【C++】16. set和map
文章目录
- 一、序列式容器和关联式容器
- 二、set系列的使⽤
- 1、set和multiset参考⽂档
- 2、set类的介绍
- 3、set对象的常用接口
- 1)constructor
- 2)Iterators
- 3)Modifiers
- 4)Operations
- 4、multiset和set的差异
- 5、练习
- 1)两个数组的交集
- 2)环形链表II
- 三、map系列的使⽤
- 1、map和multimap参考⽂档
- 2、map类的介绍
- 3、pair类型介绍
- 4、map对象的常用接口
- 1)constructor
- 2)Iterators
- 3)Modifiers
- 4)Operations
- 5、key/value场景的再实现
- 6、multimap和map的差异
- 7、练习
- 1)随机链表的复制
- 2)前K个⾼频单词
一、序列式容器和关联式容器
前⾯我们已经接触过STL中的部分容器如:string、vector、list、deque、array、forward_list等,这些容器统称为序列式容器,因为逻辑结构为线性序列的数据结构,两个位置存储的值之间⼀般没有紧密的关联关系,⽐如交换⼀下,他依旧是序列式容器。顺序容器中的元素是按他们在容器中的存储位置来顺序保存和访问的。
关联式容器也是⽤来存储数据的,与序列式容器不同的是,关联式容器逻辑结构通常是⾮线性结构,两个位置有紧密的关联关系,交换⼀下,他的存储结构就被破坏了。顺序容器中的元素是按关键字来保存和访问的。关联式容器有map/set系列和unordered_map/unordered_set系列。
本篇文章讲解的map和set底层是红⿊树,红⿊树是⼀颗平衡⼆叉搜索树。set是key搜索场景的结构,map是key/value搜索场景的结构。
二、set系列的使⽤
1、set和multiset参考⽂档
set和multiset参考⽂档
2、set类的介绍
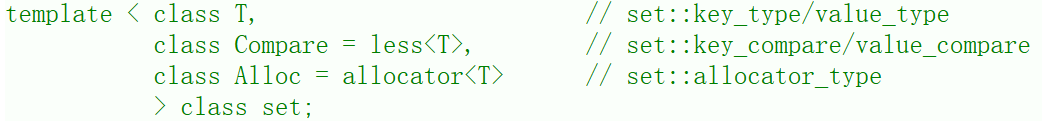
-
T就是set底层关键字的类型。
-
set默认要求T⽀持⼩于⽐较,如果不⽀持或者想按⾃⼰的需求⾛可以⾃⾏实现仿函数传给第⼆个模版参数。
-
set底层存储数据的内存是从空间配置器申请的,如果需要可以⾃⼰实现内存池,传给第三个参数。
-
⼀般情况下,我们都不需要传后两个模版参数。
-
set底层是⽤红⿊树实现,增删查效率是O(logN) ,迭代器遍历是⾛的搜索树的中序,所以是有序的。
3、set对象的常用接口
1)constructor
| (construtor)构造函数 | 接口说明 |
|---|---|
| explicit set (const key_compare& comp = key_compare()) | ⽆参默认构造 |
| template set (InputIterator first, InputIterator last,const key_compare& comp = key_compare()) | 迭代器区间构造 |
| set (const set& x) | 拷贝构造 |
| set (initializer_list<value_type> il, const key_compare& comp = key_compare()) | 列表初始化构造(C++11以后支持) |
| set& operator= (const set& x); | 赋值重载 |
示例如下:
#include<iostream>
#include<set>
