基础文本处理工具与文本三剑客其二sed awk
目录
一、基础文本处理工具 (cut, sort, uniq, tr)
1.1 cut - 按列提取文本
1.2 sort - 排序
1.3 uniq - 去除连续的重复行
1.4 tr - 字符替换/删除/压缩
二、sed - 流编辑器
2.1 sed命令选项
2.2 删除符合条件的文本(d)
2.3 替换符合条件的文本
2.4 迁移符合条件的文本
2.5 使用脚本编辑文件
三、awk - 文本报告生成器
1. 基本结构
2. 内置变量
3. 示例
4. 高级功能
四、总结与对比
五、经典组合示例
1. 统计当前主机每个IP的连接数
2.统计当前主机的连接状态
3.查看当前登录用户
4.查看登录过系统的用户
5. 统计/etc/passwd中每种Shell的数量
6. 提取日志中失败次数超过3次的IP
总结
一、基础文本处理工具 (cut, sort, uniq, tr)
这些工具擅长处理结构化的行和列,通常组合使用。
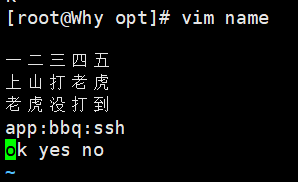
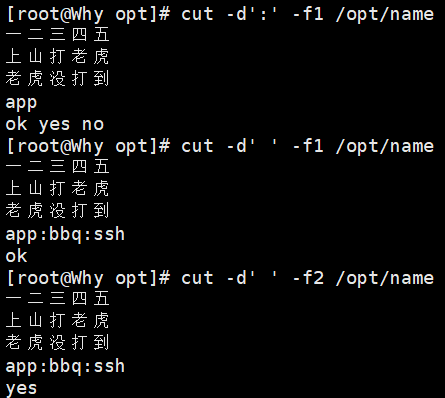
1.1 cut - 按列提取文本
-
功能:从每行中提取指定的字段、字节或字符。
-
常用选项:
-
-d:指定分隔符(默认是TAB) -
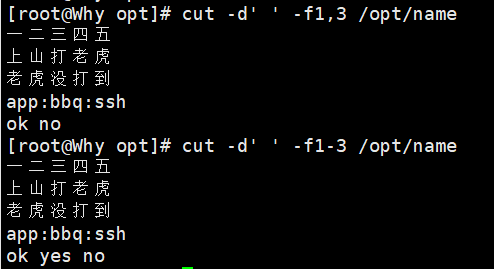
-f:指定要提取的字段(列号) -
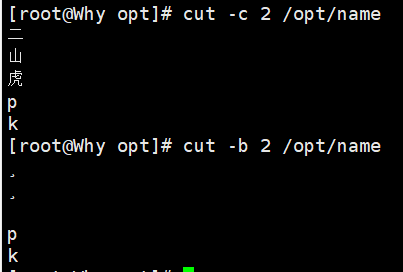
-c:按字符位置提取(适用于中文) -
-b:按字节截取
-
-
示例:
bash
cut -d: -f1,3 /etc/passwd # 提取第1列(用户)和第3列(UID) cut -d':' -f1-3 /etc/passwd # 截取第1到3列 cut -c2-5 filename # 提取每行的第2到第5个字符
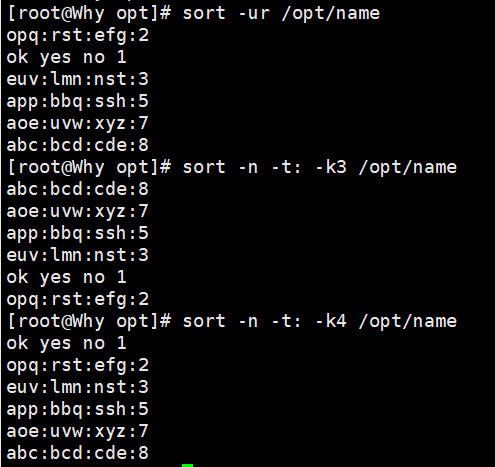
