【数学建模】数据预处理入门:从理论到动手操作
前言:欢迎各位光临本博客,这里小编带你直接手撕Make/Makefile (自动化构建),文章并不复杂,愿诸君耐其心性,忘却杂尘,道有所长!!!!

**🔥个人主页:IF’Maxue-CSDN博客
🎬作者简介:C++研发方向学习者
📖**个人专栏:
《C语言》
《C++深度学习》
《Linux》
《数据结构》
《数学建模》**⭐️人生格言:生活是默默的坚持,毅力是永久的享受。不破不立,远方请直行!
文章目录
- 一、先搞懂理论:数据预处理要做啥?
- 1. 为啥要做数据预处理?先看概念图
- 2. 第一步:标准化(让数据“站在同一水平线上”)
- 先记一个关键原则:同一特征才能标准化
- 最常用的:最小值-最大值归一化(缩到0-1之间)
- 3. 第二步:数据离散化(把“连续数”切成“区间块”)
- 常用的“离散分箱”方法
- 4. 第三步:特征编码(把“文字”转“数字”,模型才懂)
- 先看编码的核心逻辑:从离散到回归
- 三种常用编码,别搞混!
- 5. 第四步:特征衍生(“造新数据”,让模型更准)
- 三种常见衍生方式
- 二、动手上机:用代码实现这些操作
- 1. 先准备数据:输出同一特征看原始样
- 2. 实现标准化(用DataFrame操作)
- (1)Z-score标准化(常用,让数据均值为0、标准差为1)
- (2)最小值-最大值归一化(缩到0-1)
- 3. 实现数据离散化(分箱)
- (1)等宽分箱(每个区间宽度一样)
- (2)等频分箱(每个区间数据量差不多)
- 4. 实现特征编码
- (1)独热编码
- (2)序列编码(Label Encoding)
- 5. 实现特征衍生
- (1)多项式扩增
- (2)对数变换
- 总结
做数据分析或机器学习时, raw数据(原始数据)往往“不好用”——比如有的数据单位大(像收入几万),有的单位小(像年龄几十),模型会“偏心”大单位数据;还有的是文字数据(像性别“男/女”),模型根本读不懂。这篇就从理论到代码,带你搞定数据预处理的核心步骤,每个点都结合图来理解,新手也能看懂~
一、先搞懂理论:数据预处理要做啥?
1. 为啥要做数据预处理?先看概念图
