【Doris入门】Doris数据表模型:聚合模型(Aggregate Key Model)详解
目录
前言
1 聚合模型概述
1.1 什么是聚合模型
1.2 聚合模型的核心特性
1.3 聚合模型与其他模型的对比
2 聚合模型的实现原理
2.1 数据聚合流程
2.2 聚合模型的存储结构
2.3 聚合模型的查询优化
3 聚合函数详解
3.1 常用聚合函数
3.2 聚合函数使用示例
3.2.1 SUM聚合函数
3.2.2 REPLACE聚合函数
3.2.3 MAX和MIN聚合函数
3.3 高级聚合函数
3.3.1 HLL_UNION聚合函数
3.3.2 BITMAP_UNION聚合函数
4 聚合模型的使用场景
4.1 选择聚合模型的情况
4.2 不适合聚合模型的情况
5 聚合模型的性能优化
5.1 建表优化
5.1.1 合理选择Key列
5.1.2 合理设置分区策略
5.2 查询优化
5.2.1 利用预聚合结果
5.2.2 优化聚合查询
5.3 写入优化
5.3.1 批量写入
5.3.2 合理设置导入批次
5.3.3 控制并发写入
6 总结
前言
在当今大数据时代,数据仓库和实时分析系统面临着海量数据的存储和查询挑战。Apache Doris作为一款高性能的分布式分析型数据库,提供了多种数据模型来满足不同的业务场景需求。其中,聚合模型(Aggregate Key Model)是Doris中最为核心和特色的数据模型之一,它通过预聚合机制大幅提升了查询性能,特别适合报表分析、统计汇总等场景。
1 聚合模型概述
1.1 什么是聚合模型
聚合模型(Aggregate Key Model)是Apache Doris中的一种数据模型,其主要特点是根据Key列对数据进行聚合操作。在建表时,通过AGGREGATE KEY关键字指定聚合模型,并明确指定Key列用于聚合Value列。聚合模型的核心思想是在数据写入时就进行预聚合,将相同Key的数据按照指定的聚合函数进行合并,只存储聚合后的结果。这种方式极大地减少了查询时的计算量,提升了查询性能。
1.2 聚合模型的核心特性
聚合模型具有以下几个核心特性:
- 预聚合机制:在数据导入时就会进行聚合操作,减少查询时的计算量
- 节省存储空间:只存储聚合后的数据,而不是原始数据
- 提升查询性能:聚合查询时无需再次计算,直接读取预聚合结果
- 支持多种聚合函数:包括SUM、REPLACE、MAX、MIN等常用聚合函数
- 灵活的聚合策略:可以根据业务需求为不同的Value列指定不同的聚合方式
1.3 聚合模型与其他模型的对比
Doris提供了三种主要的数据模型:
- 明细模型(Duplicate Key Model)
- 聚合模型(Aggregate Key Model)
- 主键模型(Unique Key Model)
它们的区别如下:
| 特性 | 明细模型 | 主键模型 | 聚合模型 |
| 数据处理 | 保留所有原始数据 | 按主键去重,保留最新数据 | 按Key列聚合 |
| Key列约束 | 无唯一约束,Key列可重复 | Key列必须唯一 | Key列必须唯一 |
| 更新支持 | 不支持更新 | 支持更新 | 部分支持更新 |
| 删除支持 | 部分支持 | 支持删除 | 不支持删除 |
| 存储空间 | 较大 | 中等 | 较小 |
| 查询灵活性 | 高,支持任意维度查询 | 中等 | 低,受聚合方式限制 |
| 查询性能 | 中等 | 较高 | 最高(聚合查询) |
| 适用场景 | 需要保留原始数据的场景 | 需要数据更新的场景 | 需要预聚合统计的场景 |
2 聚合模型的实现原理
2.1 数据聚合流程
- 聚合模型的数据聚合流程可以分为三个主要阶段:

数据导入阶段:
- 原始数据按批次导入系统
- 系统按照Key列对数据进行分组
- 对每个分组按照指定的聚合函数进行计算
- 生成聚合后的数据版本
后台文件合并阶段(Compaction):
- 系统定期合并多个版本的数据文件
- 减少数据冗余,优化存储结构
- 提升查询性能,降低存储成本
查询阶段:
- 系统接收查询请求
- 直接读取已经聚合好的数据
- 无需再次进行聚合计算
- 返回查询结果
2.2 聚合模型的存储结构
- 聚合模型的存储结构与其他模型有显著不同:
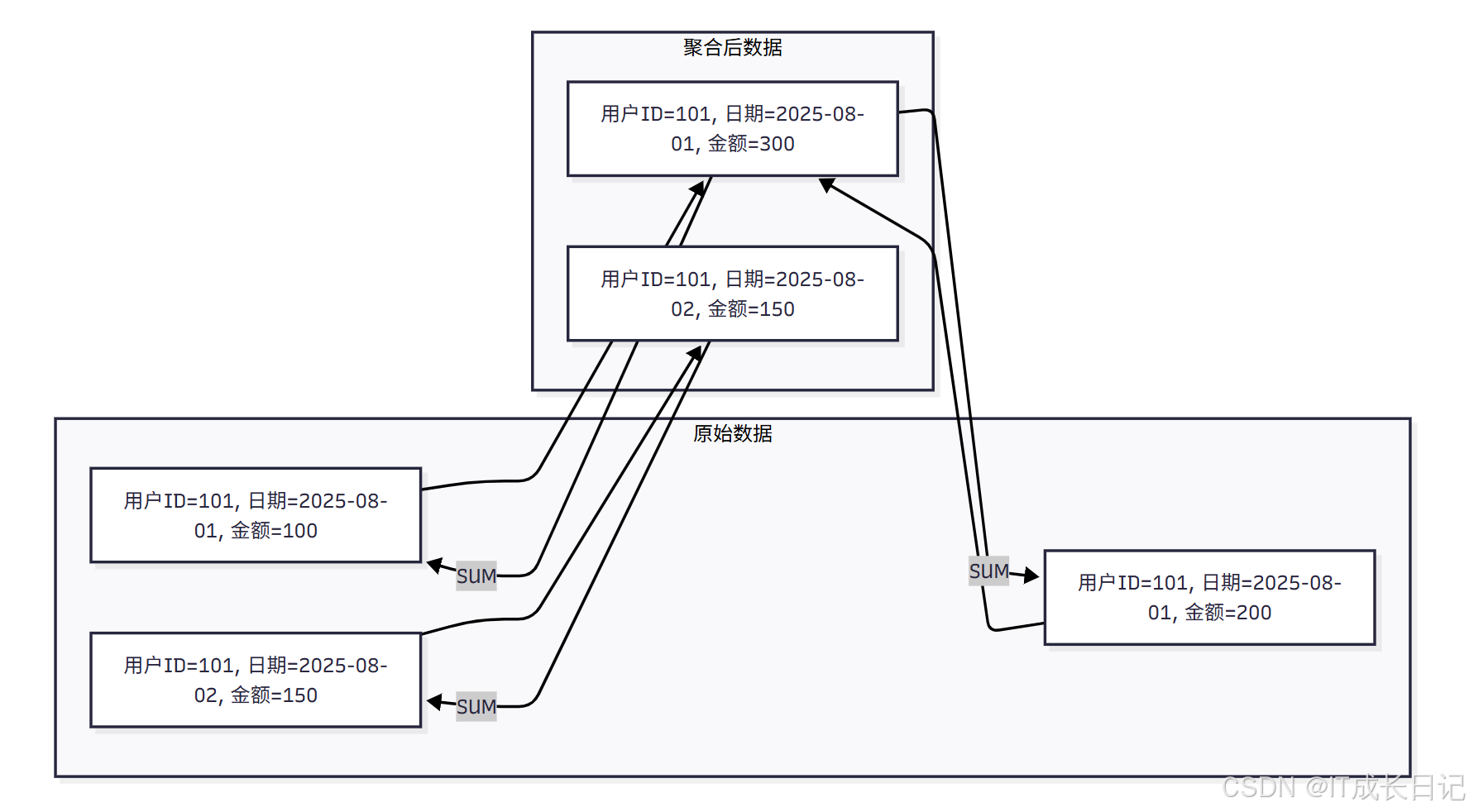
存储特点:
- 按Key聚合:相同Key的数据会被合并成一条记录
- 聚合函数应用:Value列按照指定的聚合函数进行计算
- 版本管理:每个导入批次生成一个数据版本
- 定期合并:后台进程定期合并多个版本
2.3 聚合模型的查询优化
- 聚合模型在查询时具有天然的性能优势:
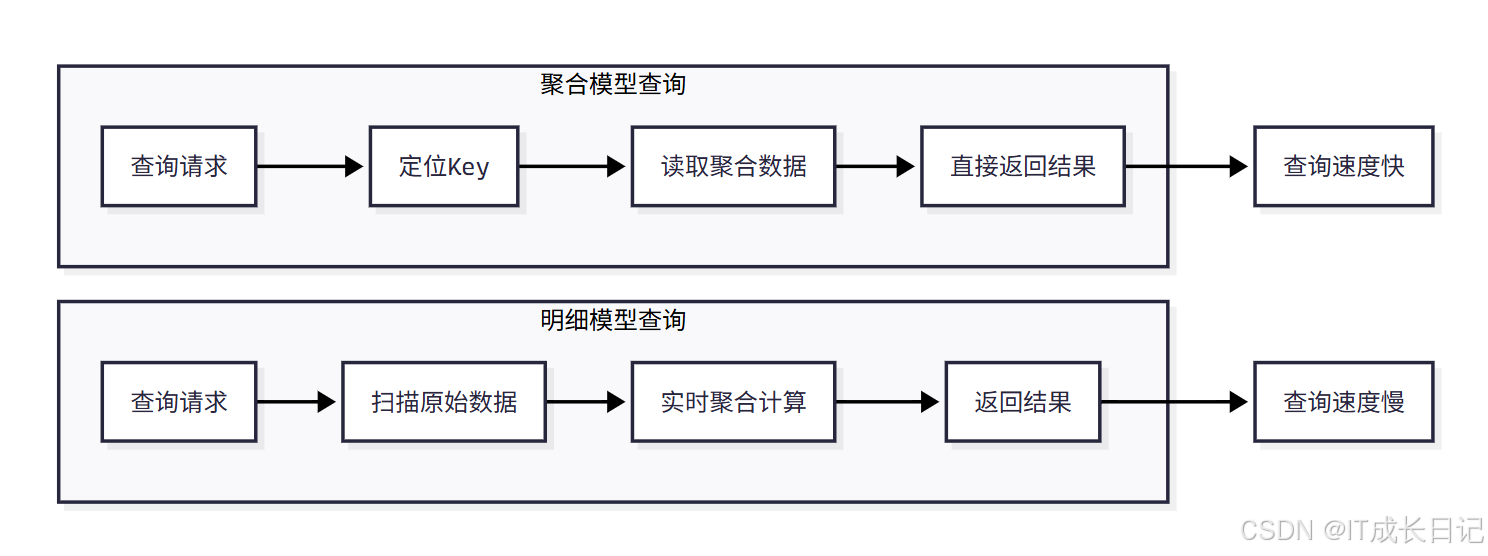
优化优势:
- 减少数据扫描量:只读取聚合后的数据,而不是原始数据
- 避免重复计算:聚合操作在写入时已经完成
- 更好的压缩率:聚合后的数据重复性更低,压缩效果更好
- 索引友好:聚合后的数据更适合建立索引
3 聚合函数详解
3.1 常用聚合函数
- 聚合模型支持多种聚合函数,每种函数都有其特定的应用场景:
| 聚合函数 | 描述 | 适用场景 | 示例 |
| SUM | 求和,多行的Value进行累加 | 数值型字段的汇总 | 订单金额、访问量统计 |
| REPLACE | 替代,下一批数据中的Value会替换之前导入过的行中的Value | 最新状态、最新信息 | 订单状态、用户最后登录时间 |
| MAX | 保留最大值 | 最大值统计 | 最高价格、最大响应时间 |
| MIN | 保留最小值 | 最小值统计 | 最低价格、最小响应时间 |
| REPLACE_IF_NOT_NULL | 非空值替换,与REPLACE的区别在于对null值不做替换 | 部分列更新 | 订单更新、字段更新 |
| HLL_UNION | HLL类型的列的聚合方式,通过HyperLogLog算法聚合 | 去重统计 | UV统计、独立访客统计 |
| BITMAP_UNION | BITMAP类型的列的聚合方式,进行位图的并集聚合 | 标签统计 | 用户标签交集、并集 |
3.2 聚合函数使用示例
3.2.1 SUM聚合函数
-- 创建使用SUM聚合的表
CREATE TABLE ads_db.sales_summary(user_id BIGINT NOT NULL,sale_date DATE NOT NULL,product_id BIGINT,category VARCHAR(50) REPLACE DEFAULT "", -- 为 category 指定 REPLACE 聚合类型sale_amount DECIMAL(10,2) SUM DEFAULT "0",sale_quantity INT SUM DEFAULT "0"
) AGGREGATE KEY(user_id, sale_date, product_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 1
PROPERTIES ("replication_num" = "1" -- 将副本数设置为与可用后端节点数一致
);-- 插入数据INSERT INTO ads_db.sales_summary VALUES
(101, '2025-08-01', 1001, '电子产品', 1000.00, 2),
(101, '2025-08-01', 1001, '电子产品', 500.00, 1),
(101, '2025-08-02', 1002, '服装', 800.00, 1);-- 查询结果
SELECT * FROM ads_db.sales_summary;- 查询结果:
mysql> SELECT * FROM ads_db.sales_summary;
+---------+------------+------------+--------------+-------------+---------------+
| user_id | sale_date | product_id | category | sale_amount | sale_quantity |
+---------+------------+------------+--------------+-------------+---------------+
| 101 | 2025-08-01 | 1001 | 电子产品 | 1500.00 | 3 |