1.2 sort - 排序
-
功能:对文本行进行排序。
-
常用选项:
-
-n:按数值大小排序 -
-r:逆序排序 -
-t:指定分隔符 -
-k:指定按哪一列排序 -
-u:去重(等同于uniq) -
-o:输出到文件
-
-
示例:
bash
sort -n -t: -k3 /etc/passwd # 按第3列(UID)数值升序排序 sort -ur filename # 去重并逆序输出
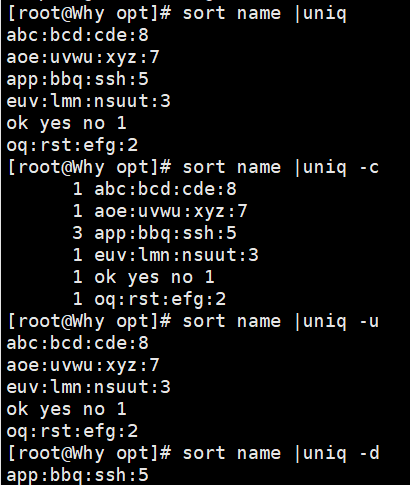
1.3 uniq - 去除连续的重复行
-
注意:只能去除相邻的重复行,因此常与
sort联用。 -
常用选项:
-
-c:统计重复次数 -
-d:仅显示重复的行 -
-u:仅显示不重复的行
-
-
示例:
bash
sort file.txt | uniq -c # 统计每行出现的次数 sort file.txt | uniq -u # 仅显示唯一的行 sort file.txt | uniq -d # 仅显示重复的行 sort fruit.txt | uniq # 全局去重
- 实战 查看登录用户
示例一
who | awk '{print $1}'| uniq
![]()
示例二
查看登陆过系统的用户
last | awk '{print $1}' | sort | uniq | grep -v "^$" | grep -v wtmp

last查看登录系统 重启 关机 注销 审计用
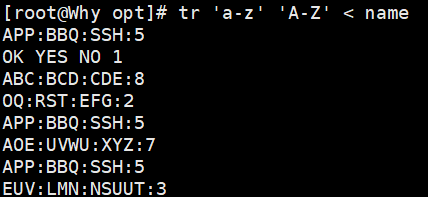
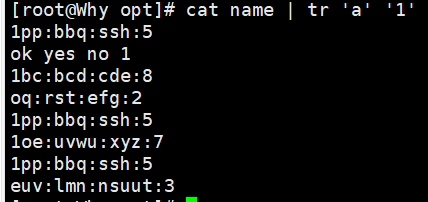
1.4 tr - 字符替换/删除/压缩
-
功能:对来自标准输入的字符进行替换、删除或压缩。主要用于 单个字符处理,不适合字段级别。
-
常用选项:
-
-d:删除字符 -
-s:压缩连续重复的字符,只保留一个
-
-
示例:
bash
