【Java鱼皮】智能协同云图库项目梳理
1、主要模块
- 用户模块:
- 用户注册、登录
- 用户分类(区分管理员、普通用户)
- 图片模块
- 图片上传(url上传 / 图片上传)、存储(COS对象存储)
- 删除
- 更新:图片名称、简介、标签等等文字性编辑;图片编辑:裁剪,旋转;AI扩图
- 查询:按照关键字(名称、标签,分类);按照主色调搜索
- 空间模块
- 每个用户提供定额私有空间
- 对于每张图片,区分每个用户对其的操作权限(审核、查看、编辑、删除)
- 对于每个空间,区分每个用户的权限(查看空间、在空间内操作图片)
- 团队模块
- 为特定一批用户提供一个共享的私有团队空间
- 区分团队空间内成员,每个成员对空间、空间内图片的操作权限。
2、库表设计
所有表的共有字段

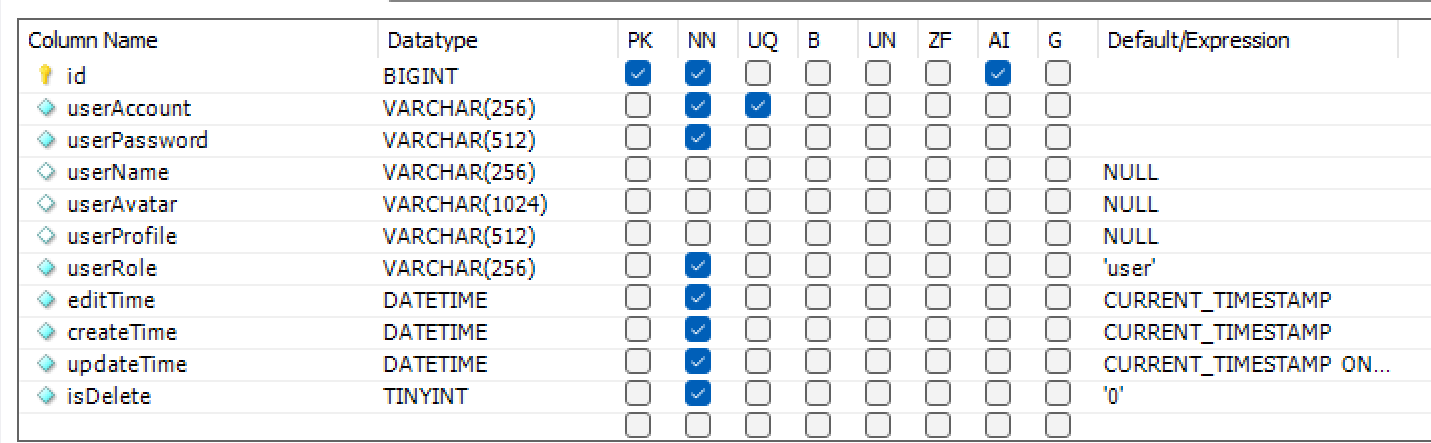
isDelete用于逻辑标记该行是否被删除,而在数据库中不做真正的删除操作。
用户表
图片表
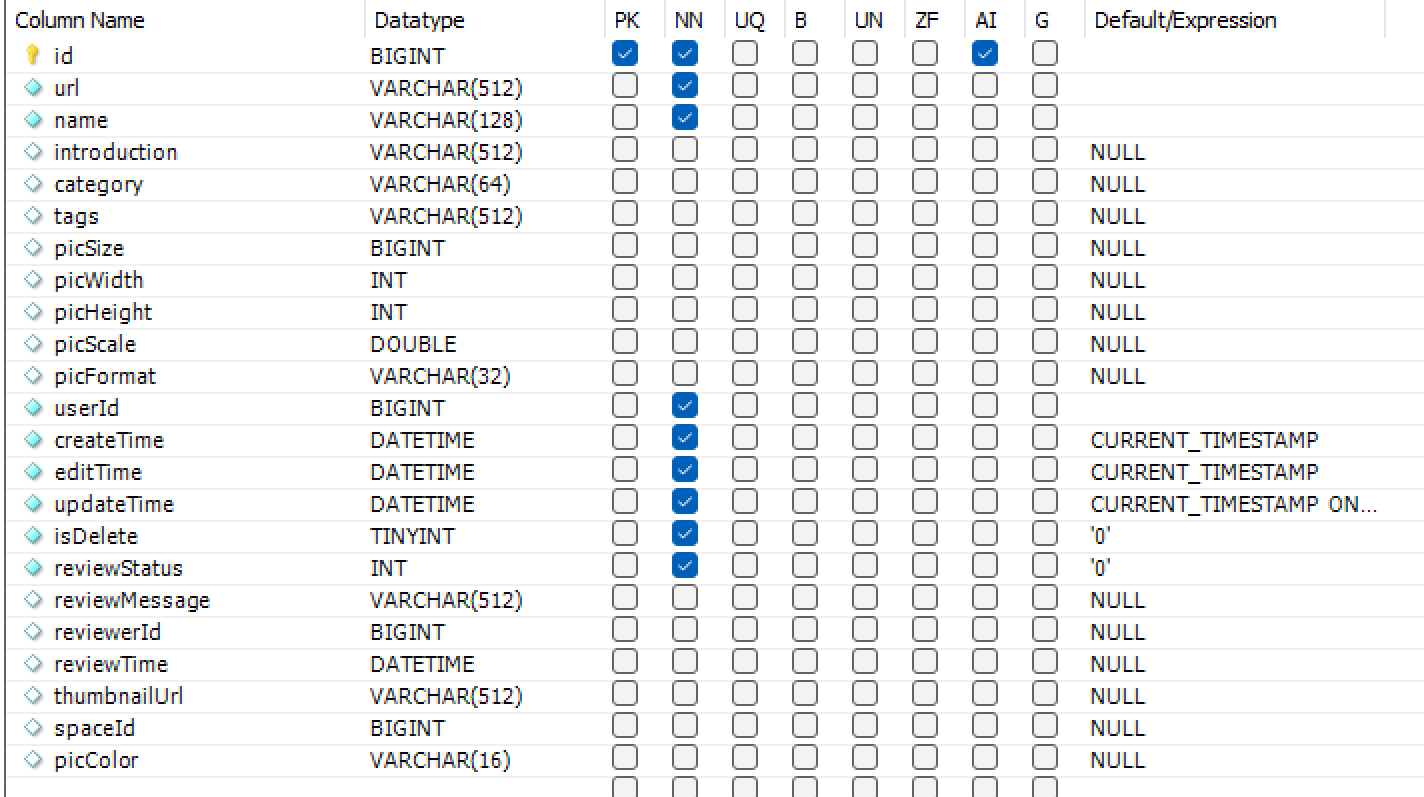
spaceId用于标记图片属于哪个图库(公共图库、私有图库、团队图库)。
review相关字段用于支持审核功能。公共图库上的图片需要管理员审核之后才公开。
thumbnailUrl用于支持缩略图加载功能,在主页上展示的图片默认加载缩略图。
picColor记录图片主色调,用于支持按照这色调查找图片的功能。
空间表
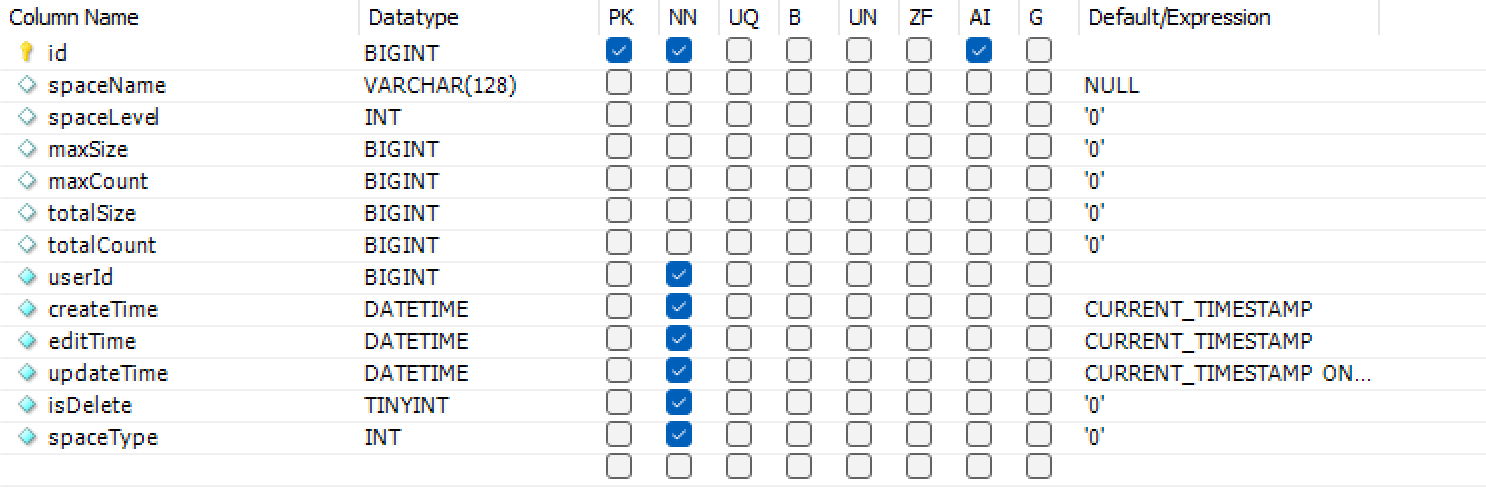
maxSize和maxCount标记空间使用限额,防止私有空间被上传无限张图片。
spaceLevel标记空间等级,不同等级的空间拥有的额度不同。
spaceType用于标记空间是团队空间还是个人空间
空间-成员表
用于支持团队空间。该表记录了团队空间内的成员。
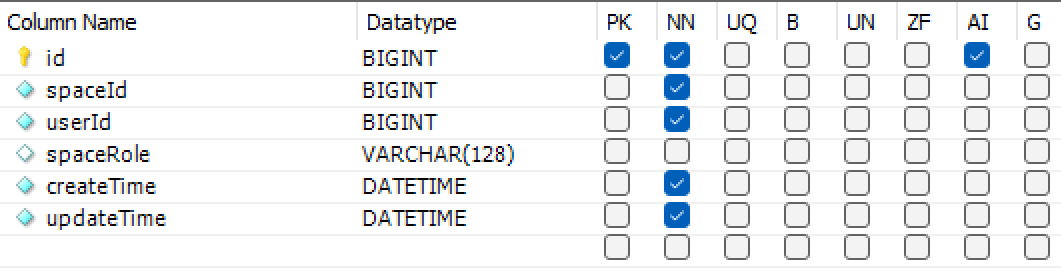
spaceRole用于区分团队内不同成员的不同角色,不同角色有不同的权限。
3、主要业务流程
通用逻辑
统一响应类
定义统一响应类,所有请求的返回值都将包装成统一相应类。
public class BaseResponse<T> implements Serializable {private int code;private String message;private T data;
}
将预先设想好的code定义成枚举类,以便后期使用维护。
public enum ErrorCode {SUCCESS(0, "ok"),PARAMS_ERROR(40000, "请求参数错误"),NOT_LOGIN_ERROR(40100, "未登录"),NO_AUTH_ERROR(40101, "无权限"),NOT_FOUND_ERROR(40400, "请求数据不存在"),FORBIDDEN_ERROR(40300, "禁止访问"),SYSTEM_ERROR(50000, "系统内部异常"),OPERATION_ERROR(50001, "操作失败");/*** 状态码*/private final int code;/*** 信息*/private final String message;ErrorCode(int code, String message) {this.code = code;this.message = message;}}响应工具类
