HDFS机架感知、副本存放机制详解(附源码地址)
HDFS机架感知、副本存放机制详解(附源码地址)

HDFS副本机制是Hadoop分布式文件系统的核心高可用设计,通过多副本策略同时保障数据可靠性和访问性能。
HDFS 写副本时,会把副本放在不同机架,防止单机架故障导致数据丢失。
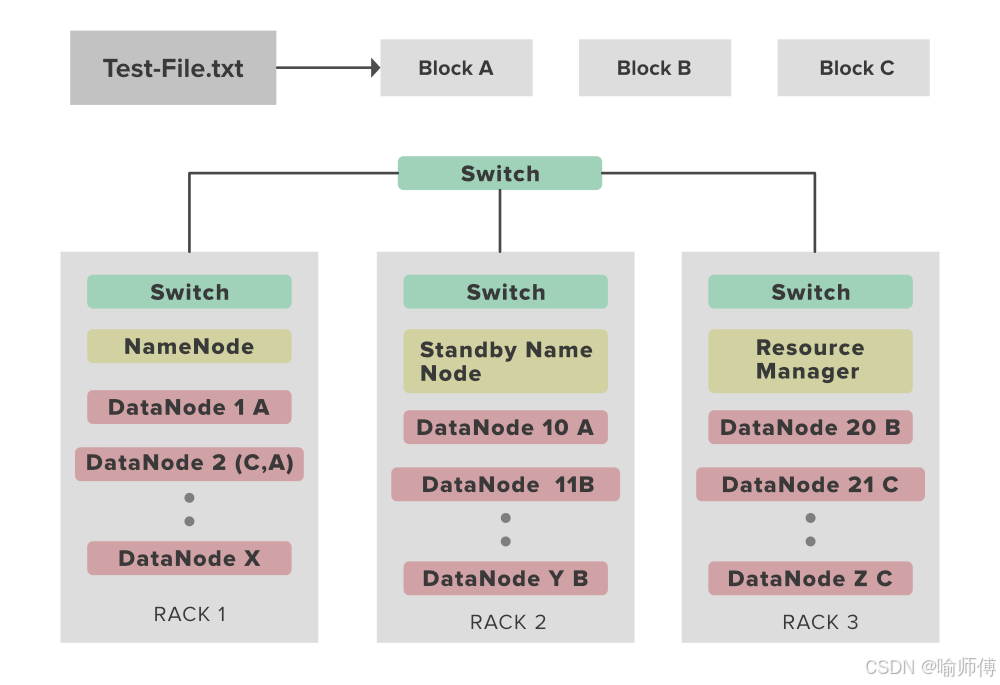
但你是否曾思考过这样一个问题: 当 HDFS 写入一个文件时,它的副本,究竟是如何决定“放哪”的?
