深入理解awk
深入理解 AWK:文本处理的强大工具
在 Linux 系统的文本处理工具中,AWK 以其强大的功能和灵活性占据着重要地位。它不仅能进行简单的文本过滤,还能实现复杂的格式化处理、数据统计等操作,是系统管理员和开发人员日常工作中的得力助手。本文将带您深入了解 AWK 的核心功能、使用方法及实际应用案例。
AWK 的基本流程
AWK 的处理流程主要分为三个部分,分别是 BEGIN 语句块、pattern 语句块和 END 语句块,其基本格式如下:
awk 'BEGIN{ commands } pattern{ commands } END{ commands }'
这三个部分的执行顺序和功能如下:
- 第一步:运行
BEGIN{ commands }语句块中的语句。该语句块在 AWK 开始从输入流中读取行之前被运行,常用于变量初始化、打印输出表格的表头等操作,是一个可选的语句块。 - 第二步:从文件或标准输入(stdin)读取一行,然后运行
pattern{ commands }语句块。它会逐行扫描文件,从第一行到最后一行反复这个过程,直到文件所有内容被读取完成。该语句块也是可选的,如果没有提供,则默认运行{ print },即打印每个读取到的行。 - 第三步:当读至输入流末尾时,运行
END{ commands }语句块。该语句块在 AWK 从输入流中读取完全部的行之后运行,常用于打印全部行的分析结果等信息汇总操作,同样是可选的语句块。
需要注意的是,这三个部分缺少任何一部分都是可以的,具体使用哪个部分取决于实际需求。
AWK 常用操作案例
基本匹配与统计
-
统计
/etc/passwd文件中以/bin/bash结尾的行数:[root@localhost ~]#awk 'BEGIN{x=0};/\/bin\/bash$/ {x++;print x,$0};END {print x}' /etc/passwd
该命令等同于
grep -c "/bin/bash$" /etc/passwd。在BEGIN模式中初始化变量x为 0,然后逐行扫描文件,当遇到以/bin/bash结尾的行时,变量x加 1 并打印相关信息,最后在END模式中打印统计的总行数。 -
输出
/etc/passwd文件中第 3 个字段的值不小于 200 的行:[root@localhost ~]#awk -F ":" '! ($3<200){print} ' /etc/passwd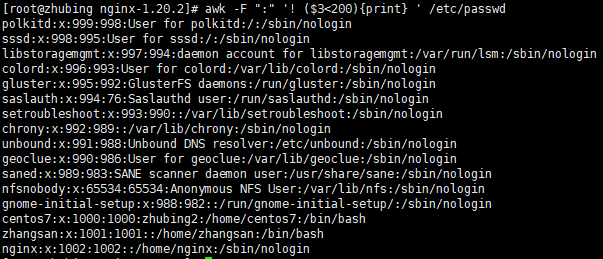
这里使用
-F ":"指定字段分隔符为冒号,! ($3<200)表示第 3 个字段的值不小于 200,然后打印满足条件的行。 -
先处理
BEGIN中的内容,再打印/etc/passwd文件中第 3 个字段的值大于等于 1000 的行:[root@localhost ~]#awk 'BEGIN {FS=":"} ;{if($3>=1000){print}}' /etc/passwd
在
BEGIN语句块中设置字段分隔符为冒号,然后使用if条件判断打印满足第 3 个字段的值大于等于 1000 的行。
行号与字段操作
-
输出
/etc/passwd文件中每行内容和行号:[root@localhost ~]#awk -F ":" '{print NR,$0}' /etc/passwd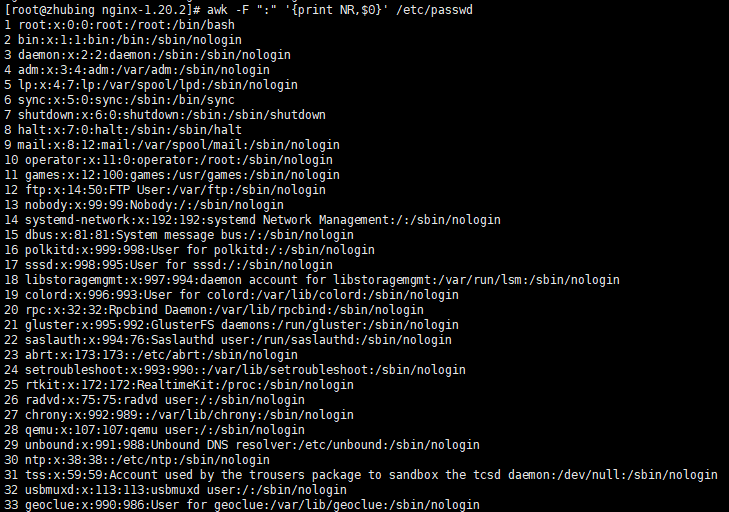
其中
NR表示当前处理的行的行号,每处理完一条记录,NR值加 1。该命令等同于sed -n '=;p' /etc/passwd。 -
输出
/etc/passwd文件中以冒号分隔且第 7 个字段中包含bash的行的第 1 个字段:[root@localhost ~]#awk -F ":" '$7~"bash"{print $1,47}' /etc/passwd
也可以使用
awk -F: '/bash/ {print $1}' /etc/passwd实现类似功能,$7~"bash"表示第 7 个字段包含bash字符串。 -
输出
/etc/passwd文件中第 1 个字段中包含root且有 7 个字段的行的第 1、2 个字段:[root@localhost ~]#awk -F":" '($1~"root") && (NF==7) {print $1,$2,$NF } ' /etc/passwd
NF表示当前行的字段总数,$NF表示最后一个字段。
多条件筛选
- 输出
/etc/passwd文件中第 7 个字段既不为/bin/bash,也不为/sbin/nologin的所有行:[root@localhost ~]#awk -F ":" '($7!="/bin/bash")&&($7!="/sbin/nologin"){print} ' /etc/passwd
与 Shell 命令结合
-
统计以冒号分隔的文本段落数(以
$PATH为例):[root@localhost ~]#echo $PATH | awk 'BEGIN{RS=":"};END {print NR}'RS表示记录分隔符,这里设置为冒号,NR在最后会表示分隔后的段落数。 -
调用
wc -l命令统计/etc/passwd文件中使用bash的用户个数:[root@localhost ~]#awk -F: '/bash$/{print | "wc -l"}' /etc/passwd
该命令等同于
grep -c "bash$" /etc/passwd或awk -F: '/bash$/ {print}' /etc/passwd | wc -l。