为了使响应变得简单(无需每次手动构造响应对象),构建一个响应工具类ResultUtils。每次调用ResultUtils特定方法,即完成响应。
public class ResultUtils {//正常响应:包含数据public static <T> BaseResponse<T> success(T data) {return new BaseResponse<>(0, data, "ok");}//正常响应:不包含数据public static BaseResponse success() {return success(null);}//错误响应:使用Code枚举类public static BaseResponse<?> error(ErrorCode errorCode) {return new BaseResponse<>(errorCode);}//错误响应:自定义code和messagepublic static BaseResponse<?> error(int code, String message) {return new BaseResponse<>(code, null, message);}//错误响应:使用Code枚举类的错误码和自定义信息public static BaseResponse<?> error(ErrorCode errorCode, String message) {return new BaseResponse<>(errorCode.getCode(), null, message);}
}统一异常类处理
利用Spring框架提供的注解@ExceptionHandler,来统一处理异常。这里的办法是获取异常的类型,并直接包装成响应类(包含异常提示信息),返回。
public class GlobalExceptionHandler {@ExceptionHandler(BusinessException.class)public BaseResponse<?> businessExceptionHandler(BusinessException e) {log.error("BusinessException", e);return ResultUtils.error(e.getCode(), e.getMessage());}@ExceptionHandler(RuntimeException.class)public BaseResponse<?> runtimeExceptionHandler(RuntimeException e) {log.error("RuntimeException", e);return ResultUtils.error(ErrorCode.SYSTEM_ERROR, "系统错误");}
}分页查询请求类
由于未来的很多个表都可能涉及分页查询,这里统一封装一个分页查询请求PageRequset,以后涉及分页查询的请求封装类继承该类即可。
public class PageRequest {//当前页号private int current = 1;//页面大小private int pageSize = 10;//排序字段private String sortField;//排序顺序(默认升序)private String sortOrder = "descend";
}权限管理
这里的权限管理针对Controller里面的每个方法进行管理。权限校验通过,则放行方法,不通过,不放行。这里的权限校验仅仅区分三种情况:
- 无需登录就能放行
- 需要登录才放行