echo "hello" | tr 'a-z' 'A-Z' # 转换为大写:HELLO cat name | tr 'apple' 'APPLE' #替换是一一对应的字母的替换 tr 'a' '/' < fruit.txt # 替换 a -> / 多个字符替换成一个 echo "hello" | tr -d 'l' # 删除所有 'l':heo tr -d '\n' < fruit.txt # 删除换行符 echo "heeello" | tr -s 'e' # 压缩连续 'e':helo
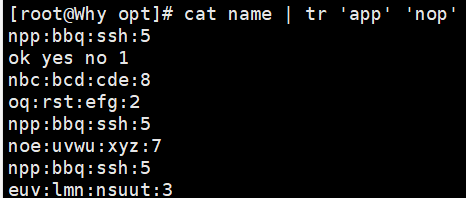
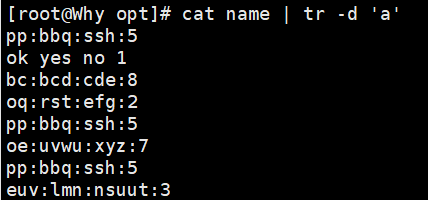

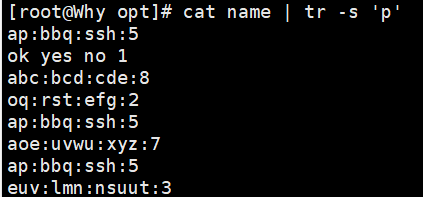
二、sed - 流编辑器
原理:逐行读取文本到“模式空间”,执行编辑命令后输出,原文件不变(除非用 -i)。
2.1 sed命令选项
1. 常用选项
-
-n:禁止默认输出(常与p命令联用) -
-e:执行多个编辑命令 -
-i[后缀]:直接修改文件(可选备份原文件) -
-r:启用扩展正则表达式
2. 常用命令
-
p:打印 -
d:删除 -
s:替换(最常用) -
a:在行后追加 -
i:在行前插入 -
c:替换整行
3. 示例
bash
sed -n '3p' demo //输出第 3 行
sed -n '3,5p' demo //输出 3~5 行
sed -n 'p;n' demo //输出所有奇数行,n 表示读入下一行资料
sed -n 'n;p' demo //输出所有偶数行,n 表示读入下一行资料
sed -n '2~2p' demo //第二行开始输出所有偶数行
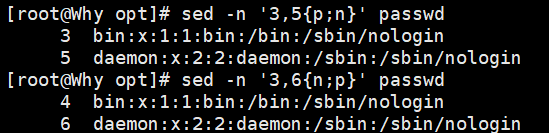
sed -n '1,5{p;n}' demo //输出第 1~5 行之间的奇数行(第 1、3、5 行)
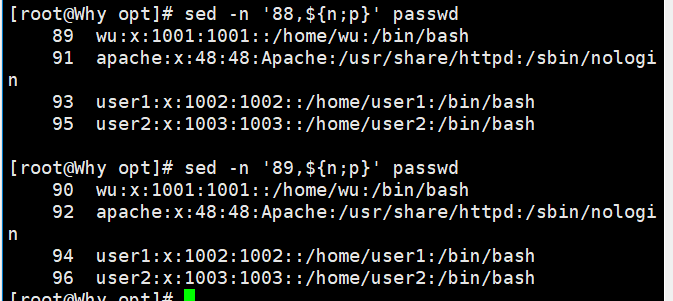