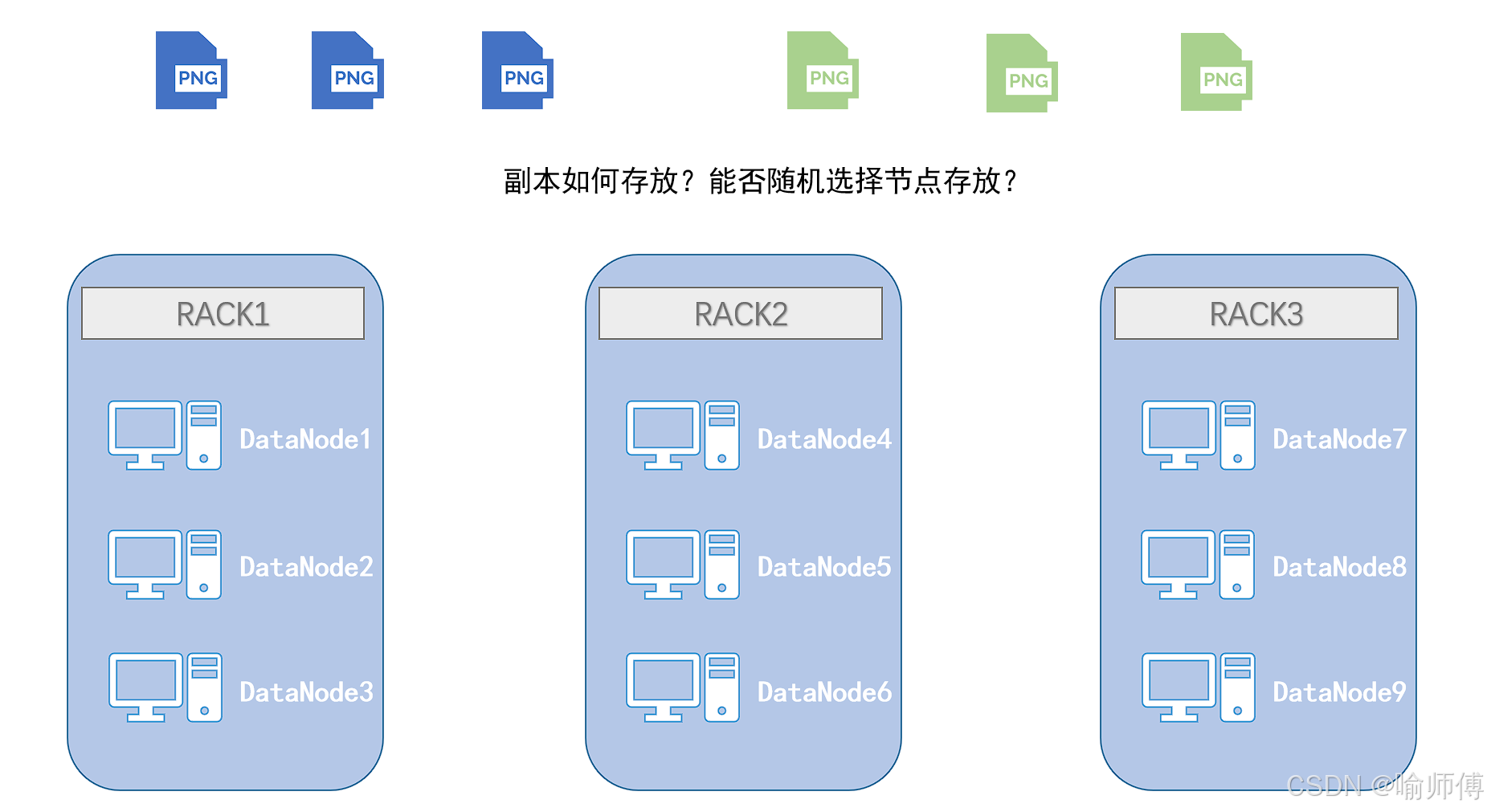
朴素设计:将副本随机放在不同节点。但这可能导致“多个副本位于同一机架”——若机架故障,副本全部丢失,显然无法实现HDFS“高可用”的目标。
HDFS的机架感知、副本存放机制很好的解决了这一问题。
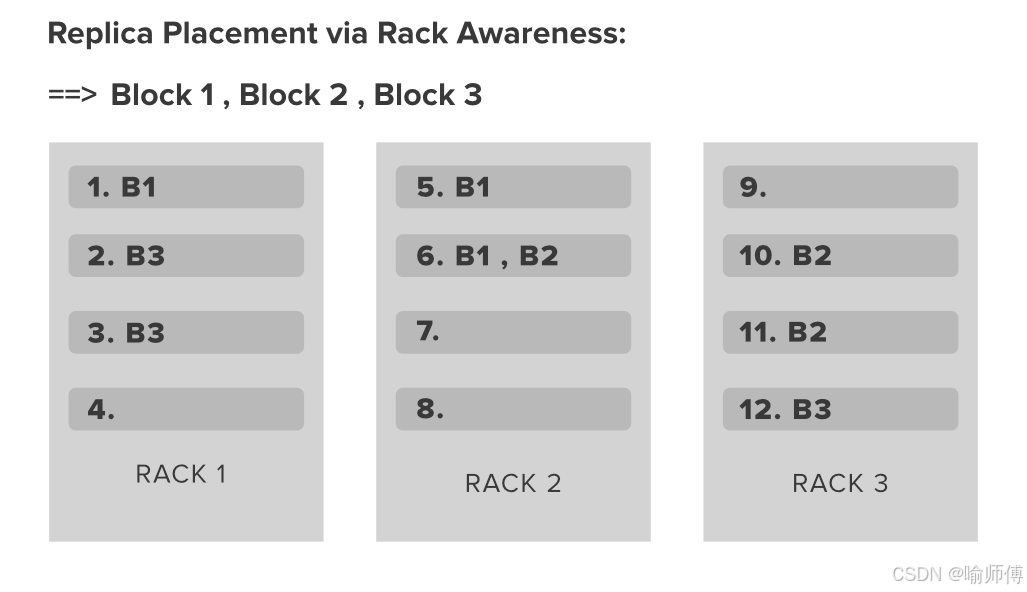
HDFS 默认采用 3 副本机制 来保证数据的高可用与容错性,核心原则是:本地优先、跨机架容错、同机架均衡。
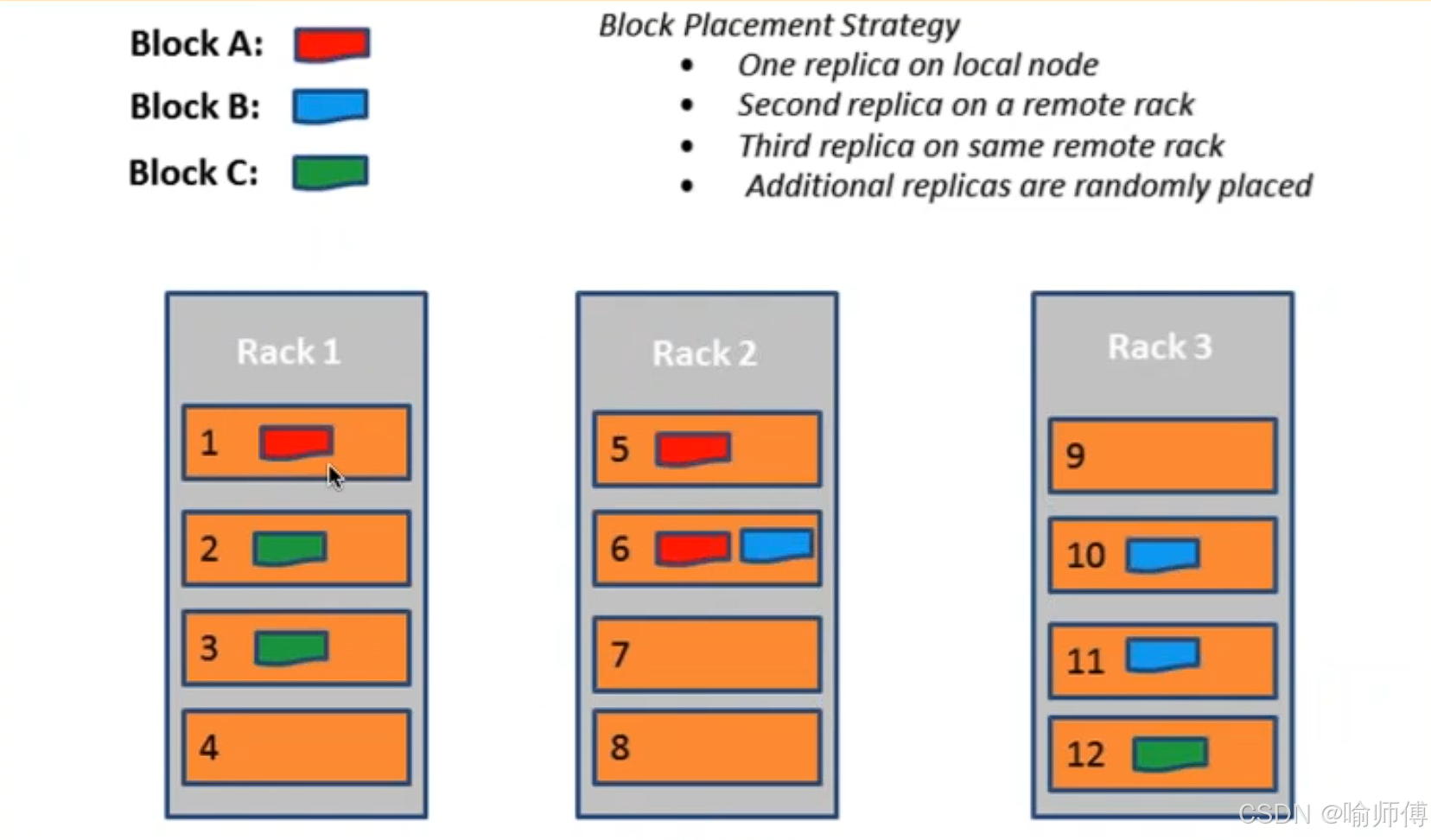