| 101 | 2025-08-02 | 1002 | 服装 | 800.00 | 1 |
+---------+------------+------------+--------------+-------------+---------------+
2 rows in set (0.37 sec)mysql> 3.2.2 REPLACE聚合函数
-- 创建使用REPLACE聚合的表
CREATE TABLE ads_db.user_profile(user_id BIGINT NOT NULL,update_date DATE NOT NULL,last_login_time DATETIME REPLACE DEFAULT "1970-01-01 00:00:00",user_level TINYINT REPLACE DEFAULT "1",last_ip VARCHAR(64) REPLACE DEFAULT "0.0.0.0"
) AGGREGATE KEY(user_id, update_date)
DISTRIBUTED BY HASH(user_id) BUCKETS 1
PROPERTIES ("replication_num" = "1" -- 将副本数设置为与可用后端节点数一致
);-- 插入数据
INSERT INTO ads_db.user_profile VALUES
(101, '2025-08-01', '2025-08-01 10:00:00', 2, '192.168.1.100'),
(101, '2025-08-01', '2025-08-01 11:00:00', 3, '192.168.1.101'),
(101, '2025-08-02', '2025-08-02 09:00:00', 3, '192.168.1.102');-- 查询结果
SELECT * FROM ads_db.user_profile;- 查询结果:
mysql> select *from ads_db.user_profile;
+---------+-------------+---------------------+------------+---------------+
| user_id | update_date | last_login_time | user_level | last_ip |
+---------+-------------+---------------------+------------+---------------+
| 101 | 2025-08-01 | 2025-08-01 11:00:00 | 3 | 192.168.1.101 |
| 101 | 2025-08-02 | 2025-08-02 09:00:00 | 3 | 192.168.1.102 |
+---------+-------------+---------------------+------------+---------------+
2 rows in set (0.25 sec)mysql> 3.2.3 MAX和MIN聚合函数
-- 创建使用MAX和MIN聚合的表
CREATE TABLE ads_db.performance_metrics(server_id BIGINT NOT NULL,metric_date DATE NOT NULL,metric_name VARCHAR(50),cpu_usage DOUBLE MAX DEFAULT "0",memory_usage DOUBLE MIN DEFAULT "100",response_time INT MAX DEFAULT "0"
)AGGREGATE KEY(server_id, metric_date, metric_name)
DISTRIBUTED BY HASH(server_id) BUCKETS 1
PROPERTIES ("replication_num" = "1" -- 将副本数设置为与可用后端节点数一致
);-- 插入数据
INSERT INTO ads_db.performance_metrics VALUES
(1, '2025-08-01', 'CPU', 80.5, 20.0, 150),