首先得明白“为啥要折腾数据”,看这两张概念引入图就懂了:
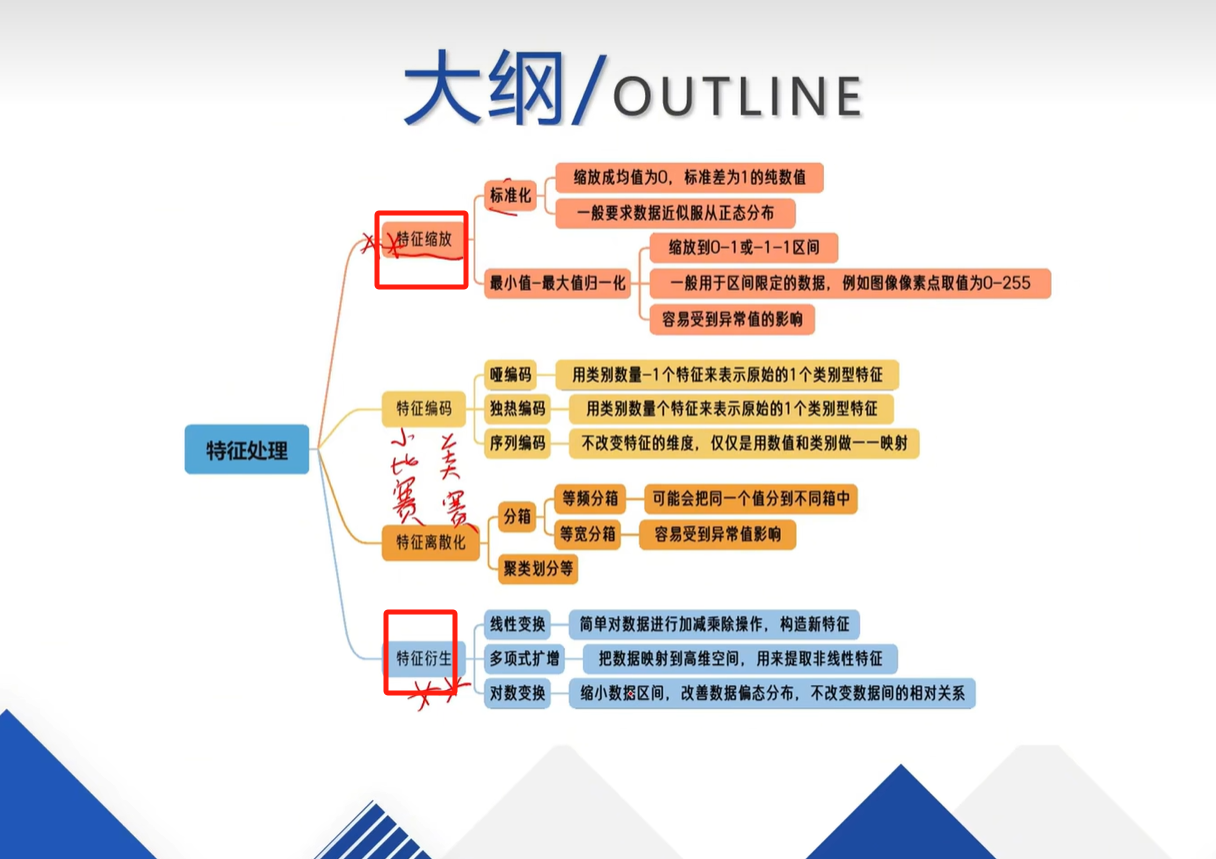

简单说:数据格式乱、范围不统一、类型不对,会让模型算错或算得慢。预处理就是把数据“整理规整”,让模型能高效学习。
2. 第一步:标准化(让数据“站在同一水平线上”)
先记一个关键原则:同一特征才能标准化
比如“身高”和“体重”不能放一起标准化——身高是厘米(几十到两百),体重是公斤(几十到一百多),两者含义不同,强行一起处理会搞混数据逻辑。
最常用的:最小值-最大值归一化(缩到0-1之间)
这种方法是把数据压缩到「0到1」的范围,方便对比。但有个前提:必须先处理异常值(比如身高里混了个“1000厘米”,不删掉会让所有正常数据都被“拉偏”)。
看公式图更直观:

大白话解释公式:用每个数据减去这列的最小值,再除以“最大值-最小值”,结果就全在0-1之间了。比如数据是[2,4,6],最小值2、最大值6,处理后就是[(2-2)/4=0, (4-2)/4=0.5, (6-2)/4=1]。
3. 第二步:数据离散化(把“连续数”切成“区间块”)
比如“年龄”是连续的(1-100岁),离散化就是把它切成“18岁以下”“18-30岁”“30-50岁”这样的区间。
但要注意:离散化会丢一点信息(比如把25和29都归为“18-30”,就看不出两者的差异了),得根据需求权衡。
看这两张图理解离散化的过程:


常用的“离散分箱”方法
分箱就是“切区间”的方式,看这张图里的常用类型:
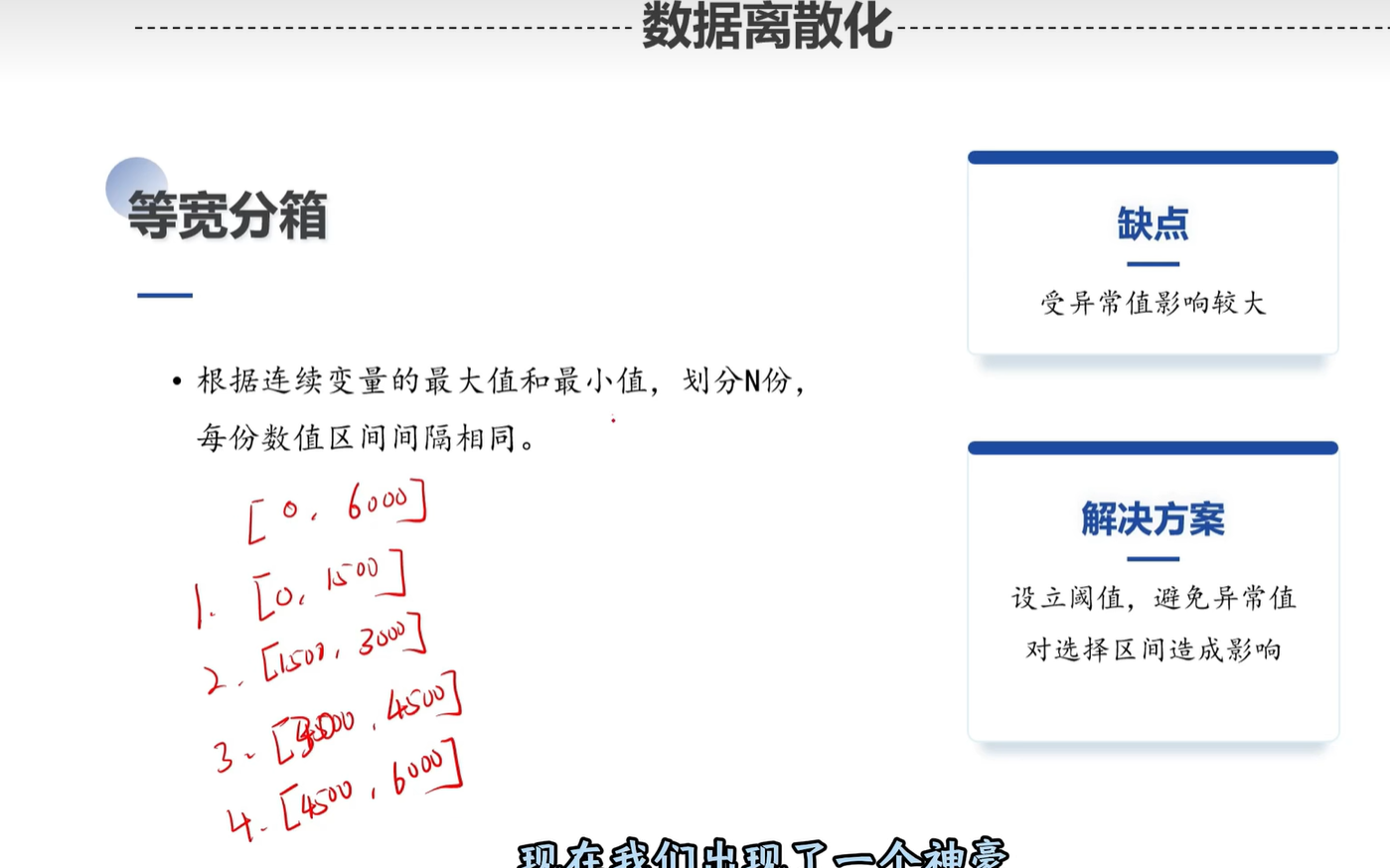
比如“等宽分箱”是每个区间宽度一样(像1-10,11-20);“等频分箱”是每个区间里的数据数量差不多(比如每个区间都有100个数据)。
4. 第三步:特征编码(把“文字”转“数字”,模型才懂)
模型只认数字,像“性别男/女”“职业教师/医生”这种文字数据,必须转成数字——这就是编码。
先看编码的核心逻辑:从离散到回归
为什么需要编码?看这张图就懂了:

简单说:离散数据(文字)不能直接代入回归模型计算,编码就是“翻译”过程。
三种常用编码,别搞混!