- 需要登录,且是管理员才放行
采用的方法是 注解+AOP切面。思路是:定义一个注解,注解接受一个参数,用于标记需要的权限(如果无需登录就能放行,则无需注解)。AOP切面,找到带有注解的方法,在方法执行之前,进行相应的权限校验逻辑。
用户模块
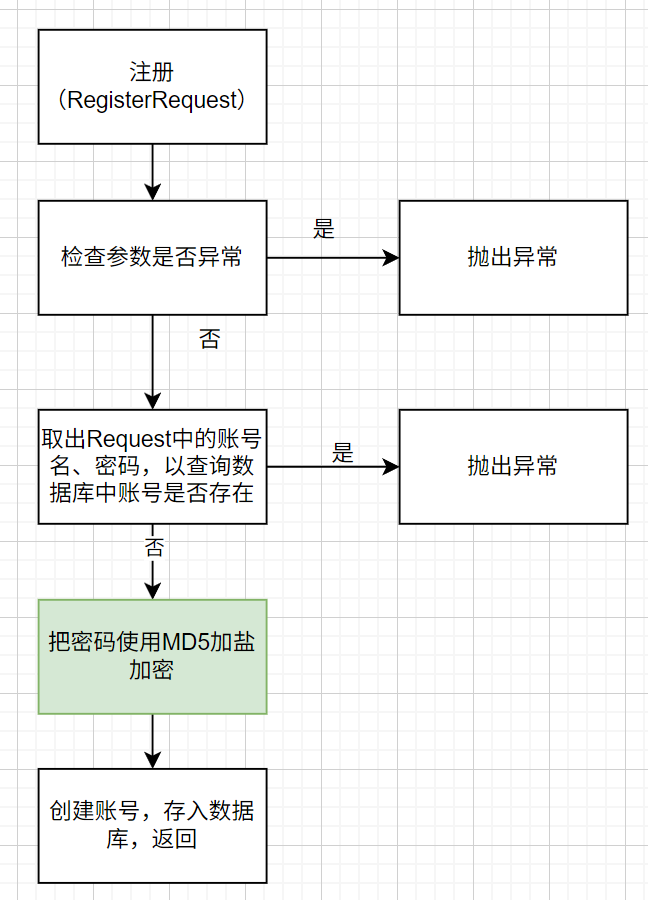
用户注册
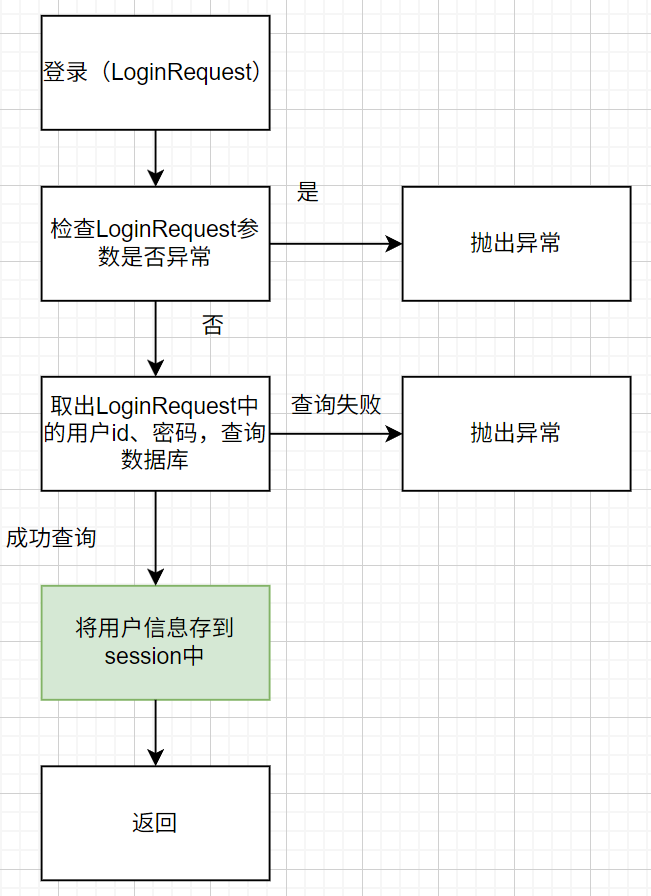
用户登录
用户登出
将session中对应的用户数据清楚,如果没有相关数据抛出“用户未登录”异常。
用户信息编辑
TODO
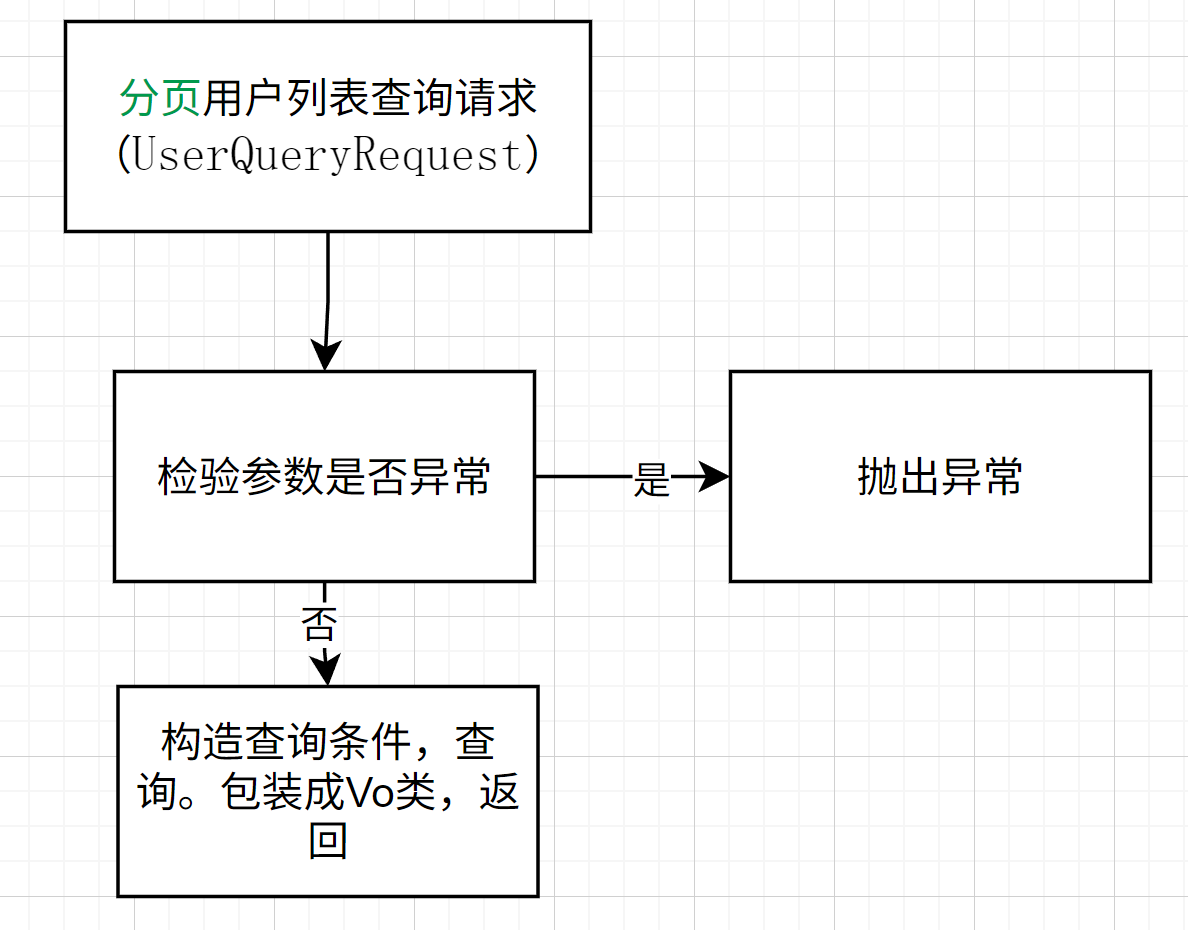
用户列表查询
图片模块
对象存储
云图库最重要的就是替用户保存图片。但是个人的本地服务器难以负荷这么多图片。因此这里选择使用第三方的对象存储服务,来保存本站的图片。
为了使用第三方服务,需要引入第三方提供的依赖,然后有响应的配置信息、配置类。
为了方便使用第三方服务,统一封装了CosManager
public class CosManager {/*** 上传对象* @param key 唯一键:取文件时根据唯一键(文件名)取* @param file 文件*/public PutObjectResult putPictureObject(String key, File file) {//……}/*** 下载对象* @param key 根据key获取对象*/public COSObject getObject(String key) {//……}/*** 删除对象* 从参数中FileUrl中获取唯一键* @param FileUrl*/public void deleteObject(String FileUrl) {//……}
}putPictureObject 逻辑
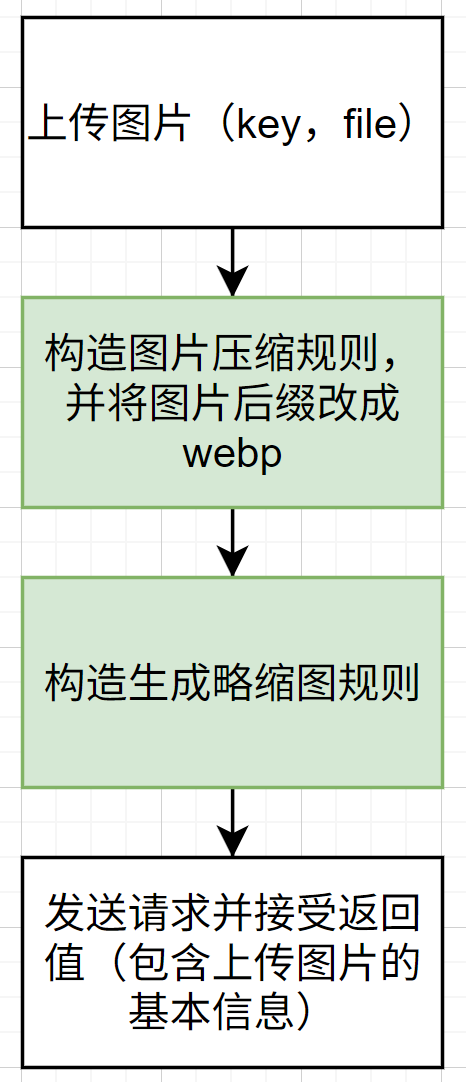
上传图片的同时,利用COS本身提供的额外服务,将图片压缩成webp形式,可以减少存储费用。同时产生对应的缩略图。在后面构建主页图片展示的时候,可以在主页展示缩略图,可以加快图片加载时间,降低访问流量,节约服务费用。
图片上传模板方法
由于图片上传的方式支持两种:图片直接上传、通过url上传。而这两种图片上传方式的流程大同小异,因此这里使用模板方式进行开发。
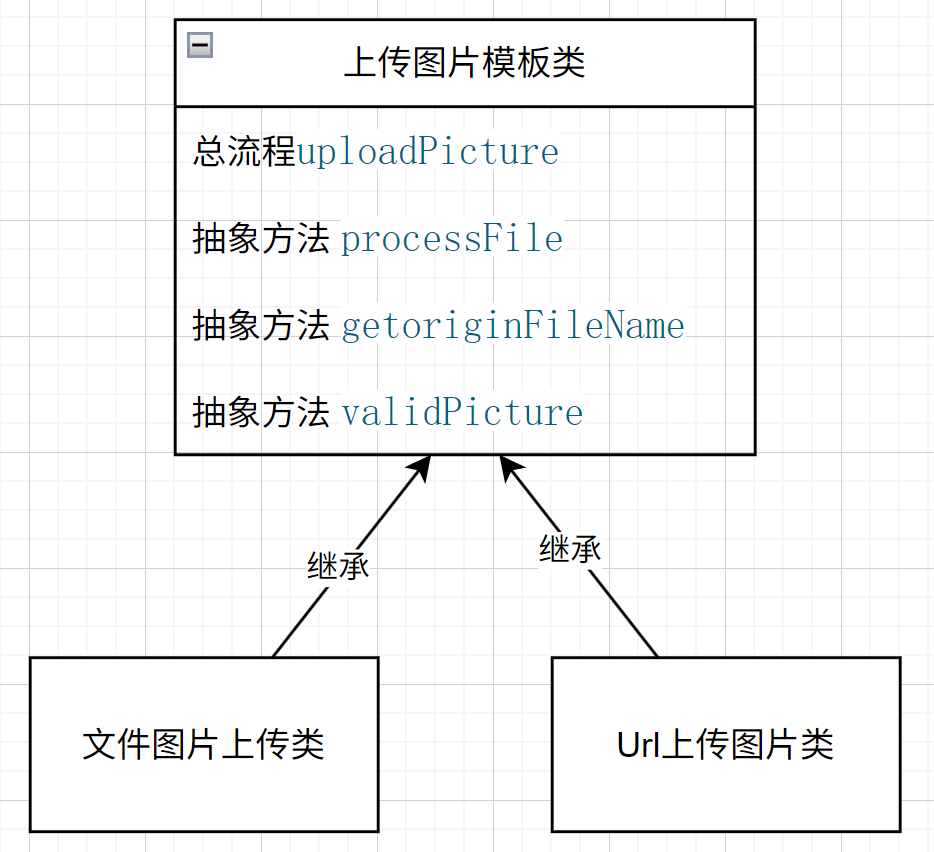
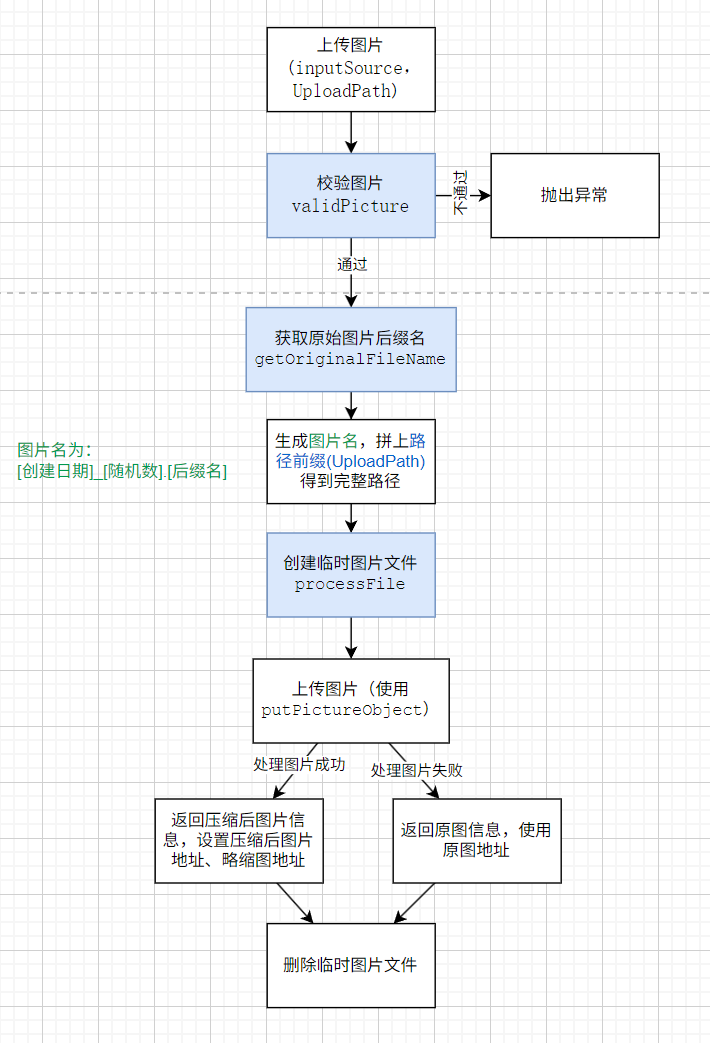
模板定义了上传图片的主流程,继承该模板的子类需要实现抽象方法。抽象方法为蓝色方框:
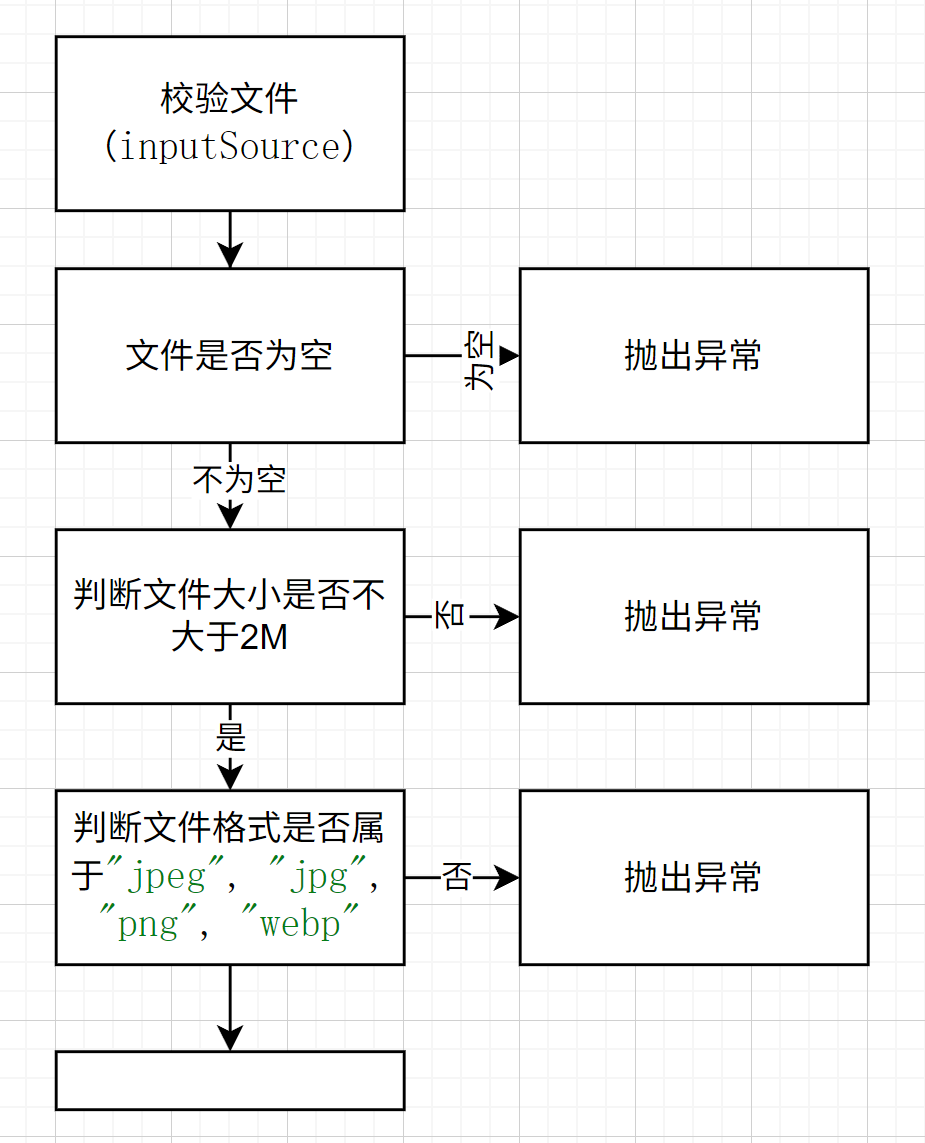
文件图片上传类
该类继承图片上传模板类,需要实现上图蓝色方框的抽象方法。由于这个类负责直接使用图片文件上传,只需直接对图片文件对象操作即可,大多比较简单。这里着重说明业务相关的图片校验方法的实现:
Url图片上传类
该类继承图片上传模板类,需要实现上图蓝色方框的抽象方法。该类在获取图片、获取图片后缀名的实现上,主要使用了 hutool工具类 的 HttpUtil.downloadFile() 方法和 FileUtil.mainName() 方法。前者提供了根据Url下载文件的功能,后者了提供根据文件路径获取文件后缀名的功能。
这里着重说明校验图片文件的逻辑。由于我们只需校验图片而非获取真正的图片,这里主要使用 HTTP 的 HEAD 方法来获取目标文件的元信息。这样可以大大减小流量开支。
