CVPR 2025|无类别词汇的视觉-语言模型少样本学习
论文信息
题目:Vocabulary-free few-shot learning for Vision-Language Models
无类别词汇的视觉-语言模型少样本学习
作者:Maxime Zanella、Clément Fuchs、Ismail Ben Ayed、Christophe De Vleeschouwer
源码:https://github.com/MaxZanella/vocabulary-free-FSL
论文创新点
提出全新范式:论文提出无类别词汇的少样本学习这一全新范式,打破了少样本视觉-语言模型适配中对预定义类别名称的传统依赖,在仅已知目标类别的视觉实例而不知其确切名称的情况下进行图像分类。
设计简单有效基线方法:针对上述问题,设计了名为相似性映射(SiM)的简单有效基线方法。该方法通过学习通用提示与目标类之间的线性映射,实现了无需明确文本目标标签的分类,仅基于少样本图像与一组通用提示(文本或视觉)之间的相似性分数进行分类。
提供模型可解释性:该方法具备理想的可解释性。通过分析学习到的线性映射中权重的相对重要性,能够将目标类与通用提示所代表的有意义概念联系起来,从而对目标类提供语义层面的理解。
探索多样实验设置与方向:在多种数据集上,使用不同来源(如ImageNet类名、ImageNet图像、Wordnet词汇)的通用提示对方法进行实验验证。
摘要
近期,视觉语言模型(VLM)在少样本适配方面取得了显著进展,大幅提升了其仅使用少量标记示例即可跨任务泛化的能力。然而,现有方法主要借助精心设计的特定任务提示,依赖这些模型强大的零样本先验知识。这种对预定义类别名称的依赖,可能会限制其适用性,尤其是在确切类别名称不可用或难以指定的情况下。为解决这一限制,作者引入了适用于VLM的无词汇表少样本学习方法,该方法中目标类别实例(即图像)是可用的,但其相应名称不可用。作者提出了相似度映射(SiM),这是一种简单而有效的基线方法,仅基于与一组通用提示(文本或视觉)的相似度得分对目标实例进行分类,无需精心手工制作提示。尽管从概念上讲很直接,但SiM表现出强大的性能,计算效率高(学习映射通常不到一秒),并且通过将目标类别与通用提示联系起来,具有可解释性。作者认为,该方法可以作为未来无词汇表少样本学习研究的重要基线。
