Redis基础认知
Redis特性
1.快速:正常情况下,Redis执行命令的速度非常快,而速度快的原因一般分为以下几点:
-
数据在内存,会比访问硬盘更快
-
核心功能的逻辑比较简单,只有操作内存的数据结构
-
从网络角度上,使用了IO多路复用的方式(epoll) --> 使用一个线程,管理多个socket
-
使用的是单线程模型(核心逻辑),减少了不必要的线程之间的竞争开销
2. 数据存储:不同于MySQL使用'表'进行存储的关系数据库,Redis是通过'键值对'(key-value)的方式来存储组织数据的非关系数据库
3.丰富的使用功能
Redis除了数据结构,还提供了一些其他的功能
-
提供了键过期功能,用来实现缓存
-
提供了发布订阅功能,可以用来实现消息系统,同时也可以用来存储session
-
支持Lua脚本,可以利用该脚本对Redis进行扩展,可以通过简单的交互式命令进行操作
-
提供了简单的事务功能,能在一定程度下保证事务特性
-
提供了流水线功能,用户可以将命令一次性传递到Redis中,减少了网络开销
-
作为一个分布式系统的中间件,要求能够支持集群,要能够水平扩展(分库分表),可以使用多个服务器来部署多个Redis
4.简单稳定
-
源码较少,虽然添加了集群特性,但是相较于数据库来说还是很少的
-
使用单线程模型,所以服务端处理模型就会很简单,同时客户端开发也会很简单
-
不需要依赖于操作系统中的类库,实现了自己的事务处理相关功能
5. 客户端语言多,几乎覆盖了主流的编程语言
6.持久化
数据存储在内存中(内存中的数据是'易失'),但是也会存储一份在硬盘上(内存为主,硬盘为辅),如果Redis重启了,就会在重启时加载硬盘中的备份数据使Redis的内存恢复到重启前的状态
7.高可用和分布式
当Redis结点发生故障之后能够及时发现并将故障自动转移,同时提供了集群,实现了分布式,提供了高可用、读写和容量的扩展性
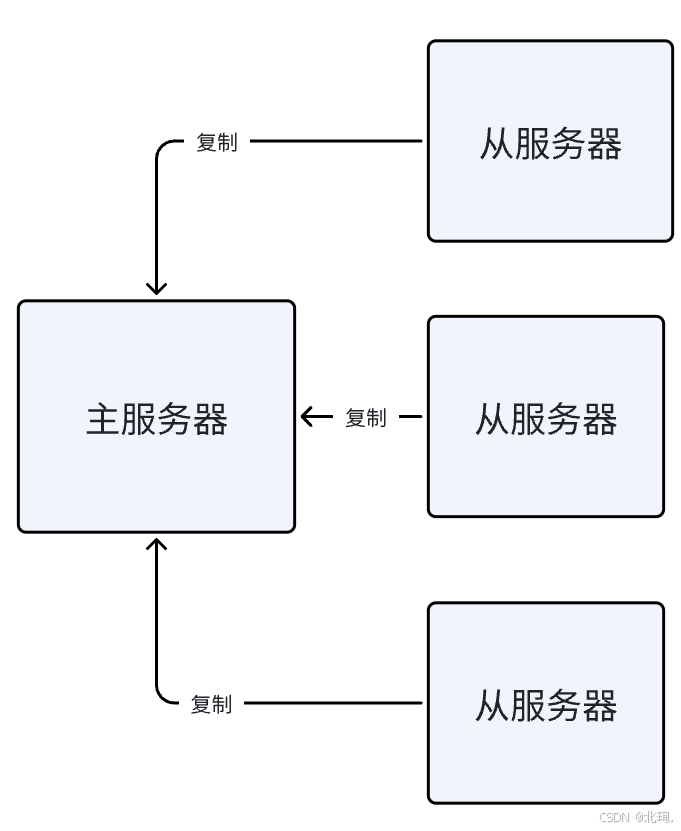
8.主从复制
提供了复制功能,实现了多个相同数据的Redis副本,进行备份,主从同步,从节点会对主节点进行备份
使用场景
可以做什么
-
实时数据库(全量数据):按照'键值对'存储,对于实时性要求高、效率要求高的场景(但是数据存储优先考虑'大')
-
作为缓存(部分数据,以及作为session):将热点数据存储在Redis中,以及存储用户数据
-
排行榜系统
-
计数器应用
-
社交网络(记录网站访问量)
-
消息队列:基于这个可以实现一个网络版本的 生产者-消费者 模型
无法做什么
-
数据规模:数据分为大规模和小规模,当数据规模过大时,使用Redis的成本就会很高
-
数据冷热:数据分为冷数据和热数据,热数据指的是需要频繁进行操作的数据,反之就是冷数据.如果我们经常存入Redis的热数据在某种业务中成为了冷数据,此时就会浪费内存