一文看懂 FastDatasets:用 LLM 极速生成高质量 SFT 数据集(已支持 Hugging Face Spaces PyPI)
一文看懂 FastDatasets:用 LLM 极速生成高质量 SFT 数据集(已支持 Hugging Face Spaces & PyPI)
当大家还在手搓数据、到处找样本时,FastDatasets 已经把“数据蒸馏 + 指令增强 + 结构化导出”打包成一键流程。它是一个面向 SFT/Fine-tuning 的“数据生成工作台”:简单、快、可控、可落地。
— 立即体验与支持 —
- 体验版在线 Demo(Hugging Face Spaces): FastDatasets · Spaces
- 项目主页(求一个 Star!): GitHub · FastDatasets
- 一行安装(PyPI):
pip install fastdatasets-llm;或带 UI/文档能力:pip install "fastdatasets-llm[all]"
为什么需要 FastDatasets?
- 数据生产是真正的瓶颈:模型多如牛毛,但高质量、成规模、结构化的数据极其难得。
- 从零到可用太慢:脚本东拼西凑、接口一堆坑、参数不成体系、导出格式不统一。
- 成本/质量难以平衡:需要“可控调用 + 合理采样 + 自动清洗 + 可复现配置”。
FastDatasets 的目标很直接:让每个团队都能像产品经理点按钮一样,批量生成可训、可复现、可解释的数据集。
FastDatasets 有什么不一样?
- 聚焦 SFT 的数据蒸馏与指令增强:围绕 Instruction/Output 设计数据模板,兼容 Alpaca 等主流格式。
- 低门槛体验:
- 在线“体验版”Space:限制成本的同时,让你秒懂核心能力与输出结构。
- 本地“完整版”:完整并发、分块、长度控制、清洗与导出能力,一次搞定。
- 现代化工程:
pyproject.toml打包,fastdatasetsCLI 即开即用。- 高层 API(
generate_dataset/generate_dataset_to_dir)开箱即用,参数可直传或走环境变量。 - 可选依赖(UI/文档/服务)按需安装,轻量不绑架。