关键词
视觉语言模型;少样本学习;无词汇表分类;相似度映射
引言
视觉语言模型(如CLIP [26])已成为跨模态学习的重要工具。这类模型通过大规模对比训练,实现图像与文本的对齐。其关键优势之一是零样本分类,能仅依据描述目标类别的文本提示对图像进行分类。这一能力带来了出色的成果,并推动了少样本学习技术的发展,这些技术进一步利用少量标记示例,使VLM适应新任务。为实现这一点,当前的少样本方法基于强大的零样本分类能力,比如将类别名称标记纳入可学习提示[17, 40, 41],将手工制作的提示与适配器结合使用[36, 38],或采用低秩微调[37]等。
然而,在许多情况下,类别定义可能模糊不清,难以设计有意义的提示。其次,有些类别可能需要冗长复杂的描述,单个提示难以完整涵盖,因此将其分解为更小、更易解释的组件更为合适。再者,可能会出现VLM预训练时未知的新概念。这些实际挑战会阻碍直接的零样本分类,进而限制了依赖预定义类别名称的现有少样本学习方法。
为克服这些限制,作者引入了无词汇表少样本学习框架,在该框架中,目标类别的视觉实例可用,但其相应名称不可用。图1展示了与标准VLM少样本学习的对比。
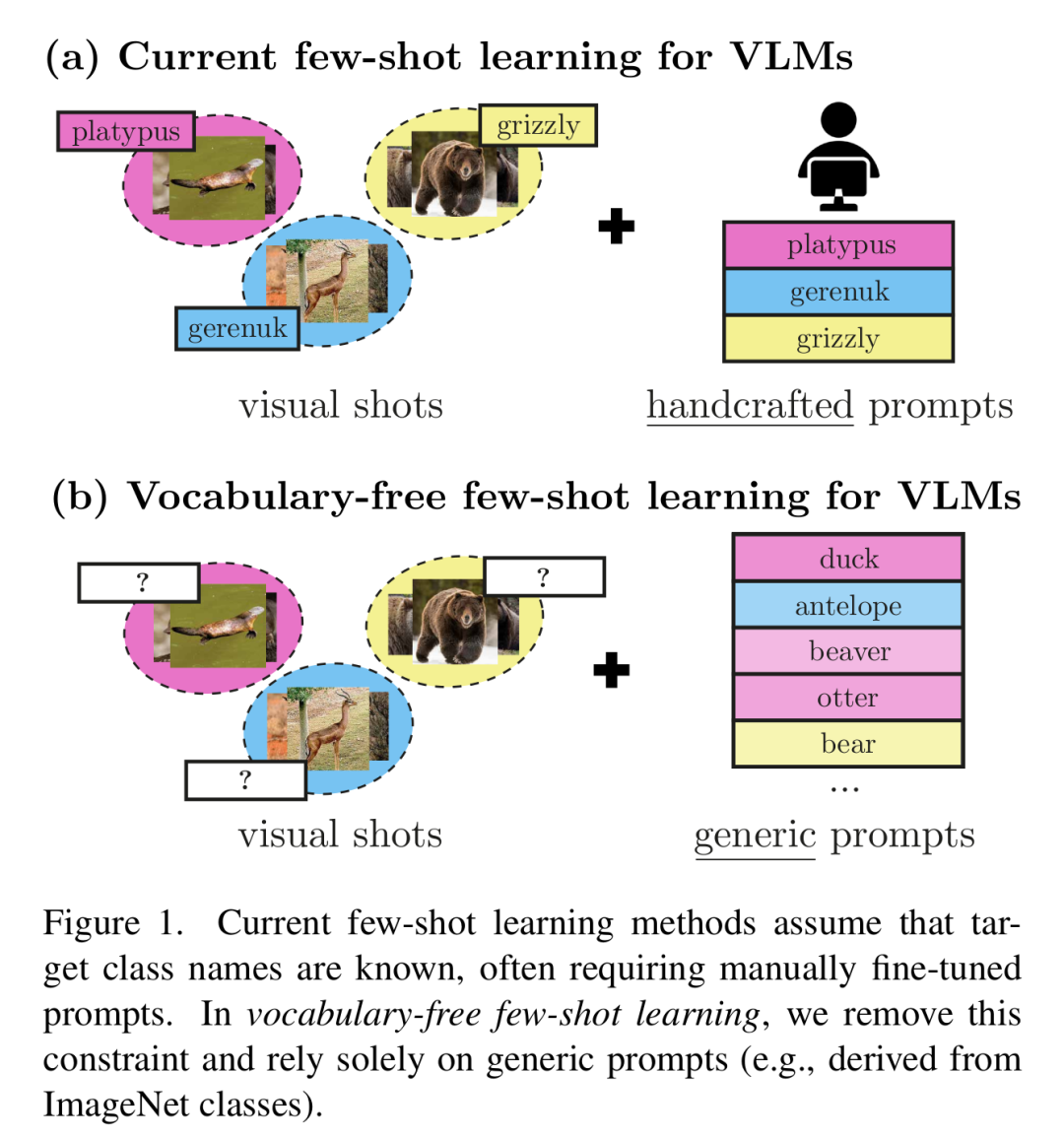
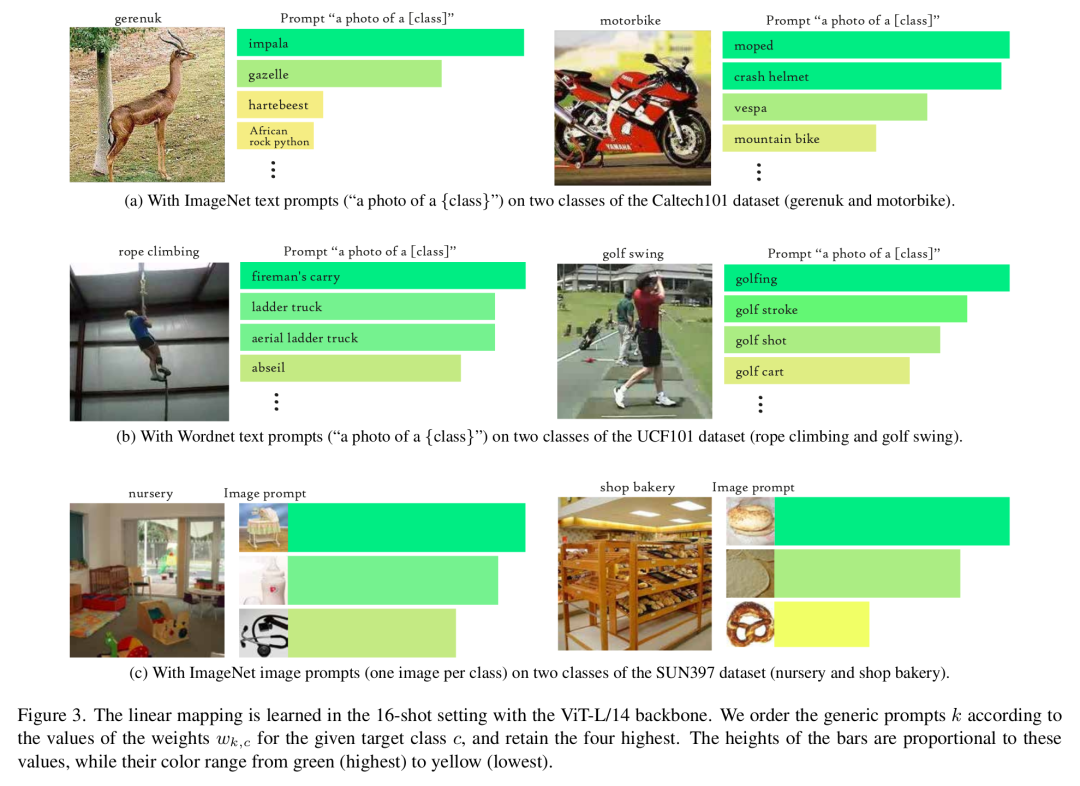
由于没有预定义的类别名称,当前VLM的少样本方法不再适用,需要其他方法来区分类别。在本研究中,作者提议使用源自ImageNet类别名称的通用文本提示(表1),同时说明如何探索更广泛的概念,如来自Wordnet词汇数据库[23]的概念。除了分类,作者的方法通过将目标类别与这些代表有意义概念的通用提示联系起来,增强了可解释性(见图3)。这反过来可能提供对目标类别的语义理解。例如,在实验中,目标类别“长颈羚”与其他羚羊物种“黑斑羚”和“瞪羚”相关联(图3a)。
