Day20_【机器学习—逻辑回归 (2)—分类评估方法】
一、混淆矩阵
混淆矩阵:用于展示真实值和预测值之间正例、反例的情况
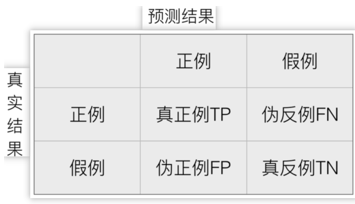
记忆口诀:同真异伪(第一个字),看预测值 (第二个字)
一般选取样本数量少的为正例
计算:
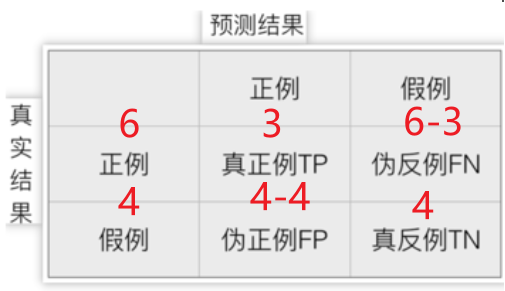
1.标注真实结果的个数
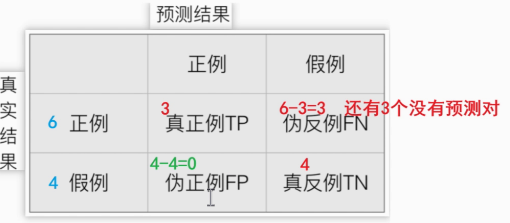
2.先算出 真正例与真反例的个数,其余两个用减法如图
二、分类评估方法
都需要依据混淆矩阵进行简单计算
1. 精确率 (Precision)
含义:在所有被模型预测为正类的样本中,有多少是真正的正类。关注的是预测的准确性。
公式:
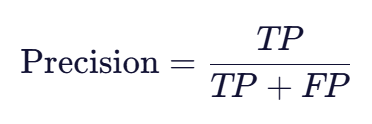
- Precision:看第一列(预测为正类的列)→
TP / (TP + FP)
2. 召回率 (Recall) / 真正率 (TPR)
含义:在所有真实的正类样本中,有多少被模型正确找了出来。关注的是查全能力。
公式:
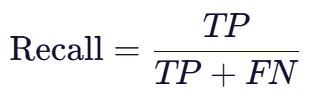
✅ 注意:召回率 = 真正率(TPR)
- Recall:看第一行(真实为正类的行)→
TP / (TP + FN)
3. F1-score
含义:精确率和召回率的调和平均数(Harmonic Mean)。
当两者都很重要,且可能相互冲突时,用 F1-score 综合评估。
公式:

举个栗子
已知条件:
- 样本总数:10个样本
- 恶性肿瘤样本(正例):6个
- 良性肿瘤样本(反例):4个
预测结果:
- 正确预测了3个恶性肿瘤样本(TP)
- 正确预测了4个良性肿瘤样本(TN)
问 :
1.计算混淆矩阵的各个值
2.计算精确率、召回率和F1-score
答1:
1. 真正例 TP 为:3
2. 伪反例例 FN 为:3
3. 伪正例 FP 为:0
4. 真反例 TN 为:4
1.标注真实结果的个数
2.先算出 真正例与真反例的个数,其余两个用减法如图
答2:
1. 精确率:3/(3+0)=1
2. 召回率:3/(3+3)=0.5
3.F1-score:2*1*0.5/(1+0.5)=0.67
API实现
from sklearn.metrics import confusion_matrix,precision_score,recall_score,f1_score