- 可控与可复现:chunk size、overlap、并发、tokens、模型/基座地址均可控;导出稳定可复现。
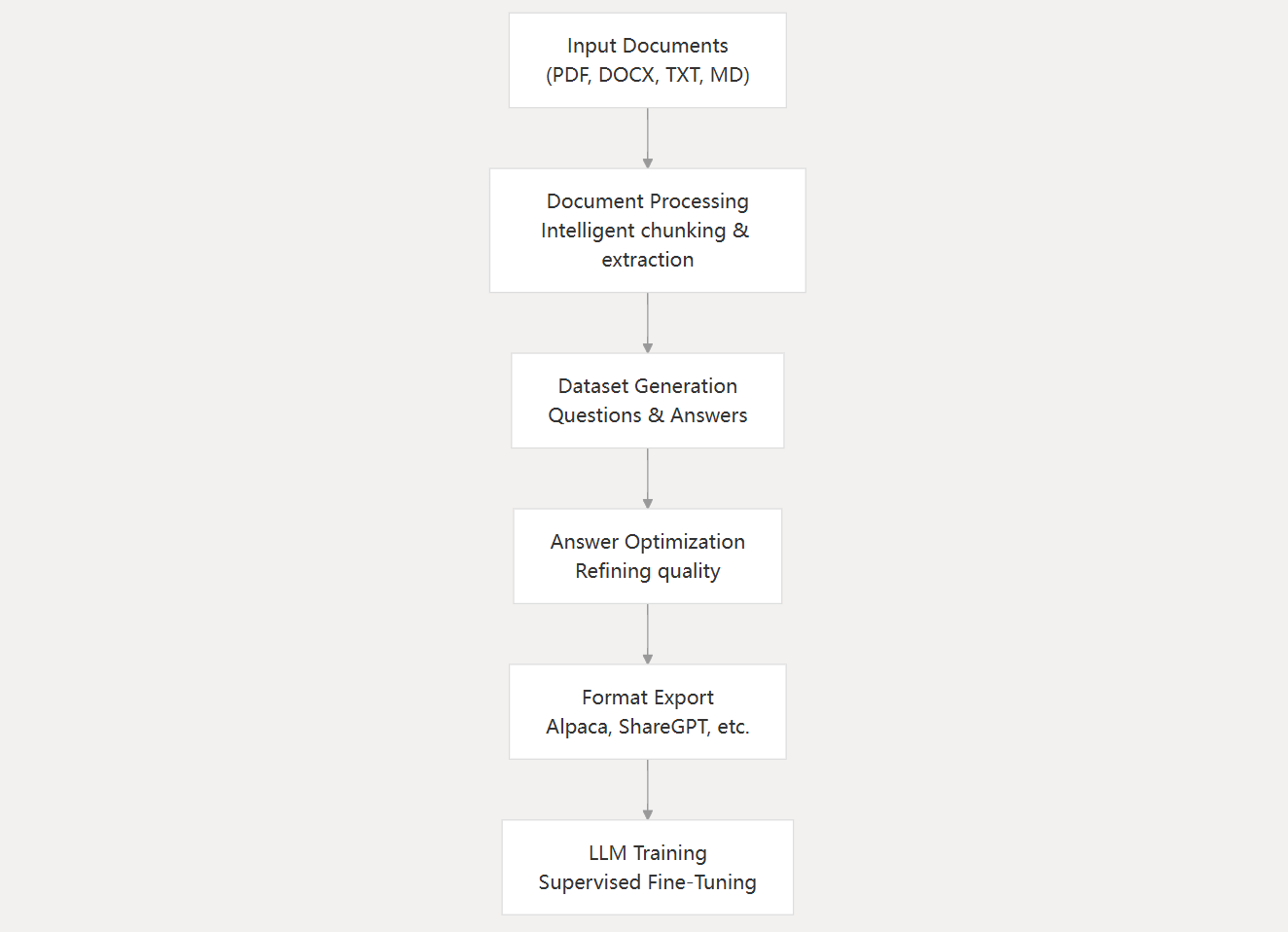
三分钟上手(PyPI)
- 安装
pip install fastdatasets-llm
# 或:pip install "fastdatasets-llm[all]"
- 配置 LLM(两种方式二选一)
- 方式 A:环境变量(建议配合 .env)
export LLM_API_KEY=...
export LLM_API_BASE=https://api.openai.com/v1
export LLM_MODEL=gpt-4o-mini
- 方式 B:直接在函数参数中传入(会覆盖环境变量)
- 最小可用示例(Python API)
from fastdatasets import generate_dataset_to_dirgenerate_dataset_to_dir(input_path="./samples.txt", # 支持 .txt/.mdoutput_dir="./out", # 导出目录# LLM 直传参数(可选,覆盖环境变量)llm_api_key="YOUR_KEY",llm_api_base="https://api.openai.com/v1",llm_model="gpt-4o-mini",# 关键可控参数chunk_size=800,chunk_overlap=120,max_concurrency=2,max_input_tokens=2000,
)
- 一键 CLI(零代码)
fastdatasets generate \--input ./samples.txt \--output ./out \--chunk-size 800 \--chunk-overlap 120 \--max-concurrency 2
导出文件默认包含 Alpaca 格式(instruction/input/output),可直接用于 SFT 训练。
主流 API 兼容与连接快速测试
- 已适配的主流提供商:OpenAI、Azure OpenAI、DeepSeek、智谱 AI(Zhipu)、Anthropic(Claude)等,统一
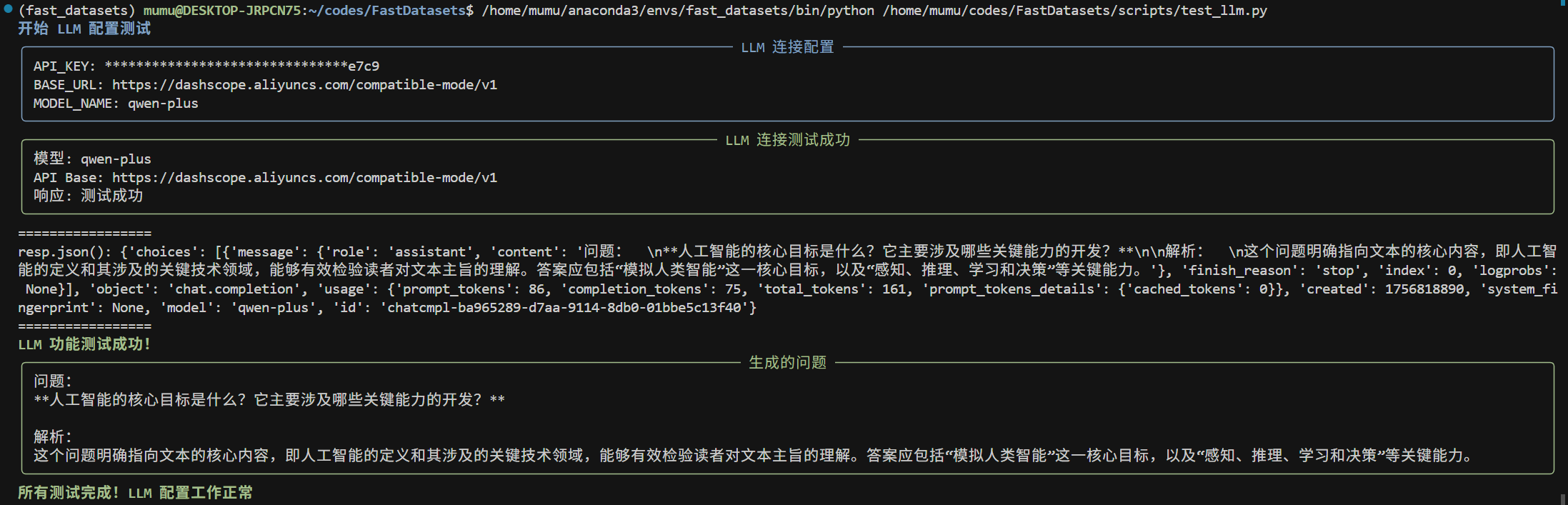