-
独热编码:适合“无大小关系”的分类
比如“颜色红/黄/蓝”,没有谁大谁小,就用独热编码——每个类别单独占一列,有这个类别就标1,没有就标0。
看例子图,能直观看到“互斥关系”(一个数据只能在一列标1):

-
哑编码:独热编码的“简化版”
比如独热编码对“红/黄/蓝”用3列,哑编码就用2列(比如用“黄=0,蓝=0”代表红),避免数据冗余。看这张图对比:

-
Label Encoding:适合“有大小关系”的分类
比如“学历小学<中学<大学<硕士”,有明确顺序,就用0、1、2、3这样的数字对应。看例子图:

5. 第四步:特征衍生(“造新数据”,让模型更准)
有时候原始特征不够用,比如只知道“身高”和“体重”,可以衍生出“BMI指数”(体重/身高²)——这就是特征衍生,能给模型多提供有用信息。
三种常见衍生方式
-
简单线性变化:比如BMI、“总价=单价×数量”,看这张图里的例子:

-
多项式扩增:把原始特征变成“平方、立方”,比如“x”变成“x、x²、x³”。但要注意:一般不超过三次,否则数据会太复杂(比如x=10,x³=1000,会盖过其他特征的影响)。看例子图:

-
对数变换:适合处理“偏态数据”(比如收入,大部分人几千,少数人几百万,数据堆在一边)。用对数转一下,数据会更“均匀”,模型更好学。看公式和例子图:

二、动手上机:用代码实现这些操作
理论懂了,接下来用代码落地——主要用Python的sklearn(预处理工具库)和pandas(数据处理库),先看要用的库函数:
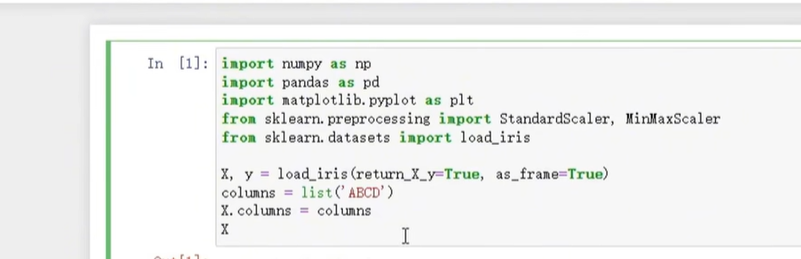
1. 先准备数据:输出同一特征看原始样
首先得明确“处理哪列数据”,比如我们只选“年龄”这一列来操作,先输出原始数据看看:
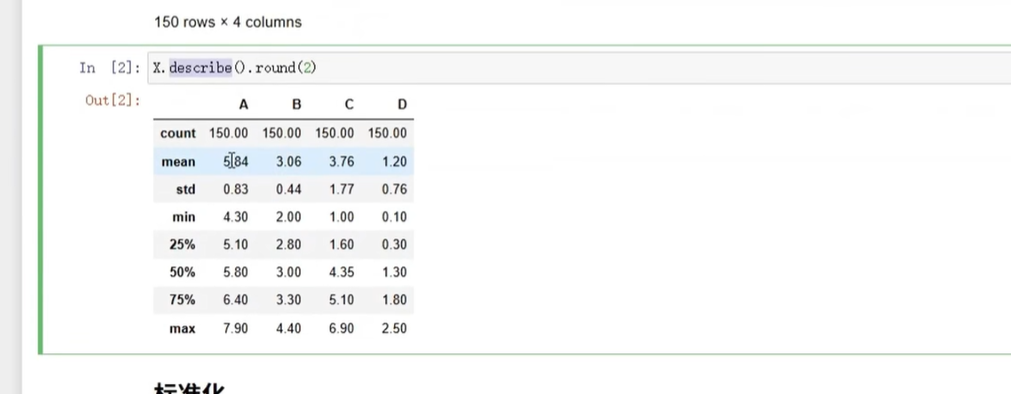
代码逻辑:用pandas读数据(比如Excel/Csv),然后用df['列名']选中要处理的特征,打印出来看原始值。
2. 实现标准化(用DataFrame操作)
(1)Z-score标准化(常用,让数据均值为0、标准差为1)
用sklearn.preprocessing.StandardScaler,步骤是“导入工具→拟合数据→转换数据”。看代码和结果图:
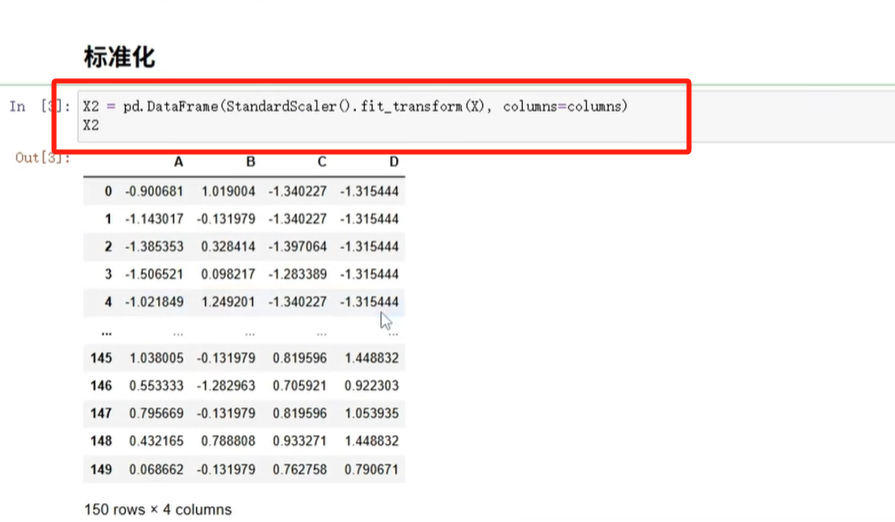
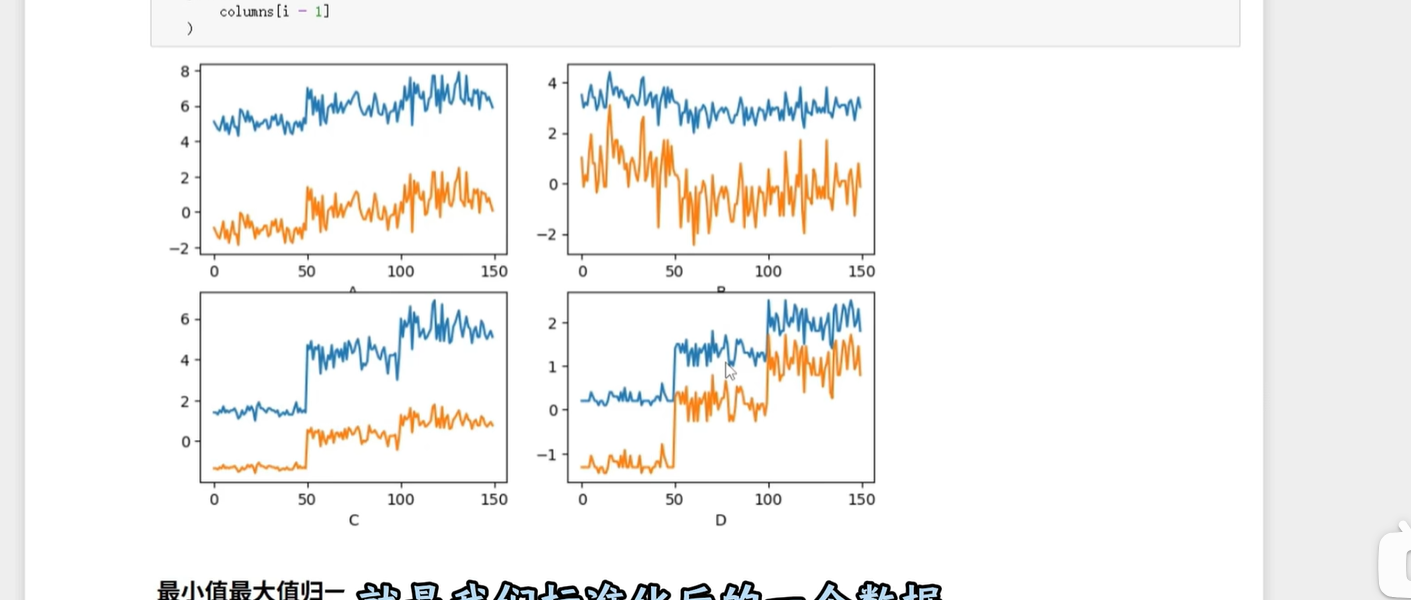
简单代码示例:
import pandas as pd
from sklearn.preprocessing import StandardScaler# 读数据(假设数据存在df里,有一列叫"age")
df = pd.read_csv("你的数据.csv")
# 初始化标准化工具
scaler = StandardScaler()
# 拟合+转换"age"列(注意:sklearn需要二维数据,所以用reshape(-1,1))
df['age_standard'] = scaler.fit_transform(df['age'].values.reshape(-1,1))
