Ollama:本地大语言模型部署和使用详解
1.什么是Ollama?
Ollama是一个开源的大语言模型管理工具,具有以下特点:
- 简单易用:提供简单的命令行接口
- 本地部署:模型运行在本地,保护数据隐私
- 跨平台支持:支持Windows、macOS、Linux
- 丰富的模型库:支持多种主流大语言模型
- Docker支持:可以容器化部署
2. Linux 本地部署Ollama
(1)环境准备
在开始部署之前,先检查一下系统环境:
# 检查系统信息
cat /etc/os-release
uname -m# 检查硬件资源(很重要!)
free -h # 查看内存
df -h # 查看磁盘空间
lscpu # 查看CPU信息# 如果有GPU,检查CUDA支持
nvidia-smi # NVIDIA GPU
rocminfo # AMD GPU(如果适用)(2)快速安装
在 Linux 上安装 Ollama 非常便捷,官方提供了一键安装脚本。这个脚本会自动检测您的系统环境(如 Ubuntu, CentOS 等),并自动下载并安装 Ollama。
# 最简单的安装方式(适用于大多数Linux发行版)
curl -fsSL https://ollama.ai/install.sh | sh# 安装完成后验证
ollama --version验证时,如果看到类似 ollama version is 0.x.x 的输出,说明安装成功。

离线下载
curl -fsSL https://ollama.com/install.sh -o install.sh
也可以直接浏览器访问https://ollama.com/install.sh,将脚本拷贝到文件install.sh中,再使用
sh install.sh命令安装。
3.docker镜像方式部署Ollama
ollama官方提供了镜像,可以直接启动容器使用,docker安装教程可参考docker安装和使用
(1)下载镜像:
docker pull ollama/ollama
(2)启动容器:
# 运行容器
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama# GPU加速运行容器
docker run -d --gpus=all -v ollama/.ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
(3)进入容器启动模型:
docker exec -it ollama bashollama run deepseek-r1:1.5b

(4)多卡运行
