后端Web实战-多表操作员工列表查询
目录
1.多表关系
1.1 一对多
1.1.1 关系实现
1.1.2 外键约束
1.2 一对一
1.3 多对多
1.4 案例
2. 多表查询
2.1 概述
2.1.1 数据准备
2.1.2 介绍
2.1.3 分类
2.2 内连接
2.3 外连接
2.4 子查询
2.4.1 介绍
2.4.2 标量子查询
2.4.3 列子查询
2.4.4 行子查询
2.4.5 表子查询
2.5 案例
3. 员工列表查询
3.1 环境准备
3.2 基本查询
3.3 分页查询
3.3.1 原始分页
3.3.1.1 需求分析
3.3.1.2 接口文档
3.3.1.3 思路分析
3.3.1.4 代码实现
3.3.2 分页插件
3.3.2.1 介绍
3.3.2.2 代码实现
3.3.2.3 实现机制
3.4 分页查询(带条件)
3.4.1 需求
3.4.2 思路分析
3.4.3 功能开发
3.4.3.1 Controller
3.4.3.2 Service
3.4.3.3 Mapper
3.4.4 功能测试
3.4.5 前后端联调
1.多表关系
关于单表的设计和增删查改在前面已经学完了,接下来学习多表的操作。各个表结构之间存在着各种联系,基本分为三种:
- 一对多(多对一)
- 多对多
- 一对一
1.1 一对多
1.1.1 关系实现
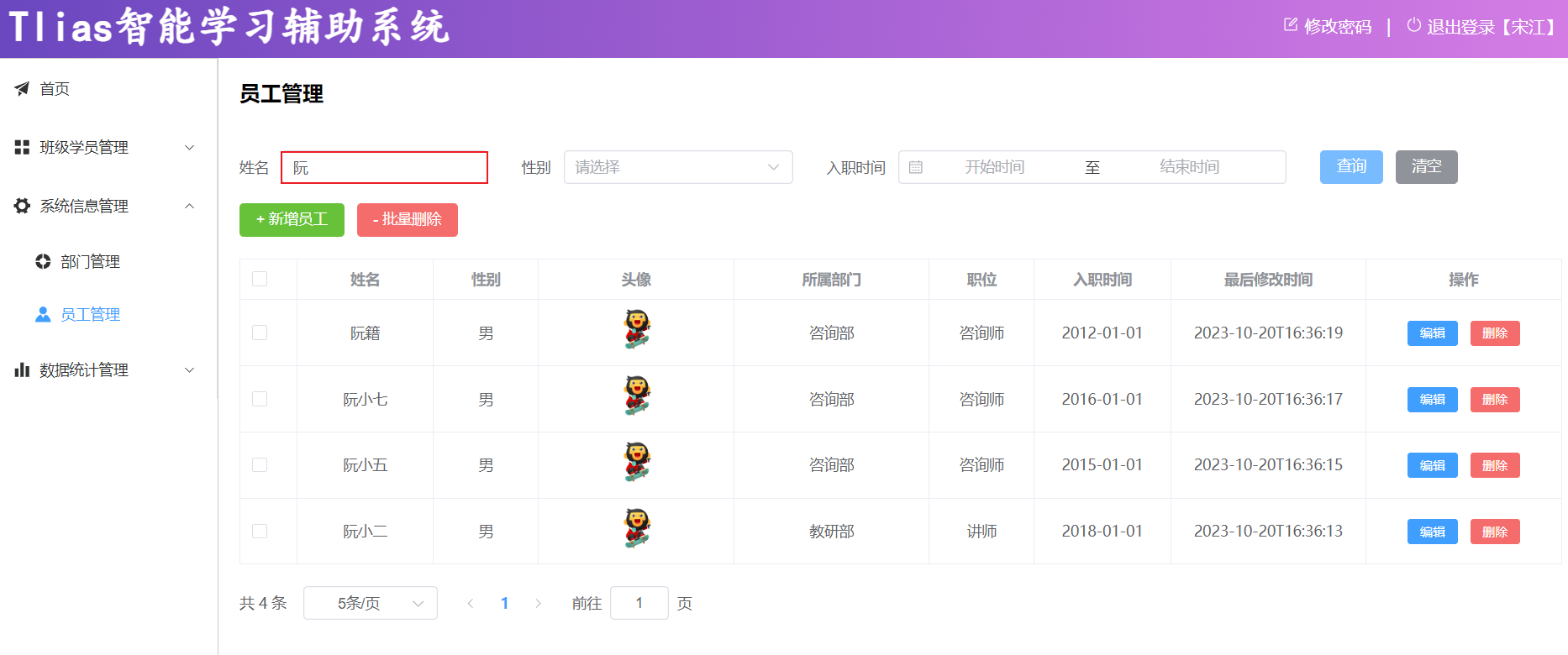
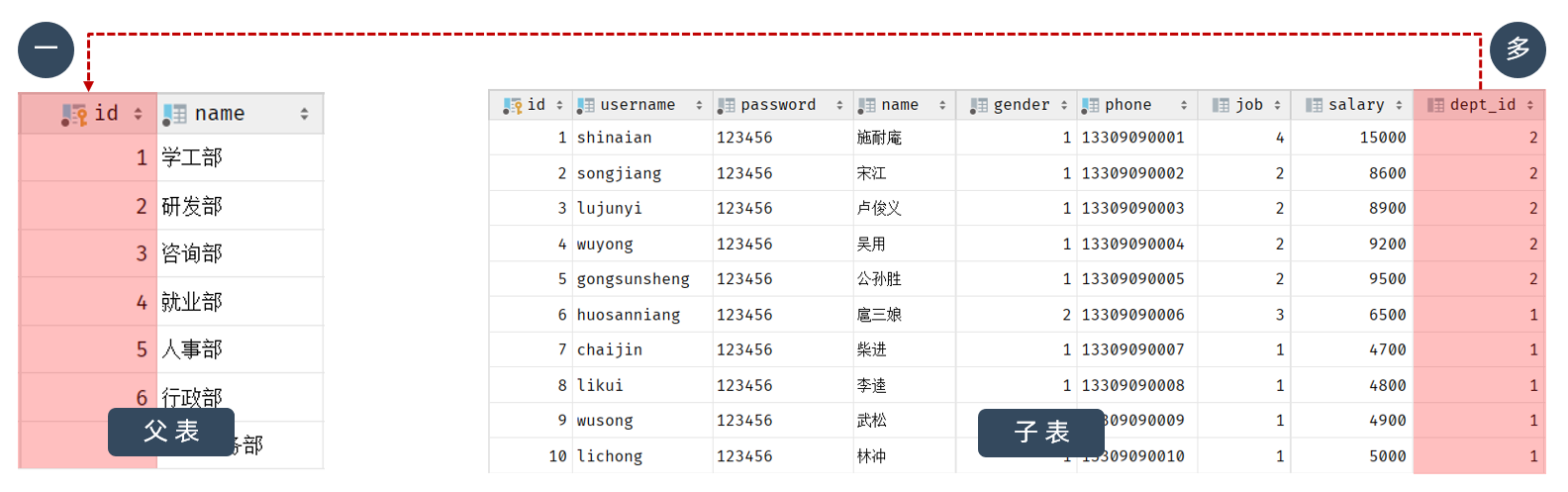
场景:部门与员工的关系(一个部门下有多个员工)
员工管理页面原型:(emp表结构设计)
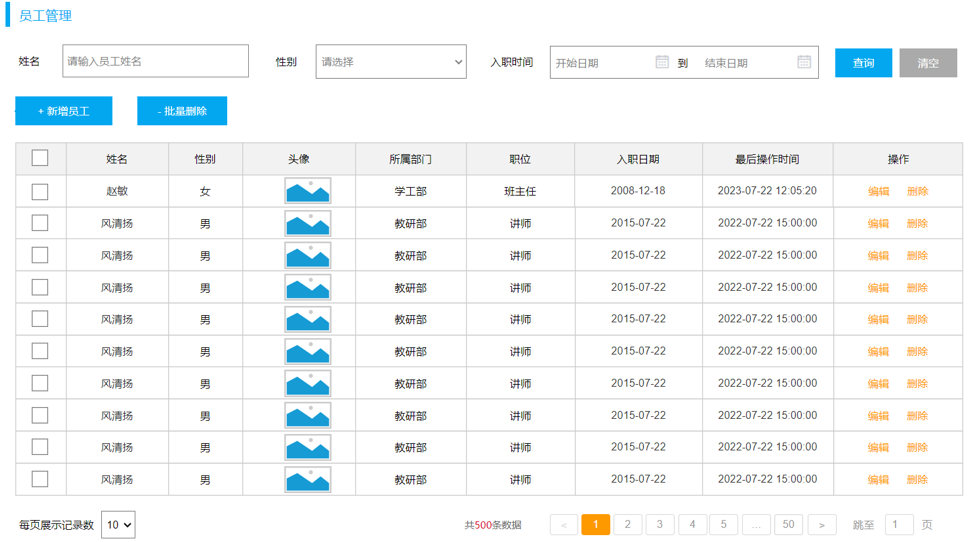
部门管理页面原型:
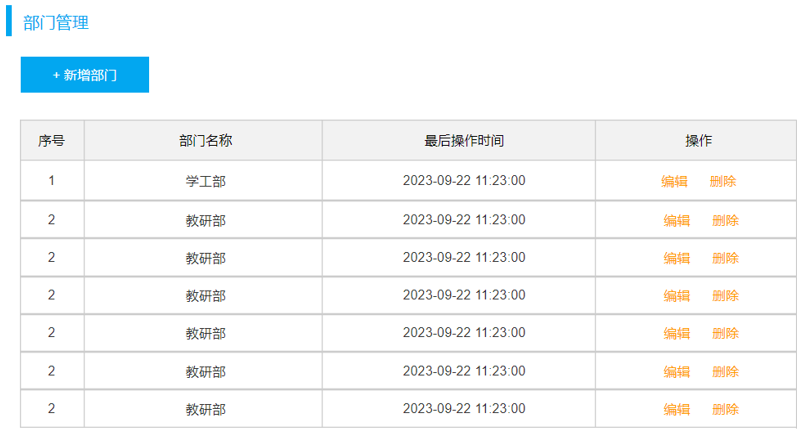
由于一个部门下,会关联多个员工。 而一个员工,是归属于某一个部门的 。那么此时,我们就需要在 emp 表中增加一个字段 dept_id 来标识这个员工属于哪一个部门,dept_id 关联的是 dept 的 id 。 如下所示:
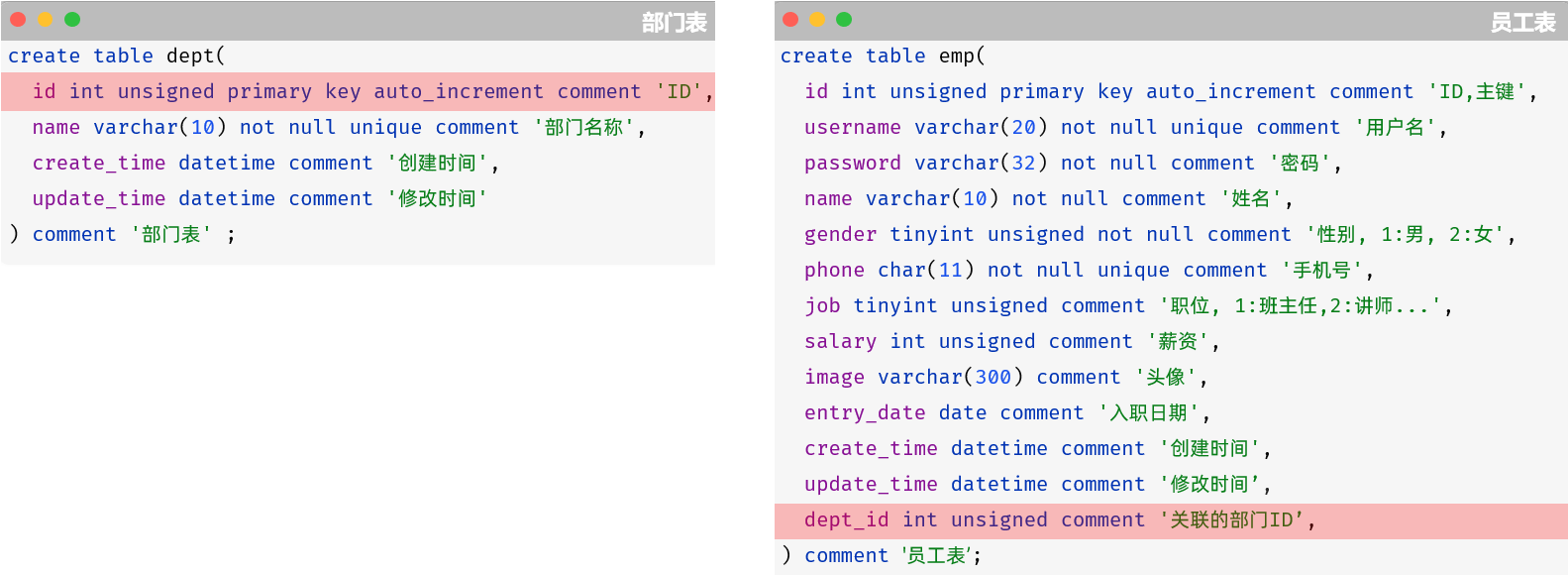
上述的 emp 员工表的 dept_id 字段,关联的是 dept 部门表的 id 。部门表是一的一方,也称为 父表,员工表是多的一方,称之为 子表。
接下来在数据库中用SQL语句将上述的两张表创建出来。
问题在于:一对多的表关系,在数据库层面该如何实现呢?
