DeepSeek、GPT-5都在卷的“快慢脑”,腾讯中科院给出了更优解:还是多模态的!
一、导读
本研究旨在解决当前多模态大语言模型 (MLLM) 在集成“逐步思考”能力后面临的效率困境:虽然该能力显著提升了复杂推理任务的性能,但在处理简单问题时会造成不必要的计算开销。为应对这一挑战,论文提出了R-4B,一个具备自动思考 (auto-thinking) 能力的MLLM,能够根据问题复杂度自适应地决定是否启用思考过程。其核心方法论包含两个阶段:首先,通过一种名为双模态退火 (bi-mode annealing) 的训练策略,使模型同时掌握“思考”和“不思考”两种能力。该阶段依赖于一个精心构建的双模态数据集。其次,为解决模型在决策时倾向于不思考的“思维萎缩 (thinking atrophy)”问题,论文提出了一种名为双模态策略优化 (Bi-mode Policy Optimization, BPO) 的强化学习 (RL) 算法。该算法强制模型在训练中同时探索两种模式的效用,从而学会最优的决策策略。最终,R-4B在多个基准测试中取得了领先性能,以更低的计算成本达到了与更大规模模型相媲美的推理水平,为开发更智能、高效的MLLM提供了有效路径。
二、论文基本信息

基本信息
-
论文标题:4B: INCENTIVIZING GENERAL-PURPOSE AUTO-THINKING CAPABILITY IN MLLMS VIA BI-MODE ANNEALING AND REINFORCE LEARNING
-
作者:Tencent Hunyuan Team, Institute of Automation, CAS
-
作者单位:腾讯混元团队,中国科学院自动化研究所
摘要精炼
本文旨在解决MLLM在简单问题上不必要地调用复杂思考过程所导致的效率低下问题。为此,研究团队提出了R-4B,一个能根据问题复杂度自适应决策是否进行思考的自动思考MLLM。其核心技术贡献在于一个两阶段训练范式:首先通过双模态退火,在一个包含思考与非思考样本的特制数据集上训练,使模型兼具两种能力;接着,应用改进的GRPO框架——**双模态策略优化 (BPO)**,强制模型对每个输入同时生成两种模式的响应,从而优化其决策准确性。关键结论是,R-4B在25个挑战性基准测试中达到了SOTA水平,在大部分任务上超越了Qwen2.5-VL-7B,并在计算成本更低的情况下,于推理密集型基准测试中取得了与更大参数模型(如Kimi-VL-A3B-Thinking-2506,16B)相当的性能。
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/_2f41iXDAVnxOom0gEiffw
https://mp.weixin.qq.com/s/_2f41iXDAVnxOom0gEiffw
三、研究背景与相关工作
研究背景
近年来,通过引入显式的“逐步思考”过程(如使用<think>标签包裹推理步骤),MLLM在数学推理、科学图表理解等复杂任务上的表现得到显著提升。然而,这种“永远思考”的默认行为模式存在固有缺陷:在处理如“这道菜叫什么?”之类的简单问题时,复杂的推理过程不仅冗余,还浪费了大量计算资源。这种性能与效率之间的矛盾日益突出,因此,开发一种能根据问题难度自动启用或禁用思考能力的自动思考范式,对于构建更智能、更高效的MLLM至关重要。
相关工作
先前对自动思考的探索存在局限性。一些模型(如Qwen3)需要用户手动激活思考模式,未能实现自动化。另一些方法尝试通过强化学习(RL)训练自动思考能力,但通常依赖于人工设计的、复杂的奖励函数或标注数据,且主要局限于纯文本模态。最近,Keye-VL虽首次尝试了多模态自动思考,但其方法需要为训练数据手动构建复杂的分析,过程不精确且在推理时引入了额外的Token开销。这些现有方法的不足,凸显了市场对于一个更智能、计算效率更高的通用自动思考解决方案的迫切需求。