(1, '2025-08-01', 'CPU', 75.2, 25.0, 120),
(1, '2025-08-01', 'Memory', 0.0, 15.0, 0),
(1, '2025-08-01', 'Memory', 0.0, 18.0, 0);-- 查询结果
SELECT * FROM ads_db.performance_metrics;- 查询结果:
mysql> select * from ads_db.performance_metrics;
+-----------+-------------+-------------+-----------+--------------+---------------+
| server_id | metric_date | metric_name | cpu_usage | memory_usage | response_time |
+-----------+-------------+-------------+-----------+--------------+---------------+
| 1 | 2025-08-01 | CPU | 80.5 | 20 | 150 |
| 1 | 2025-08-01 | Memory | 0 | 15 | 0 |
+-----------+-------------+-------------+-----------+--------------+---------------+
2 rows in set (0.26 sec)mysql>3.3 高级聚合函数
3.3.1 HLL_UNION聚合函数
-- 创建使用HLL_UNION聚合的表
CREATE TABLE ads_db.uv_stats(date_key DATE NOT NULL,channel VARCHAR(50) NOT NULL,user_id HLL HLL_UNION -- 移除了 DEFAULT '' 设置
) AGGREGATE KEY(date_key, channel)
DISTRIBUTED BY HASH(date_key) BUCKETS 1
PROPERTIES ("replication_num" = "1"
);-- 插入数据
INSERT INTO ads_db.uv_stats VALUES
('2025-08-01', 'search', hll_hash('user1')),
('2025-08-01', 'search', hll_hash('user2')),
('2025-08-01', 'search', hll_hash('user1')), -- 重复用户
('2025-08-01', 'direct', hll_hash('user3'));-- 查询结果
SELECT date_key, channel, count(DISTINCT user_id) as uv_count
FROM ads_db.uv_stats
GROUP BY date_key, channel;- 查询结果:
mysql> SELECT date_key, channel, count(DISTINCT user_id) as uv_count-> FROM ads_db.uv_stats-> GROUP BY date_key, channel;
+------------+---------+----------+
| date_key | channel | uv_count |
+------------+---------+----------+
| 2025-08-01 | direct | 1 |
| 2025-08-01 | search | 2 |
+------------+---------+----------+
2 rows in set (0.31 sec)mysql> 3.3.2 BITMAP_UNION聚合函数
-- 创建使用BITMAP_UNION聚合的表
CREATE TABLE ads_db.user_tags(user_id BIGINT NOT NULL,tag_id INT NOT NULL,tag_bitmap BITMAP BITMAP_UNION -- 移除了 DEFAULT '0'