在数据库中多的一方,添加字段,来关联另一方的主键
1.1.2 外键约束
表结构创建完毕后,我们看到两张表的数据分别为:
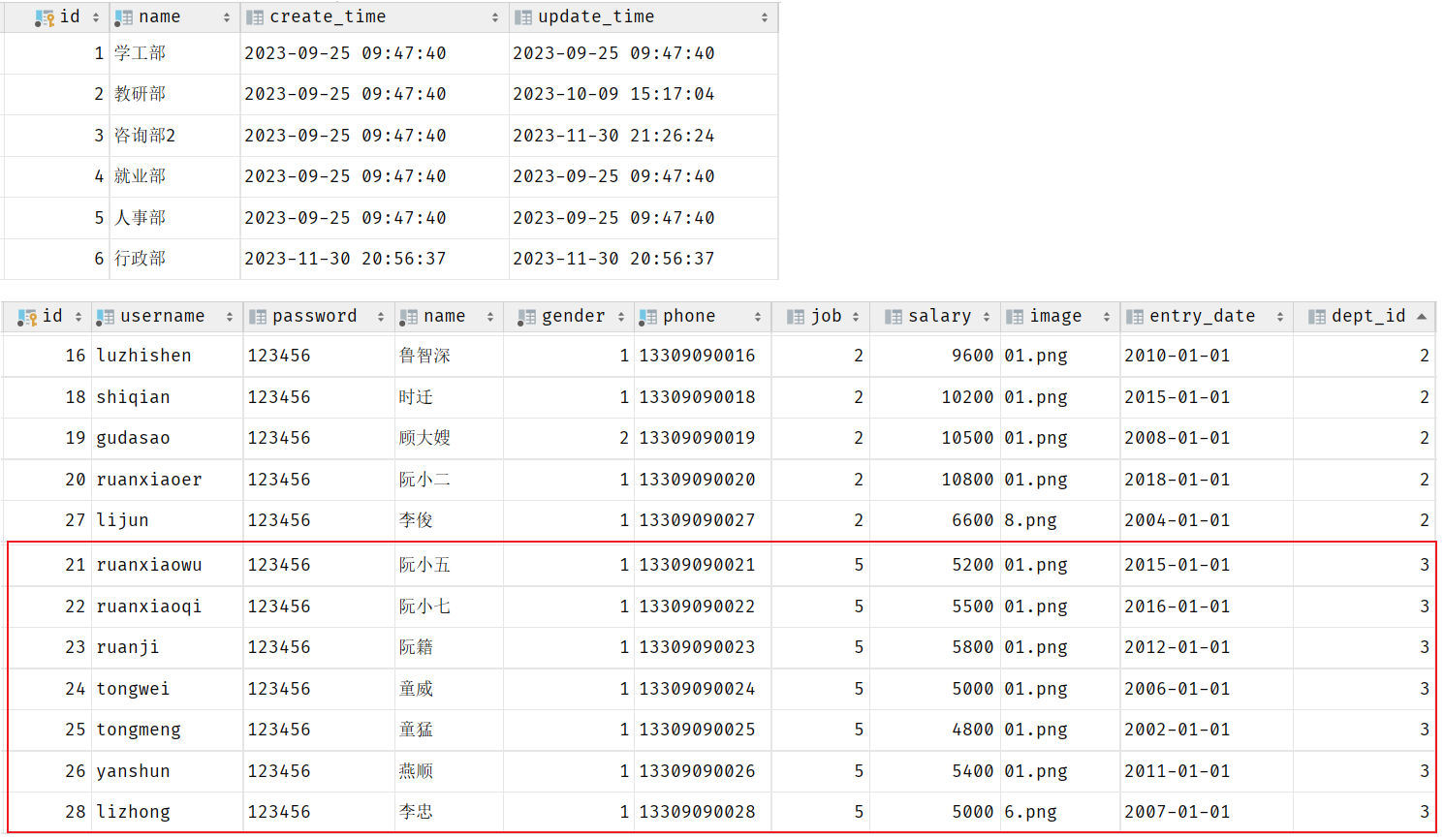
我们可以看到5号部门下,是关联的有7个员工。当点击删除5号部门后,我们发现5号部门被删除了,但是依然还有7个员工是属于5号部门的。 此时:就出现数据的不完整、不一致了。
原因是目前上述的两张表(员工表、部门表),在数据库层面,并未建立关联,所以是无法保证数据的一致性和完整性的。
问题解决
想解决上述的问题呢,我们就可以通过数据库中的 外键约束 来解决。
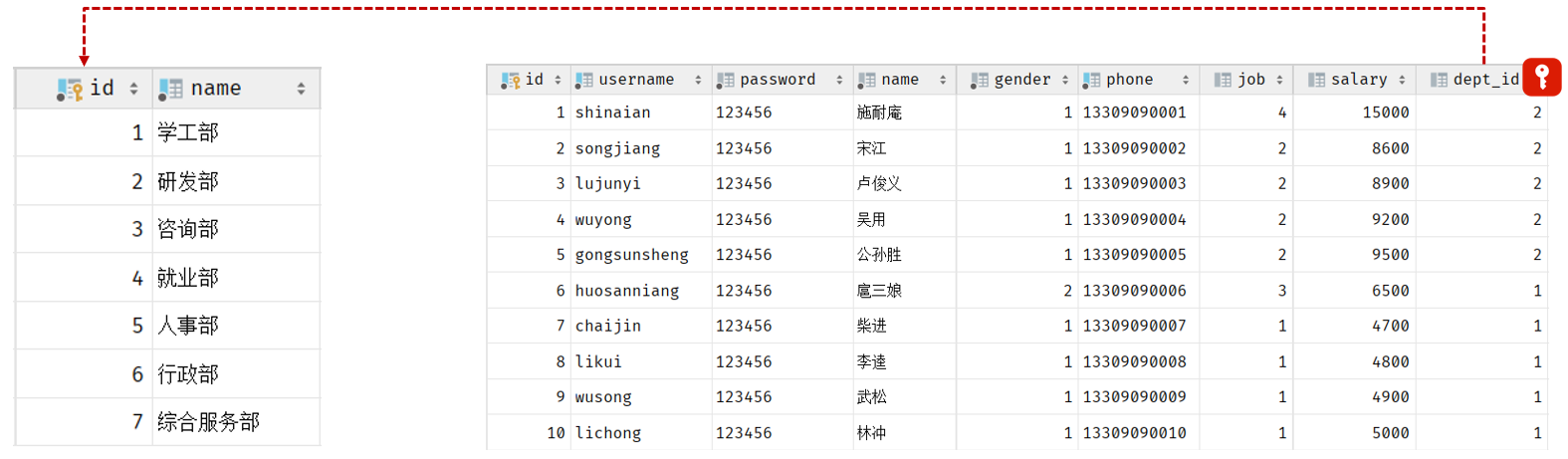
外键约束:让两张表的数据建立连接,保证数据的一致性和完整性。
对应的关键字:foreign key
外键约束的语法:
-- 创建表时指定
create table 表名(字段名 数据类型,...[constraint] [外键名称] foreign key (外键字段名) references 主表 (主表列名)
);-- 建完表后,添加外键
alter table 表名 add constraint 外键名称 foreign key(外键字段名) references 主表(主表列名);那接下来,我们就为员工表的dept_id 建立外键约束,来关联部门表的主键。
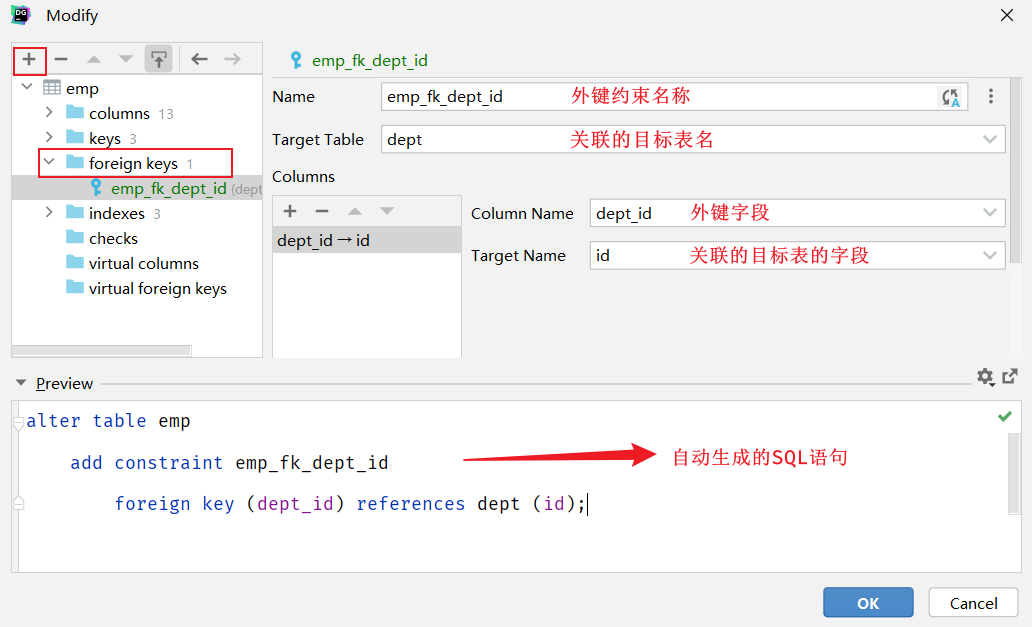
方式1:通过SQL语句操作
-- 修改表: 添加外键约束
alter table tb_emp add constraint fk_dept_id foreign key (dept_id) references tb_dept(id);方式2:图形化界面操作
当我们添加外键约束时,我们得保证当前数据库表中的数据是完整的。 所以,我们需要将之前删除掉的数据再添加回来。
当我们添加了外键之后,再删除ID为3的部门,就会发现,此时数据库报错了,不允许删除。
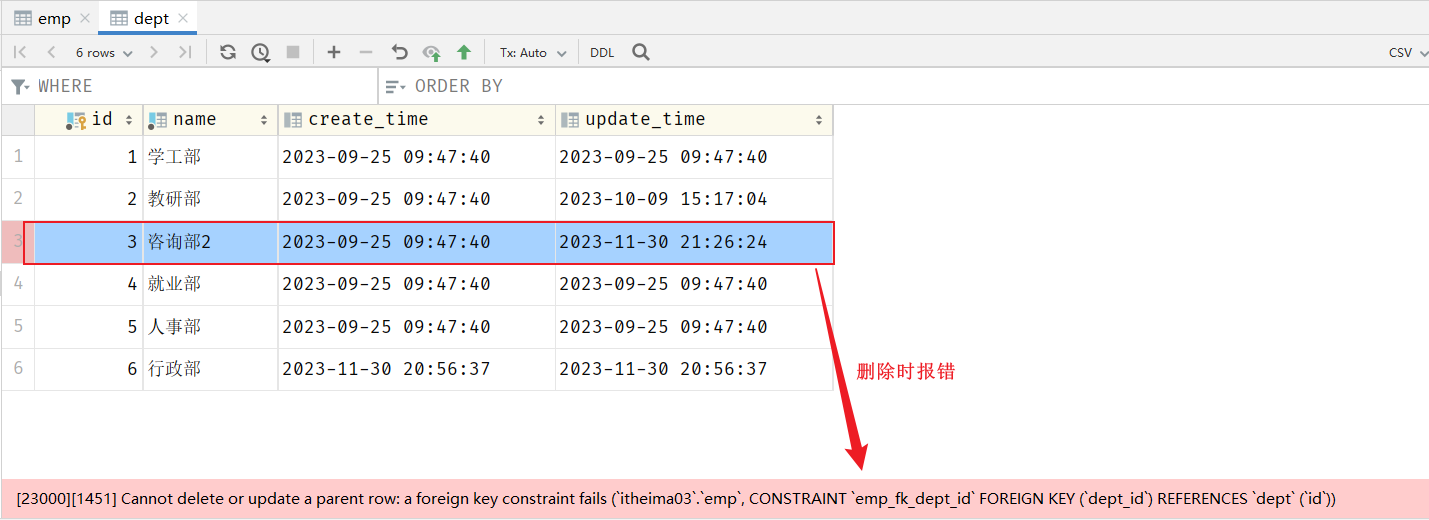
外键约束(foreign key):保证了数据的完整性和一致性。
物理外键和逻辑外键
-
物理外键
-
概念:使用foreign key定义外键关联另外一张表。
-
缺点:
-
影响增、删、改的效率(需要检查外键关系)。
-
仅用于单节点数据库,不适用与分布式、集群场景。
-
容易引发数据库的死锁问题,消耗性能。
-
-
-
逻辑外键
-
概念:在业务层逻辑中,解决外键关联。
-
通过逻辑外键,就可以很方便的解决上述问题。
-
在现在的企业开发中,很少会使用物理外键,都是使用逻辑外键。 甚至在一些数据库开发规范中,会明确指出禁止使用物理外键 foreign key
1.2 一对一
一对一关系表在实际开发中应用起来比较简单,通常是用来做单表的拆分,也就是将一张大表拆分成两张小表,将大表中的一些基础字段放在一张表当中,将其他的字段放在另外一张表当中,以此来提高数据的操作效率。
一对一的应用场景: 用户表(基本信息+身份信息)

-
基本信息:用户的ID、姓名、性别、手机号、学历
-
身份信息:民族、生日、身份证号、身份证签发机关,身份证的有效期(开始时间、结束时间)
在业务系统中,我们对基本信息的查询频率特别的高,而对于用户的身份信息查询频率较低,此时我们可以将一张表拆分为二,第一张表存放的是用户的基本信息,而第二张表存放的就是用户的身份信息。
如何实现一对一的关系?
其实一对一我们可以看成一种特殊的一对多。设计一对多时我们在多的一方添加外键。同样我们也可以通过外键来体现一对一之间的关系,我们只需要在任意一方来添加一个外键就可以了。