- 第一个副本:优先存放在上传文件的客户端所在节点(若客户端为集群内的 DataNode);若客户端在集群外,则随机选择一个节点。
- 第二个副本:放置在与第一个副本不同机架的节点上,实现跨机架容错,防止单机架故障导致数据丢失。
- 第三个副本:放置在与第二个副本同一机架但不同节点上,在保证容错的同时,提升写入效率并支持机架内数据冗余。
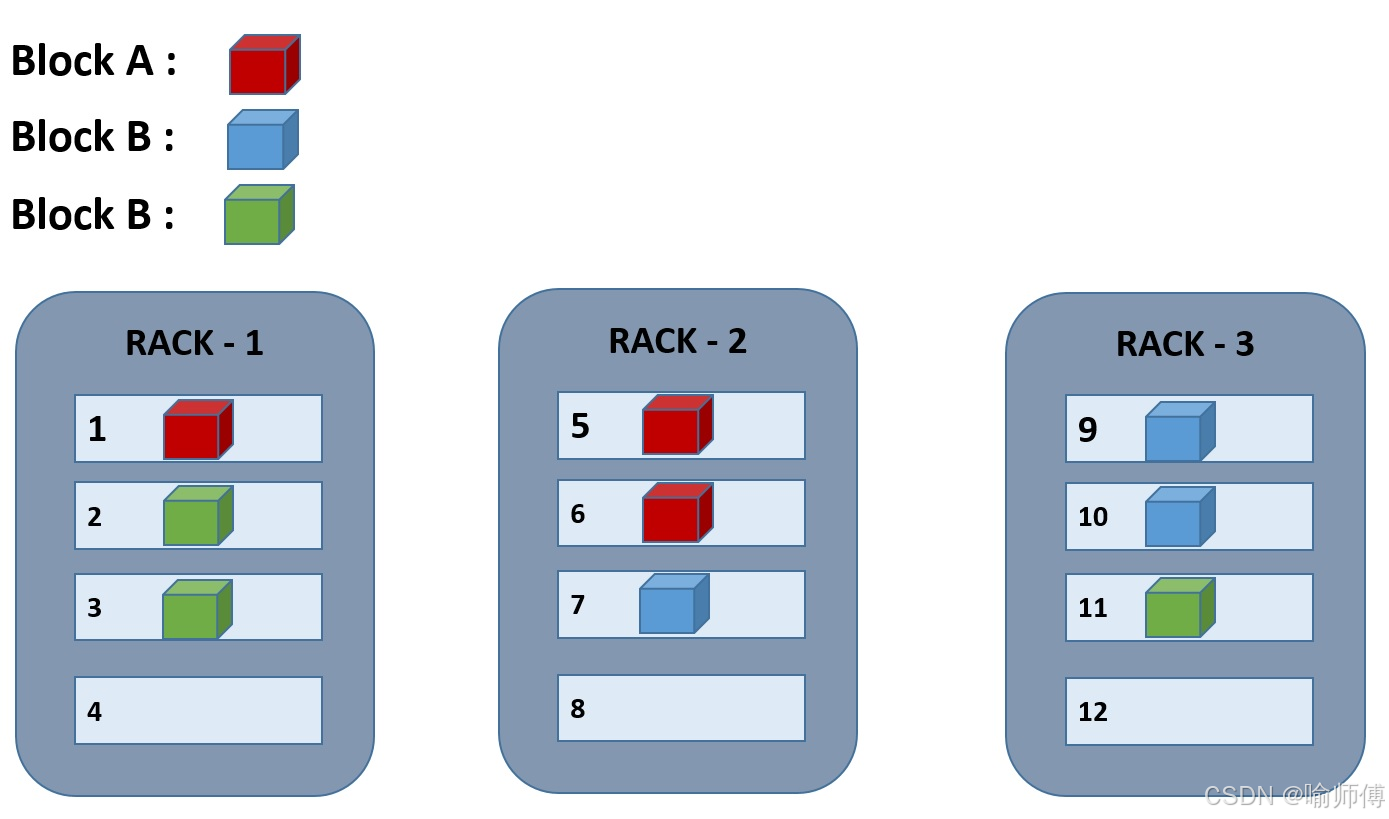
对于更多副本(如配置了超过 3 副本),HDFS 会继续在其他机架或节点上随机分布(遵循机架负载均衡原则,并不是完全随机)。
