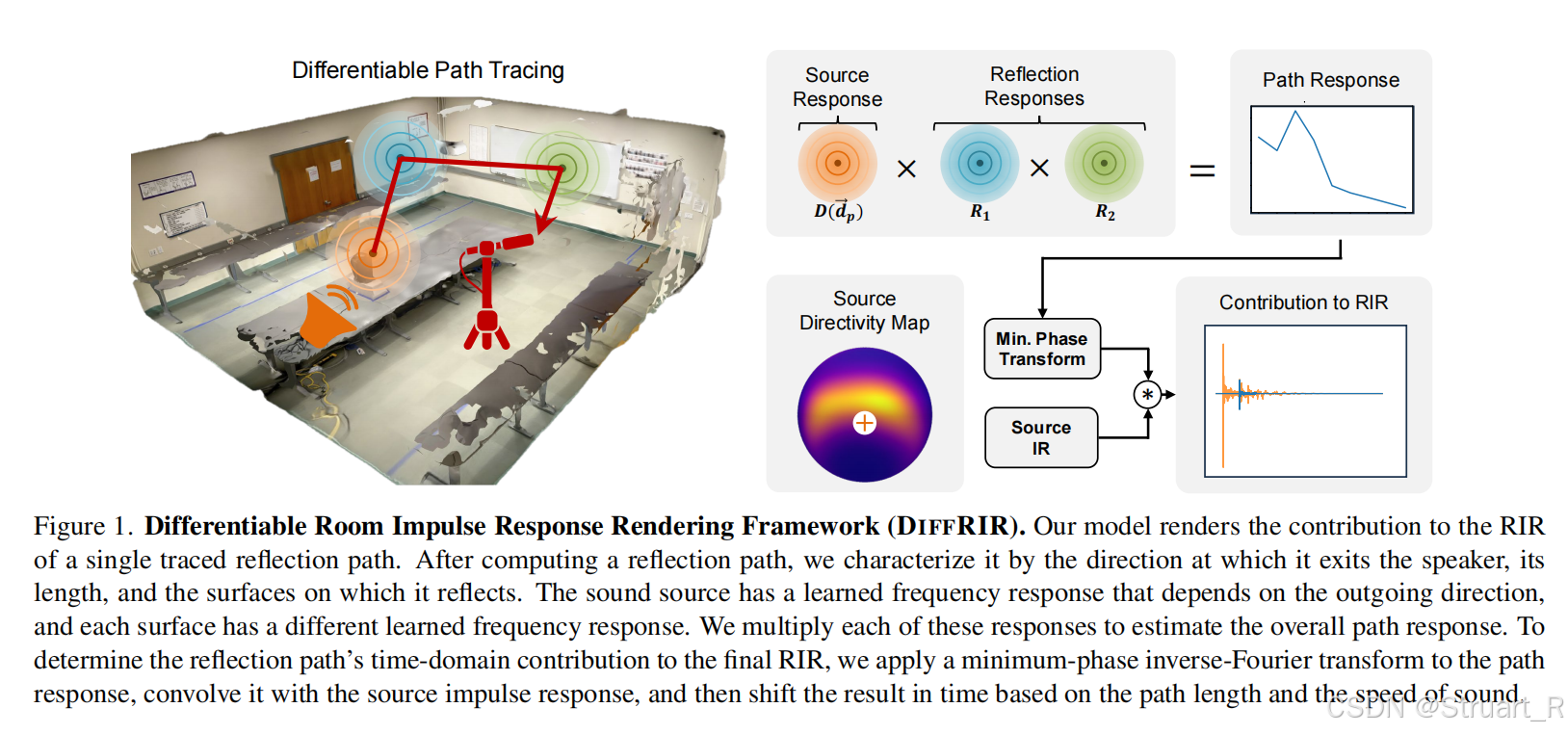
DIFFRIR Dataset
包含教室,消音室(接近无混响),走廊(高混响),不规则五棱柱复杂房间四个场景。
录音设备非常精密,全向麦,双耳麦,激光测距仪都拿上来了。空间采集高密度,但只选择12个点训练,其他点用来测试。
另外为了保证泛化能力,引入了声源旋转,声源平移,隔音板挡声源的三个动态场景。
参考论文:
[2301.08730] Novel-View Acoustic Synthesis
[2403.18821] Real Acoustic Fields: An Audio-Visual Room Acoustics Dataset and Benchmark
[2406.07532] Hearing Anything Anywhere