sed -n '10,${n;p}' demo //输出第 10 行至文件尾之间的偶数行,在执行“sed -n‘10,${n;p}’demo”命令时,读取的第 1 行是文件的第 10 行,读取的第 2 行是文件的第 11 行,依此类推,所以输出的偶数行是文件的第 11 行、13 行直至文件结尾, 其中包括空行。
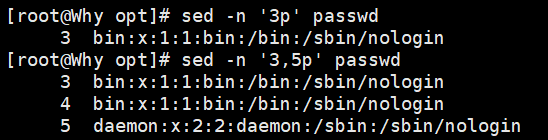
sed 命令结合正则表达式时,格式略有不同,正则表达式以“/”包围
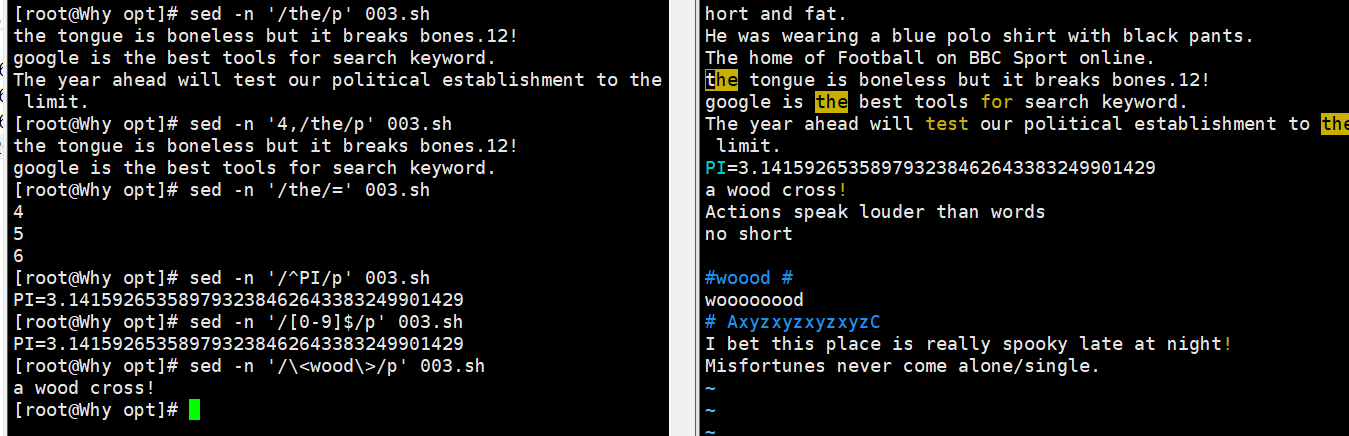
sed -n '/the/p' demo 词边界 //输出包含the 的行sed -n '4,/the/p' demo //输出从第 4 行至第一个包含 the 的行 sed -n '/the/=' demo //输出包含the 的行所在的行号,等号(=)用来输出行号 4 5 6 sed -n '/^PI/p' demo //输出以PI 开头的行 sed -n '/[0-9]$/p' demo //输出以数字结尾的行 sed -n '/\<wood\>/p' demo //输出包含单词wood 的行,\代表单
2.2 删除符合条件的文本(d)
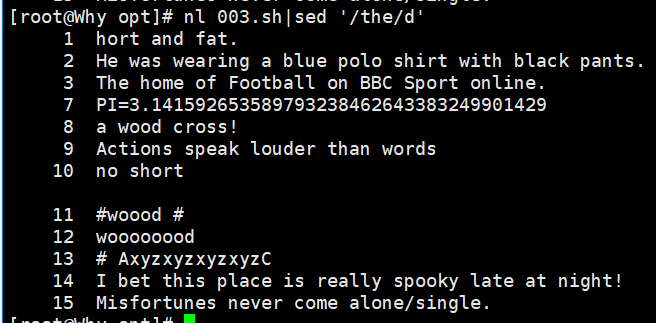
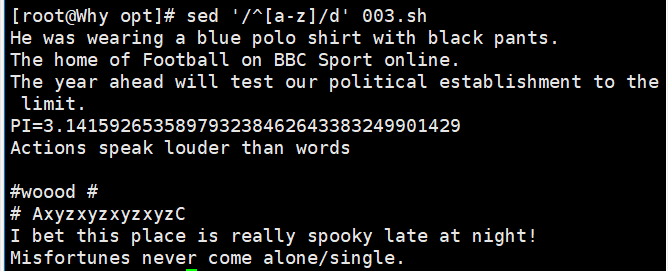
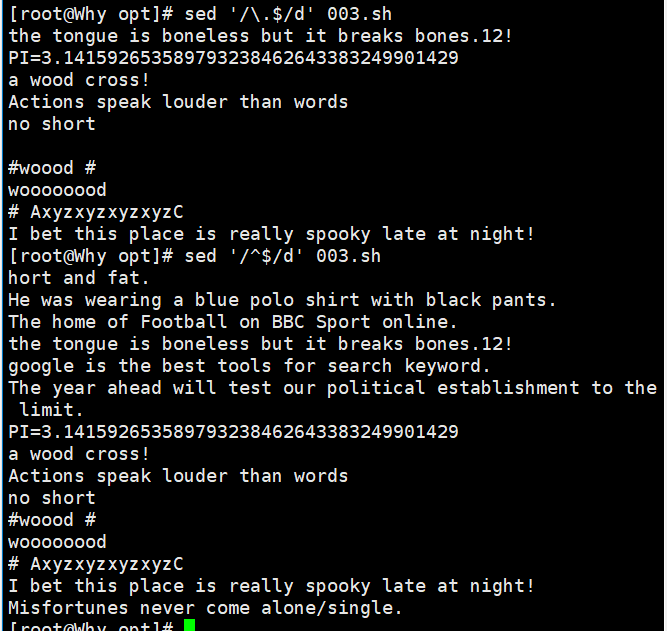
因为后面的示例还需要使用测试文件 demo,所以在执行删除操作之前需要先将测试文件备份。以下示 例分别演示了 sed 命令的几种常用删除用法。 下面命令中 nl 命令用于计算文件的行数,结合该命令可以更加直观地查看到命令执行的结果。
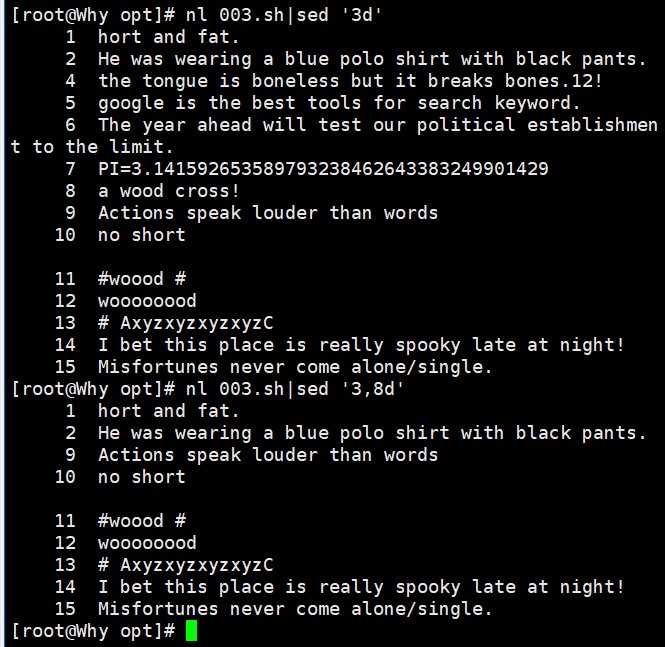
nl demo | sed '3d' //删除第 3 行 nl demo | sed '3,5d' //删除第 3~5 行 nl demo |sed '/cross/d' //删除匹配所有包含 cross 的行。 sed '/^[a-z]/d' demo //删除以小写字母开头的行 sed '/\.$/d' demo //删除以"."结尾的行 sed '/^$/d' demo //删除所有空行