副本策略默认由 BlockPlacementPolicyDefault 类实现:
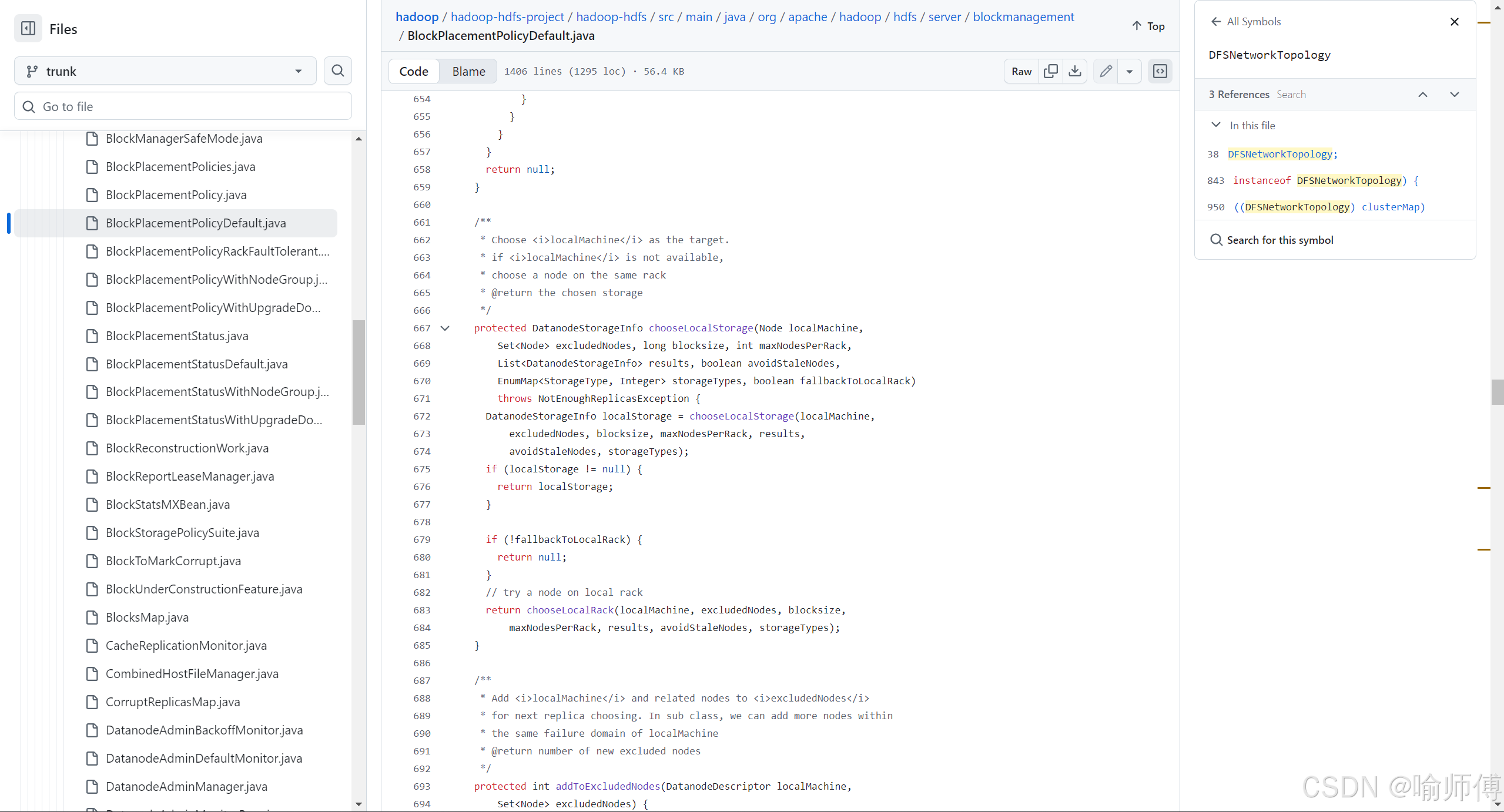
可以看一下源码中BlockPlacementPolicyDefault类的核心方法 —chooseTargetInOrder()
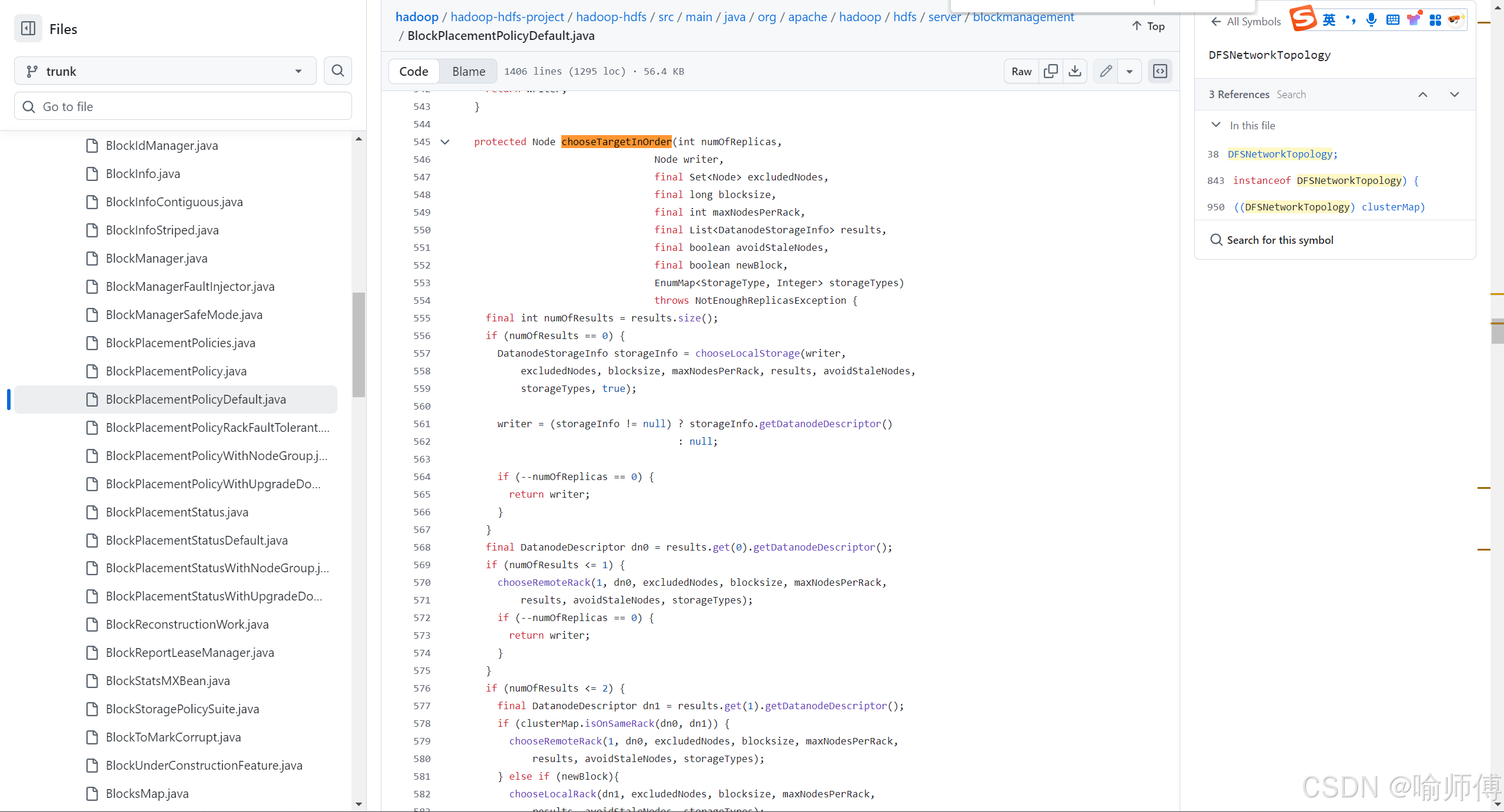
参数说明:
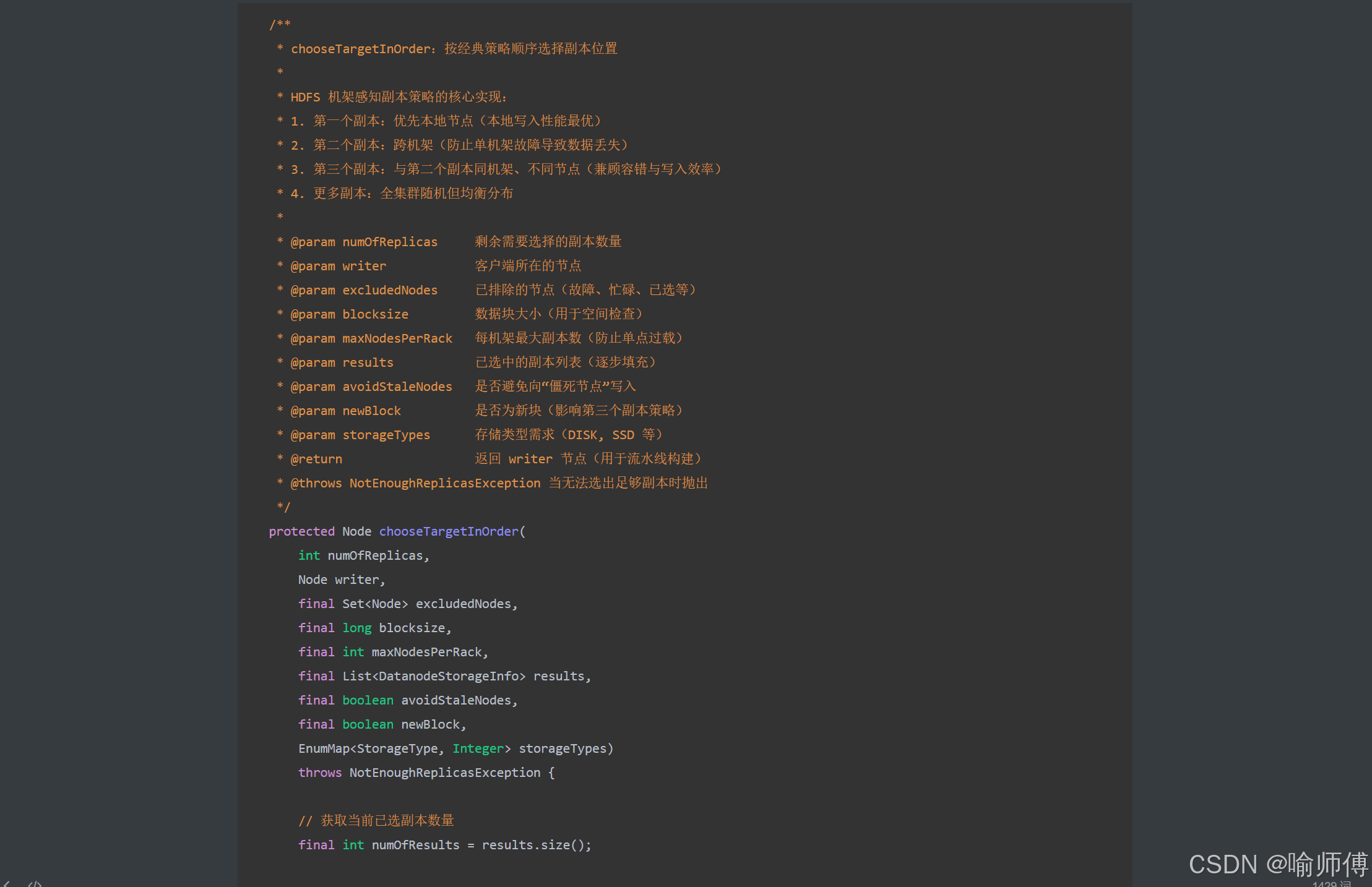