为利用通用文本提示,作者提议学习这些提示与目标类别之间的线性映射。给定每个目标类别的少量标记示例(样本),作者估计一个映射,将图像与通用文本提示之间的相似度得分投影到类别分配上。该方法与视觉重编程中使用的标签映射技术[5, 12, 33]有相似之处,在视觉重编程中,映射函数将预训练模型的输出与新任务标签对齐。作者的方法效率极高,作为黑箱模型运行(仅依赖相似度得分,而非直接访问文本或视觉嵌入),且计算开销极小。
除了当前的表述,作者认为无词汇表少样本学习和提议的基线开启了几个有前景的研究方向。其中包括将少样本学习的最新进展应用于无词汇表问题,扩展通用提示集,整合更丰富的文本和图像数据库,或考虑类别关系的先验知识。最后,为目标类别分配有意义的名称仍然是一个开放问题。
贡献:在这项工作中,作者引入了无词汇表少样本学习这一新范式,其中目标类别的视觉实例可用,但其确切名称不可用,这对少样本视觉语言模型适配中传统上对预定义类别名称的依赖提出了挑战。为解决此问题,作者提出了一种简单而有效的基线方法,该方法学习通用提示与目标类别之间的线性映射,从而在无需明确文本目标标签的情况下进行分类。此外,作者的方法具有理想的可解释性,因为学习到的映射提供了关于目标类别与已知概念如何关联的见解。最后,作者概述了几个未来改进的研究方向,包括改进少样本学习算法、扩展通用提示(文本和/或图像)的多样性,以及实现目标类别的细粒度命名。
方法
预备知识
为全面理解作者针对视觉语言模型(VLM)的无词汇表少样本学习方法,首先定义常规视觉语言分类框架的关键要素。其核心是,CLIP将图像和文本描述嵌入到一个共同的潜在空间中,实现对齐并衡量它们的相似度。给定一组具有已知名称的预定义个类别,该框架依赖于生成所谓的文本提示,如“一张classc}的照片”。这些文本描述首先被标记化,然后由文本编码器处理为单位超球面$S^{d - 1} = {u \in R^d;|u||_2 = 1}上的归一化嵌入t_c。类似地,图像x_i由视觉编码器转换,生成表示f_i \in S^{d - 1$。这使得能够计算相似度得分:
最后,通过选择最高相似度得分来获得图像的预测类别,即。请注意,在无词汇表设置中,此方法不可行,因为类别名称{classc}不可用,无法计算嵌入。
作者的方法
作者的方法称为相似度映射(SiM),它学习一个矩阵,将使用预定义的一组通用提示计算出的相似度得分线性映射到由少样本图像集定义的类别的独热表示。整个流程总结在图2中。