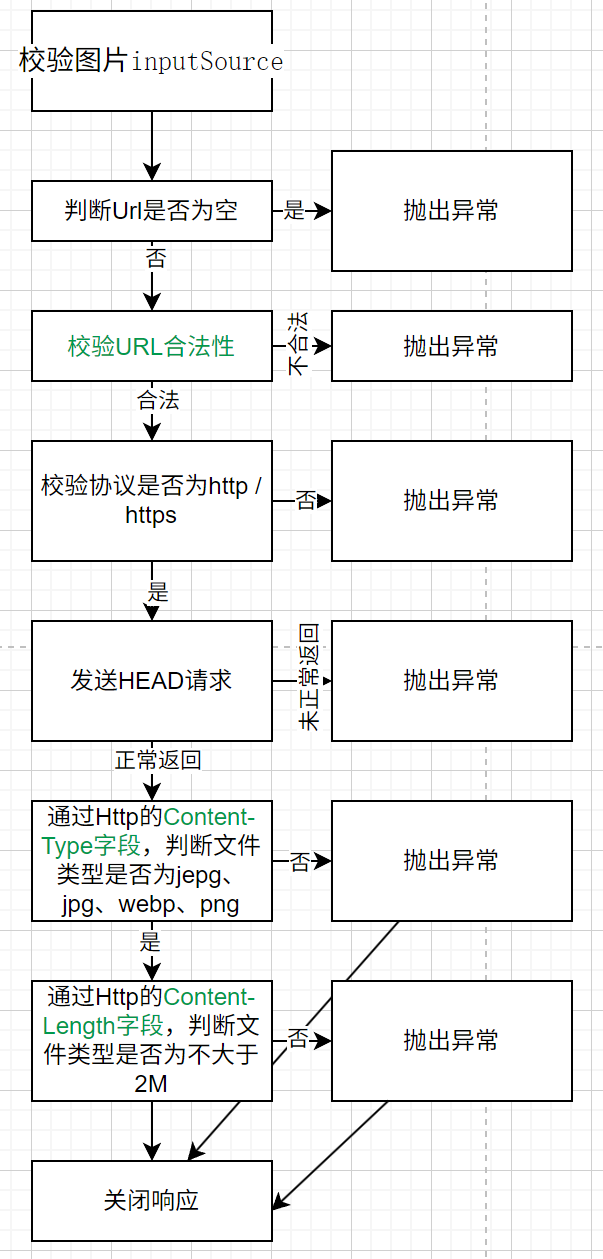
校验URL合法性
使用java.net.URL来实现。尝试使用它解析并创建URL对象,创建失败,即Url不合法。
//验证url合法性 try {new URL(fileUrl); } catch (MalformedURLException e) {throw new BusinessException(ErrorCode.PARAMS_ERROR, "文件地址不合法"); }
图片上传 / 图片编辑
该项目中,图片上传和图片编辑过程大相径庭。图片编辑实则是上传编辑好的新图片,将数据库中对应 url 改为编辑好的新图片,在 COS 中删除老图片。因此图片上传和图片编辑复用同一个接口,利用参数 pictureId 是否为空,来判断该操作为上传新图片还是编辑已有图片。
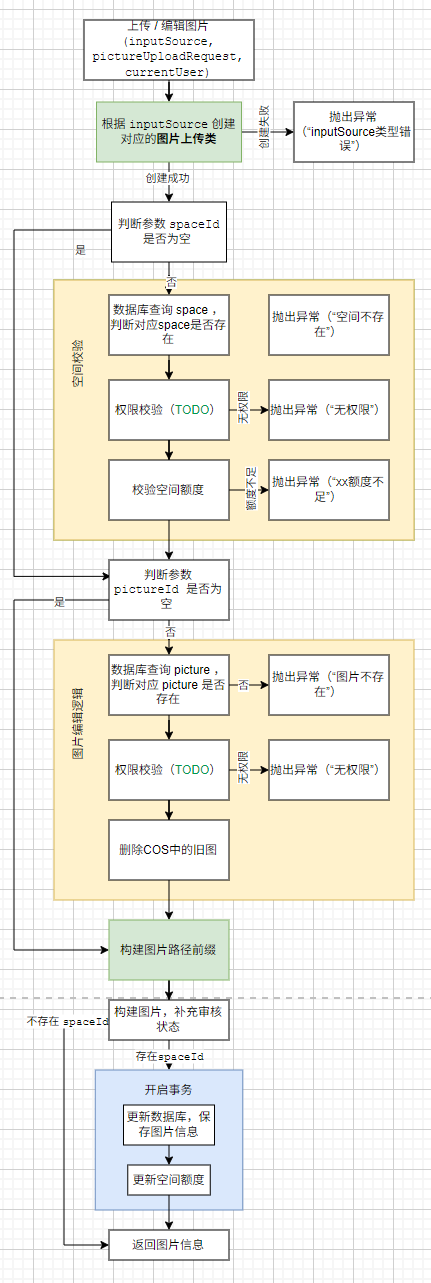
InputSource 设计
该上传图片方法接受的参数 inputSurce 设计为 Object 类。如果使用Url的方式上传,它就是String类型。如果使用文件图片的方式上传,它就是 MultipartFile 类型。通过类型的判断,可以得知使用什么方式上传的图片。
public PictureVo uploadPicture(Object inputSource, PictureUploadRequest pictureUploadRequest, User loginUser) {PictureUploadTemplate uploadTemplate = null;if(inputSource instanceof MultipartFile){uploadTemplate = filePictureUpload;}else if(inputSource instanceof String){uploadTemplate = urlPictureUpload;}//…… }图片文件路径前缀设计:
公共图库:public / [上传的用户id] /
私有图库:space / [图库id] /
补充审核状态
如果当前操作用户是管理员,审核状态设置为“过审”。否则审核状态设置为“待审核”。
TransactionTemplate 事务模板
为了保证数据库中空间额度和实际使用额度的一致性,这里使用事务来实现。
图片删除
逻辑比图片上传简单很多。进行权限校验后,开启事务完成图片删除和空间额度更新(如果图片属于私有空间)。
图片更新
指的是对数据库中字段的修改。如图片名称、图片类别、图片标签、简介……是简单的“改”操作,通过MyBatis框架实现。注意需要重新填充审核状态。
图片获取
简单的“查”操作。如果图片展示给前端需要包装成Vo类,对信息进行脱敏。
获取图片列表
对于主页展示的图片,由于访问频繁,如果每次访问都进行一次数据库查询操作,则对数据库造成的压力很大。因此这里可以使用多级缓存来提高查询速度、降低数据库压力。
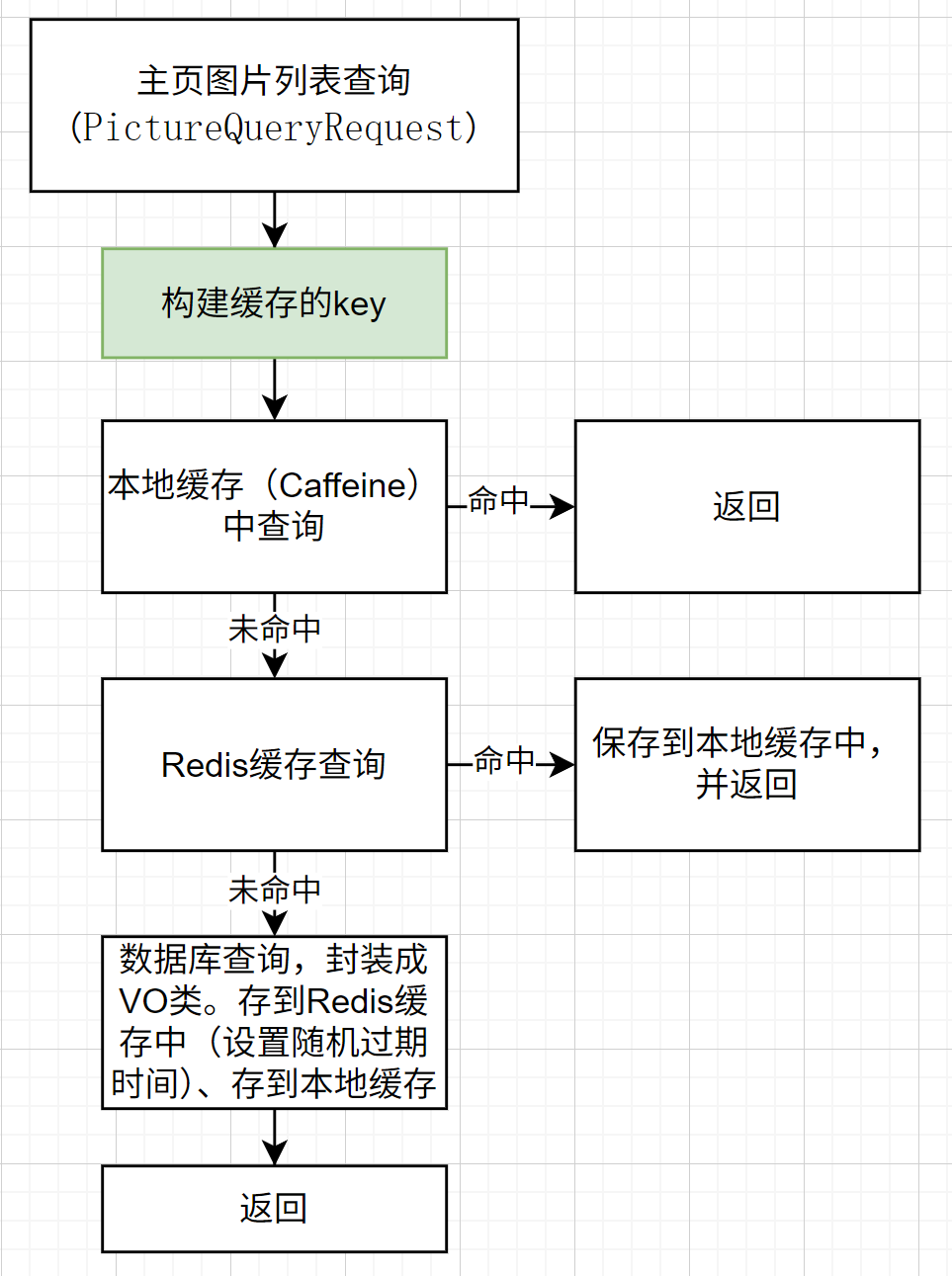
构建缓存的Key
缓存的Key通常为String形式。如果直接将查询条件转换成 Json 会导致Key冗长,占据大量存储空间,查询效率也没那么高。因此这里将查询条件的Json字符串的MD5码作为Key
批量抓取图片