2.3 替换符合条件的文本
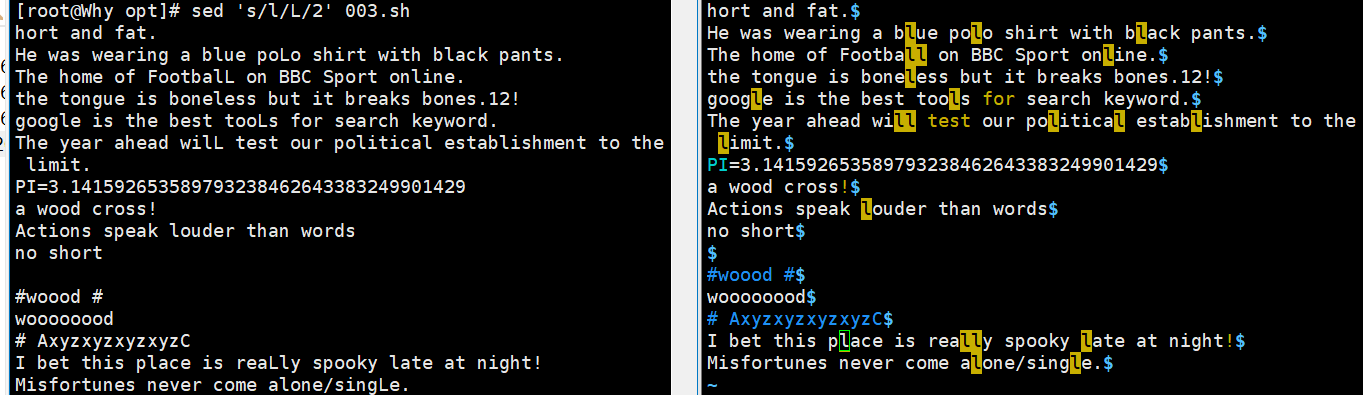
在使用 sed 命令进行替换操作时需要用到 s(字符串替换)、c(整行/整块替换)、y(字符转换) 命令选项,常见的用法如下所示。
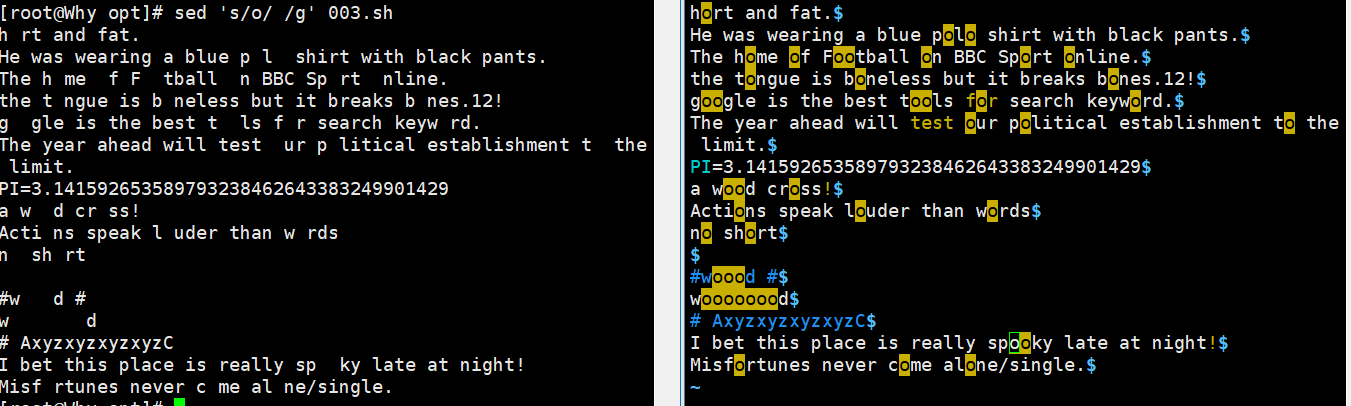
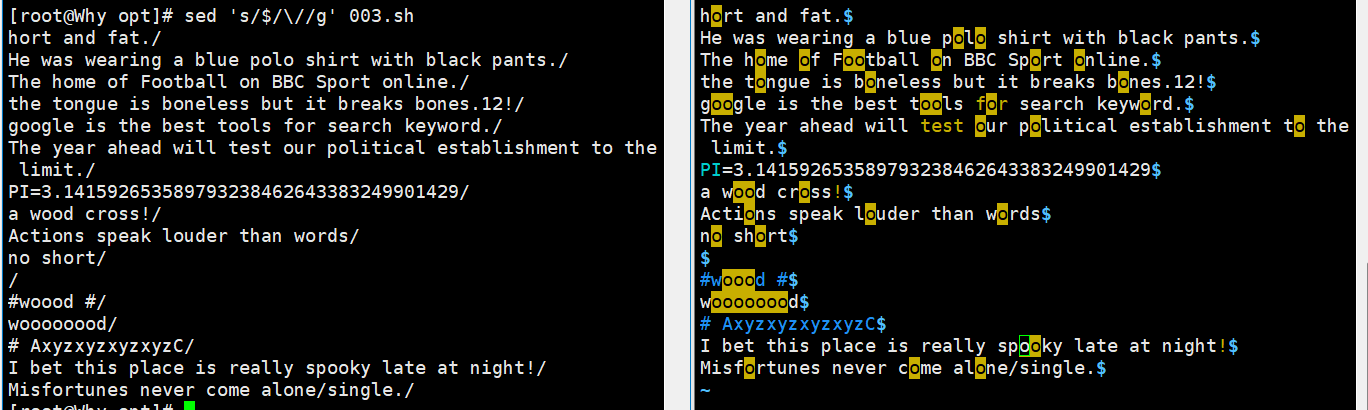
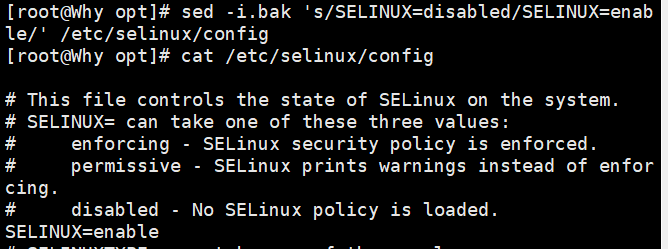
sed 's/the/THE/' demo //将每行中的第一个the 替换为 THE sed 's/l/L/2' demo //将每行中的第 2 个 l 替换为L sed 's/the/THE/g' demo //将文件中的所有the 替换为 THE sed 's/o//g' demo //将文件中的所有o 删除(替换为空串) sed 's/^/#/' demo //在每行行首插入#号 sed '/the/s/^/#/' demo //在包含the 的每行行首插入#号 sed 's/$/EOF/' demo //在每行行尾插入字符串EOF sed '3,5s/the/THE/g' demo //将第 3~5 行中的所有 the 替换为THE sed '/the/s/o/O/g' demo //将包含the 的所有行中的 o 都替换为 O sed -i.bak 's/SELINUX=disabled/SELINUX=enable/' /etc/selinux/config





2.4 迁移符合条件的文本
在使用 sed 命令迁移符合条件的文本时,常用到以下参数
H:复制到剪贴板;
g、G:将剪贴板中的数据覆盖/追加至指定行;
w:保存为文件;
r:读取指定文件;