using namespace std;int main()
{//默认去重+升序排序set<int> s;//默认构造//set<int, greater<int>> s;//降序set<int> s1{ 2,4,3,1,5 };//初始化列表构造set<int> s2(s1.begin(), s1.end());//迭代器区间构造set<int> s3(s1);//拷贝构造s = s1;//赋值return 0;
}
调试观察:
2)Iterators
| 函数声明 | 接口说明 |
|---|---|
| begin + end | 返回指向起始位置的迭代器+返回指向末尾的迭代器 |
| rbegin+ rend | 返回指向反向起始位置的反向迭代器 +返回指向反向末尾的反向迭代器 |
示例如下:
#include<iostream>
#include<set>
using namespace std;int main()
{set<int> s{ 2,4,3,1,5 };//正向遍历set<int>::iterator it = s.begin();while (it != s.end()){cout << *it << " ";++it;}cout << endl;//反向遍历set<int>::reverse_iterator rit = s.rbegin();while (rit != s.rend()){cout << *rit << " ";++rit;}cout << endl;//范围forfor (auto e : s){cout << e << " ";}cout << endl;return 0;
}
运行结果:

注意: set⽀持正向和反向迭代遍历,遍历默认按升序顺序,因为底层是⼆叉搜索树,迭代器遍历⾛的中序;⽀持迭代器就意味着⽀持范围for,set的iterator和const_iterator都不⽀持迭代器修改数据,修改关键字数据,破坏了底层搜索树的结构。
3)Modifiers
| 函数声明 | 接口说明 |
|---|---|
| insert | 插入元素 |
| erase | 删除元素 |
示例如下:
#include<iostream>
#include<set>
using namespace std;int main()
{set<int> s;s.insert(2);//直接插入s.insert(2);s.insert(3);s.insert(1);s.insert(5);for (auto e : s){cout << e << " ";}cout << endl;s.insert(s.begin(), 10);//迭代器位置插入for (auto e : s){cout << e << " ";}cout << endl;set<int> s1{ 6,7,8,9 };s.insert(s1.begin(), s1.end());//迭代区间插入for (auto e : s){cout << e << " ";}cout << endl;s.insert({ 20,30,40 });//初始化列表插入for (auto e : s){cout << e << " ";}cout << endl;//直接删除xint x;cin >> x;int num = s.erase(x);if (num == 0){cout << x << "不存在" << endl;}for (auto e : s){cout << e << " ";}cout << endl;//直接查找再利用迭代器删除xcin >> x;auto pos = s.find(x);if (pos != s.end()){s.erase(pos);}else{cout << x << "不存在" << endl;}for (auto e : s){cout << e << " ";}cout << endl;return 0;