-- 用户身份信息表
create table tb_user_card(id int unsigned primary key auto_increment comment 'ID',nationality varchar(10) not null comment '民族',birthday date not null comment '生日',idcard char(18) not null comment '身份证号',issued varchar(20) not null comment '签发机关',expire_begin date not null comment '有效期限-开始',expire_end date comment '有效期限-结束',user_id int unsigned not null unique comment '用户ID',constraint fk_user_id foreign key (user_id) references tb_user(id)
) comment '用户身份信息表';一对一 :在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一的(UNIQUE)
1.3 多对多
多对多的关系在开发中属于也比较常见的。比如:学生和老师的关系,一个学生可以有多个授课老师,一个授课老师也可以有多个学生。在比如:学生和课程的关系,一个学生可以选修多门课程,一个课程也可以供多个学生选修。
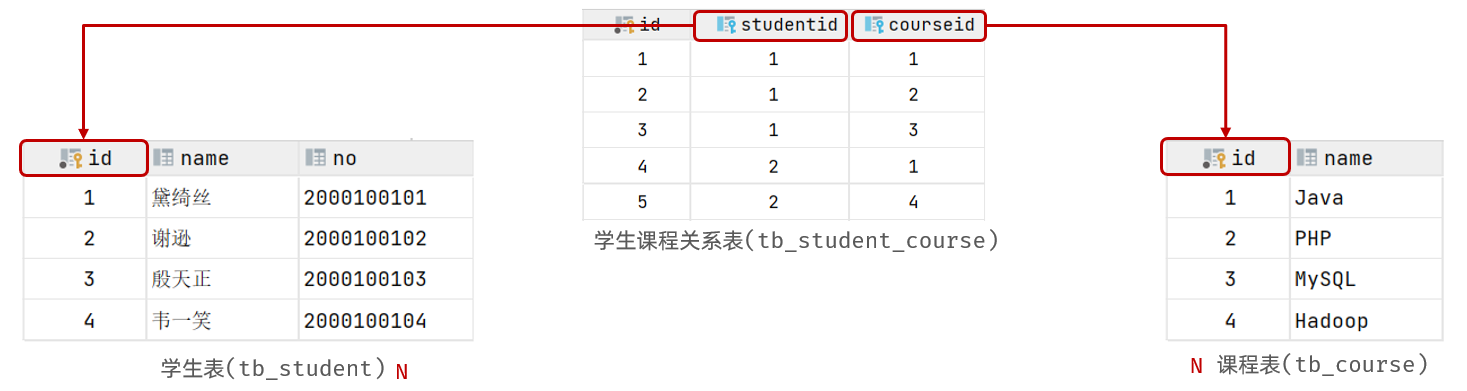
案例:学生与课程的关系
-
关系:一个学生可以选修多门课程,一门课程也可以供多个学生选择
-
实现关系:建立第三张中间表,中间表至少包含两个外键,分别关联两方主键
-- 学生表
create table tb_student(id int auto_increment primary key comment '主键ID',name varchar(10) comment '姓名',no varchar(10) comment '学号'
) comment '学生表';
-- 学生表测试数据
insert into tb_student(name, no) values ('黛绮丝', '2000100101'),('谢逊', '2000100102'),('殷天正', '2000100103'),('韦一笑', '2000100104');-- 课程表
create table tb_course(id int auto_increment primary key comment '主键ID',name varchar(10) comment '课程名称'
) comment '课程表';
-- 课程表测试数据
insert into tb_course (name) values ('Java'), ('PHP'), ('MySQL') , ('Hadoop');-- 学生课程表(中间表)
create table tb_student_course(id int auto_increment comment '主键' primary key,student_id int not null comment '学生ID',course_id int not null comment '课程ID',constraint fk_courseid foreign key (course_id) references tb_course (id),constraint fk_studentid foreign key (student_id) references tb_student (id)