a:追加指定内容。插入具体操作方法如下所示。
I,i 忽略大小写
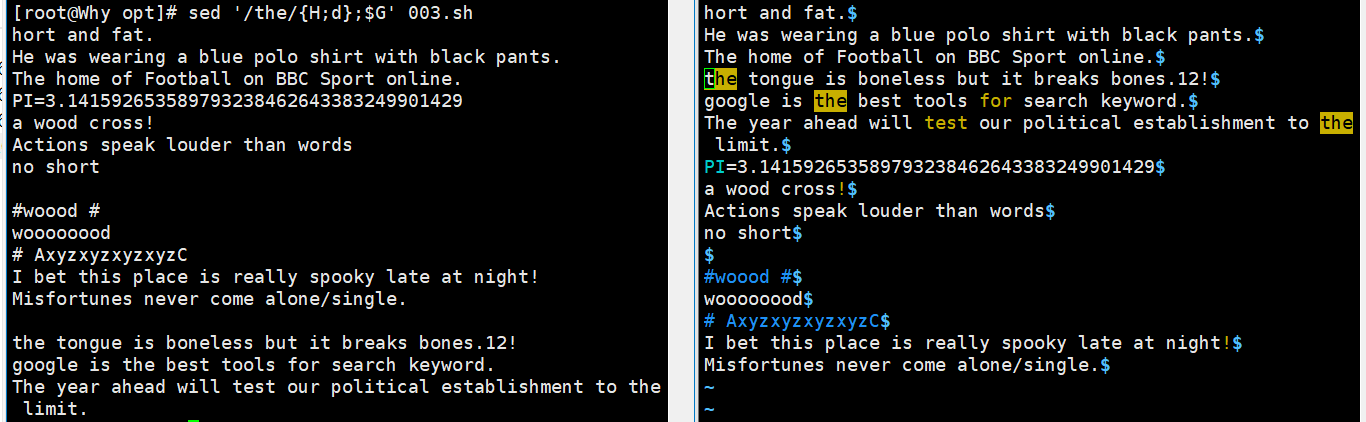
sed '/the/{H;d};$G' demo //将包含the 的行迁移至文件末尾,{;}用于多个操作
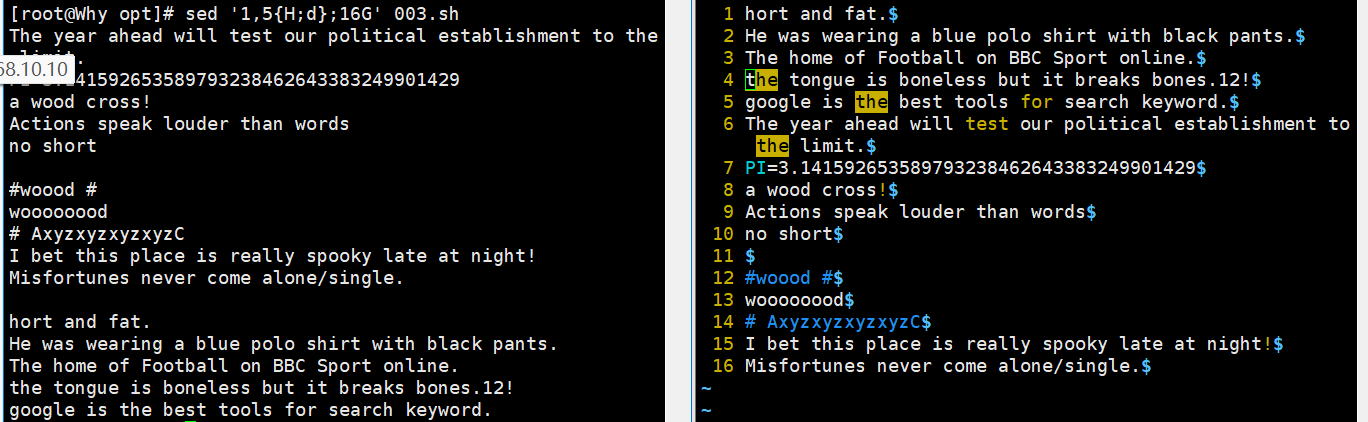
sed '1,5{H;d};17G' demo //将第 1~5 行内容转移至第 17 行后
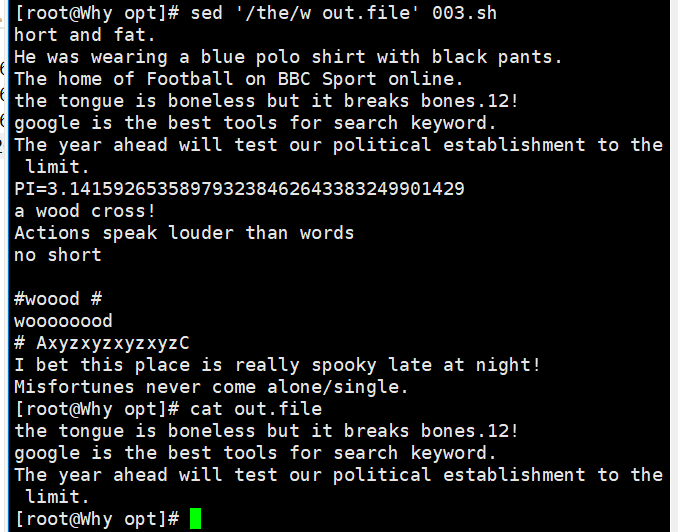
sed '/the/w out.file' demo //将包含the 的行另存为文件 out.file
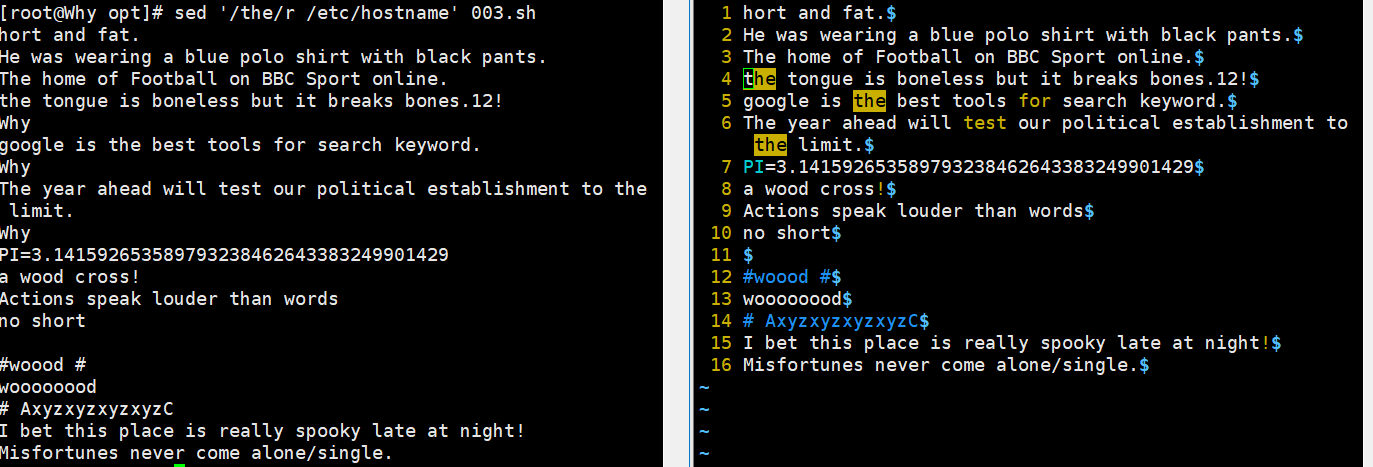
sed '/the/r /etc/hostname' demo //将文件/etc/hostname 的内容添加到包含 the 的每行以后
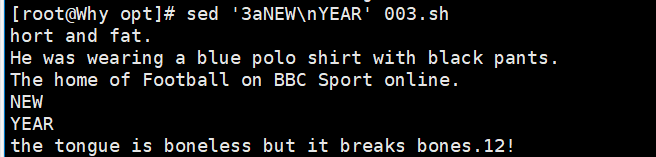
sed '3aNew' demo //在第 3 行后插入一个新行,内容为New
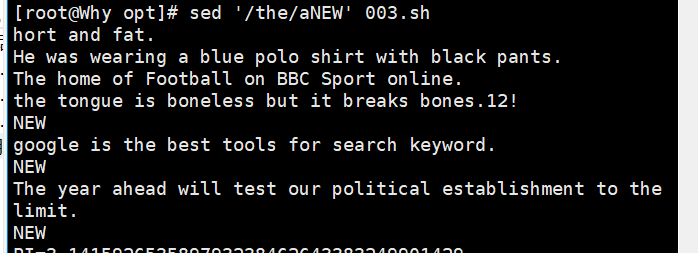
sed '/the/aNew' demo //在包含the 的每行后插入一个新行,内容为New
sed '3aNew1\nNew2' demo //在第 3 行后插入多行内容,中间的\n 表示换行

2.5 使用脚本编辑文件
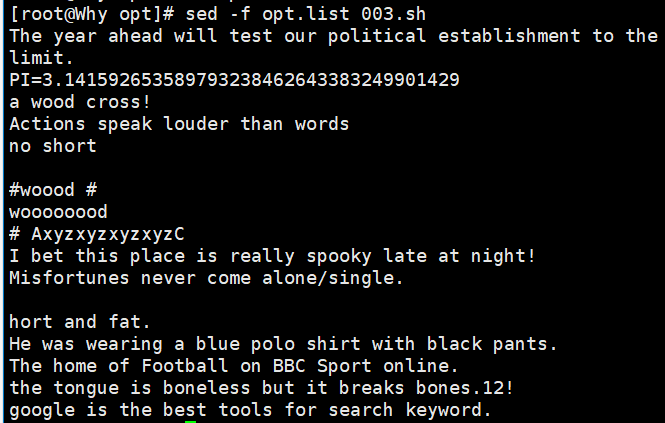
使用 sed 脚本将多个编辑指令存放到文件中(每行一条编辑指令),通过“-f”选项来调用。 例如执行以下命令即可将第 1~5 行内容转移至第 16 行后
sed '1,5{H;d};16G' demo //将第 1~5 行内容转移至第 16 行后
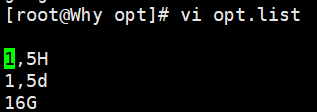
以上操作可以改用脚本文件方式:
vi opt.list
1,5H
1,5d