}
运行结果:

4)Operations
| 函数声明 | 接口说明 |
|---|---|
| find | 获取指向元素的迭代器 |
| count | 统计具有特定值的元素数量 |
| lower_bound | 返回大于等于val位置的迭代器 |
| upper_bound | 返回大于val位置的迭代器 |
示例如下:
#include<iostream>
#include<set>
using namespace std;int main()
{set<int> s{ 2,3,1,5,4 };for (auto e : s){cout << e << " ";}cout << endl;int x;cin >> x;//算法库的查找 O(N)auto pos1 = find(s.begin(), s.end(), x);//set自身实现的查找 O(logN) 效率相当之快auto pos2 = s.find(x);//利用cout间接实现快速查找if (s.count(x)){cout << x << "存在" << endl;}else{cout << x << "不存在" << endl;}cout << endl;set<int> s1;for (int i = 1; i < 10; i++){s1.insert(i * 10);}for (auto e : s1){cout << e << " ";}cout << endl;//[25,55]set<int>::iterator itlow = s1.lower_bound(25);//返回>=25set<int>::iterator itup = s1.upper_bound(55);//返回>55//删除这段区间的值s1.erase(itlow, itup);for (auto e : s1){cout << e << " ";}cout << endl;return 0;
}
运行结果:

4、multiset和set的差异
multiset和set的使⽤基本完全类似,主要区别点在于multiset⽀持值冗余,那么
insert/find/count/erase都围绕着值冗余有所差异。
示例如下:
#include<iostream>
#include<set>
using namespace std;int main()
{//相⽐set不同的是,multiset是排序,但是不去重multiset<int> s = { 2,2,2,5,1,3 };for (auto e : s){cout << e << " ";}cout << endl;//相⽐set不同的是,x可能会存在多个,find查找中序的第⼀个int x;cout << "输入x:";cin >> x;auto pos = s.find(x);while (pos != s.end() && *pos == x){cout << *pos << " ";++pos;}cout << endl;//相⽐set不同的是,count会返回x的实际个数cout << s.count(x) << endl;//相⽐set不同的是,erase时会删除所有的x s.erase(x);for (auto e : s){cout << e << " ";}cout << endl;return 0;