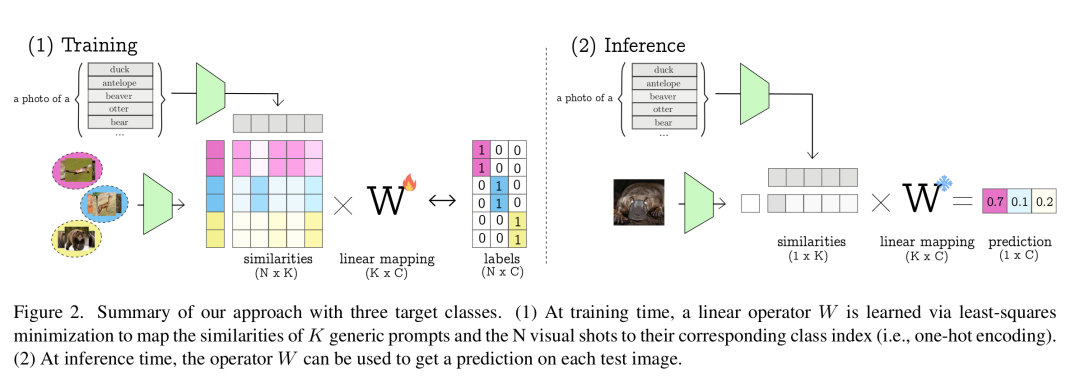
通用提示:给定图像,由于无法获得嵌入,所以无法计算相似度得分(公式(1))。相反,相似度得分是相对于一组个预定义嵌入()计算的。可以从一组任意的通用文本提示或其他图像中获得。任务是在已知少样本图像集的相似度得分的情况下,从得分中获得类别预测。形式上,这些相似度得分可以组合成一个矩阵:
从少样本集学习:然后作者可以估计,使得,其中是矩阵,其行对应于少样本图像的独热编码标签。这是通过使用Tikhonov正则化最小化最小二乘目标来实现的,即:
其中是一个超参数。将公式(3)中的目标函数的梯度设为0,得到:
测试图像分类:对于测试图像,作者得到相对于预定义的任意通用提示集的相似度。然后使用将这些相似度映射到目标类别得分:
预测类别为。通过研究给定目标类别的权重的相对重要性,作者可以找到在个任意通用提示集中最对齐的嵌入,这可能为目标类别提供高层次的语义理解(见图3)。 4. 将公式(3)解释为无监督聚类目标:公式(3)中的问题可以看作是类似于K - means [1]的无监督聚类目标,但它作用于视觉样本的特征向量,并使用固定的点到簇分配变量。[1]中K - means的矩阵分解公式使我们能够从这个角度理解。实际上,矩阵的列向量(即优化变量)可以看作是簇原型。因此,本质上,作者的方法可以看作是基于与通用提示集的相似度所驱动的特征,对视觉样本进行无监督聚类。
实验验证
对比方法
一对一映射:此方法尝试使用相似度矩阵(公式(2))将单个通用提示与每个目标类别相关联。具体来说,为学习映射,作者采用[33]中提出的频率标签映射(FLM)算法。
贝叶斯标签映射:贝叶斯标签映射(BLM)在[4]中被引入,它利用标签的联合分布来学习更灵活的多对多映射。
质心:为进一步验证作者的方法,将其与受[30]启发的仅视觉少样本学习基线进行比较。该方法遵循VLM的常规分类框架(见公式(1)),但用属于类别的图像的视觉特征的样本均值替换文本提示。请注意,此方法不使用通用提示,也无法为目标类别提供语义洞察。