) AGGREGATE KEY(user_id, tag_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 1
PROPERTIES ("replication_num" = "1"
);-- 插入数据
INSERT INTO ads_db.user_tags VALUES
(101, 1, to_bitmap(1)),
(101, 1, to_bitmap(2)),
(101, 2, to_bitmap(3)),
(102, 1, to_bitmap(1));-- 查询结果
SELECT user_id, tag_id, BITMAP_UNION_COUNT(tag_bitmap) as tag_count -- 使用 BITMAP_UNION_COUNT 聚合函数
FROM ads_db.user_tags
GROUP BY user_id, tag_id;- 查询结果:
mysql> SELECT -> user_id, -> tag_id, -> BITMAP_UNION_COUNT(tag_bitmap) as tag_count -- 使用 BITMAP_UNION_COUNT 聚合函数-> FROM ads_db.user_tags-> GROUP BY user_id, tag_id;
+---------+--------+-----------+
| user_id | tag_id | tag_count |
+---------+--------+-----------+
| 101 | 1 | 2 |
| 102 | 1 | 1 |
| 101 | 2 | 1 |
+---------+--------+-----------+
3 rows in set (0.23 sec)mysql> 4 聚合模型的使用场景
4.1 选择聚合模型的情况
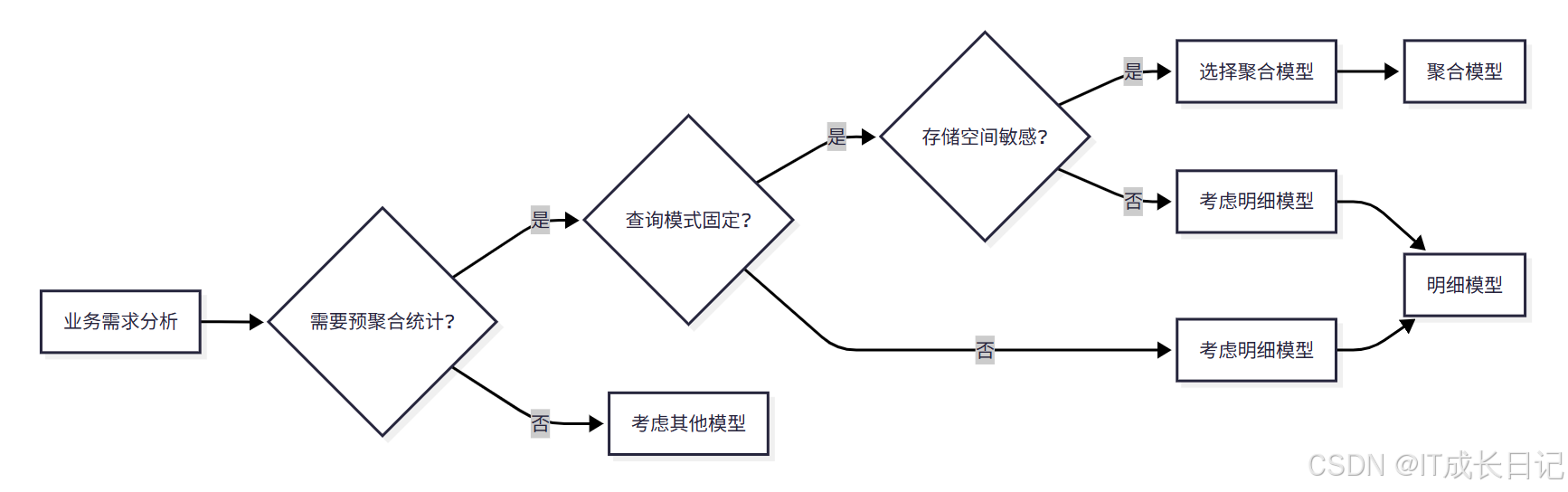
选择标准:
- 需要预聚合统计:业务场景中需要频繁进行聚合查询
- 查询模式固定:查询模式相对固定,聚合方式明确
- 存储空间敏感:对存储空间有要求,希望节省存储成本
- 查询性能要求高:对查询性能有较高要求
4.2 不适合聚合模型的情况
以下场景不建议使用聚合模型:
- 需要查询原始明细数据:如果需要查询原始明细数据,应该使用明细模型
- 数据频繁更新:如果数据需要频繁更新,应该使用主键模型
- 聚合方式不明确:如果聚合方式不明确或需要灵活调整,应该使用明细模型
- 需要支持任意维度查询:如果需要支持任意维度的Ad-hoc查询,应该使用明细模型
5 聚合模型的性能优化
5.1 建表优化
5.1.1 合理选择Key列
- Key列的选择对聚合模型的性能有重要影响:

选择原则:
- 高基数列优先:选择基数较高的列作为Key列
- 查询条件匹配:Key列应该与常用查询条件匹配
- 避免过多Key列:Key列数量不宜过多,一般2-5个为宜
- 数据类型优化:优先选择整型数据类型
-- 优化前的建表语句
CREATE TABLE ads_db.sales_stats(order_date DATE NOT NULL,user_id BIGINT NOT NULL,product_id BIGINT NOT NULL,category_id BIGINT NOT NULL,seller_id BIGINT NOT NULL,payment_amount DECIMAL(10,2) SUM DEFAULT "0",order_quantity INT SUM DEFAULT "0"
)AGGREGATE KEY(order_date, user_id, product_id, category_id, seller_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 1
PROPERTIES ("replication_num" = "1"
);-- 优化后的建表语句