前期构建网站的时候,网站图片资源比较缺乏,因此给管理员提供了快速从网络上批量抓取图片的方法。主要方法是,服务器模仿网页的图片查询请求,向bing的搜图接口发送图片搜索请求,然后解析返回结果中图片的url,再用url图片上传的方式将抓取的图片上传到自己的服务器上。
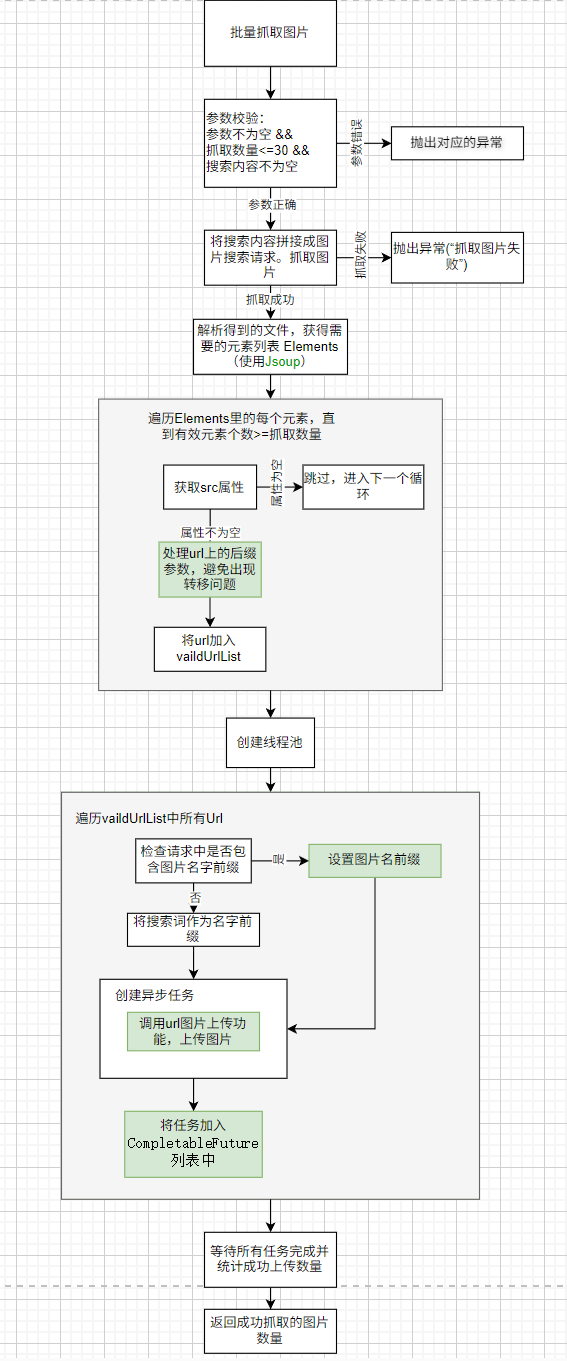
Jsoup
批量图片抓取主要是事先通过分析bing的图片搜索功能的接口、对应的响应。包括对响应的HTML的分析,来获取使用bing来抓取图片的接口。
通过分析,每次搜索图片,bing都会响应一个HTML文件,该文件有我们需要的图片的URL。
通过使用Jsoup提供的 Document.select() 方法,能方便解析HTML的各个元素。通过每个元素的 element.attr() 方法,可以获得对应元素的属性。
url后缀参数处理
爬取的图片URL中可能包含很多查询参数。这里将这些参数通通去掉。
如URL可能为
https://example.com/image.jpg?sid=12345&cb=67890×tamp=1234567890
处理后URL变成:
https://example.com/image.jpg
这样处理的好处【通义千问】
避免临时链接失效:许多图片服务生成的带参数URL可能是临时有效的
确保直接访问:去除参数后得到的是图片的直接访问地址
提高稳定性:避免因查询参数变化导致的图片访问失败
统一格式:确保存储的都是标准的图片URL格式
这是图片爬取和处理中的常见做法,目的是获取稳定、持久的图片访问地址。设置名字前缀
该项目支持在批量抓取图片的时候,自定义图片名字。每张图片名字将被设置为:
[自定义图片名]_[序号].[图片格式]
如果没有自定义图片名,则用搜索词代替。
CompletableFuture
由于对抓取的每张图片的url进行上传操作,都涉及两次网络请求(一次校验图片url的合法性、一次请求文件),如果每个图片的上传操作串行执行,这个过程会比较慢。因此这里采用异步的方式,对每个url创建一个上传任务。
至于CompletableFuture,本质上用于等待所有异步任务处理完成。其实使用CountDownLatch来实现这一功能也可行。但是CompletableFuture相对更加灵活,如果后续需要对抓取失败的图片进行重传,CompletableFuture 可通过 exceptionally() 直接处理,而 CountDownLatch 需额外记录失败任务信息。
【豆包】
对比维度 CountDownLatchCompletableFuture.allOf()核心能力 仅支持 “计数等待”(等待计数减为 0),不直接处理任务结果 不仅能等待所有任务完成,还能便捷处理任务结果(成功 / 失败)、链式调用 结果处理 需额外用原子类(如 AtomicInteger)统计成功数,无法直接获取单个任务结果可通过 join()直接获取每个任务的结果(如future.join()判断是否成功),无需额外原子类异常处理 任务异常需在任务内部捕获(否则线程会退出但不影响计数),主线程无法感知单个任务异常 可通过 exceptionally()或handle()统一处理异常,也可通过join()捕获异常灵活性 计数一旦减为 0, CountDownLatch就失效(不可重复使用),不支持任务依赖支持链式调用(如任务完成后自动执行后续逻辑)、任务依赖(如 A 任务完成后执行 B 任务),且可重复创建 代码简洁性 需手动管理计数( countDown()必须在finally中调用),代码稍繁琐链式调用更简洁,无需手动管理计数,结果统计更直观