标准VLM少样本学习:此外,作者提供了需要类别名称的少样本方法的结果。由于这些领域非常受欢迎,作者报告了一些最流行的方法,即文本提示调整方法CoOp [40]、视觉和文本提示调整方法MaPLe [17]、基于缓存的方法Tip - Adapter [38]、基于适配器的方法TaskRes [36]以及低秩适应方法CLIP - LoRA [37]。这些方法在作者的实验中作为上限参考,因为它们可以访问预定义的类别名称,因此可以利用零样本预测,这与无词汇表方法不同。
实验设置
数据集:作者采用先前工作[40]的设置,并使用11个数据集进行图像分类任务,即ImageNet [10](一个大规模的对象识别基准数据集)、SUN397 [34](用于场景的细粒度分类)、Aircraft [22](用于飞机类型分类)、EuroSAT [16](用于卫星图像分类)、StanfordCars [19](用于汽车模型分类)、Food101 [2](用于食品项目分类)、Pets [25](用于宠物类型分类)、Flower102 [24](用于花卉物种分类)、Caltech101 [13](用于各种一般对象分类)、DTD [7](用于纹理类型分类)和UCF101 [31](用于动作识别)。
用于提示的ImageNet类别名称:对于主要结果,作者使用ImageNet [10]的类别生成个形式为“一张{classk}的照片”的提示,并随后获得相关的嵌入。
用于提示的ImageNet图像:为证明可以使用多种提示计算相似度,作者研究了一种替代设置,其中基于图像的表示取代文本提示。如后文所讨论的,这突出了改进提示选择可能是未来研究的一个有趣方向。在这种设置下,对于每个随机种子,作者为个类别中的每个类别随机抽取一张图像,然后由视觉编码器处理这些图像,生成归一化嵌入。因此,矩阵中的相似度是图像与图像之间的,而不是图像与文本之间的。
用于提示的Wordnet词汇:在这种设置下,作者选择Wordnet [23]中与[“建筑物”、“车辆”、“食物”、“花卉”、“动物”、“纹理”、“动作”、“家具”]中至少一个词相关的所有单词,得到一个个单词的词汇表。然后作者生成形式为“一张{wordk}的照片”的提示,这些提示由文本编码器处理并归一化,以生成嵌入。
结果
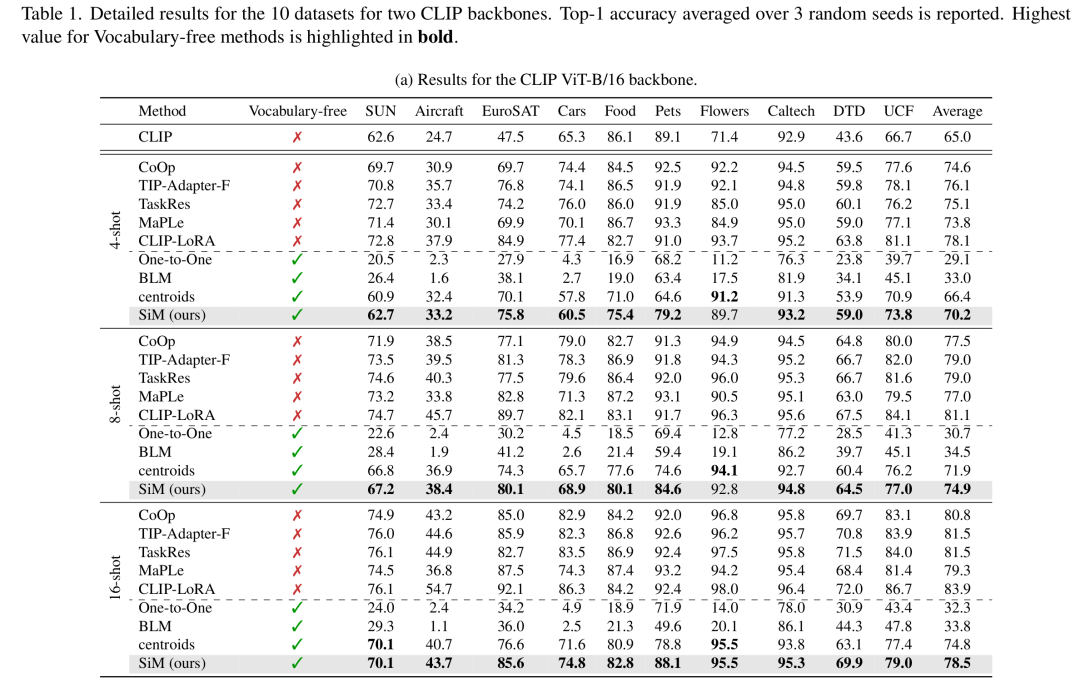