}
5、练习
1)两个数组的交集
两个数组的交集
题目:

分析:
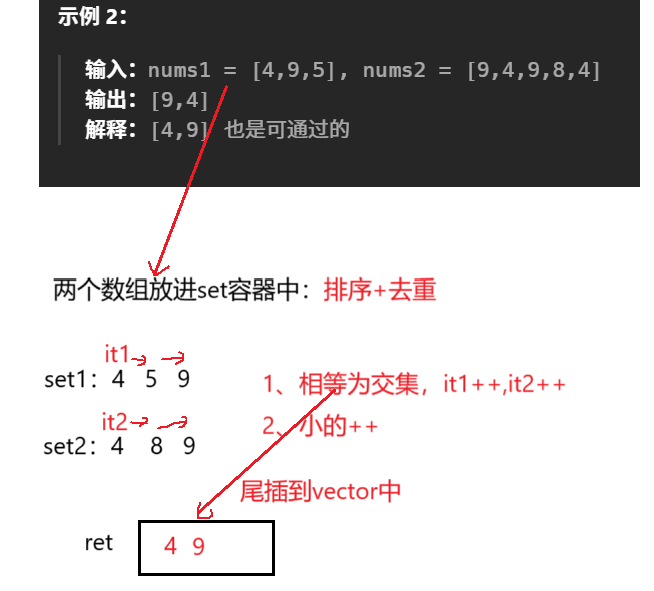
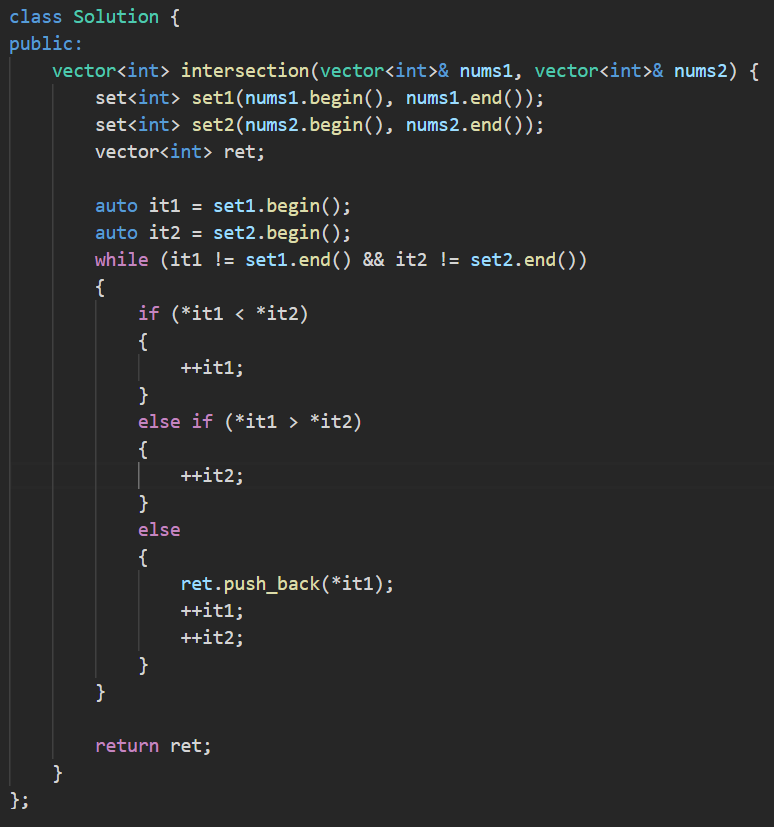
解析:
2)环形链表II
环形链表II
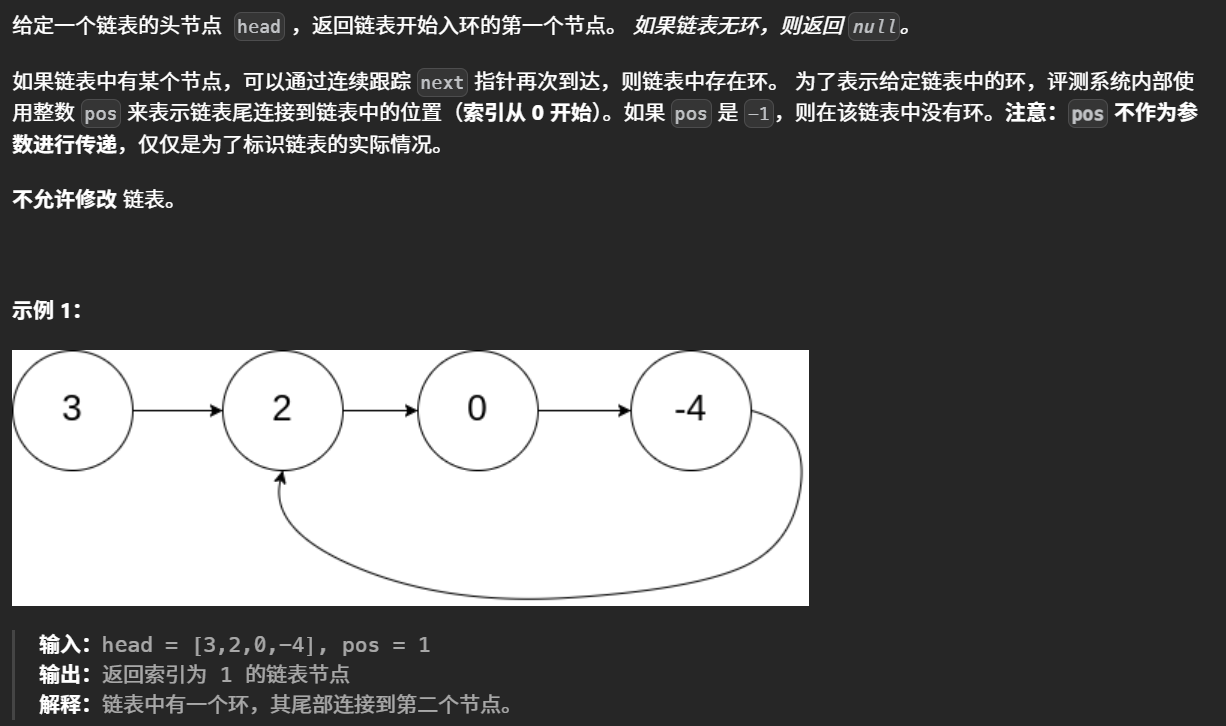
分析:
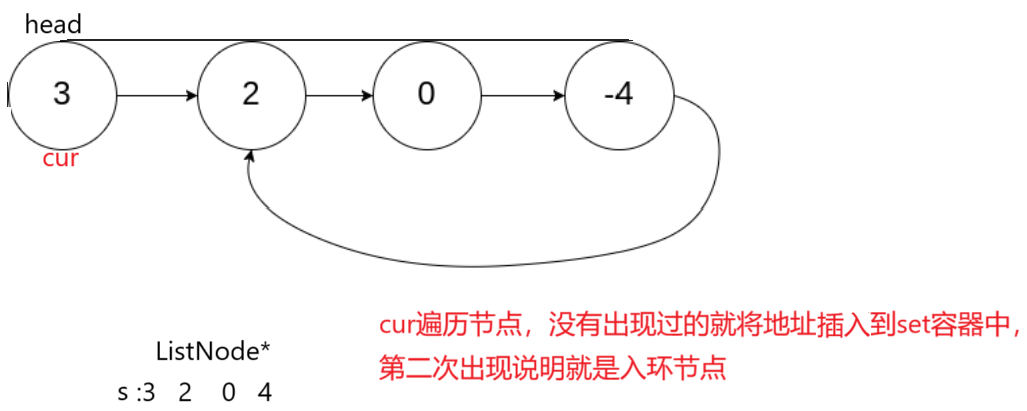
解析:
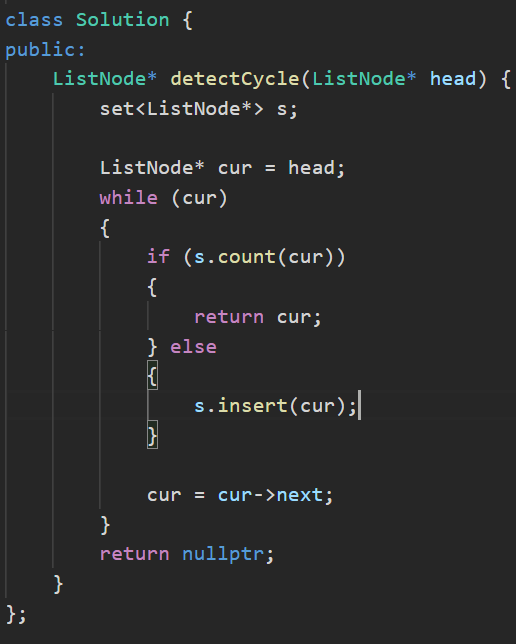
三、map系列的使⽤
1、map和multimap参考⽂档
map和multimap参考⽂档
2、map类的介绍

-
map的声明如下,Key就是map底层关键字的类型,T是map底层value的类型,
-
set默认要求Key⽀持⼩于⽐较,如果不⽀持或者需要的话可以⾃⾏实现仿函数传给第⼆个模版参数,
-
map底层存储数据的内存是从空间配置器申请的。
-
⼀般情况下,我们都不需要传后两个模版参数。
-
map底层是⽤红⿊树实现,增删查改效率是O(logN) ,迭代器遍历是⾛的中序,所以是按key有序顺序遍历的。
3、pair类型介绍
map底层的红⿊树节点中的数据,使⽤pair<Key, T>存储键值对数据。
typedef pair<const Key, T> value_type;
template<class T1,class T2>
struct pair
{typedef T1 first_type;typedef T2 second_type;T1 first;T2 second;
};
示例如下:
#include<iostream>
#include<utility>
using namespace std;int main()
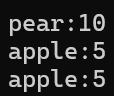
{pair<string, int> p1;pair<string, int> p2("apple", 5);pair<string, int> p3(p2);p1 = make_pair("pear", 10);p3 = p2;cout << p1.first << ":" << p1.second << endl;cout << p2.first << ":" << p2.second << endl;cout << p3.first << ":" << p3.second << endl;return 0;
}
运行结果:
4、map对象的常用接口
1)constructor
map对象的构造与set对象类似,都支持无参默认构造、迭代器区间构造、拷贝构造
初始化列表构造以及赋值重载。
示例如下:
#include<iostream>
#include<map>
using namespace std;int main()
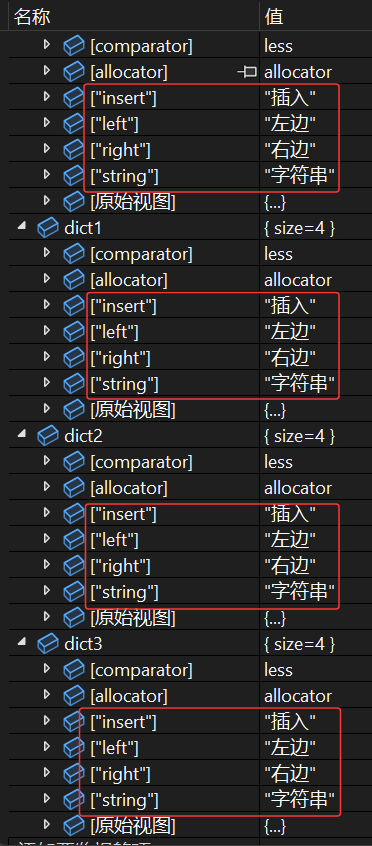
{//默认去重+升序排序(根据key的大小来排序)map<string, string> dict;//无参默认构造map<string, string> dict1 = { {"left","左边"}, {"right", "右边"}, {"insert", "插入"},{ "string", "字符串" } };//初始化列表构造map<string, string> dict2(dict1);//拷贝构造map<string, string> dict3(dict1.begin(), dict1.end());//迭代器区间构造dict = dict1;//赋值重载return 0;