# 打印结果
print(df[['age', 'age_standard']])
(2)最小值-最大值归一化(缩到0-1)
用sklearn.preprocessing.MinMaxScaler,逻辑和标准化类似,看代码和结果图:
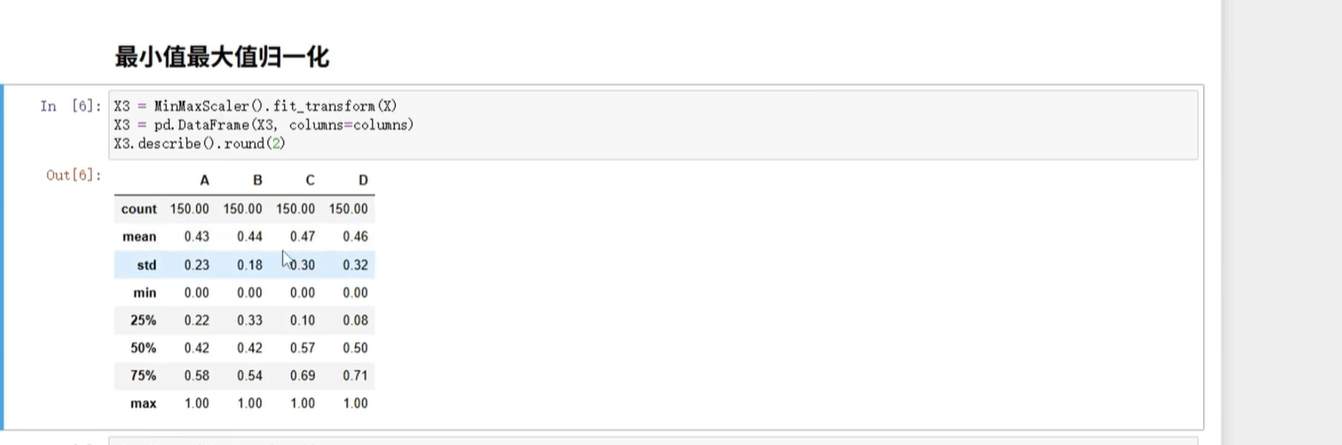
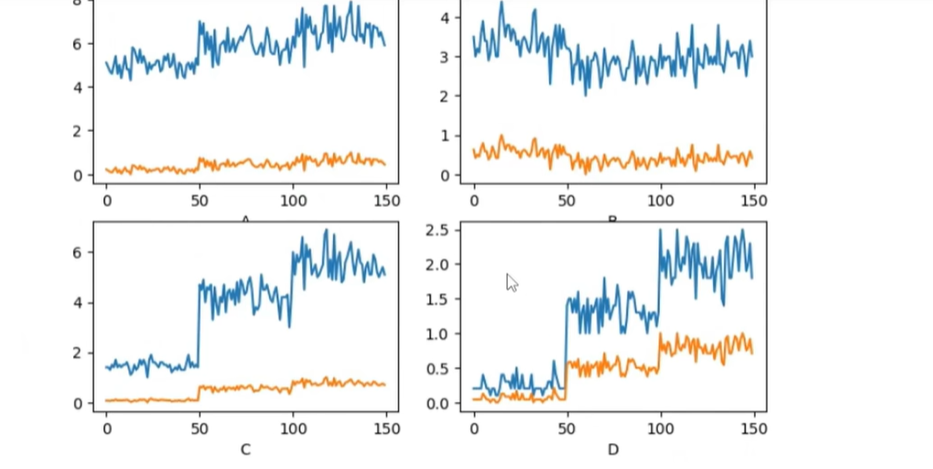
简单代码示例:
from sklearn.preprocessing import MinMaxScaler# 初始化归一化工具
minmax_scaler = MinMaxScaler()
# 拟合+转换
df['age_minmax'] = minmax_scaler.fit_transform(df['age'].values.reshape(-1,1))
# 打印结果
print(df[['age', 'age_minmax']])
3. 实现数据离散化(分箱)
(1)等宽分箱(每个区间宽度一样)
用pandas.cut,指定分箱数量即可,看代码图:
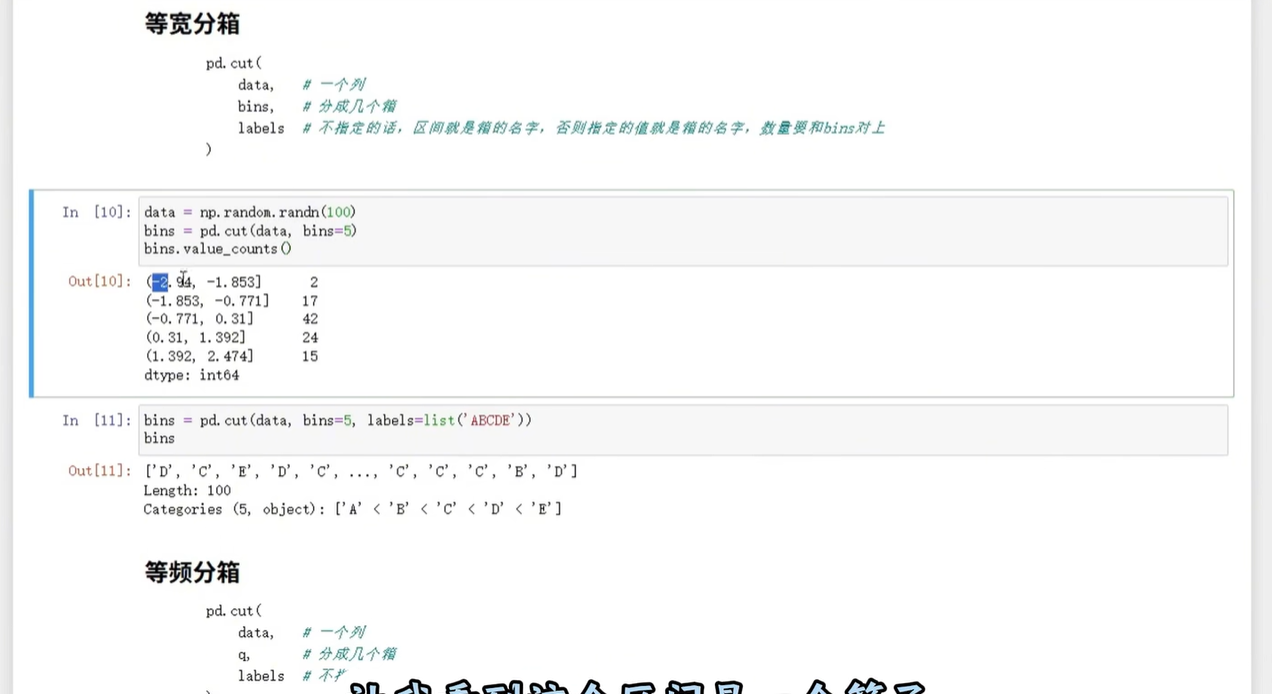
代码示例(把年龄分成3箱):
# 等宽分箱,分3箱,加标签
df['age_cut_width'] = pd.cut(df['age'], bins=3, labels=['低龄', '中龄', '高龄'])
print(df[['age', 'age_cut_width']].value_counts()) # 看每个区间的数量