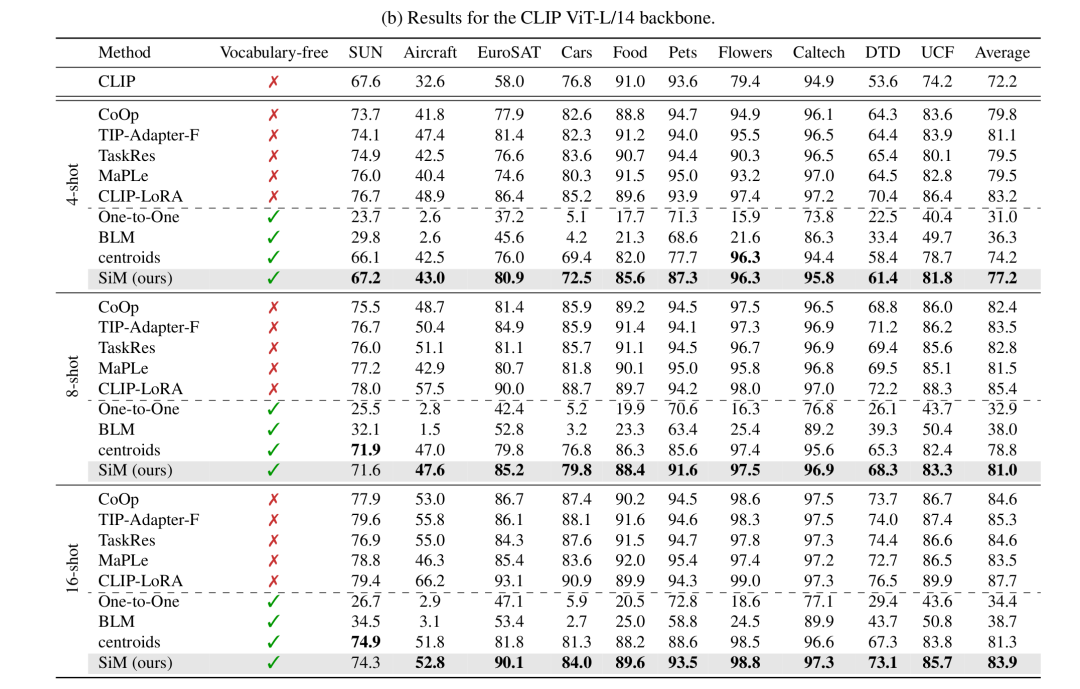
现有标签映射技术不足:表1显示,在所有10个数据集上,与SiM相比,最先进的标签映射策略始终表现不佳。一对一映射平均比BLM表现更差,这突出了将多个通用类别映射到每个目标类别,而不是依赖严格的一对一对应关系的好处。令人惊讶的是,质心基线(尽管是一种简单的仅视觉方法)在很大程度上优于BLM,这引发了关于BLM在VLM少样本学习设置中的可行性问题。当将BLM与SiM进行比较时,作者观察到Pets和Caltech101的性能差距最小,这可能是因为它们的概念与ImageNet中的概念紧密对齐。相反,Aircraft、Cars和Flowers的性能下降最大,这可能是由于它们的细粒度性质,这些性质在ImageNet中要么不存在,要么仅在超类级别表示,使得区分更具挑战性。
SiM与零样本分类具有竞争力:表1展示了零样本结果,这些结果仅在类别名称可用时才能实现。作者的方法在每个类别有4个样本的情况下,在10个数据集中的6个数据集上优于零样本CLIP,在每个类别有16个样本的情况下,在10个数据集中的8个数据集上优于零样本CLIP。然而,不同数据集的性能差异很大。在Flowers、DTD和EuroSAT等数据集上,SiM仅在每个类别有4个样本时就超过了零样本CLIP,而对于Food101和Pets,即使在16样本设置下,SiM的性能仍低于零样本性能。这些结果表明,纳入哪怕是部分或有噪声的先验知识(例如来自字幕模型的初始零样本预测[9]),都可能进一步提高SiM的性能,特别是在无词汇表方法难以达到零样本准确率的情况下。
词汇缺乏会降低性能:尽管结果很有前景,但表1显示,SiM与受益于明确类别名称的传统少样本学习方法之间仍存在性能差距。然而,当使用更强大的骨干网络(如ViT - L/14)时,特别是对于Flowers、Caltech101和EuroSAT等数据集,这种差距会显著减小。作者还可以假设,将当前关于VLM少样本学习的最新观察与作者的方法相结合(例如与提示调整、适配器或低秩适应方法相结合),可能有助于弥合剩余差距。