)comment '学生课程中间表';1.4 案例
下面通过一个综合案例加深对于多表关系的理解,并掌握多表设计的流程。
需求
-
根据参考资料中提供的《Talis智能学习辅助系统》页面原型,设计员工管理模块涉及到的表结构。
创建工作经历的表,员工:工作经历 = 1 : N
create table emp_expr
(id int unsigned primary key auto_increment comment '主键ID',begin date comment '开始时间',end date comment '结束时间',company varchar(50) comment '公司',job varchar(50) comment '职位',emp_id int unsigned comment '员工ID'
) comment '员工工作经历表';在工作经历表中我们使用逻辑外键。
2. 多表查询
2.1 概述
2.1.1 数据准备
创键部门表dept,员工表emp
2.1.2 介绍
多表查询:查询时从多张表中获取所需数据
单表查询的SQL语句:select 字段列表 from 表名;
那么要执行多表查询,只需要使用逗号分隔多张表即可,如: select 字段列表 from 表1, 表2;
查询用户表和部门表中的数据:
select * from emp , dept;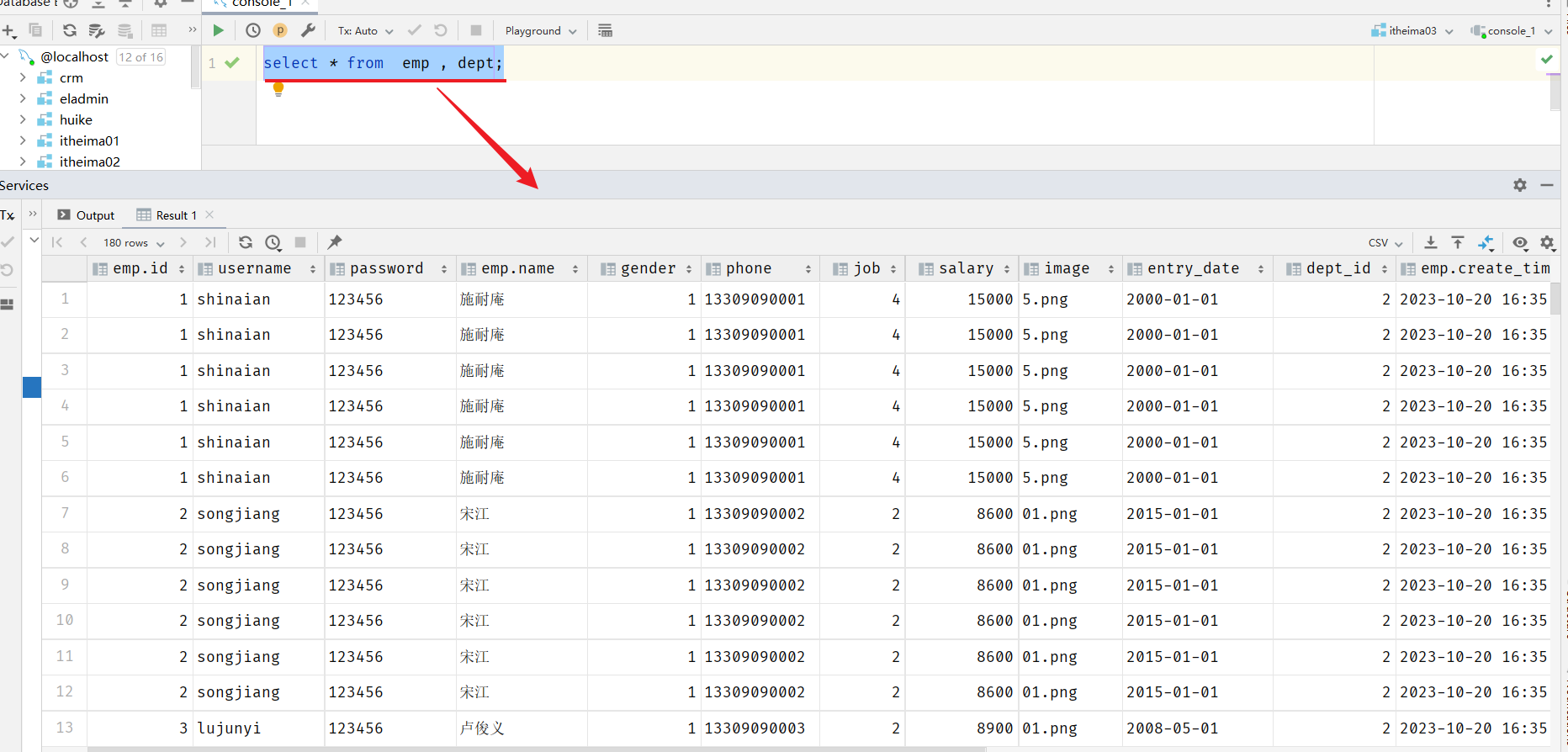
此时,我们看到查询结果中包含了大量的结果集,总共180条记录,而这其实就是员工表所有的记录(30行)与部门表所有记录(6行)的所有组合情况,这种现象称之为笛卡尔积。
笛卡尔积:笛卡尔乘积是指在数学中,两个集合(A集合和B集合)的所有组合情况。
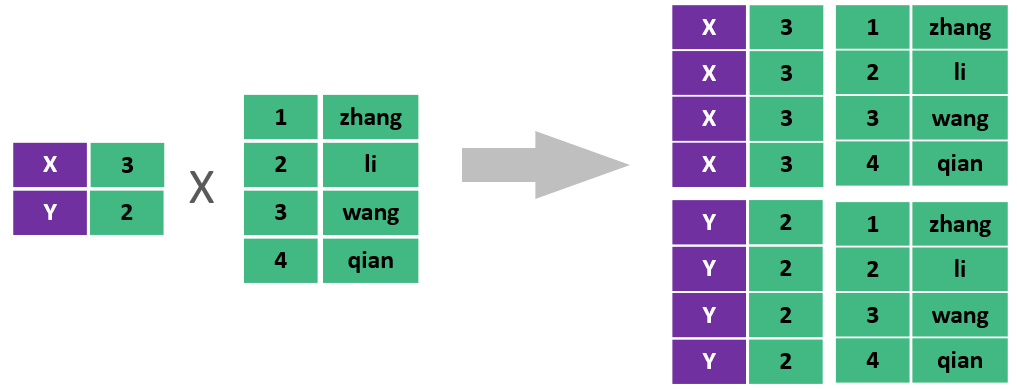
在多表查询时,需要消除无效的笛卡尔积,只保留表关联部分的数据。
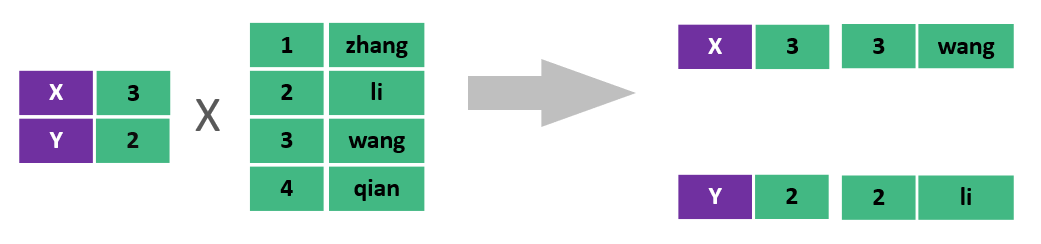
在SQL语句中,如何去除无效的笛卡尔积呢?只需要给多表查询加上连接查询的条件即可。
select * from emp , dept where emp.dept_id = dept.id ;2.1.3 分类
多表查询可以分为:
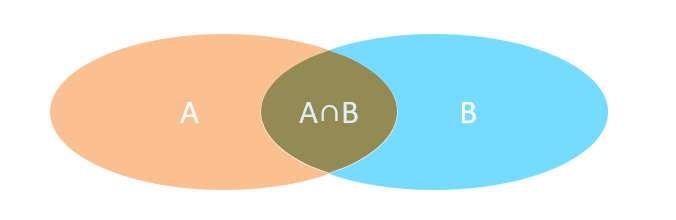
1.连接查询
-
内连接:相当于查询A、B交集部分数据
-
外连接
-
左外连接:查询左表所有数据(包括两张表交集部分数据)
-
右外连接:查询右表所有数据(包括两张表交集部分数据)
-
2.子查询
2.2 内连接
内连接查询:查询两表或多表中交集部分数据。
内连接从语法上可以分为:
-
隐式内连接
-
显式内连接
隐式内连接语法:
select 字段列表 from 表1 , 表2 where 条件 ... ;显式内连接语法
select 字段列表 from 表1 [ inner ] join 表2 on 连接条件 ... ;案例:
-- ============================= 内连接 ==========================
-- A. 查询所有员工的ID, 姓名 , 及所属的部门名称 (隐式、显式内连接实现)
-- 涉及到的表:emp, dept
-- 隐式内连接
select emp.id, emp.name, dept.name
from emp,dept
where emp.dept_id = dept.id;
-- 显示内连接 [inner] join ... on ...