(2)等频分箱(每个区间数据量差不多)
用pandas.qcut,同样指定分箱数量,看代码图:
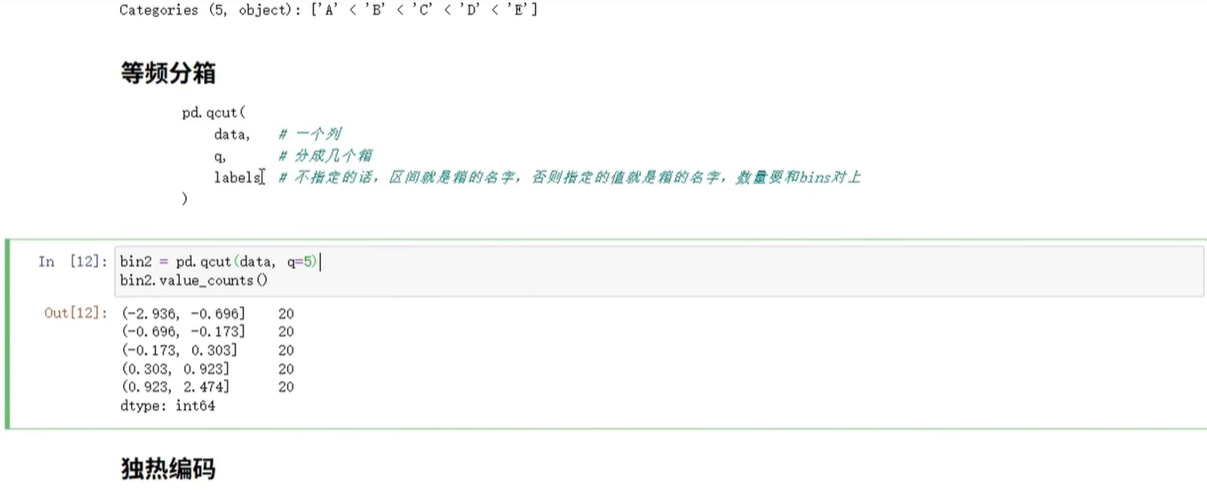
代码示例(把年龄分成3箱,保证每箱数量接近):
df['age_cut_freq'] = pd.qcut(df['age'], q=3, labels=['低龄', '中龄', '高龄'])
print(df[['age', 'age_cut_freq']].value_counts())
4. 实现特征编码
(1)独热编码
用pandas.get_dummies(简单直观)或sklearn.OneHotEncoder,看代码和结果图:

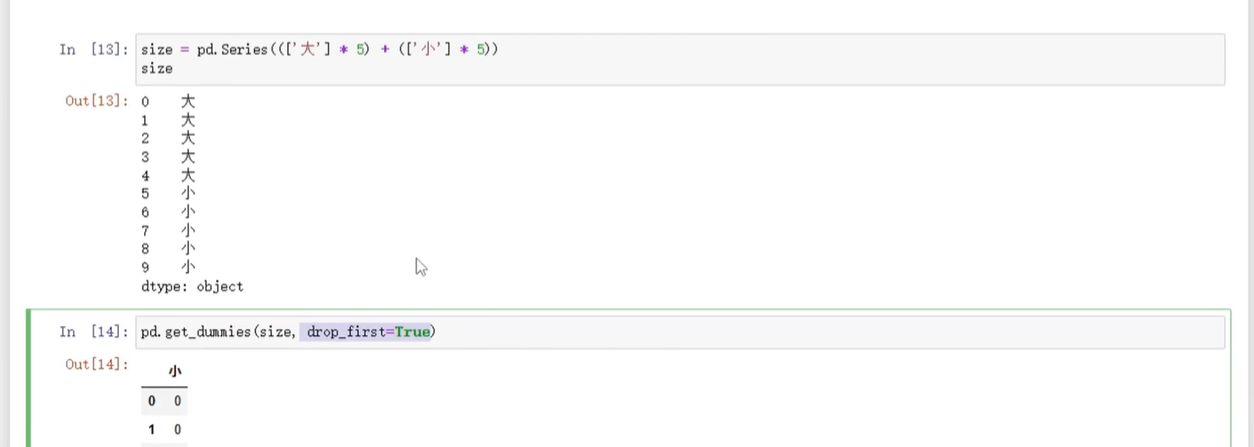
代码示例(对“性别”列做独热编码):
# 用get_dummies,直接生成编码列
gender_dummies = pd.get_dummies(df['gender'], prefix='gender') # prefix是列名前缀
# 把编码列合并回原数据
df = pd.concat([df, gender_dummies], axis=1)
print(df[['gender', 'gender_男', 'gender_女']])
(2)序列编码(Label Encoding)
用sklearn.preprocessing.LabelEncoder,适合有顺序的分类,看代码图:

代码示例(对“学历”列编码:小学=0,中学=1,大学=2):
from sklearn.preprocessing import LabelEncoder# 初始化编码工具
le = LabelEncoder()
# 拟合+转换(注意:先确保学历列是字符串类型)
df['education_label'] = le.fit_transform(df['education'])
# 查看编码对应关系
print(dict(zip(le.classes_, le.transform(le.classes_)))) # 输出:{'小学':0, '中学':1, '大学':2}
5. 实现特征衍生
(1)多项式扩增
用sklearn.preprocessing.PolynomialFeatures,比如把“年龄”衍生出“年龄²、年龄³”,看代码图:
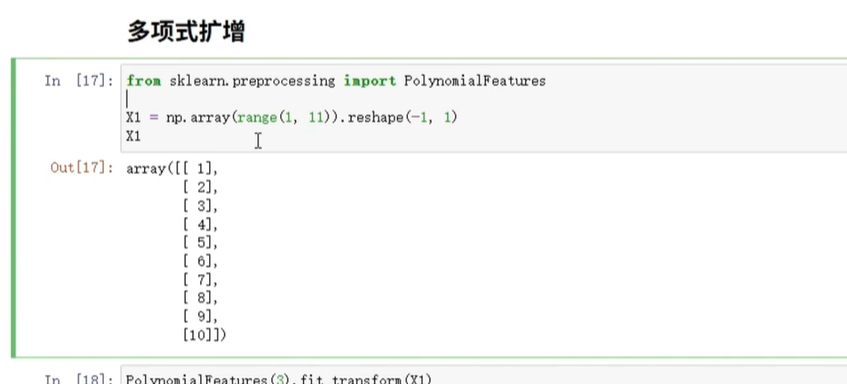
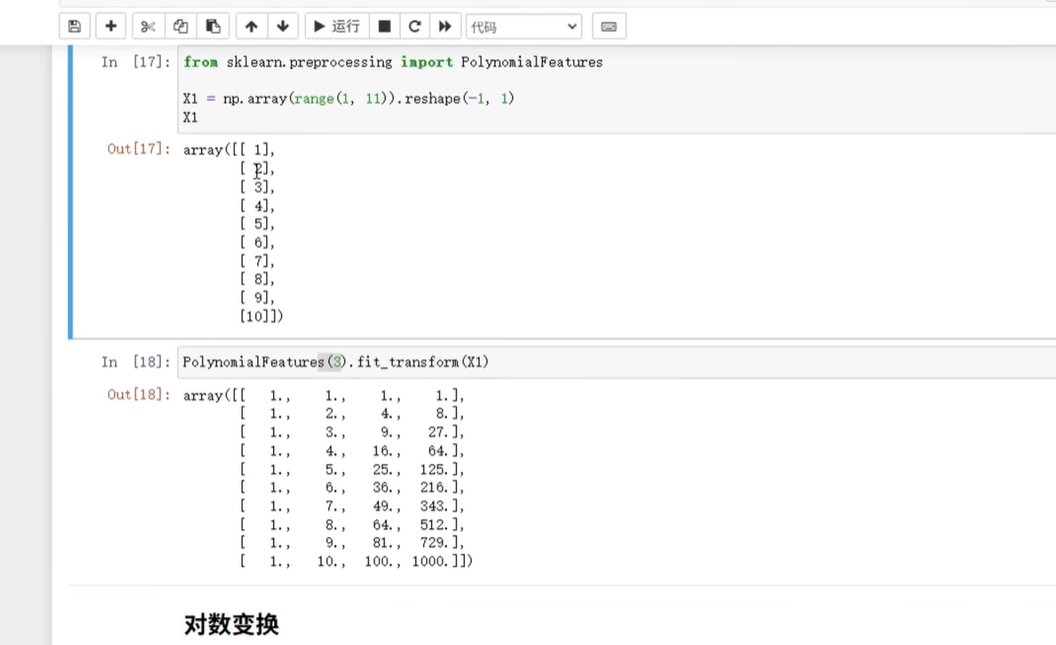
代码示例(扩增到3次项):
from sklearn.preprocessing import PolynomialFeatures# 初始化扩增工具,degree=3表示到3次项
poly = PolynomialFeatures(degree=3, include_bias=False) # include_bias=False去掉常数项
# 拟合+转换(注意二维数据)
age_poly = poly.fit_transform(df['age'].values.reshape(-1,1))