}
调试观察:
2)Iterators
| 函数声明 | 接口说明 |
|---|---|
| begin + end | 返回指向起始位置的迭代器+返回指向末尾的迭代器 |
| rbegin+ rend | 返回指向反向起始位置的反向迭代器 +返回指向反向末尾的反向迭代器 |
示例如下:
#include<iostream>
#include<map>
using namespace std;int main()
{map<string, string> dict = { {"left","左边"}, {"right", "右边"}, {"insert", "插入"},{ "string", "字符串" } };//正向遍历map<string, string>::iterator it = dict.begin();while (it != dict.end()){cout << (*it).first << ":" << (*it).second << endl;++it;}cout << endl;//范围forfor (auto e : dict){cout << e.first << ":" << e.second << endl;}return 0;
}
运行结果:

注意: map⽀持正向和反向迭代遍历,遍历默认按key的升序顺序,因为底层是⼆叉搜索树,迭代器遍历⾛的中序;⽀持迭代器就意味着⽀持范围for,map⽀持修改value数据,不⽀持修改key数据,修改关键字数据,破坏了底层搜索树的结构。
3)Modifiers
| 函数声明 | 接口说明 |
|---|---|
| insert | 插入元素 |
| erase | 删除元素 |
| operator[] | 访问元素 |
#include<iostream>
#include<map>
using namespace std;int main()
{//insertmap<string, string> dict;pair<string, string> kv1("first", "第一个");dict.insert(kv1);//插入显示pair对象dict.insert(pair<string, string>("second", "第二个"));//插入匿名pair对象dict.insert(make_pair("sort", "排序"));//插入make_pair函数//C++11:初始化列表dict.insert({ "auto", "自动的" });//注:插入相等key,value不会更新dict.insert({ "auto","自动的xxxx" });//可以修改value,不支持修改keymap<string, string>::iterator it = dict.begin();//it->first += 'y'; //errit->second += 'y';while(it!