16G
sed -f opt.list demo
三、awk - 文本报告生成器
工作原理:逐行扫描文件,按字段处理(默认以空格或TAB分隔)。
1. 基本结构
bash
awk 'BEGIN{预处理} pattern{动作} END{后处理}' 文件名
-
BEGIN:在处理前执行一次 -
pattern:模式匹配(如/root/或NR==1) -
END:在处理后执行一次
2. 内置变量
-
$0:整行内容 -
$1, $2, ...:第1、2…个字段 -
NF:当前行的字段数 -
NR:当前行号 -
FS:输入字段分隔符(默认空格) -
OFS:输出字段分隔符(默认空格)
3. 示例
bash
awk -F: '{print $1,$3}' /etc/passwd # 打印用户名和UID
awk 'NR==2{print}' file.txt # 打印第2行
awk '/root/{print $0}' /etc/passwd # 打印包含 root 的行
awk 'BEGIN{FS=":";OFS="--"}{print $1,$3}' /etc/passwd # 修改输入输出分隔符
awk '{if($3>1000) print $1}' /etc/passwd # 打印UID大于1000的用户名
4. 高级功能
-
数组:用于统计(如统计IP出现次数)
-
循环:
for、while -
内置函数:
length、substr、gsub等 -
调用Shell命令:通过管道
| "command"
四、总结与对比
| 工具 | 特点 | 适用场景 |
|---|---|---|
cut | 按列提取 | 提取特定字段(如用户名、UID) |
sort | 排序 | 对行或列进行排序 |
uniq | 去重(需先排序) | 统计重复行 |
tr | 字符操作 | 大小写转换、删除字符、压缩重复 |
sed | 流编辑,按行处理 | 文本替换、删除、插入 |
awk | 按字段处理,支持编程 | 复杂文本分析、统计、报表生成 |
五、经典组合示例