按颜色搜索图片
这个功能只在私有空间中提供,主要是根据图片主色调进行分页搜索。图片主色调是在上传图片的时候,通过第三方服务获取,并保存至数据库中的。
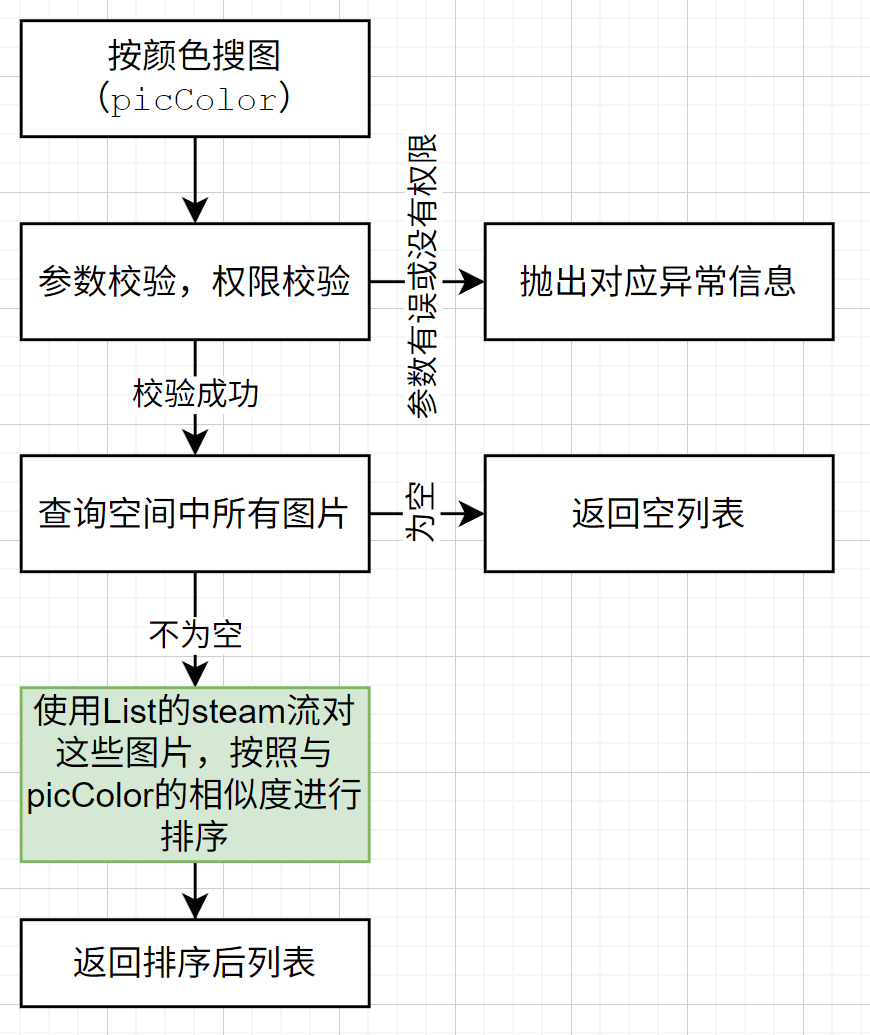
颜色RGB值
计算机中的颜色常用RGB值来表示,该值是一个三维向量(R,G,B)。分别表示颜色红、绿、蓝三个分量的大小。
计算颜色相似度的时候使用欧几里得算法,相当于计算三维空间中两点之间的距离,距离越小,颜色越相似。
以图搜图
真正的以图搜图应该是在特定图片集中搜索相似图片。实现这个功能一般使用第三方API。但本项目目前没有实现。而是以网络抓取的形式,在网络中搜索相似图片。
本项目是让服务器模拟浏览器行为,向百度以图搜图API发送搜索请求。同样首先需要分析相关API,得到目标的HTML资源文件,然后利用Jsoup和Hutool的网络http相关工具实现。
百度以图搜图,从输入文件到获得相似图片url列表的过程涉及多个API的调用以及结果的处理,因此这里使用门面模式统一管理这些过程,而只对外提供简洁易用的接口。
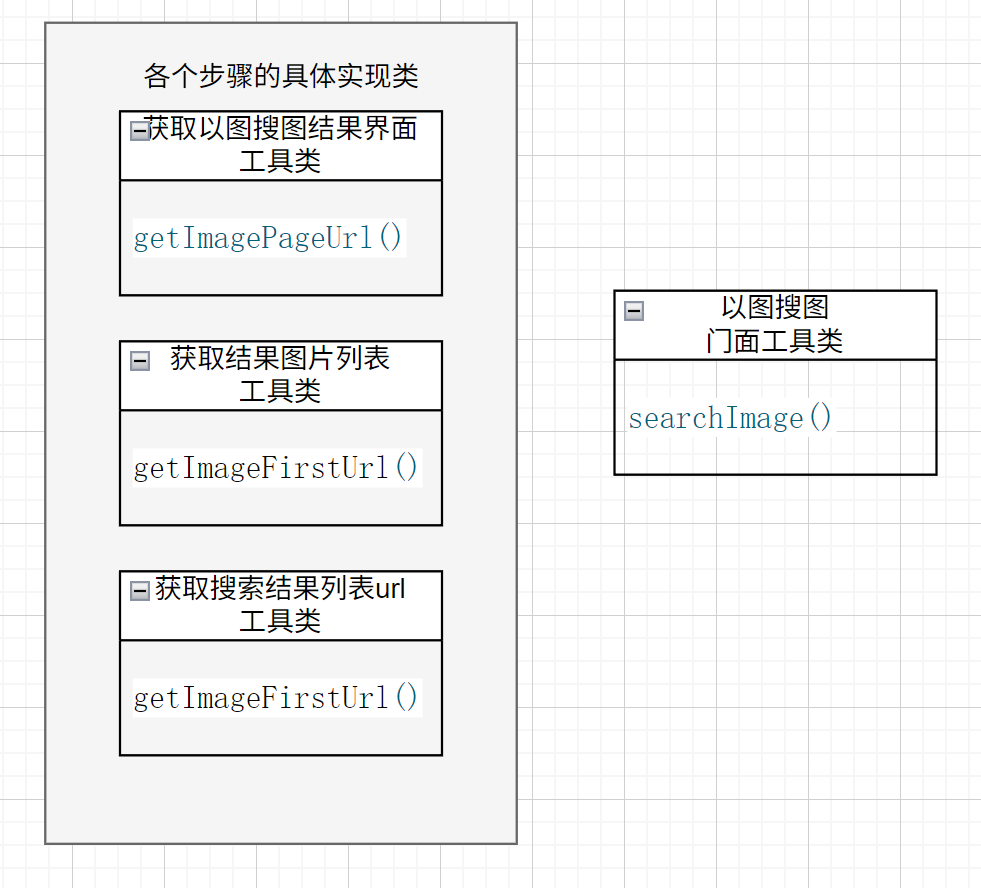
门面类里面包含的唯一方法提供对这些具体的过程进行封装:
public static List<ImageSearchResult> searchImage(String imageUrl) {String imagePageUrl = GetImagePageUrlApi.getImagePageUrl(imageUrl);String imageFirstUrl = GetImageFirstUrlApi.getImageFirstUrl(imagePageUrl);List<ImageSearchResult> imageList = GetImageListApi.getImageList(imageFirstUrl);return imageList;
}AI扩图
该功能主要调用第三方AI服务的API完成。这个功能的主要问题在于,AI扩图需要一定的时间,AI服务并不能立即将结果返回。且AI服务通常需要客户端(相对于第三方服务而言的客户端,如该云图库项目中的服务器)主动向AI服务请求任务的完成情况。
一般会选择使用轮询的方式向AI服务请求任务结果。如果使用项目中后端服务器来实现轮询,由于任务阻塞,很容易造成后端服务器资源耗尽。所以该项目采用前端轮询的方式实现。
具体为:前端向后端查询任务情况,后端作为“中介”请求AI服务,并将结果立即返回给前端。

后端需要提供两个接口:
- AI扩图任务创建接口
- AI扩图任务完成情况查询接口
空间模块
空间创建(同步块:一人一“单” + 事务:多表一致性)
空间创建本质就是一个数据库“增”操作。但为了避免一个用户创建多个私有空间 / 团队空间,使用“用户锁”来确保同一时间一个用户只有一个线程在创建空间。
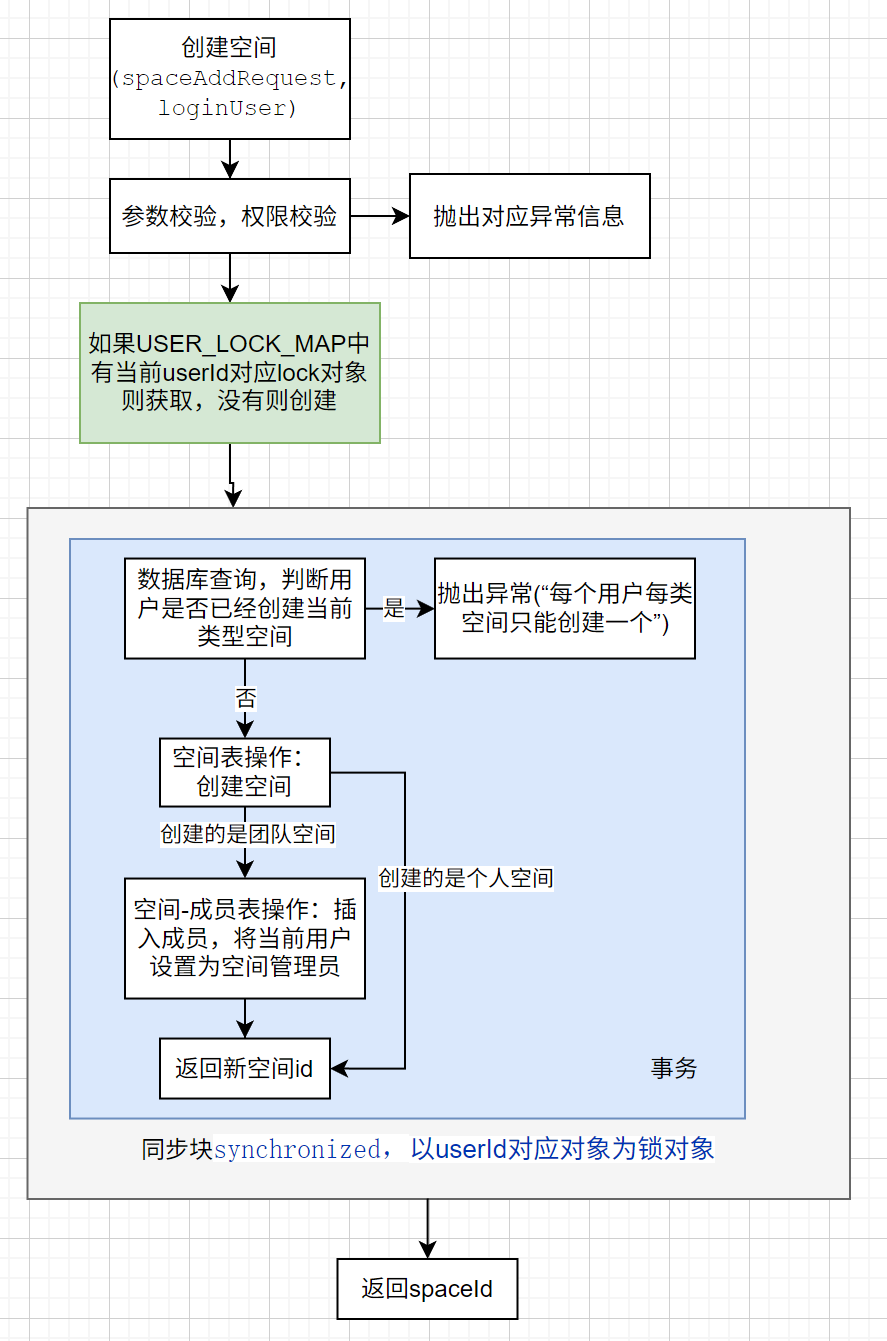
ConcurrentHashMap
在改方法对应的类中,维护一个静态的 ConcurrentHashMap。使用 putIfAbsent() 这个原子性的方法避免并发安全问题。这个Map作为一个对象池维护每个不同userId对应的锁对象。尽管存在一定的内存泄露,但由于每个键值对只占用32字节,100万用户仅仅消耗32MB。
TODO 后期优化可以加入定期清理锁对象的逻辑,规避内存不足的风险。