=dict.end()){cout << it->first << ":" << it->second << endl;++it;}cout << endl;//erasedict.erase("sort");//直接删除keydict.erase(dict.begin());//删除迭代器位置的keyfor (auto e : dict){cout << e.first << ":" << e.second << endl;}//[]map<string, string> dict1;dict1.insert({ "sort","排序" });dict1["insert"];//key不存在->插入dict1["left"] = "左边";//key不存在->插入+修改dict1["left"] = "左边xxx";//key存在->修改//查找时如果key不存在,那么就会变成插入cout << dict1["right"] << endl;for (auto e : dict1){cout << e.first << ":" << e.second << endl;}return 0;
}
运行结果:

知识点补充:
insert插⼊⼀个pair<key, T>对象
1、如果key已经在map中,插⼊失败,则返回⼀个pair<iterator,bool>对象, first是key所在结点的迭代器,second是false 。
2、如果key不在在map中,插⼊成功,则返回⼀个pair<iterator,bool>对象,first是新插⼊key所在结点的迭代器,second是true。
也就是说⽆论插⼊成功还是失败,返回pair<iterator,bool>对象的first都会指向key所在的迭代器,那么也就意味着insert插⼊失败时充当了查找的功能,正是因为这⼀点,insert可以⽤来实现operator[]。
需要注意的是这⾥有两个pair,不要混淆了,⼀个是map底层红⿊树节点中存的pair<key, T>,另⼀个是insert返回值。
//operator的内部实现
mapped_type& operator[] (const key_type& k)
{
//1、如果k不在map中,insert会插⼊k和mapped_type默认值,同时[]返回结点中存储mapped_type值的引⽤,那么我们可以通过引⽤修改返映射值,所以[]具备了插⼊ + 修改功能。
//2、如果k在map中,insert会插⼊失败,但是insert返回pair对象的first是指向key结点的迭代器,返回值同时[]返回结点中存储mapped_type值的引⽤,所以[]具备了查找 + 修改的功能。
pair<iterator, bool> ret = insert({ k, mapped_type() });
iterator it = ret.first;
return it->second;
}
4)Operations
| 函数声明 | 接口说明 |
|---|---|
| find | 获取指向元素的迭代器 |
| count | 统计具有特定值的元素数量 |
| lower_bound | 返回大于等于val位置的迭代器 |
| upper_bound | 返回大于val位置的迭代器 |
示例如下:
#include<iostream>
#include<map>
using namespace std;int main()
{map<char, int> dict;dict['a'] = 5;dict['b'] = 10;dict['c'] = 15;dict['d'] = 20;map<char, int>::iterator it = dict.find('a');//findcout << it->first << ":" << it->second << endl;cout << dict.count('b') << endl;//countcout << endl;//['a','b']map<char, int>::iterator low = dict.lower_bound('a');//>='a'map<char, int>::iterator up = dict.upper_bound('b');//>'b'dict.erase(low, up);//删除['a','b']区间for (auto e : dict){cout << e.first << ":" << e.second << endl;}return 0;