select emp.id, emp.name, dept.name
from empinner join dept on emp.dept_id = dept.id;select emp.id, emp.name, dept.name
from empjoin dept on emp.dept_id = dept.id;-- B. 查询 性别为男, 且工资 高于8000 的员工的ID, 姓名, 及所属的部门名称 (隐式、显式内连接实现)
-- 隐式内连接
select t1.id, t1.name, t2.name
from emp t1,dept t2
where t1.dept_id = t2.idand t1.gender = 1and t1.salary > 8000;
-- 显式内连接
select emp.id, emp.name, dept.name
from empinner join dept on emp.dept_id = dept.id
where emp.gender = 1and emp.salary > 8000;
给表起别名简化书写:
select 字段列表 from 表1 as 别名1 , 表2 as 别名2 where 条件 ... ;select 字段列表 from 表1 别名1 , 表2 别名2 where 条件 ... ; -- as 可以省略注意事项:
一旦为表起了别名,就不能再使用表名来指定对应的字段了,此时只能够使用别名来指定字段。
2.3 外连接
外连接分为两种:左外连接 和 右外连接。
左外连接语法:
select 字段列表 from 表1 left [ outer ] join 表2 on 连接条件 ... ;左/右外连接相当于查询表1(左/右表)的所有数据,当然也包含表1和表2交集部分的数据。
右外连接语法:
select 字段列表 from 表1 right [ outer ] join 表2 on 连接条件 ... ;-- =============================== 外连接 ============================
-- A. 查询员工表 所有 员工的姓名, 和对应的部门名称 (左外连接)
select emp.*, dept.name
from empleft join dept on emp.dept_id = dept.id;-- B. 查询部门表 所有 部门的名称, 和对应的员工名称 (右外连接)
select dept.*, emp.name
from empright join dept on emp.dept_id = dept.id;-- 改成左外连接
select dept.*, emp.name
from deptleft join emp on emp.dept_id = dept.id;
-- C. 查询工资 高于8000 的 所有员工的姓名, 和对应的部门名称 (左外连接)
select emp.*, dept.name
from empleft join dept on emp.dept_id = dept.id
where emp.salary > 8000;这里我们需要注意,当有员工对应的部门为null时,此时的需求要把所有员工对应的部门信息都输出(包括部门 = null)的情况,这种情况下我们只能用外连接,内连接不会把部门 = null的员工信息展示出来。
2.4 子查询
2.4.1 介绍
SQL语句中嵌套select语句,称为嵌套查询,又称子查询。
SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2 ... );子查询外部的语句可以是insert / update / delete / select 的任何一个,最常见的是 select。
根据子查询结果的不同分为:
-
标量子查询(子查询结果为单个值[一行一列])
-
列子查询(子查询结果为一列,但可以是多行)
-
行子查询(子查询结果为一行,但可以是多列)
-
表子查询(子查询结果为多行多列[相当于子查询结果是一张表])
子查询可以书写的位置:
-
where之后
-
from之后
-
select之后
2.4.2 标量子查询
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询称为标量子查询。
常用的操作符: = <> > >= < <=
-- ========================= 子查询 ================================
-- 标量子查询
-- A. 查询 最早入职 的员工信息
-- 1.查询最早入职的日期
select min(entry_date)
from emp;
-- 2000-01-01
-- 2.查询2000-01-01日期的员工
select *
from emp
where entry_date = '2000-01-01';
-- 3.合并sql
select *
from emp
where entry_date = (select min(entry_date) from emp);-- B. 查询在 "阮小五" 入职之后入职的员工信息
-- 1.查询 "阮小五" 入职日期
select entry_date
from emp
where name = '阮小五';
-- '2015-01-01'
-- 2.查询在 "阮小五" 入职之后入职的员工信息
select *
from emp
where entry_date > (select entry_date from emp where name = '阮小五');2.4.3 列子查询
子查询返回的结果是一列(可以是多行),这种子查询称为列子查询。
常用的操作符:
| 操作符 | 描述 |
|---|---|
| IN | 在指定的集合范围之内,多选一 |
| NOT IN | 不在指定的集合范围之内 |
-- 列子查询
-- A. 查询 "教研部" 和 "咨询部" 的所有员工信息
-- 1.查询 "教研部" 和 "咨询部" 的id
select id
from dept
where name = '教研部'or name = '咨询部';
-- 2.查询2号部门和3号部门下的所有员工
select *
from emp
where dept_id = 2or dept_id = 3;select *
from emp
where dept_id in (select id from dept where name = '教研部' or name = '咨询部');2.4.4 行子查询