图像可用作提示,但落后于文本提示:表2展示了使用不同提示获得的结果。当嵌入从ImageNet类别的单个图像中获得时,性能往往略低于使用ImageNet类别名称时的性能。当样本数量增加或使用更强大的骨干网络时,这种差距会缩小。在使用ViT - L/14的16样本设置中,基于图像和基于文本的提示在大多数数据集上产生可比的性能。
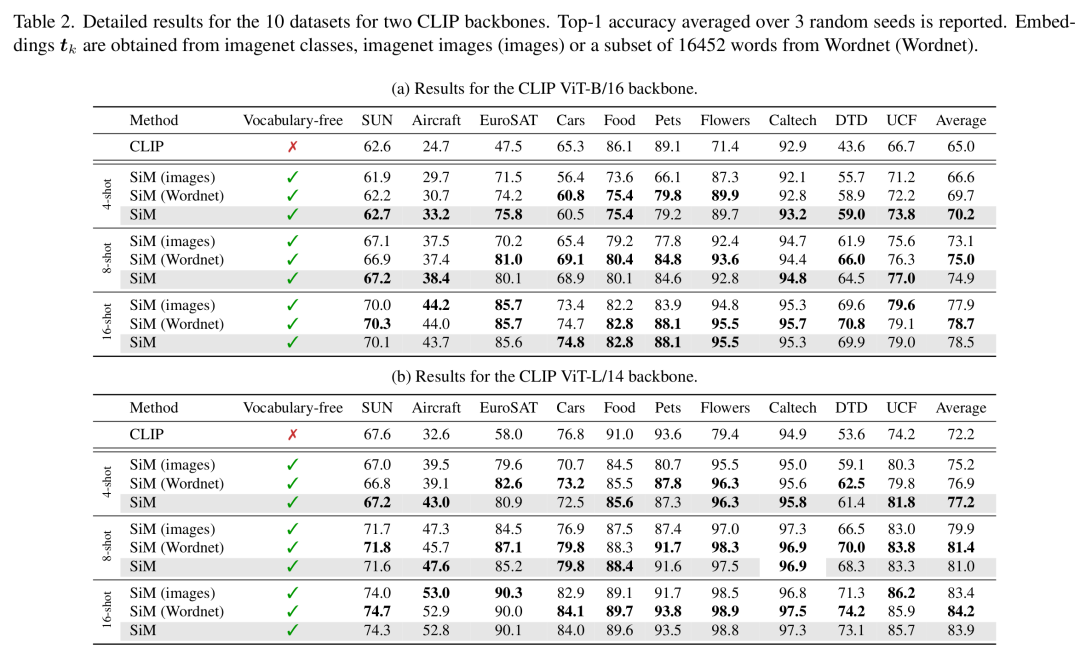
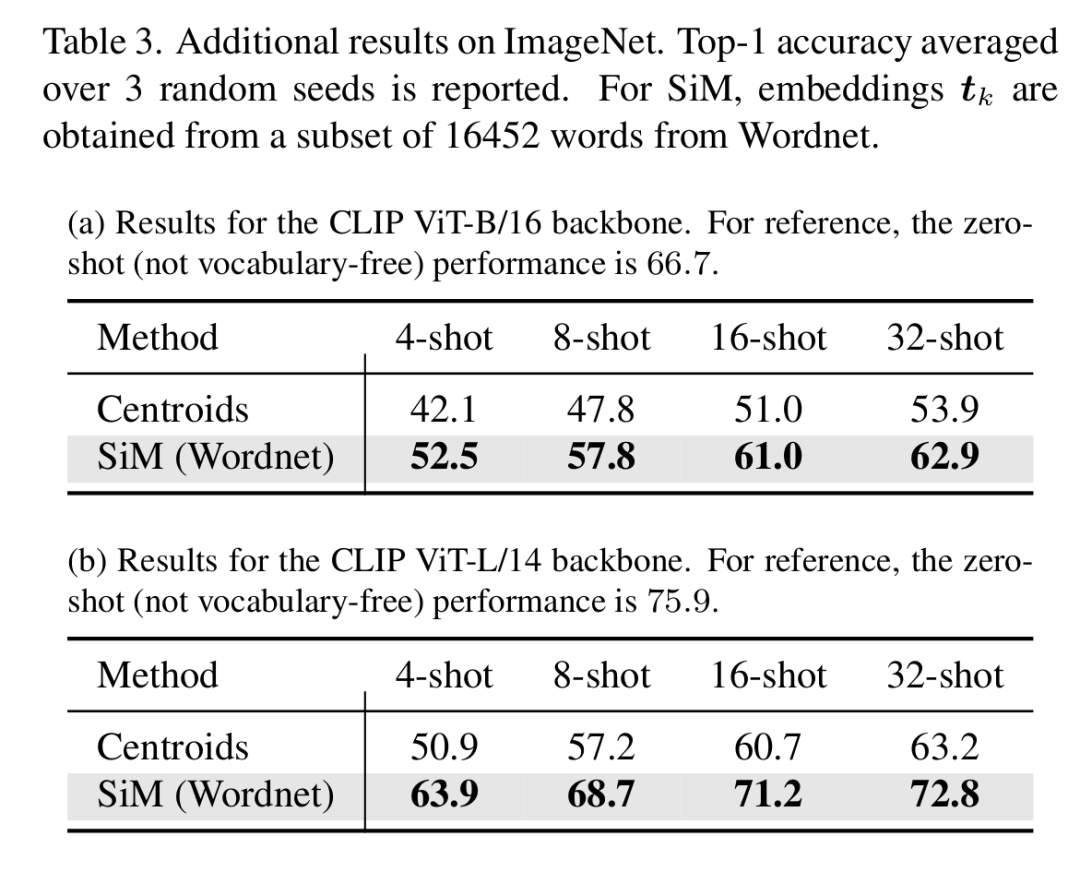
文本提示不限于ImageNet类别:表2展示了使用不同提示获得的结果,即使用来自Wordnet的个单词的子集生成嵌入。作者的方法可很好地扩展,因为在Tesla A100上使用16样本ImageNet()学习映射需要0.8秒。与两个骨干网络在4样本设置下的ImageNet类别相比,性能略有下降。这可能是由于大得多导致对噪声更敏感,在测试时学习到的映射泛化效果不佳。在8样本和16样本设置下,平均性能相当。在这种设置下,作者还可以提供ImageNet的结果,如表3所示。与其他一些数据集(如Food)类似,即使有16个和32个样本,SiM的性能仍低于零样本性能。使用更强大的ViT - L/14骨干网络时,差距会缩小。
学习到的权重可提供语义理解:除了分类性能,作者可以研究给定目标类别的权重的相对重要性(见公式(5)),这可能提供高层次的语义理解。图3展示了在这项工作中研究的三种提示类型上的这种可解释性。图3a展示了在Caltech101(动物和物体)上使用ImageNet类别名称提示的结果,作者的方法将长颈羚与其他羚羊物种黑斑羚和瞪羚有意义地关联起来。图3b展示了在UCF101数据集(动作识别)上使用基于Wordnet的提示的结果,与攀岩语义相关的单词(如“绕绳下降”)作为相关匹配出现。图3c展示了在SUN397数据集(场景识别)上使用基于图像的提示的结果,表明商店面包店与百吉饼、面团和椒盐卷饼等烘焙食品相关联。