# 把结果转成DataFrame,加列名
age_poly_df = pd.DataFrame(age_poly, columns=[f'age^{i}' for i in range(1,4)])
# 合并回原数据
df = pd.concat([df, age_poly_df], axis=1)
print(df[['age', 'age^1', 'age^2', 'age^3']].head())
(2)对数变换
用numpy.log1p(log(1+x),避免x=0时出错),处理偏态数据,看代码图:
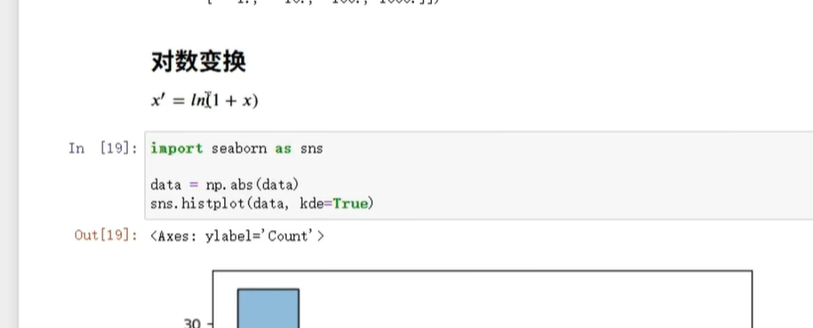
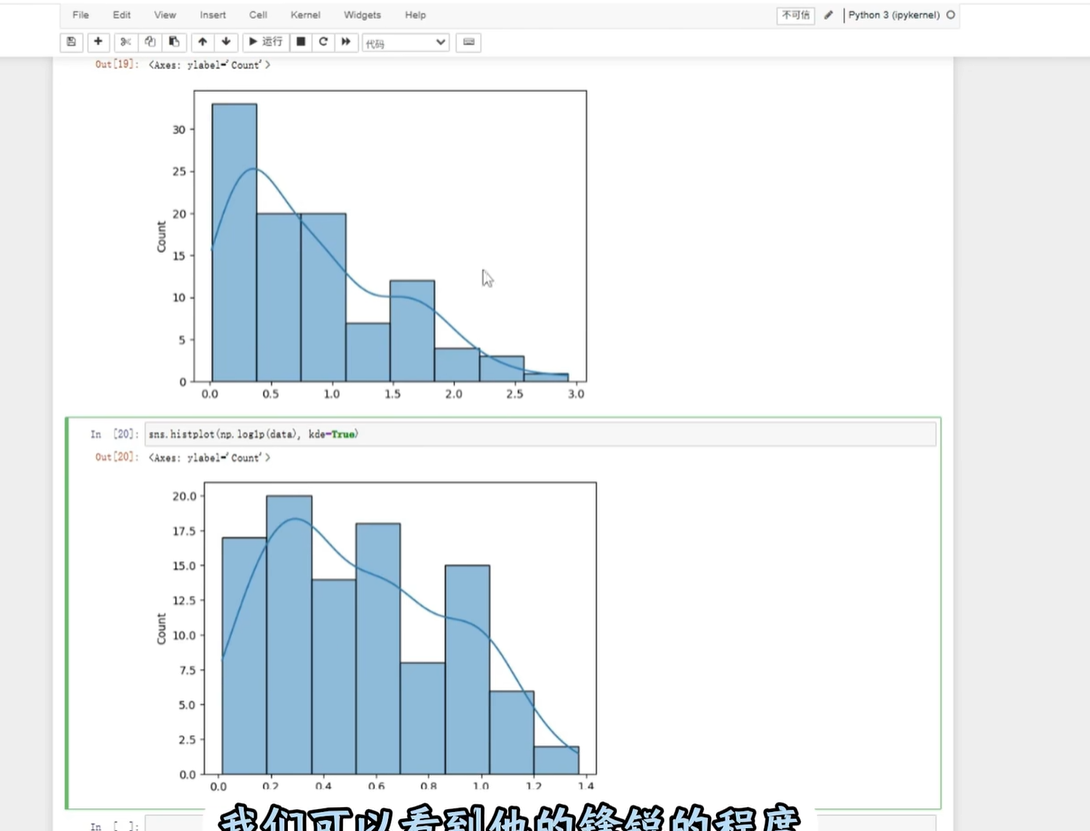
代码示例(对“收入”列做对数变换):
import numpy as np# 假设收入列是"income",先确保没有负数(对数不能处理负数)
df['income_log'] = np.log1p(df['income']) # log1p = log(1+income)
print(df[['income', 'income_log']].head())
总结
数据预处理就像“做饭前洗菜切菜”——不做不行,做不好影响后续口感(模型效果)。核心步骤就是:
- 标准化:统一数据范围;
- 离散化:把连续数据切区间;
- 编码:文字转数字;
- 衍生:造新特征补信息。
跟着上面的理论图和代码,一步步试,很快就能上手~