四、主要贡献与创新
提出R-4B:一个通用的自动思考MLLM
-
论文设计并实现了一个能够根据输入内容的复杂度,自主在“思考”与“直接回答”两种模式间切换的4B级MLLM,有效平衡了推理性能与计算效率。
提出双阶段训练范式
-
双模态退火 (Bi-mode Annealing): 设计了一种启发式驱动的数据构建策略,系统性地将数据分为推理和非推理两类。通过在该混合数据集上训练,使模型基座(R-4B-Base)同时掌握了两种核心能力。
-
双模态策略优化 (BPO): 提出了一种新颖的RL算法,通过强制模型在训练时对同一问题生成“思考”和“非思考”两种响应路径(即双模态部署, bi-mode rollouts),并基于简单的规则化奖励进行优化,有效解决了模型的“思维萎缩”问题,教会模型何时进行思考。
实现SOTA性能与效率
-
R-4B在25个公开基准测试上取得了优异性能。如图1所示,它不仅在性能上超越了同规模的先进模型,还在计算成本更低的情况下,在多个高难度推理基准上媲美甚至超越了参数量远大于自身的模型。
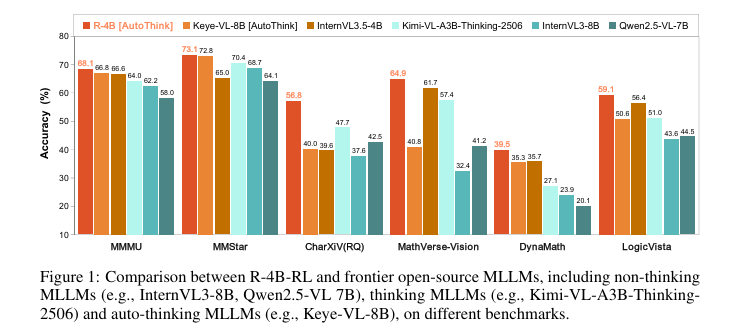
五、研究方法与原理
总体框架与核心思想
本研究的核心思想是采用“先赋予能力,再教会决策”的两阶段训练策略,来构建一个高效的自动思考模型。
-
阶段一:双模态退火 (能力赋予)
-
目标:使基础模型同时精通“思考”和“非思考”两种响应模式。
-
实现:通过一种启发式驱动的数据策管策略(如图3所示),利用一个强大的现有MLLM(Qwen2.5-32B-VL)作为标注器,将数据自动分为需要推理的“硬样本”和可直接回答的“简单样本”。随后,将这些数据统一格式化(思考样本包含
<think>...</think>,非思考样本则包含空的<think> </think>),混合后对模型进行微调,得到具备双模态能力的R-4B-Base。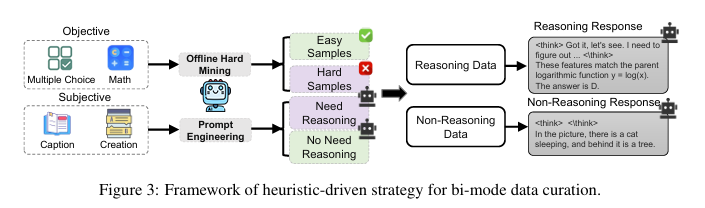
-
-
阶段二:双模态策略优化 (BPO) (决策学习)
-
目标:解决R-4B-Base在面对复杂问题时倾向于“不思考”的思维萎ősz(thinking atrophy)问题,教会模型根据问题难度自适应选择模式。
-
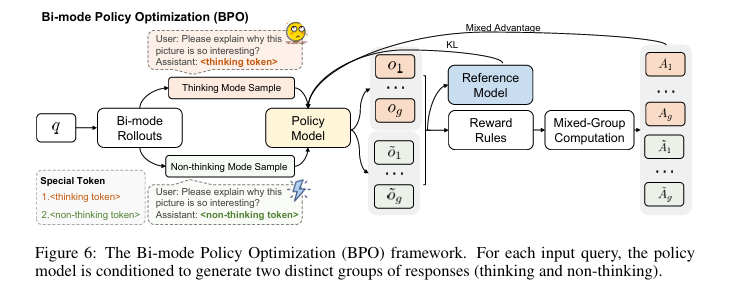
实现:提出BPO算法,该算法是GRPO框架的改进。其核心创新在于**双模态部署 (bi-mode rollouts)**(如图6所示),即对每个输入,通过添加特殊token(如
<thinking token>)强制策略模型生成一个“思考”响应组和一个“非思考”响应组。通过对比这两种路径的奖励,模型可以学习到一个最优的自适应决策策略。
-
关键实现与评估原理
关键实现细节:
-
数据格式化:在退火阶段,所有数据均采用统一的指令跟随结构,思考样本格式为
<think>reasoning steps</think>answer,非思考样本为<think> </think>answer,确保结构一致性。 -
双模态部署:在BPO阶段,通过在输入提示中确定性地附加特殊token(如
<thinking token>或<non-thinking token>)来强制生成特定模式的响应,从而确保对两种策略的均衡探索。 -
简单奖励机制:BPO避免了复杂的奖励工程,仅利用数学问题领域的简单、基于规则的奖励信号,却表现出强大的泛化能力,能推广到其他非数学领域。