CREATE TABLE ads_db.sales_stats_1(order_date DATE NOT NULL,user_id BIGINT NOT NULL,product_id BIGINT NOT NULL,-- 非聚合键列:添加 REPLACE 聚合(同一 product_id 对应唯一 category_id)category_id BIGINT REPLACE NOT NULL,-- 修正 DEFAULT 值:去掉引号,使用数值类型payment_amount DECIMAL(10,2) SUM DEFAULT 0,order_quantity INT SUM DEFAULT 0
)
-- 聚合键:仅包含维度列,确保聚合粒度正确
AGGREGATE KEY(order_date, user_id, product_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 1
PROPERTIES ("replication_num" = "1"
);5.1.2 合理设置分区策略
- 分区策略的选择对查询性能有重要影响:
-- 按日期分区
CREATE TABLE ads_db.daily_stats(stat_date DATE NOT NULL,metric_name VARCHAR(50) NOT NULL,metric_value DOUBLE SUM DEFAULT "0"
)AGGREGATE KEY(stat_date, metric_name)
PARTITION BY RANGE(stat_date) (PARTITION p202501 VALUES LESS THAN ('2025-02-01'),PARTITION p202502 VALUES LESS THAN ('2025-03-01'),PARTITION p202503 VALUES LESS THAN ('2025-04-01'),PARTITION p202504 VALUES LESS THAN ('2025-05-01')
)
DISTRIBUTED BY HASH(stat_date) BUCKETS 1
PROPERTIES ("replication_num" = "1"
);-- 按业务分区
CREATE TABLE ads_db.regional_stats(region_code VARCHAR(10) NOT NULL,business_type VARCHAR(50) NOT NULL,stat_date DATE NOT NULL,revenue DECIMAL(12,2) SUM DEFAULT "0",order_count INT SUM DEFAULT "0"
)AGGREGATE KEY(region_code, business_type, stat_date)
PARTITION BY LIST(region_code) (PARTITION p_north VALUES IN ("110", "120", "130", "140"),PARTITION p_east VALUES IN ("310", "320", "330", "340"),PARTITION p_south VALUES IN ("440", "450", "460", "470")
)
DISTRIBUTED BY HASH(region_code) BUCKETS 1
PROPERTIES ("replication_num" = "1"
);5.2 查询优化
5.2.1 利用预聚合结果
- 聚合模型的最大优势是预聚合,查询时应该充分利用这一优势:
-- 推荐的查询方式
SELECT order_date,product_id,SUM(payment_amount) as total_amount,SUM(order_quantity) as total_quantity
FROM ads_db.sales_stats
WHERE order_date >= '2025-08-01' AND order_date < '2025-12-01'AND category_id = 1001
GROUP BY order_date, product_id;5.2.2 优化聚合查询
-- 推荐的聚合查询