print(f"A的精确率:{precision_score(y_test,y_predict)}")
print(f"A的召回率:{recall_score(y_test,y_predict)}")
print(f"A的F1-score:{f1_score(y_test,y_predict)}")4.ROC曲线和AUC指标
4.1真正率TPR与假正率FPR

4.2 ROC曲线
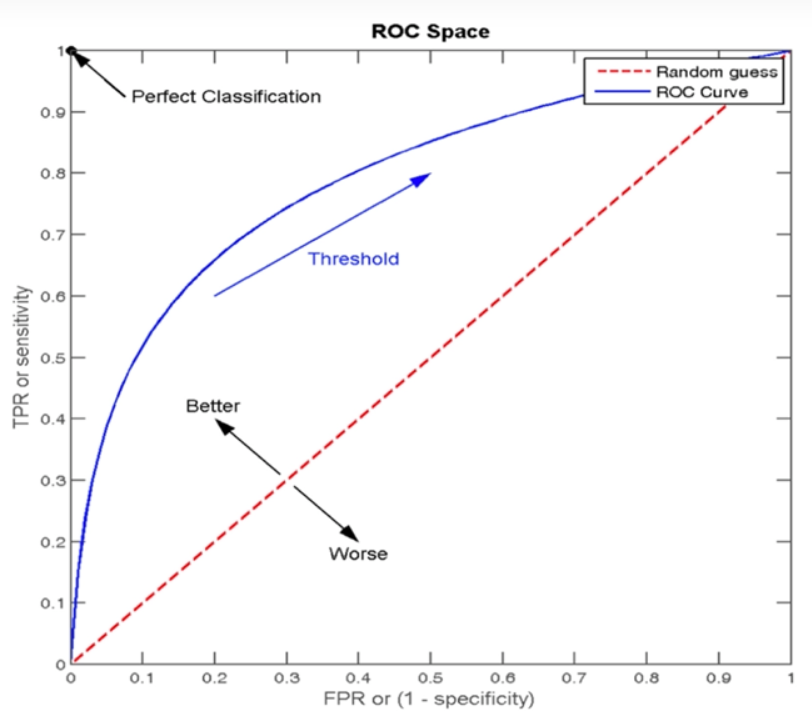
- ROC曲线是一种常用于评估分类模型性能的可视化工具。
- ROC曲线以模型的真正率TPR为纵轴,假正率FPR为横轴,
- 它将模型在不同阈值下的表现以曲线的形式展现出来。
特殊点含义
| 预测为正类(Positive) | 预测为负类(Negative) | |
|---|---|---|
| 实际为正类(Positive) | 真正例 (TP) | 假负例 (FN) |
| 实际为负类(Negative) | 假正例 (FP) | 真负例 (TN) |
(0,0):全部预测为负例
- 所有样本都被预测为负类,TP = FP = 0,因此 TPR = 0,FPR = 0
(1,1):全部预测为正例
- 所有样本都被预测为正类,TP = 所有正例,FP = 所有负例,因此 TPR = 1,FPR = 1
(0,1):完美分类器
- 所有正例都被正确预测为正,所有负例都被正确预测为负,TP = 所有正例,FP = 0,因此 TPR = 1,FPR = 0
(1,0):最差分类器(反向预测)
- 所有正例被预测为负,所有负例被预测为正,TP = 0,FP = 所有负例,因此 TPR = 0,FPR = 1
4.3 AUC值
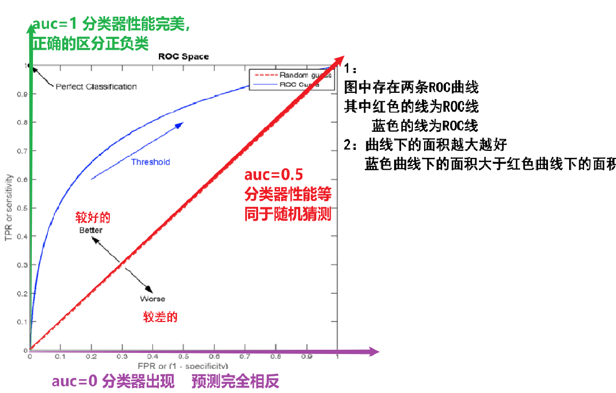
ROC曲线的优劣可以通过曲线下面积(AUC)来衡量,AUC越大表示分类器性能越好。
- 当AUC=0.5时,表示分类器的性能等同于随机猜测;
- 当AUC=1时,表示分类器的性能完美,能够完全正确地将正负例分类。
API实现
from sklearn.metrics import roc_auc_score,classification_report
# AUC的计算api
print(roc_auc_score(y_test, y_predict))
# 分类评估报告api
report_api = classification_report(y_test, y_predict)
print(report_api)