第一个副本存放策略:选择第一个副本 —— 优先本地节点(本地写入,性能最优)
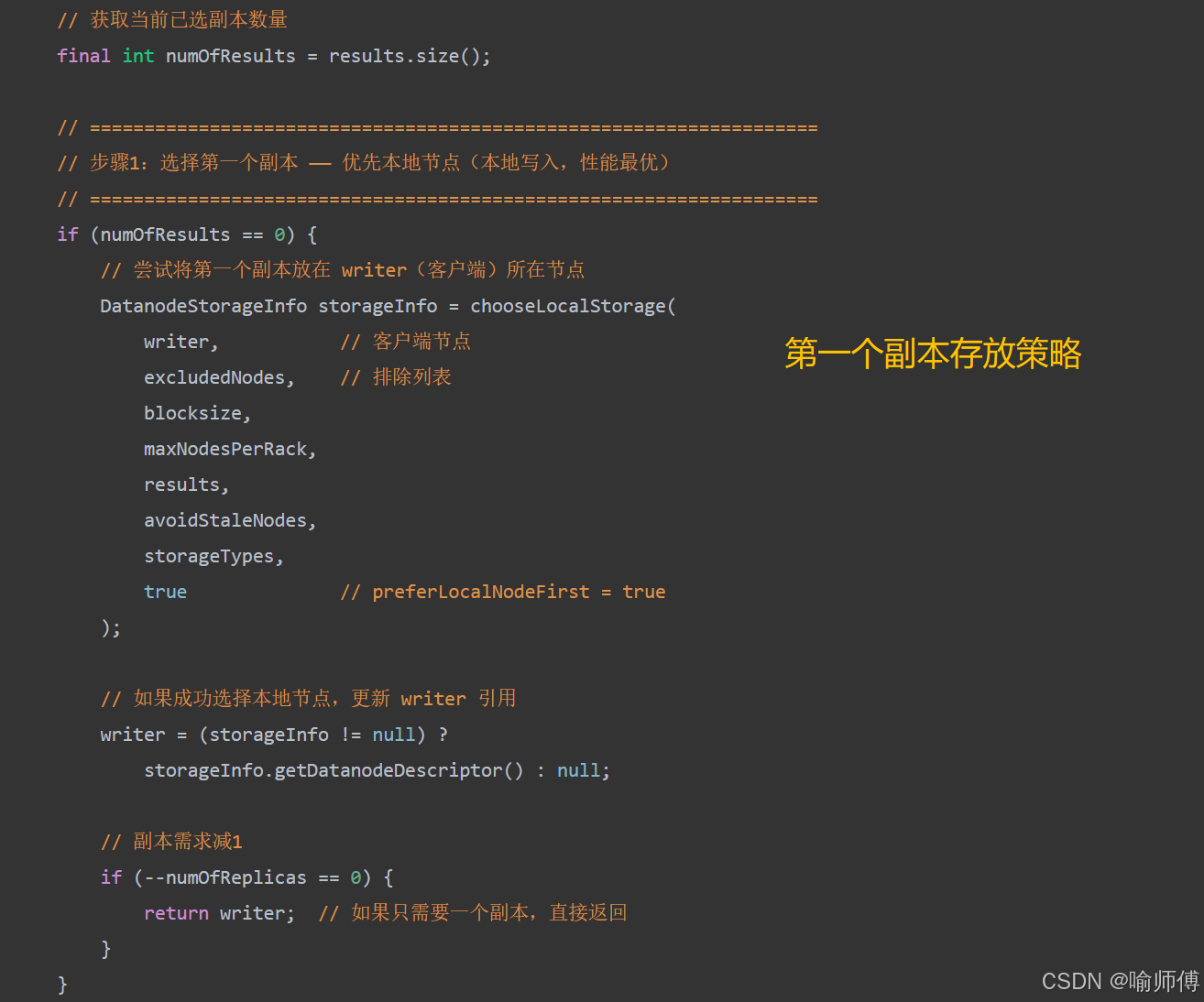
第二个副本存放策略:必须跨机架(实现机架级容错)
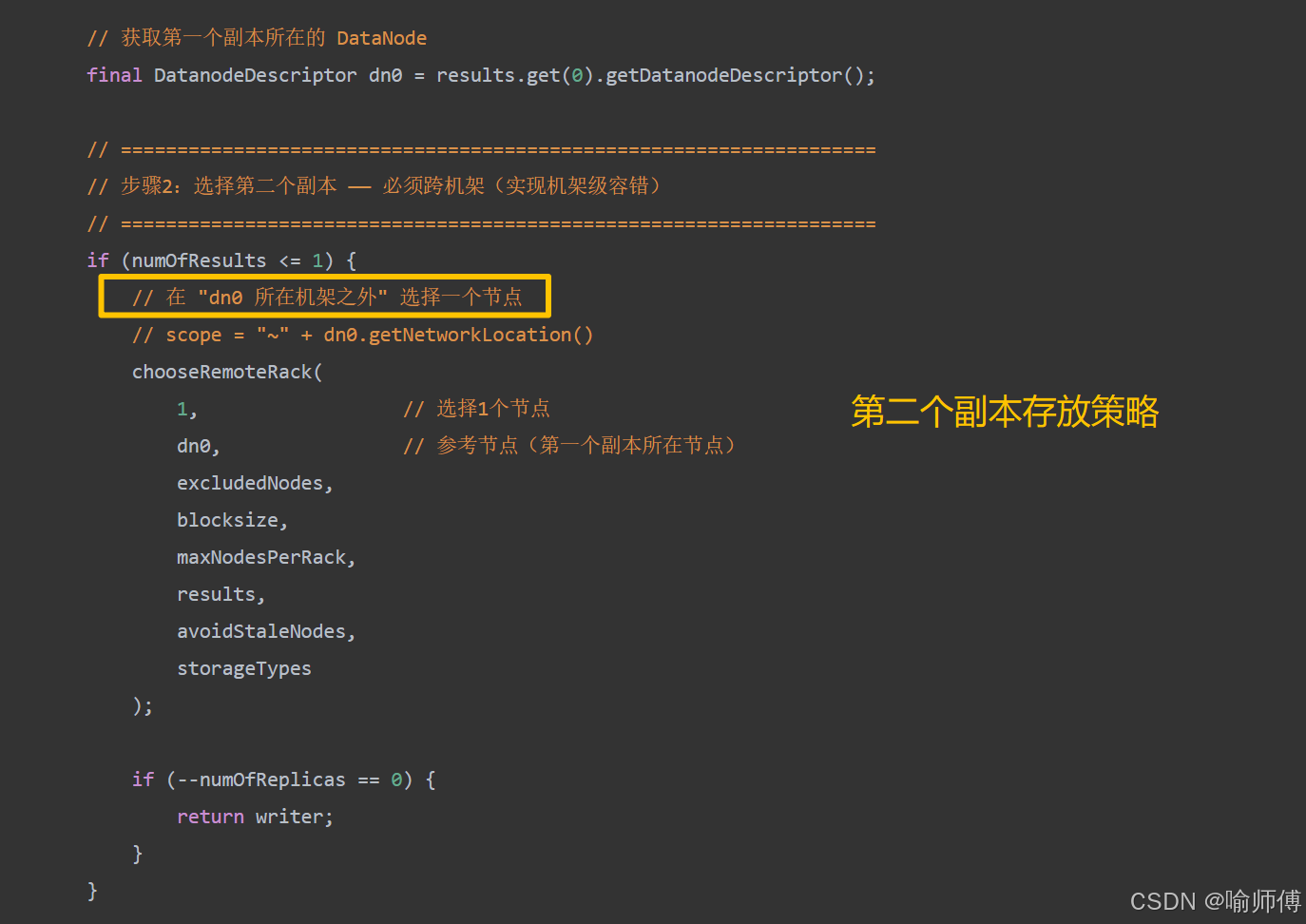
第三个副本存放策略:与第二个副本同机架,不同节点
其余副本:在保证均衡分布的情况下实现随机分布。
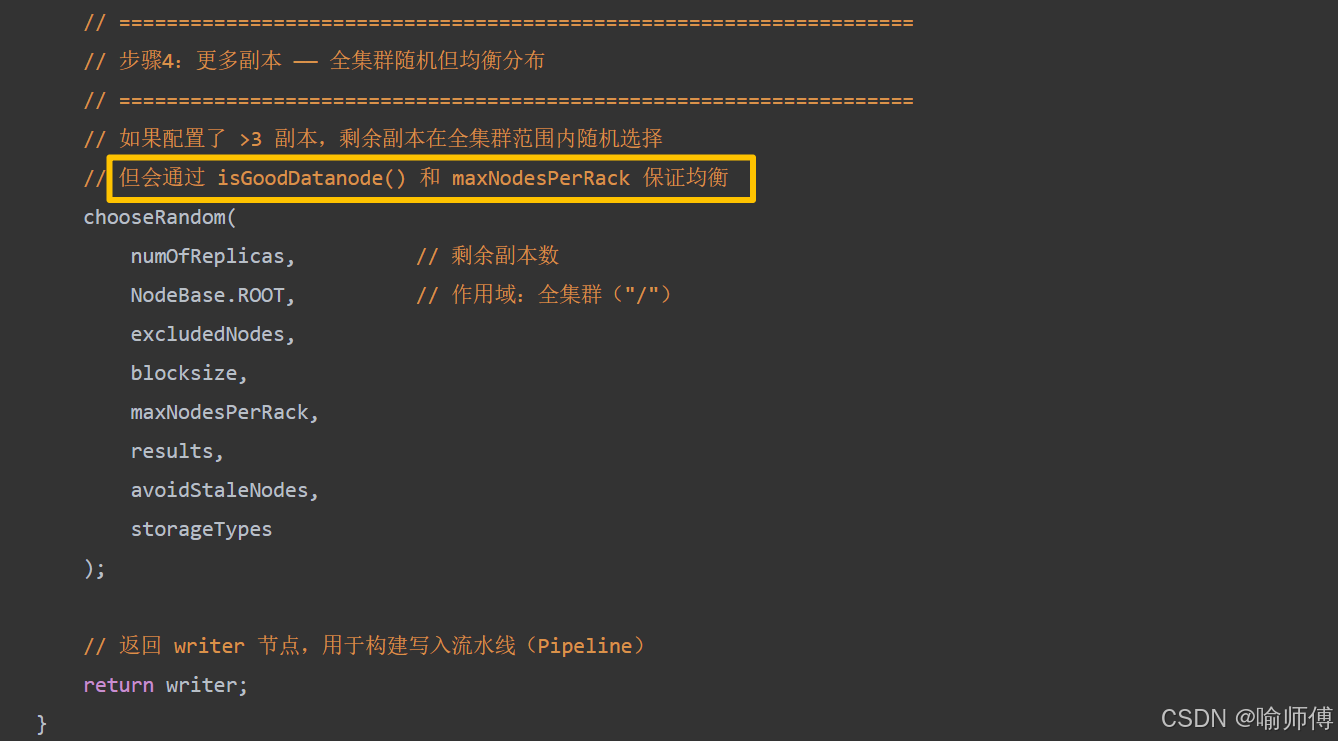