核心评估原理与指标:
-
BPO的优化目标通过以下公式定义,旨在最大化奖励并约束策略模型与参考模型的偏离度:
-
其中, 代表思考和非思考两种模式的部署(rollouts), 是策略比率, 是优势值, 和 是超参数。
-
实验评估主要采用各基准的准确率(Accuracy)和平均输出Token数,前者衡量性能,后者衡量效率。
六、实验结果与分析
实验设置
-
数据集: 在25个多样化的公开基准上进行评估,涵盖通用视觉问答 (MMMU, MMStar)、图表与文档理解 (AI2D, CharXiv)、数学推理 (MathVista, MathVerse) 等。
-
评估指标: 主要使用各基准定义的准确率。在分析效率时,使用平均每查询输出Token数。
-
对比基线: 与多个前沿开源MLLM进行比较,包括非思考模型 (InternVL3-8B, Qwen2.5-VL-7B)、思考模型 (Kimi-VL-A3B-Thinking-2506) 和自动思考模型 (Keye-VL-8B)。
-
关键超参: 推理时采用贪心解码(greedy decoding),温度(temperature)设为0,最大生成长度为8,192个token。
核心实验与结论
【一项最核心的实验:不同模式下的Token消耗量对比】
-
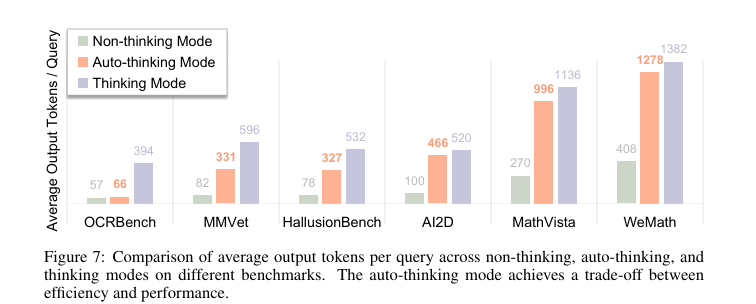
实验目的: 该实验旨在验证R-4B-RL的自动思考模式是否能有效根据任务复杂度动态调整计算开销(以输出Token数量衡量),实现性能与效率的最佳权衡。
-
关键结果: 如图7所示,实验结果清晰地展示了自动思考模式的智能适应性:
-
在简单任务(如OCRBench)上,自动思考模式的平均输出Token数(66个)与非思考模式(57个)相近,远低于思考模式(394个),同时性能并未受损。
-
在复杂推理任务(如MathVista和WeMath)上,自动思考模式的平均输出Token数(分别为996和1278个)显著增加,接近完全思考模式(分别为1136和1382个)。
-
-
作者结论: 作者认为,该实验证明了通过BPO学到的自动思考策略是真正智能且可泛化的。模型能有效辨别不同领域的任务复杂度,在需要时投入更多计算资源以确保高性能,在任务简单时则节约资源,从而在性能和效率之间达到了近乎最优的平衡。
七、论文结论与启示
总结
本文成功提出了R-4B,一个旨在解决MLLM推理效率与性能矛盾的4B级自动思考模型。通过创新的双模态退火和双模态策略优化(BPO)两阶段训练范式,R-4B被赋予了兼顾“思考”与“非思考”的能力,并学会了如何根据问题复杂度智能地选择响应模式。实验证明,R-4B不仅在25个基准测试中表现出色,超越了同级别模型,还以更低的计算成本达到了与更大规模模型相媲美的推理性能。这项工作为开发下一代更智能、资源效率更高的MLLM提供了坚实的理论基础和可行的技术路径。
展望
论文的结论强调了该研究为开发更智能、更高效的MLLM指明了一条有效途径。未来的研究可以沿着这条路径继续探索:
-
更精细的思考控制:研究如何在思考过程中实现更细粒度的控制,例如动态调整思考的深度和广度。
-
跨模态奖励机制:虽然本文证明了简单奖励的泛化性,但探索更通用的、跨模态的奖励函数可能进一步提升决策的精确度。
-
更广泛的应用:将此自动思考机制推广到更多模态(如视频、音频)和更广泛的应用场景中,是值得探索的方向。
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/_2f41iXDAVnxOom0gEiffw
https://mp.weixin.qq.com/s/_2f41iXDAVnxOom0gEiffw