private static final ConcurrentHashMap<Long, Object> USER_LOCK_MAP = new ConcurrentHashMap<>();synchronized 同步块
以获取到的userId对应锁对象来锁住同步块,以实现一个用户同一时间只有一个线程进入“创建空间”的核心逻辑
事务
使用 transactionTemplate 事务来保证创建团队空间的时候,创建空间和空间成员表的一致性。
编辑 / 更新空间
编辑空间是给用户使用的接口,提供编辑空间名字的功能。
更新空间是给管理员使用的接口,提供为空间升级、降级的功能。
这两种操作都很简单,在参数校验、权限校验之后,利用MyBatis-Plus进行简单的“改”操作即可。
根据id查询空间
在参数校验、权限校验之后,利用MyBatis-Plus进行简单的“查询”操作即可。这里涉及两个接口,给管理员用的和给普通用户使用的,对于后者的操作,将space脱敏,返回spaceVo即可。
根据id查询空间列表
和上面逻辑类似。不同的是这是分页查询
空间使用情况分析(大量查询的优化)
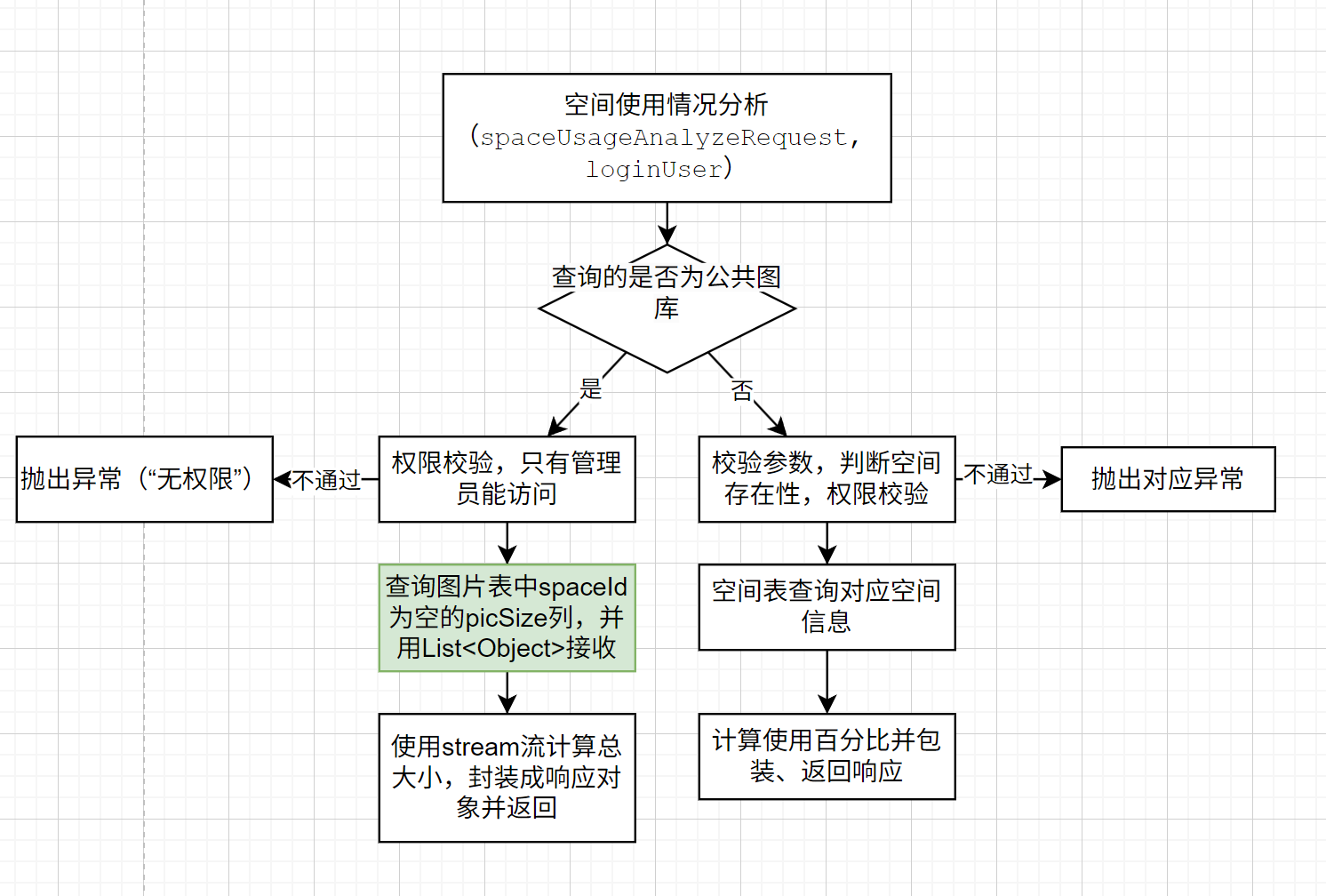
计算公共图库图片总大小的时候,需要查询图片表中所有属于公共图库的图片,由于查询的行比较多,为了节约性能,仅仅查询需要的列picSize(图片大小)。
接收查询结果的时候,为了节约内存,使用Object接受查到的每个对象,而非Picture。因为一个Picture包括很多字段,体积较大。
获取空间中图片的分类
简单的数据库MyBatisPlus“查”操作。使用SQL聚合函数统计空间内图片的分类情况。
// 使用 MyBatis-Plus 分组查询
queryWrapper.select("category AS category","COUNT(*) AS count","SUM(picSize) AS totalSize").groupBy("category");获取空间中图片的标签(stream流)
库表中每个图片有一个tag字段,这个字段保存一个字符串,字符串是Json格式的 List<String>。List中的每个元素都是一个标签。
库表查询是很简单的,有点复杂的是如何统计查询出来的tag。(其实使用“笨方法”for循环遍历每个Json字符串也能解决。)
该项目使用的处理方法是使用stream流统一对tag进行处理。
// 查询所有符合条件的标签
queryWrapper.select("tags");
List<String> tagsJsonList = pictureService.getBaseMapper().selectObjs(queryWrapper).stream() //获得流.filter(ObjUtil::isNotNull) //过滤为null的元素.map(Object::toString) //将每个元素映射(转换)为String类型.collect(Collectors.toList()); //收集流,转换成List// 合并所有标签并统计使用次数
Map<String, Long> tagCountMap = tagsJsonList.stream().flatMap(tagsJson -> JSONUtil.toList(tagsJson,String.class).stream()) //扁平化处理,对流中的每个Json串元素,将其转换成List<String>类型,再合并成大流.collect(Collectors.groupingBy(tag -> tag, Collectors.counting()));//将流中的元素收集,并根据tag分类,并计算每个分类的数量// 转换为响应对象,按使用次数降序排序