SELECT order_date,category_id,COUNT(DISTINCT user_id) as unique_users,SUM(payment_amount) as total_amount
FROM ads_db.sales_stats
WHERE order_date >= '2025-08-01' AND order_date < '2025-12-01'
GROUP BY order_date, category_id
ORDER BY total_amount DESC;-- 避免的复杂聚合查询
SELECT order_date,category_id,user_id,product_id,COUNT(*) as order_count,SUM(payment_amount) as amount_sum,AVG(payment_amount) as amount_avg,MAX(payment_amount) as amount_max,MIN(payment_amount) as amount_min
FROM ads_db.sales_stats
WHERE order_date >= '2025-08-01' AND order_date < '2025-12-01'
GROUP BY order_date, category_id, user_id, product_id
ORDER BY amount_sum DESC;5.3 写入优化
5.3.1 批量写入
- 聚合模型支持批量写入,可以提高写入性能:
-- 批量插入数据
INSERT INTO ads_db.sales_stats VALUES
('2025-08-01', 101, 1001, 1001, 500.00, 2),
('2025-08-01', 101, 1002, 1002, 300.00, 1),
('2025-08-01', 102, 1001, 1001, 800.00, 3),
('2025-08-02', 101, 1003, 1003, 200.00, 1);5.3.2 合理设置导入批次
-- 使用Broker Load批量导入
LOAD LABEL batch_load_sales
(DATA INFILE("hdfs://namenode:8020/user/sales/*.csv")INTO TABLE sales_statsFORMAT AS "csv"FIELDS TERMINATED BY "," LINES TERMINATED BY "\n"(order_date, user_id, product_id, category_id, payment_amount, order_quantity)
)
WITH BROKER 'broker_name'
PROPERTIES ("timeout" = "3600","max_filter_ratio" = "0.1","exec_mem_limit" = "8589934592"
);5.3.3 控制并发写入
-- 控制并发写入参数
SET query_timeout = 300;
SET exec_mem_limit = 8589934592;
SET parallel_fragment_exec_instance_num = 8;
SET parallel_pipeline_task_num = 8;6 总结
通过本文,我们了解到Apache Doris的聚合模型(Aggregate Key Model)在数据分析领域具有重要的价值:
- 预聚合机制:通过在数据写入时就进行聚合操作,极大地提升了查询性能
- 存储优化:只存储聚合后的数据,节省了存储空间,降低了存储成本
- 查询加速:聚合查询时无需再次计算,直接读取预聚合结果
- 灵活聚合:支持多种聚合函数,满足不同的业务需求
- 适用场景广泛:特别适合报表分析、统计汇总、用户行为分析等场景
在选择是否使用聚合模型时,建议考虑以下因素:
- 业务需求:如果业务场景中需要频繁进行聚合查询,聚合模型是最佳选择
- 查询模式:如果查询模式相对固定,聚合方式明确,聚合模型非常适合
- 存储空间:如果对存储空间有要求,希望节省存储成本,聚合模型是很好的选择
- 性能要求:如果对查询性能有较高要求,聚合模型能够提供显著的性能提升