}
运行结果:
5、key/value场景的再实现
在前一篇文章中,我们通过自己模拟实现的key/value结构完成了对水果出现次数的统计,学习了map之后,就可以使用map的各种接口来实现了。
#include<iostream>
#include<map>
using namespace std;void test1()
{string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜","苹果", "香蕉", "苹果", "香蕉" };map<string, int> countMap;//先查找⽔果在不在map中//1、不在,说明⽔果第⼀次出现,则插⼊{⽔果, 1}//2、在,则查找到的节点中⽔果对应的次数++for (const auto& str : arr){map<string, int>::iterator ret = countMap.find(str);if (ret == countMap.end()){countMap.insert({ str,1 });}else{ret->second++;}}for (const auto& e : countMap){cout << e.first << ":" << e.second << endl;}
}void test2()
{string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜","苹果", "香蕉", "苹果", "香蕉" };map<string, int> countMap;// []先查找⽔果在不在map中// 1、不在,说明⽔果第⼀次出现,则插⼊{⽔果, 0},同时返回次数的引用,++一下就变成1次了// 2、在,则返回⽔果对应的次数++for (const auto& str : arr){countMap[str]++;//插入+修改}for (const auto& e : countMap){cout << e.first << ":" << e.second << endl;}
}
运行结果:

可以看到上面两种方式都可以实现。
6、multimap和map的差异
multimap和map的使⽤基本完全类似,主要区别点在于multimap⽀持关键值key冗余,那么insert/find/count/erase都围绕着⽀持关键值key冗余有所差异,这⾥跟set和multiset完全⼀样,⽐如find时,有多个key,返回中序第⼀个。其次就是multimap不⽀持[ ],因为⽀持key冗余,[ ]就只能⽀持插⼊了,不能⽀持修改。
7、练习
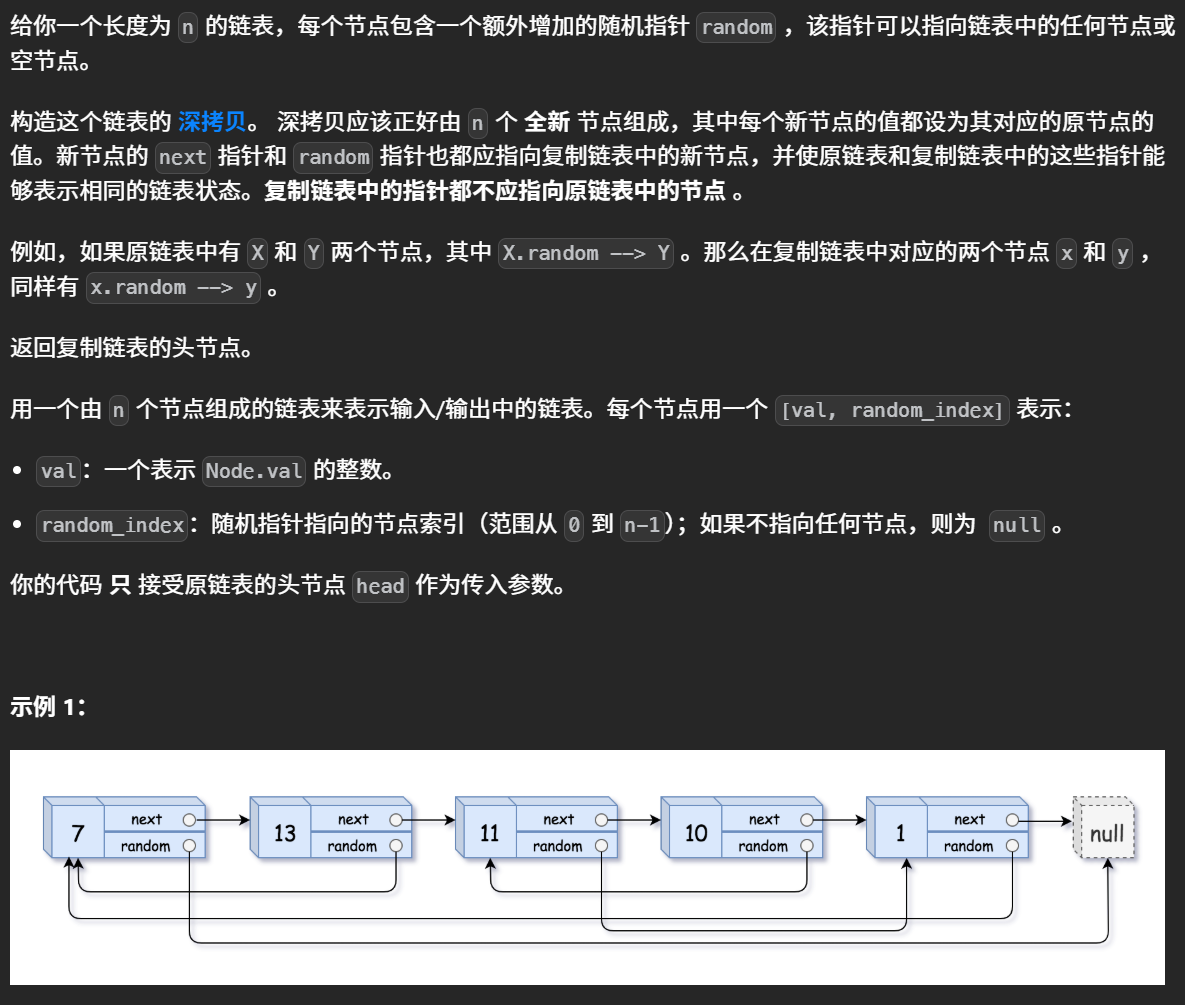
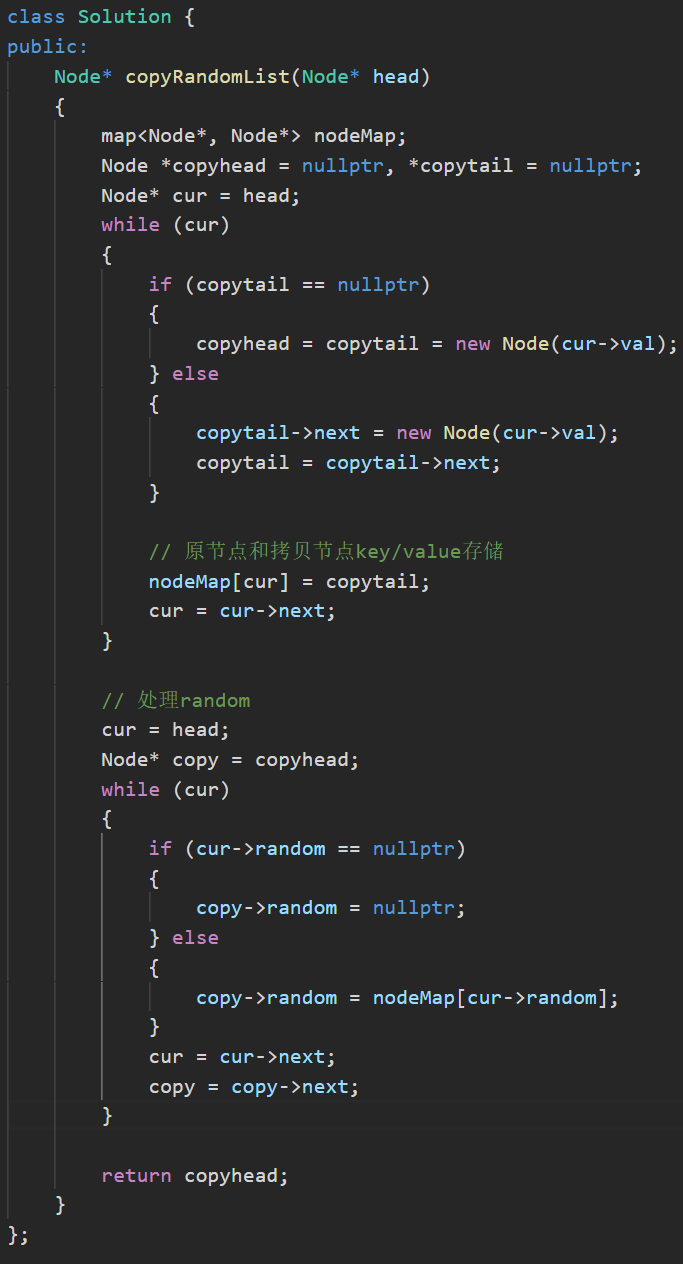
1)随机链表的复制
随机链表的复制
题目:
解析:
2)前K个⾼频单词
前K个⾼频单词
题目:

分析:本题⽬我们利⽤map统计出次数以后,返回的答案应该按单词出现频率由⾼到低排序,有⼀个特殊要求,如果不同的单词有相同出现频率,按字典顺序排序。