ollama默认使用单卡进行部署,使用多卡推理需要设置环境变OLLAMA_SCHED_SPREAD=1,对于docker容器部署的ollama,直接在启动命令里添加环境变量即可,对于Linux启动的ollama,可手动更改环境变量,更改方法可参考Linux设置环境教程
docker run -d --gpus=all -e OLLAMA_SCHED_SPREAD=1 -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
4.Ollama的基本使用
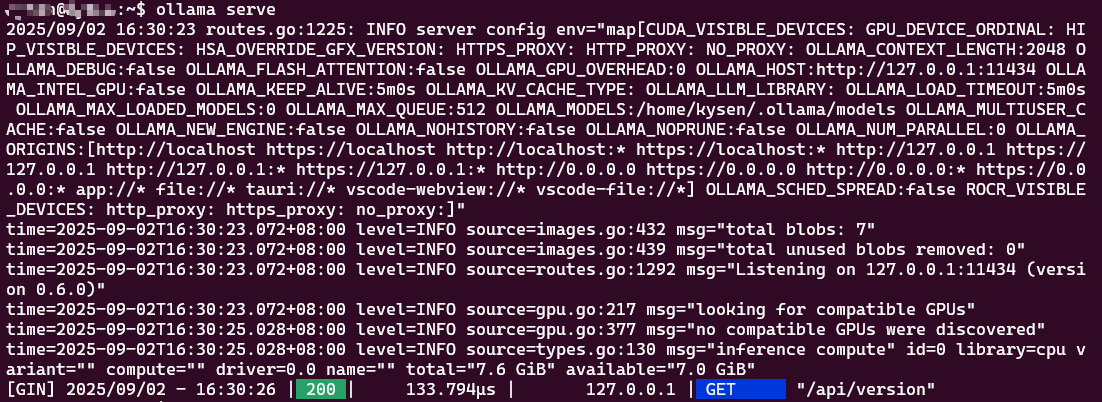
(1)启动服务
ollama serve
(2)模型管理
下载模型
查看已下载模型
# 列出所有模型
ollama list# 查看模型详情
ollama show deepseek-r1:1.5b删除模型
# 删除指定模型
ollama rm deepseek-r1:1.5b(3)模型下载
ollama pull <model_name># 例如
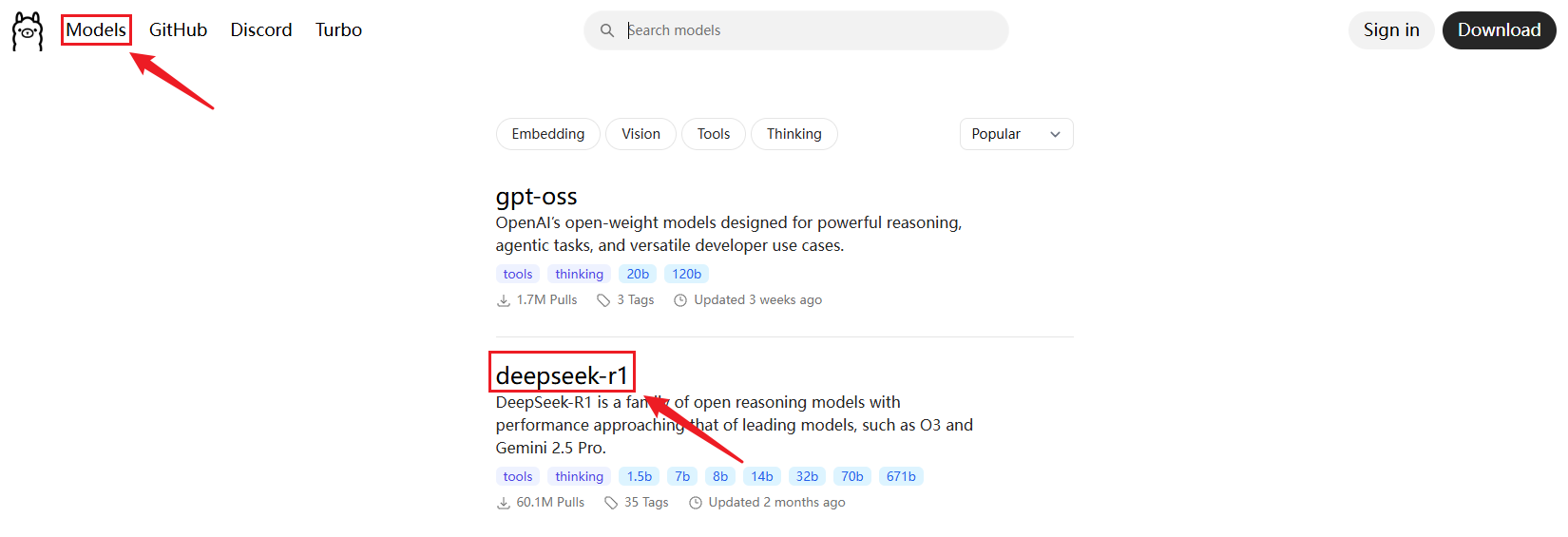
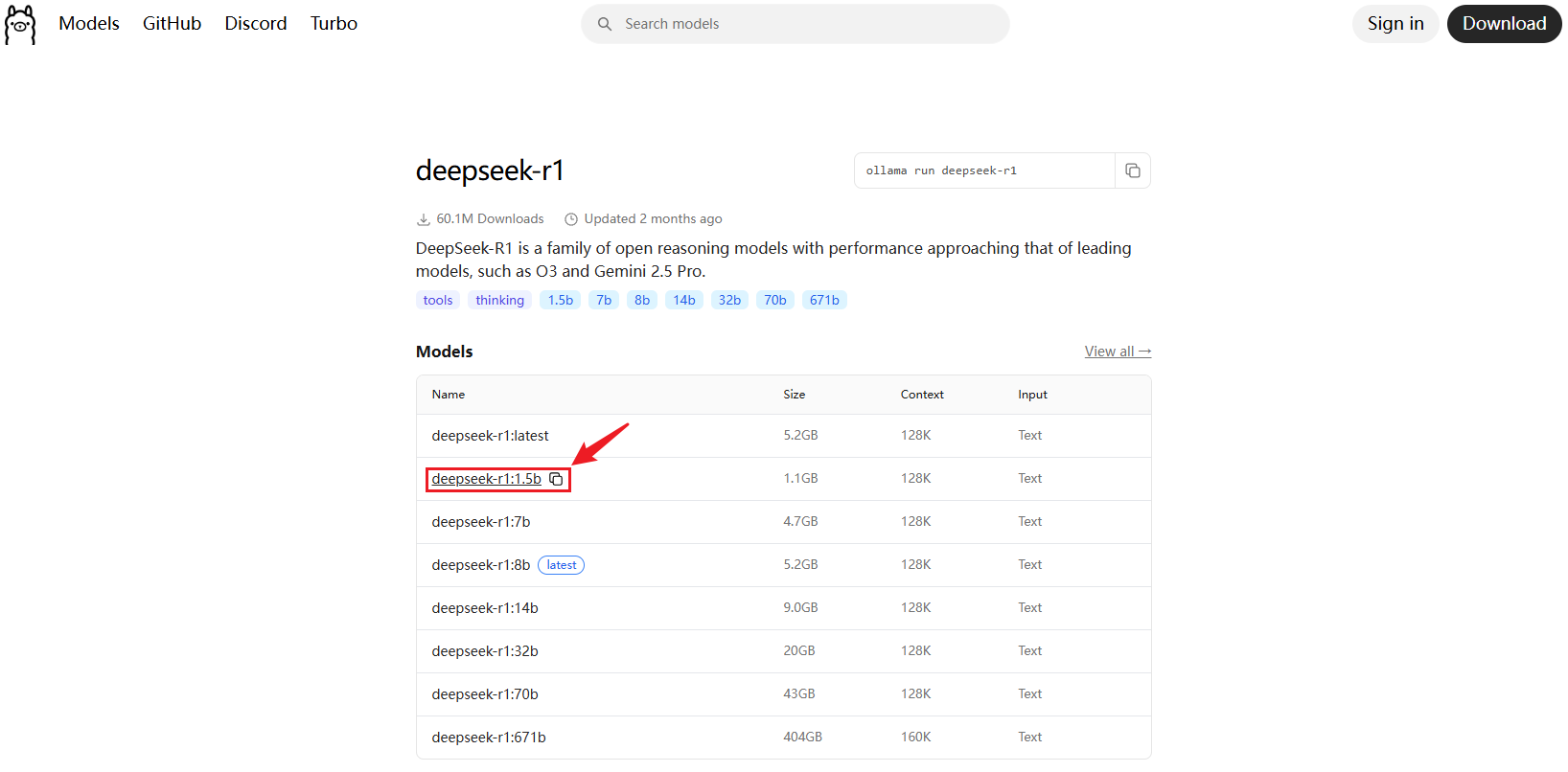
ollama pull deepseek-r1:1.5b需要下载的模型,可去官网Ollama上去查看,点击左上角的Models,点击需要下载的模型
复制模型名称
(4)模型运行
命令行交互
# 启动模型交互
ollama run deepseek-r1:1.5b# 带参数运行
ollama run deepseek-r1:1.5b "你好,介绍一下你自己"API调用
# 使用curl调用API
curl http://localhost:11434/api/generate -d '{"model": "deepseek-r1:1.5b","prompt": "你好世界","stream": false
}'(5)Python集成
安装依赖
pip install ollama基本使用示例
import ollama# 简单对话
response = ollama.chat(model='llama2', messages=[{'role': 'user','content': '你好,介绍一下Python',},
])
print(response['message']['content'])# 流式输出
response = ollama.generate(model='llama2',prompt='写一首关于春天的诗',stream=True,