1. 统计当前主机每个IP的连接数
ss -nt | tr -s ' ' | cut -d ' ' -f5 | cut -d: -f1 | sort | uniq -c

ss -nt
ss:查看 socket 连接
-n:不解析服务名,直接显示端口号(避免 http 变成 80 之类的)
-t:只显示 TCP 连接
tr -s " "
把多个空格压缩成一个,方便后续 cut。
输出变成规则的单空格分隔。
cut -d " " -f5
以空格为分隔符,取第 5 列(即 对端地址:端口)
cut -d ":" -f1
以冒号分隔,取第 1 段(只要 对端 IP,去掉端口
sort
排序,保证相同的 IP 连续排列。
uniq -c
统计重复行数量(即同一个 IP 出现多少次
2.统计当前主机的连接状态
ss -nta | grep -v '^State' | cut -d" " -f1 | sort | uniq -c

3.查看当前登录用户
who | awk '{print $1}' | uniq
4.查看登录过系统的用户
last | awk '{print $1}' | sort | uniq | grep -v "^$" | grep -v wtmp

5. 统计/etc/passwd中每种Shell的数量
bash
awk -F: '{print $NF}' /etc/passwd | sort | uniq -c
6. 提取日志中失败次数超过3次的IP
bash
awk '/Failed password/{ip[$11]++} END{for(i in ip) if(ip[i]>3) print i, ip[i]}' /var/log/secure
总结
Cut/Sort/Uniq/Tr:基础文本处理工具,分别用于截取字段、排序、去重、字符替换,常组合使用于数据清洗和统计。
SED:流编辑器,用于文本替换、删除、插入,支持正则表达式,适合批量文本处理。
AWK:擅长字段处理、统计、格式化输出,支持条件判断、循环、数组,常用于日志分析、数据提取。