chat/completions风格调用,参数可通过环境变量或函数参数传入。 - 一键连通性自检:项目内置脚本可快速检测 API Key、Base URL、模型是否可用,并给出最小对话验证与基础能力验证。
python scripts/test_llm.py
在线体验 vs 本地完整版(如何选择?)
- Spaces 体验版:超低成本、无门槛,限制文件数与长度,展示真实调用路径与输出结构。
- 本地完整版:解锁并发/分块/清洗/更大上下文/多格式导出,适合真实生产与迭代。
建议:先在 Space 秒懂流程,再在本地批量跑真活。
典型用法场景
- 指令集扩增:把少量高质量示例扩增为成百上千条规范化样本。
- 知识蒸馏:从文档/知识库中抽取问答/摘要/逐步推理样本。
- 错误对抗:为模型构造“好坏对比”样本,提升鲁棒性。
- 领域定制:金融/医疗/教育等领域,统一模板、统一格式、可控成本。
真材实料的工程细节
- 高层 API:
generate_dataset:返回内存中的样本列表generate_dataset_to_dir:直接落盘,内置asyncio.run,对调用方零心智负担
- 参数一体化:同一组参数既可走环境变量也可在函数中覆盖,避免“只改一处不起作用”的烦恼。
- 可选依赖策略:
[web]、[doc]、[all]分层拆分,安装极致轻量。 - HF Spaces 兜底逻辑:即使体验版依赖最小化,也能稳定展示核心流程。
为什么选择 FastDatasets?
- 面向 SFT 的产品化数据生产:从采样、清洗到导出,一条龙可复现。
- 即开即用、可大可小:体验版秒懂流程,完整版立刻规模化产出。
- 简而不简:高层 API 覆盖常用场景,参数精细可调,工程可维护。
现在就参与(你的一个 Star,非常重要)
- 给仓库点个 Star,帮我们被更多人看见 → GitHub · FastDatasets
- 打开在线体验:一键理解“输入→蒸馏→导出”的全链路 → HF Spaces
- pip 安装立刻使用:
pip install fastdatasets-llm - 欢迎 Issues/PR/Feature 请求,一起把“数据生产”真的变简单!
— 我们相信:好的模型建立在好的数据之上;而好的数据,应该被快速、优雅、低成本地生产出来。