线性映射并非总是可解释:学习到的映射中包含的信息并非对每个目标类别都能直接解释。例如,图4a展示了一个示例,其中最重要的权重与与目标类别语义相关的通用提示相关联,但这些提示并未出现在定义该类别的图像中。另一个可解释性失败的情况似乎与细粒度数据集有关,如图4b所示,目标类别与完全不相关的概念相匹配。有趣的是,这种缺乏可解释性似乎对准确性并无损害,因为与使用类别名称的零样本分类相比,在使用ViT - L/14骨干网络的16样本设置下(即图4b获得的设置),SiM实现了31%的错误率降低。因此,通用提示的选择可能会在目标类别的可解释性和可分离性之间引发权衡。

讨论与未来工作
由于到目前为止,只有少数研究针对无词汇表图像分类问题,因此对于VLM的无词汇表少样本学习,未来的研究方向似乎很多。表1中的结果表明,可能有机会将VLM少样本适配的最新进展(如提示调整)应用于这个新设置。此外,作者的基线可以通过提出不同的正则化方法进行调整,以提高分类准确率或增强可解释性。
除了改进学习算法,优化通用提示的选择也可能在提高性能方面发挥关键作用。如表2所示,通用提示集可能来自非常多样化的来源,这表明有可能优化用于计算相似度的嵌入的选择。这反过来可能有助于缓解图4b中所示的问题。
最后,为样本组关联有意义的名称仍然是一个开放挑战。例如,通过研究自动标记发现类别的技术,同时使用语义指标(如语义交并比(IoU))评估性能,如[9]中所建议的。
结论
在这项工作中,作者引入了无词汇表少样本学习,这是一种使用VLM进行图像分类的新框架,其中类别名称不可用。作者强调了当前少样本适配方法在处理这种实际场景时的不足。为解决这一限制,作者提出了一种简单而有效的基线方法,该方法利用少样本图像与一组通用、任意提示之间的相似度得分,这些提示可以来自文本或图像,且在预定义时无需任何目标类别的知识。有趣的是,作者的最小二乘基线SiM,实现了与依赖明确类别名称的更复杂少样本适配技术相近的性能。此外,SiM不需要直接访问通用提示或图像的嵌入,仅需相似度得分。最后,作者证明了分析学习到的线性映射的相对权重,可能为目标类别提供高层次的语义洞察。总体而言,作者希望这项工作能成为无词汇表少样本学习的基石,这是VLM适配中一个重要但被忽视的问题。
声明
本文内容为论文学习收获分享,受限于知识能力,本文对原文的理解可能存在偏差,最终内容以原论文为准。本文信息旨在传播和学术交流,其内容由作者负责,不代表本号观点。文中作品文字、图片等如涉及内容、版权和其他问题,请及时与我们联系,我们将在第一时间回复并处理。