)for chunk in response:print(chunk['response'], end='', flush=True)高级应用
import ollama
import jsonclass OllamaClient:def __init__(self, model='llama2'):self.model = modeldef chat(self, messages):"""聊天对话"""response = ollama.chat(model=self.model, messages=messages)return response['message']['content']def generate(self, prompt, **kwargs):"""文本生成"""response = ollama.generate(model=self.model, prompt=prompt, **kwargs)return response['response']def embed(self, text):"""文本嵌入"""response = ollama.embeddings(model=self.model, prompt=text)return response['embedding']# 使用示例
client = OllamaClient('llama2')
result = client.chat([{'role': 'user', 'content': '什么是人工智能?'}
])
print(result)5. Ollama 后台部署方式
Ollama 服务 (ollama serve) 通常在安装后会自动作为系统服务启动并后台运行,但了解手动管理方式也很重要。
(1)默认后台运行
安装完成后,Ollama 服务通常已经启动。您可以使用以下命令检查其状态:
# 对于使用 systemd 的系统 (如 Ubuntu, CentOS)
sudo systemctl status ollama(2)使用 nohup 手动后台启动(不推荐长期使用)
如果您需要手动启动 ollama serve 并让它在终端关闭后继续运行,可以使用 nohup:
nohup ollama serve > ollama.log 2>&1 &这会将服务在后台启动,并将输出日志保存到 ollama.log 文件中。
6. Ollama 同时运行多个模型
Ollama 的现代版本(如 0.2 及以上)支持同时加载和运行多个不同的模型,以及处理单个模型的并发请求。
(1)配置环境变量
要启用多模型并行,需要在启动 ollama serve 时设置以下环境变量:
OLLAMA_MAX_LOADED_MODELS:设置可以同时加载到内存中的模型最大数量。OLLAMA_NUM_PARALLEL:设置单个模型可以同时处理的请求数量。
(2)示例配置(Docker 方式)
以下命令启动一个 Docker 容器,并配置它可以同时加载最多 2 个模型,每个模型可以并行处理 3 个请求:
docker run -d \-v ollama:/root/.ollama \-p 11434:11434 \-e OLLAMA_MAX_LOADED_MODELS=2 \-e OLLAMA_NUM_PARALLEL=3 \--name ollama \ollama/ollama注意: 同时运行多个模型会显著增加内存(RAM)消耗。请确保您的系统有足够的资源。
(3)运行多个模型
配置好环境变量并启动服务后,就可以像平常一样运行不同的模型,Ollama 会根据配置和系统资源自动管理模型的加载和卸载。
7. Ollama 的管理命令
Ollama 提供了丰富的命令行接口 (CLI) 来方便地管理模型和服务。
常用管理命令列表
ollama serve:启动 Ollama 服务(通常后台自动运行)。ollama pull <model_name>:从 Ollama 库下载指定模型。ollama run <model_name>:运行指定模型,可以进行交互式对话。ollama ls:列出本地已安装的所有模型。ollama ps:查看当前正在运行的模型。ollama show <model_name>:显示模型的详细信息。ollama cp <source_model> <destination_model>:复制模型。ollama rm <model_name>:删除本地指定模型。ollama create <model_name> -f <Modelfile>:使用Modelfile创建自定义模型。
下载模型:
ollama pull deepseek-r1:1.5b列出模型:
ollama ls注:ollama list 和 ollama ls 是完全相同的命令
运行模型(交互式):
ollama run deepseek-r1:1.5b
# 进入交互模式后,可以输入问题,例如:
# >>> 你好,deepseek!
# <<< 你好!很高兴见到你!有什么我可以帮你的吗?
# 使用 /bye 或 Ctrl+C 退出交互模式查看运行中的模型:
ollama ps显示模型信息:
ollama show deepseek-r1:1.5b删除模型:
ollama rm deepseek-r1:1.5b