系统资源监控案例
-
查看当前内存使用百分比:
[root@localhost ~]#free -m |awk '/Mem:/ {print int($3/($3+$4)*100)"%"}'
先通过
free -m查看内存使用情况,然后使用 AWK 提取相关字段计算内存使用百分比,int函数用于取整数部分。 -
查看当前 CPU 空闲率:
[root@localhost ~]#top -b -n 1 | grep Cpu | awk -F ',' '{print $4}'| awk '{print $1}'
top -b -n 1表示只需要 1 次的输出结果,然后通过 AWK 提取 CPU 空闲率相关字段。 -
调用
w命令统计在线用户数:[root@localhost ~]# awk 'BEGIN {n=0 ; while ("w" | getline) n++ ; {print n-2}}'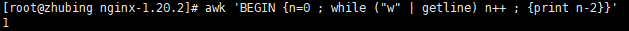
使用
getline从w命令的输出中读取内容并进行统计。 -
调用
hostname命令并输出当前的主机名:[root@localhost ~]#awk 'BEGIN { "hostname" | getline ; {print $0}}'
AWK 数组与循环
数组基本操作
AWK 数组的下标除了可以使用数字,也可以使用字符串,字符串需要使用双引号。例如:
[root@localhost ~]#awk 'BEGIN{a[0]=10;a[1]=20;print a[1]}'
[root@localhost ~]#awk 'BEGIN{a["abc"]=10;a["xyz"]=20;print a["abc"]}'
[root@localhost ~]#awk 'BEGIN{a["abc"]="aabbcc";a["xyz"]="xxyyzz";print a["xyz"]}'



结合数组和循环的案例
-
遍历数组并打印下标和对应的值:
[root@localhost ~]# awk 'BEGIN{a[0]=10;a[1]=20;a[2]=30;for(i in a){print i,a[i]}}'
-
统计
httpd访问日志中每个客户端 IP 的出现次数:[root@localhost ~]# awk '{a[$1]+=1;} END {for(i in a){print a[i]" "i;}}' /var/log/httpd/access_log | sort -r定义数组
a,数组的下标为日志文件的第 1 列(即客户端的 IP 地址),a[$1]+=1表示对客户端进行统计计数,客户端 IP 出现一次计数器就加 1。END中的指令在读取完文件后执行,通过循环将所有统计信息输出并按出现次数降序排序。 -
统计
/var/log/secure文件中登录失败的 IP 及其次数:[root@localhost ~]# awk '/Failed password/{ip[$11]++}END{for(i in ip){print i","ip[i]}}' /var/log/secure
生产脚本编写示例
以下是一个根据登录失败次数进行警告的脚本:
#!/bin/ bash
x=`awk '/Failed password/{ip[$11]++}END{for(i in ip){print i","ip[i]}}' /var/log/secure`
#190.168.10.22 3
for j in $x
do
ip=`echo $j | awk -F "," '{print $1}'`
num=`echo $j | awk -F "," '{print $2}'`
if [ $num -ge 3 ];then
echo "警告! $ip访问本机失败了$num次,请速速处理!"
fi
done
该脚本先通过 AWK 统计 /var/log/secure 文件中登录失败的 IP 及其次数,然后遍历统计结果,当失败次数大于等于 3 时,输出警告信息。
提取版本号案例
对于以下文件内容,提取版本号:
ant-1.9.7.jar
ant-launcher-1.9.7.jar
antlr-2.7.7.jar
antlr-runtime-3.4.jar
aopalliance-1.0.jar
archaius-core-0.7.6.jar
asm-5.0.4.jar
aspectjweaver-1.9.5.jar
bcpkix-jdk15on-1.64.jar
bcprov-jdk15-1.46.jar
bcprov-jdk15on-1.64.jar
checker-compat-qual-2.5.5.jar
可以使用以下命令:
[root@localhost /]#cat 1.txt |sed -r 's/.*-(.*)\.jar/\1/'
该命令使用 sed 命令的正则替换功能,提取出 .jar 文件名中 - 后面的版本号部分。
总结
- grep 和 egrep:更适合单纯的查找或匹配文本。
- sed:流编辑器,更适合编辑匹配到的文本。
- awk:文本报告生成器,更适合格式化文本,对文本进行较复杂格式处理。
通过本文的介绍,相信您对 AWK 有了更深入的了解。在实际工作中,灵活运用 AWK 的各种功能,可以大大提高文本处理的效率。希望这些内容能帮助您更好地掌握 AWK 这一强大的工具。