return tagCountMap.entrySet().stream().sorted((e1, e2) -> Long.compare(e2.getValue(), e1.getValue())) // 降序排列.map(entry -> new SpaceTagAnalyzeResponse(entry.getKey(), entry.getValue())).collect(Collectors.toList());基于时间维度,统计用户上传图片数量 (格式化函数+COUNT实现日期分类)
简单得数据库表操作。重点在于需要了解SQL提供的函数。
使用 DATE_FORMAT函数 / YEARWEEK 函数 将 DateTime字为想要的分类的格式,如“年月日”、“某年某周”,再结合聚合函数 COUNT() 和GROUP BY 实现分类统计。
如:
-- 按天统计
SELECT DATE_FORMAT(createTime, '%Y-%m-%d') AS period,COUNT(*) AS count
FROM your_table
WHERE createTime BETWEEN '2023-01-01' AND '2023-12-31'
GROUP BY period
ORDER BY period;团队模块-团队协作
本项目的在线协作编辑相比较成熟的企业的产品,功能比较有限。
业务设计
业务功能大致设计为:
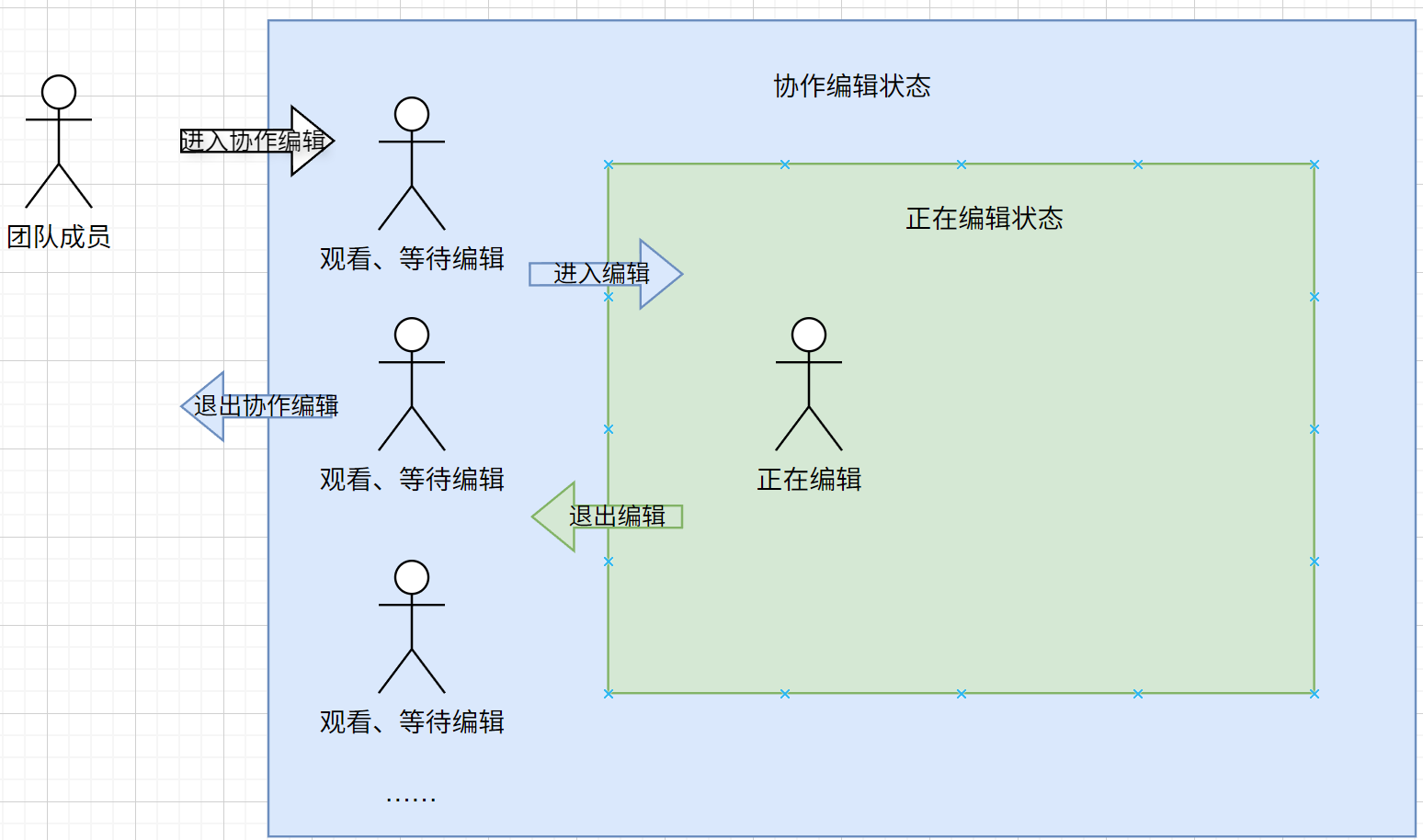
- 对于同一个图片,团队成员可以进入“协作编辑状态”。
- 有多个成员可以处于“协作编辑状态”,处于该状态的成员可以实时看到正在编辑图片的成员对图片的操作,即可以实时看到图片发生的变化。
- 处于“协作编辑状态”的成员可以选择进入“正在编辑状态”。同一时刻仅允许最多一个成员处于“正在编辑状态”。
- 处于“正在编辑状态”的成员可以选择退出“正在编辑状态”,处于“协作编辑状态”的成员可以选择退出“协作编辑状态”。
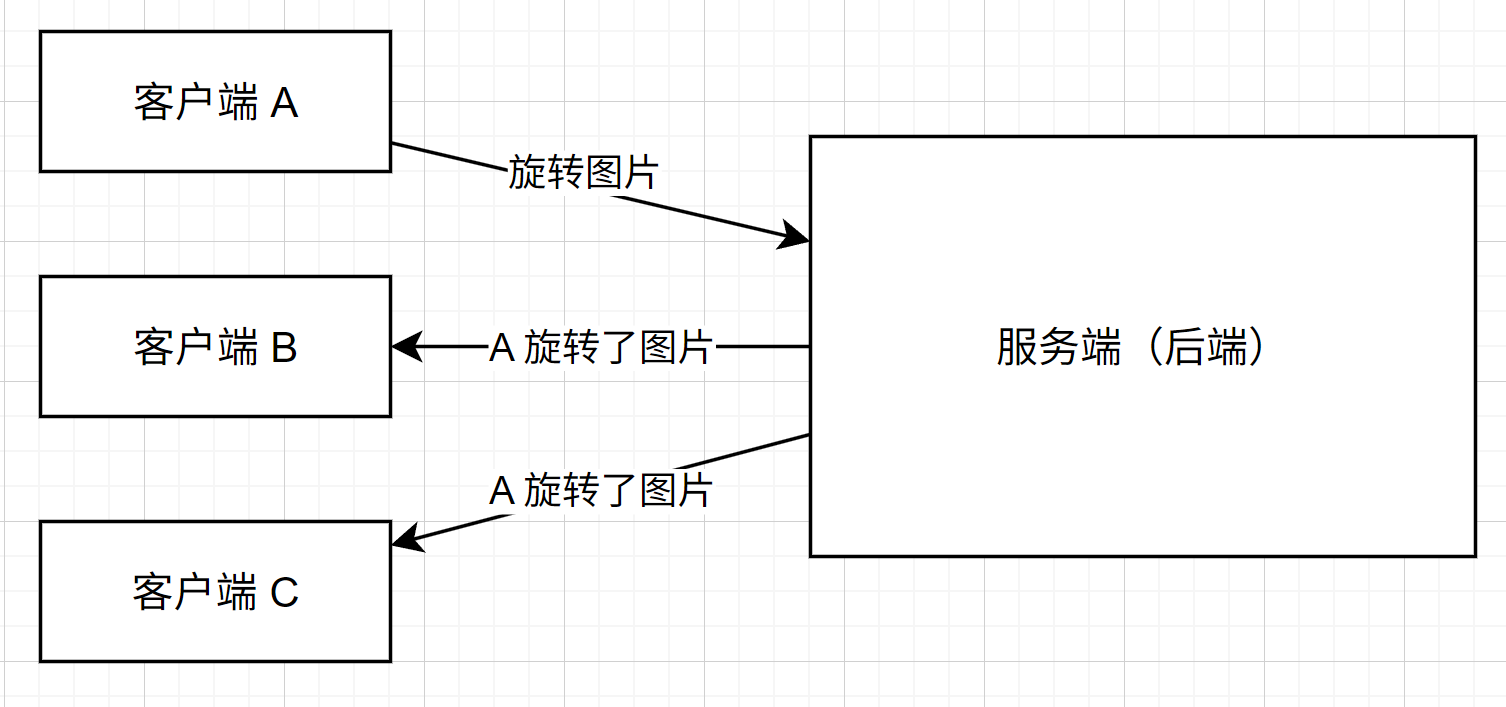
实时推送 (WebSocket)
为了达到实时的效果,选用WebSocket将正在编辑的信息即时推送给处于“协作编辑状态”的成员。
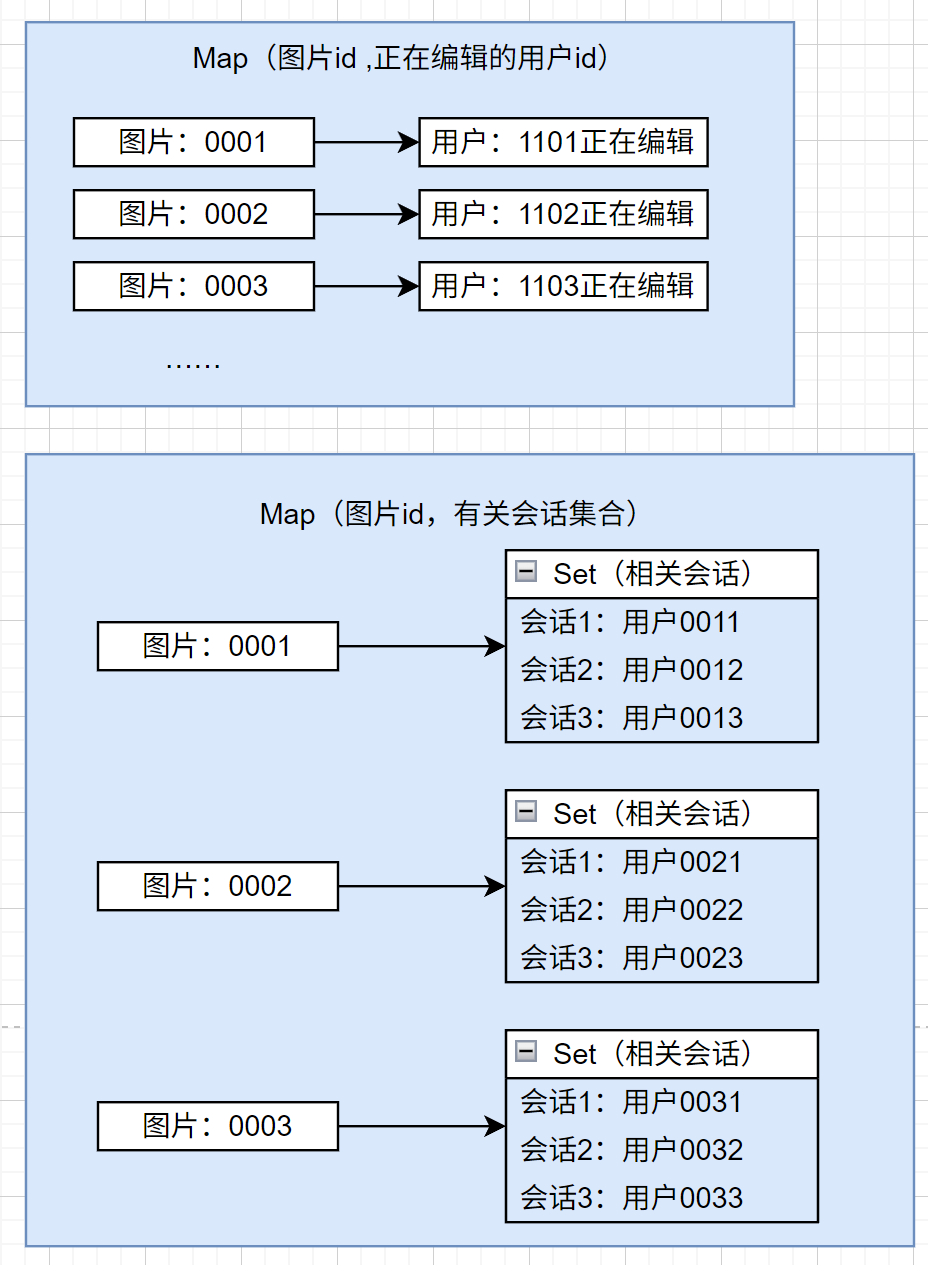
在后端,需要维护两个重要的表(Map):
- 图片->正在编辑的用户 映射表:用于实现统一时刻只有一个用户处于“正在编辑状态”
- 图片->相关会话集合 映射表:用户实现将某个成员的编辑动作推送给处于同图片协作编辑状态的成员。
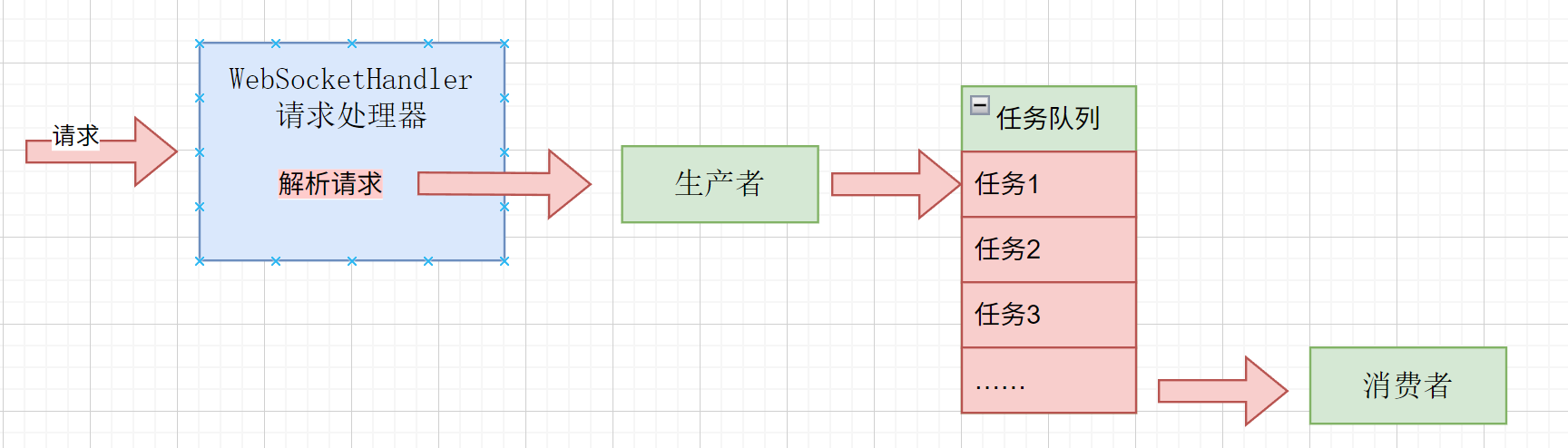
异步任务执行(任务队列Disruptor)
由于Spring WebSocket中,在处理消息的时候,对于同一个连接(同一个会话),这些消息的处理是按顺序串联处理。如果一个会话的某个请求,需要消耗大量时间,就会导致后面的连接堵塞。这些阻塞的连接也占用系统的资源,如系统的最大连接数。如果同时有很多会话,同时连续发送大量耗时请求,就会导致系统资源很快耗尽。
于是,把WebSocket接受到消息之后,要具体处理的任务放到一个任务队列里面。异步执行这些任务,从而尽快释放连接资源。