所有方法都依赖 isGoodDatanode() 方法进行健康检查,只有通过所有检查的节点才会被考虑
/*** isGoodDatanode:判断一个 DataNode 是否适合作为副本目标* * 只有通过所有检查的节点才会被考虑。* * @param node 目标 DataNode* @param maxTargetPerRack 每个机架允许的最大副本数(防止单机架过载)* @param considerLoad 是否考虑节点负载(CPU、网络等)* @param results 当前已选中的副本列表(用于机架平衡检查)* @param avoidStaleNodes 是否避免选择“僵死节点”(心跳超时)* @return true 表示节点合格,false 表示被拒绝*/
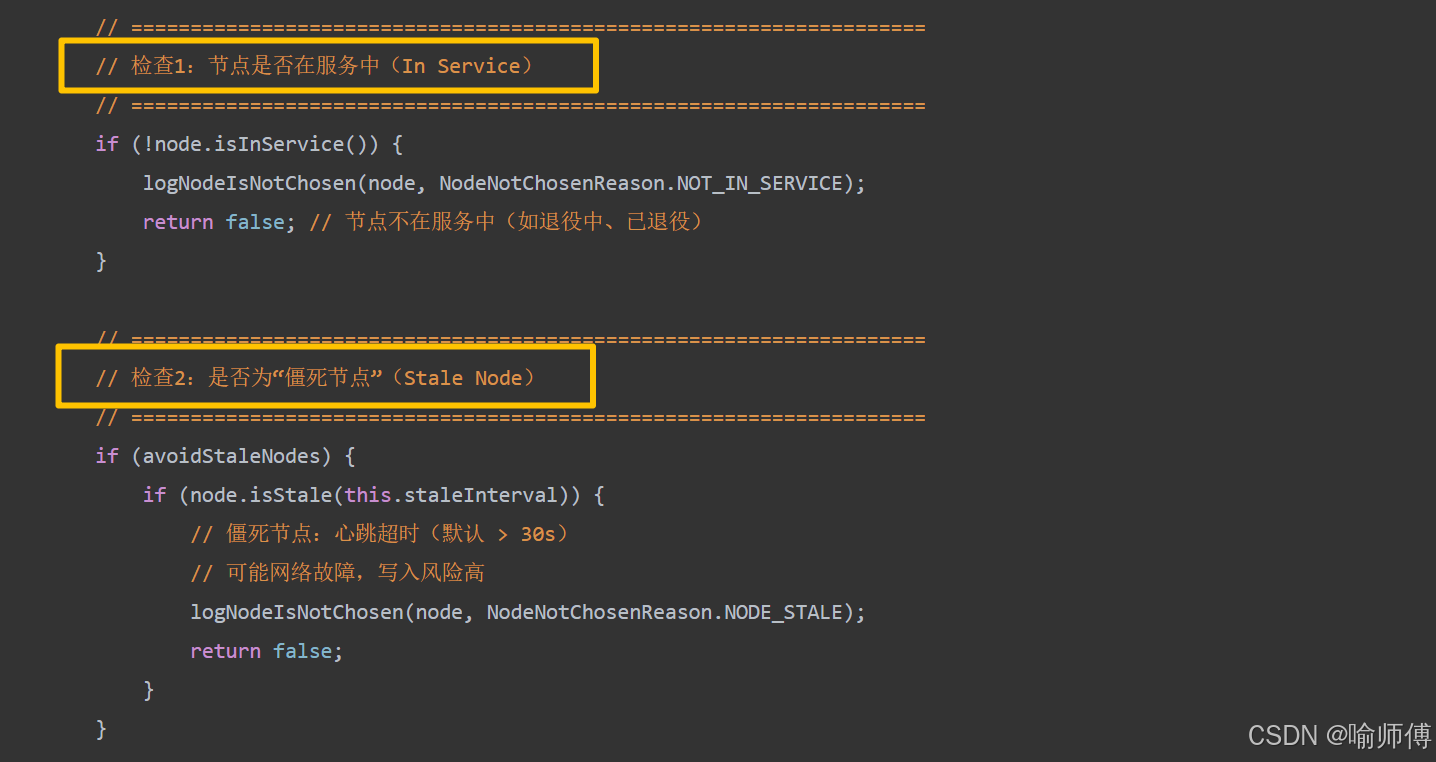
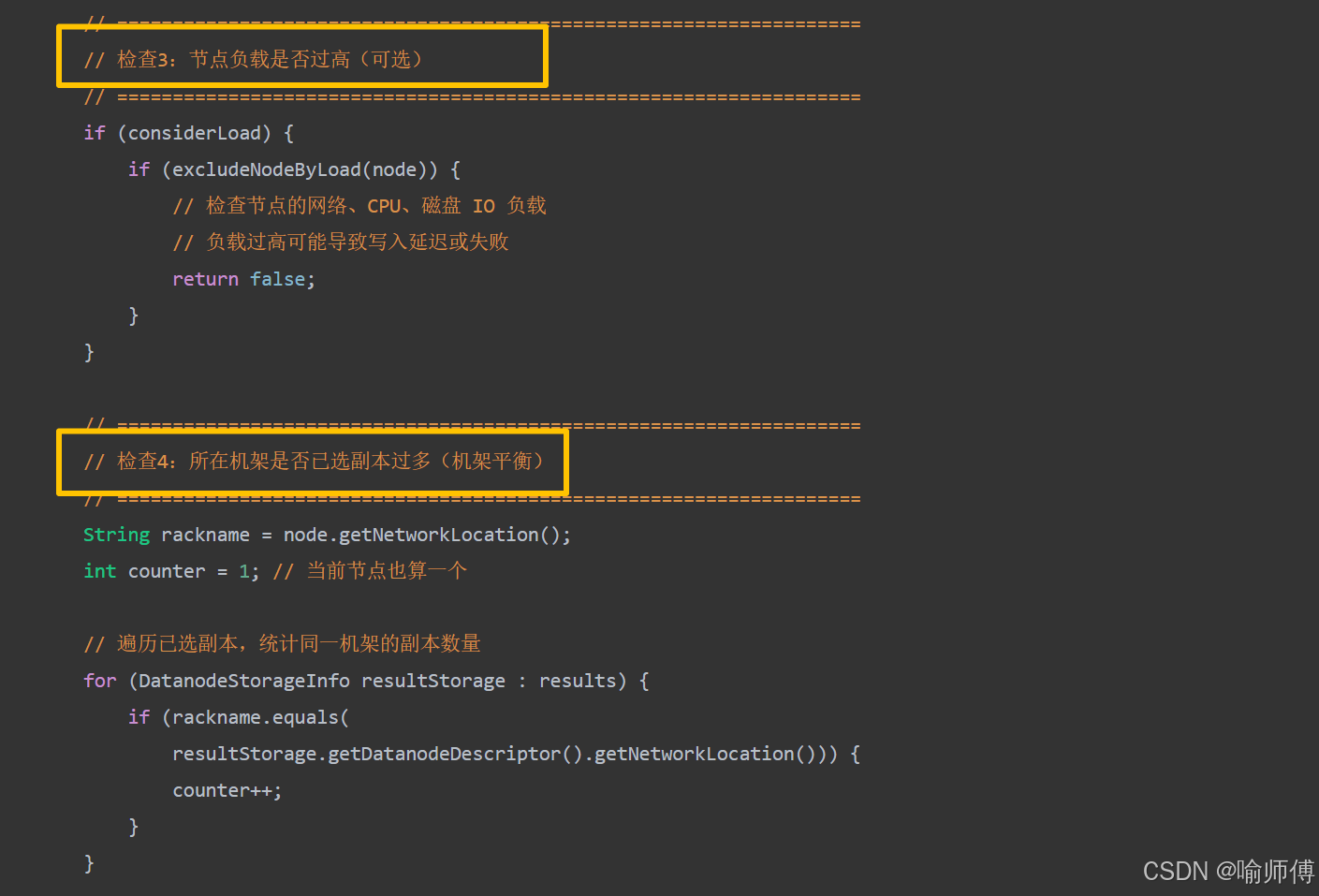
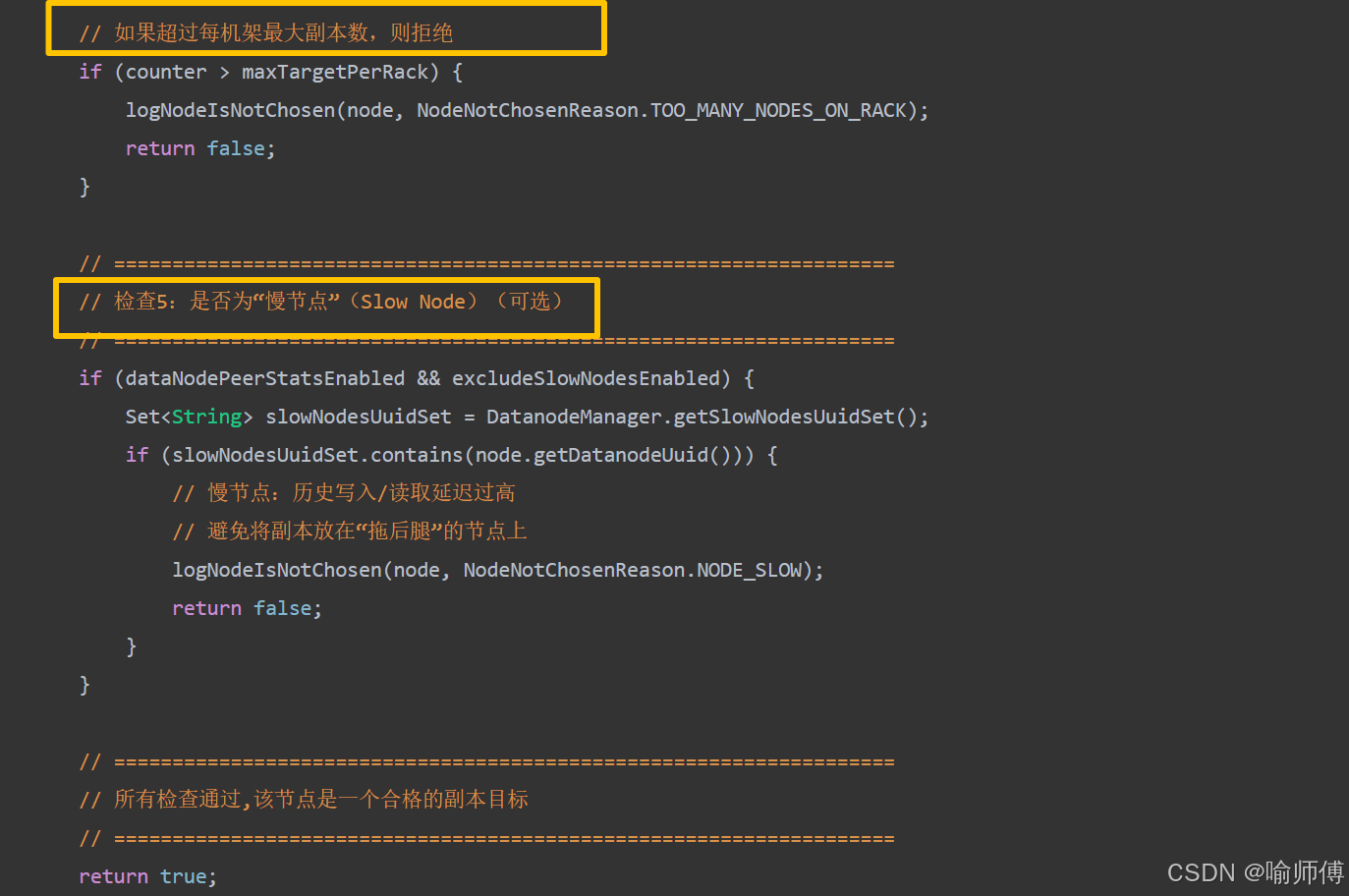
源码中还有很多细节,时间问题就不在这里一一赘述啦,大家有兴趣可以去github上研究一下,加深一下对副本存放机制的理解,链接在下面啦~ 感谢支持。
官网链接:https://hadoop.apache.org/docs/r3.4.0/hadoop-project-dist/hadoop-common/RackAwareness.html
源码地址:hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/server/blockmanagement/BlockPlacementPolicyDefault.java