思路1:
⽤排序找前k个单词,因为map中已经对key单词排序过,也就意味着遍历map时,次数相同的单词,字典序⼩的在前⾯,字典序⼤的在后⾯。那么我们将数据放到vector中⽤⼀个稳定的排序就可以实现上⾯特殊要求,但是sort底层是快排,是不稳定的,所以我们要⽤stable_sort,他是稳定的。

解析:
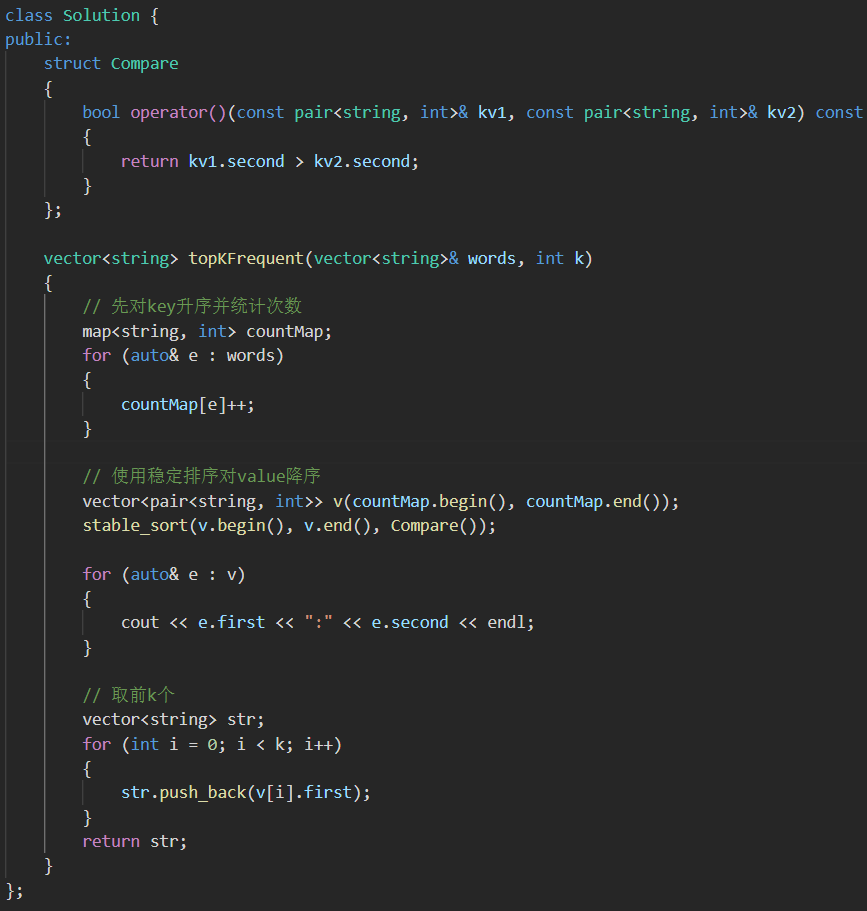
思路2:
将map统计出的次数的数据放到vector中排序,或者放到priority_queue中来选出前k个。利⽤仿函数强⾏控制次数相等的,字典序⼩的在前⾯。
class Solution {
public:struct Compare{bool operator()(const pair<string, int>& kv1, const pair<string, int>& kv2) const{return kv1.second > kv2.second || (kv1.second == kv2.second && kv1.first < kv2.first);}};vector<string> topKFrequent(vector<string>& words, int k) {// 先对key升序并统计次数map<string, int> countMap;for (auto& e : words){countMap[e]++;}// 对value降序(仿函数控制次数相等,字典序小的在前面 )vector<pair<string, int>> v(countMap.begin(), countMap.end());sort(v.begin(), v.end(), Compare());// 取前k个vector<string> str;for (int i = 0; i < k; i++){str.push_back(v[i].first);}return str;}
};
class Solution {
public:struct Compare {// 要注意优先级队列底层是反的,大堆要实现小于比较,// 所以这里次数相等,想要字典序小的在前面要比较字典序大的为真bool operator()(const pair<string, int>& kv1,const pair<string, int>& kv2) const {return kv1.second < kv2.second ||(kv1.second == kv2.second && kv1.first > kv2.first);}};vector<string> topKFrequent(vector<string>& words, int k) {// 先对key升序并统计次数map<string, int> countMap;for (auto& e : words) {countMap[e]++;}// 将map中的<单词,次数>放到priority_queue中,仿函数控制大堆,次数相同按照字典序规则排序priority_queue<pair<string, int>, vector<pair<string, int>>, Compare> p(countMap.begin(), countMap.end());// 取前k个vector<string> str;for (int i = 0; i < k; i++) {str.push_back(p.top().first);p.pop();}return str;}
};