子查询返回的结果是一行(可以是多列),这种子查询称为行子查询。
常用的操作符:= 、<> 、IN 、NOT IN
-- 行子查询
-- A. 查询与 "李忠" 的薪资 及 职位都相同的员工信息 ;
-- 1.查询李忠的薪资以及职位
select salary, job
from emp
where name = '李忠';
-- 2.查询salary = 5000,且职位为5的员工信息
select *
from emp
where salary = 5000and job = 5;
-- 3.合并
select *
from emp
where (salary, job) = (5000, 5);select *
from emp
where (salary, job) = (select salary, job from emp where name = '李忠');2.4.5 表子查询
子查询返回的结果是多行多列,常作为临时表,这种子查询称为表子查询。
-- A. 查询入职日期是 "2006-01-01" 之后的员工信息 , 及其部门信息
-- 1.查询入职日期是 "2006-01-01" 之后的员工信息(表1)
select *
from emp
where entry_date > '2006-01-01';
-- 2.查询 表1 与部门表的交集
select *
from (select * from emp where entry_date > '2006-01-01') t1,dept t2
where t1.dept_id = t2.id;2.5 案例
-- 需求:
-- 1. 查询 "教研部" 的 "男性" 员工,且在 "2011-05-01" 之后入职的员工信息 。
-- a.查询教研部id
# select id
# from dept
# where name = '教研部';select t2.*, t1.name
from dept t1,emp t2
where t1.id = t2.dept_idand t1.name = '教研部'and t2.gender = 1and t2.entry_date > '2011-05-01';-- 2. 查询工资 低于公司平均工资的 且 性别为男 的员工信息 。
-- a.查询公司平均工资 avg()
# select avg(salary) from emp; -- 7548.2759
select *
from emp
where salary < (select avg(salary) from emp)and gender = 1;-- 3. 查询工资 低于本部门平均工资的员工信息 。
-- a.求每个部门的平均工资
select dept_id, avg(salary)
from emp
group by dept_id;
-- b.查询工资低于本部门平均工资的员工信息(两张表:t1 + 员工表emp)
select *
from emp t1,(select dept_id, avg(salary) safrom empgroup by dept_id) t2
where t1.dept_id = t2.dept_idand t1.salary < t2.sa;
-- 4. 查询部门人数超过 10 人的部门名称 。
-- a.根据部门统计每个部门有多少人
select dept_id, count(*)
from emp
group by dept_id;
-- b.只查询出部门人数超过10人的部门名称
select dept_id, count(*) cnt
from emp
group by dept_id
having cnt > 10;
-- c.联表查询,查出部门名称
select dept.name, count(*) cnt
from emp,dept
where emp.dept_id = dept.id
group by dept_id
having cnt > 10;3. 员工列表查询
那接下来,我们要来完成的是员工列表的查询功能实现。 具体的需求如下:
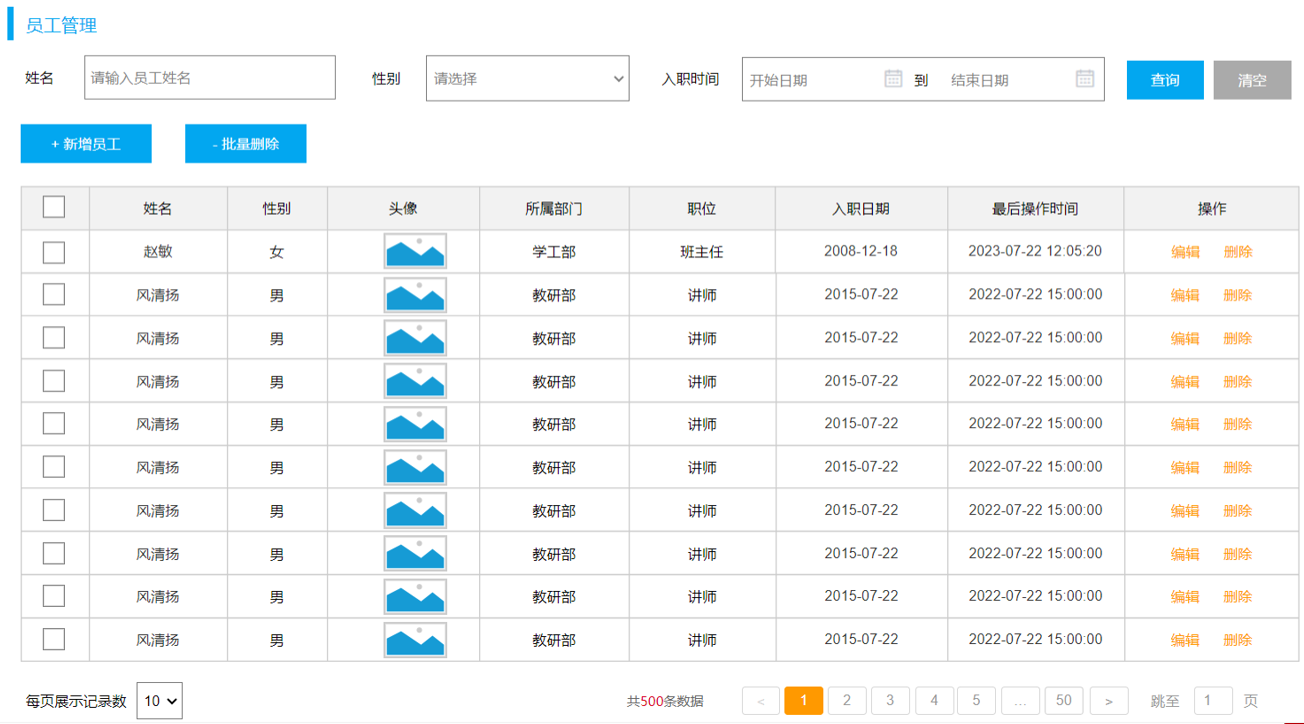
在查询员工列表数据时,既需要查询 员工的基本信息,还需要查询员工所属的部门名称,所以这里呢,会涉及到多表查询的操作。
而且,在查询员工列表数据时,既要考虑搜索栏中的查询条件,还要考虑对查询的结果进行分页处理。
那么接下来,我们在实现这个功能时,将会分为三个部分来逐一实现:
-
基本查询
-
分页查询
-
条件分页查询
3.1 环境准备
1). 准备数据库表 emp(员工表) emp_expr(员工工作经历表)
2). 准备与表结构对应的实体类 (EMP和EMPExpr)
/*** 员工信息*/
@Data
public class Emp {private Integer id; //ID,主键private String username; //用户名private String password; //密码private String name; //姓名private Integer gender; //性别, 1:男, 2:女private String phone; //手机号private Integer job; //职位, 1:班主任,2:讲师,3:学工主管,4:教研主管,5:咨询师private Integer salary; //薪资private String image; //头像private LocalDate entryDate; //入职日期private Integer deptId; //关联的部门IDprivate LocalDateTime createTime; //创建时间private LocalDateTime updateTime; //修改时间//封装部门名称数private String deptName; //部门名称
}
/*** 工作经历*/
@Data
public class EmpExpr {private Integer id; //IDprivate Integer empId; //员工IDprivate LocalDate begin; //开始时间private LocalDate end; //结束时间private String company; //公司名称private String job; //职位
}3.2 基本查询
那接下来,我们就先考虑一下要查询所有的员工数据,及其关联的部门名称,这个SQL语句该如何实现 ?
这里,要查询所有的员工,也就意味着,即使员工没有部门,也需要将该员工查询出来 。所以,这里需要用左外连接实现,具体SQL如下:
select e.*, d.name from emp as e left join dept as d on e.dept_id = d.id那接下来,我们就定义一个员工管理的mapper接口 EmpMapper 并在其中完成员工信息的查询。 具体代码如下:
@Mapper
public interface EmpMapper {/*** 查询所有的员工及其对应的部门名称*/@Select("select e.*, d.name deptName from emp as e left join dept as d on e.dept_id = d.id ")public List<Emp> list();}注意,上述SQL语句中,给 部门名称起了别名 deptName ,是因为在接口文档中,要求部门名称给前端返回的数据中,就必须叫 deptName。 而这里我们需要将查询返回的每一条记录都封装到Emp对象中,那么就必须保证查询返回的字段名与属性名是一一对应的。
此时,我们就需要在Emp中定义一个属性 deptName 用来封装部门名称。 具体如下:
@Data
public class Emp {private Integer id; //ID,主键private String username; //用户名private String password; //密码private String name; //姓名private Integer gender; //性别, 1:男, 2:女private String phone; //手机号private Integer job; //职位, 1:班主任,2:讲师,3:学工主管,4:教研主管,5:咨询师private Integer salary; //薪资private String image; //头像private LocalDate entryDate; //入职日期private Integer deptId; //关联的部门IDprivate LocalDateTime createTime; //创建时间private LocalDateTime updateTime; //修改时间//封装部门名称数private String deptName; //部门名称
}代码编写完毕后,我们可以编写一个单元测试,对上述的程序进行测试:
@SpringBootTest
class TliasWebManagementApplicationTests {@Autowiredprivate EmpMapper empMapper;@Testpublic void testListEmp(){List<Emp> empList = empMapper.list();empList.forEach(emp -> System.out.println(emp));}}
实体类里的属性必须用包装类,如Integer salary,如果用int,那么不赋值的时候salary = 0,但是用包装类Integer可以让salary = null
3.3 分页查询
3.3.1 原始分页
3.3.1.1 需求分析
上面的基本查询我们在Mapper接口中定义了接口方法,完成了查询所有员工及其部门名称的功能,是将数据库中所有的数据查询出来了。试想如果数据库中的数据有很多的时候,我们将数据全部展示不现实,此时就需要用到分页查询。
使用分页解决这个问题。每次只展示一页的数据,比如:一页展示10条数据,如果还想看其他的数据,可以通过点击页码进行查询。
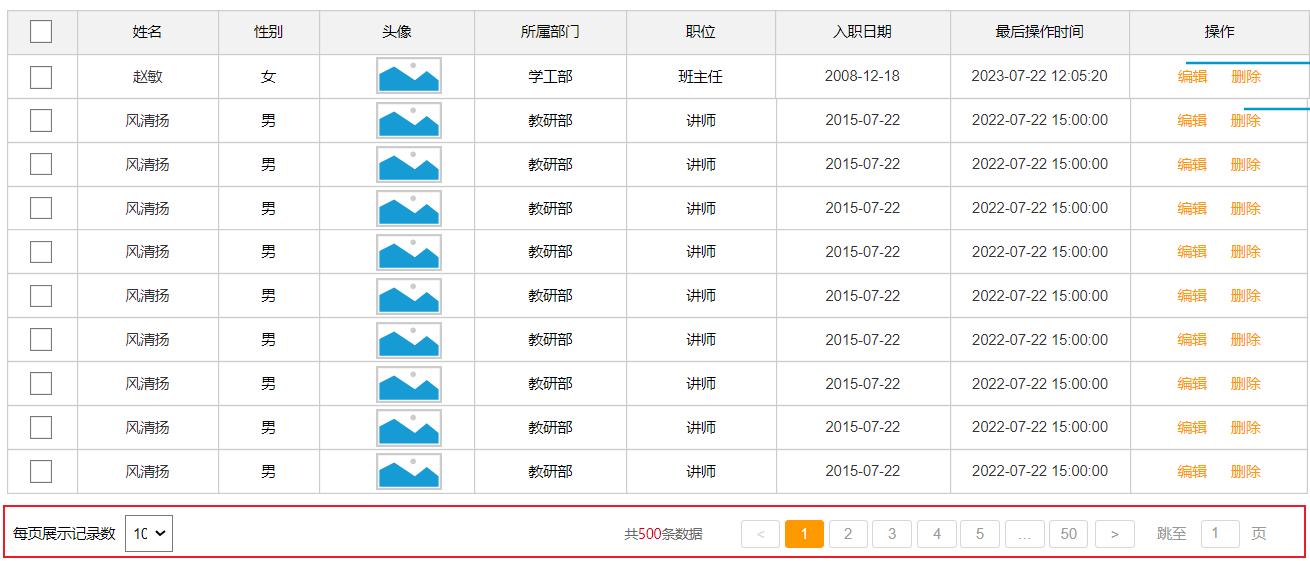
而在员工管理的需求中,就要求我们进行分页查询,展示出对应的数据。 具体的页面原型如下:
要想从数据库中进行分页查询,我们要使用LIMIT关键字,格式为:limit 开始索引 每页显示的条数
-- 分页查询
-- 查询第1页,每页展示5条
select * from emp limit 0,5;
# select * from emp limit 5;
-- 查询第2页,每页展示5条
select * from emp limit 5,5;
-- 查询第3页,每页展示5条
select * from emp limit 10,5;-- 第一个参数:起始索引 = (页码 - 1) * 每页记录数 【索引从0开始,0可省略】开始索引的计算公式: 开始索引 = (当前页码 - 1) * 每页显示条数
我们基于原型页面继续分析:
1.前端在请求服务器时,传递的参数
- 当前页码 page
- 每页显示条数 pageSize
2.后端需要响应什么数据给前端
- 所查询到的数据列表(存储到List集合中)
- 总记录数
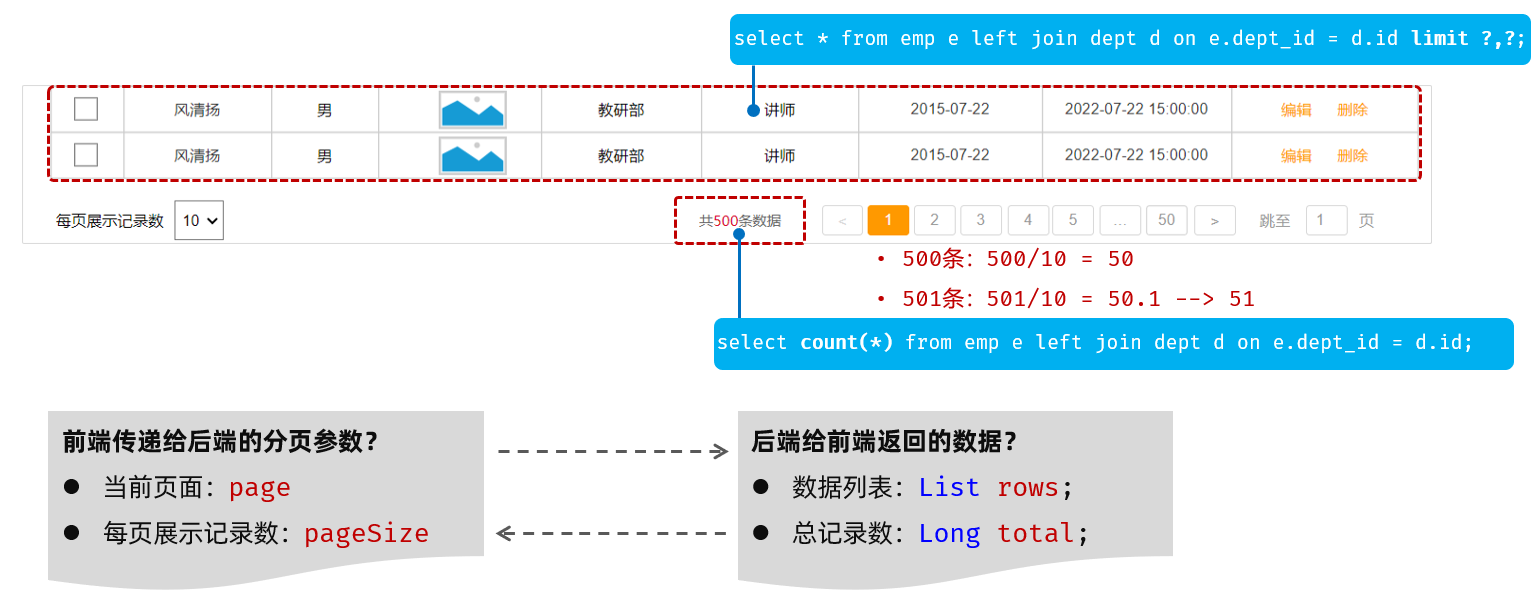
后端会给前端返回的数据包含:List集合(数据列表)、total(数据总数)
而我们需要将这两个数据都返回给浏览器,我们通常将数据封装到PageBean对象中,并将该对象转换为json格式的数据响应回给浏览器。
下面我们定义一个PageBean实体类用来封装数据:
/*** 封装分页列表结果*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class PageBean {private Long total; //总条数private List rows; //分页结果列表
}3.3.1.2 接口文档
员工列表查询
-
基本信息
请求路径:/emps
请求方式:GET
接口描述:该接口用于员工列表数据的条件分页查询 -
请求参数
参数格式:queryString
参数说明:
参数名称 是否必须 示例 备注 name 否 张 姓名 gender 否 1 性别 , 1 男 , 2 女 begin 否 2010-01-01 范围匹配的开始时间(入职日期) end 否 2020-01-01 范围匹配的结束时间(入职日期) page 是 1 分页查询的页码,如果未指定,默认为1 pageSize 是 10 分页查询的每页记录数,如果未指定,默认为10
请求数据样例:
/emps?name=张&gender=1&begin=2007-09-01&end=2022-09-01&page=1&pageSize=10- 响应数据
参数格式:application/json
参数说明:
| 名称 | 类型 | 是否必须 | 备注 |
|---|---|---|---|
| code | number | 必须 | 响应码, 1 成功 , 0 失败 |
| msg | string | 非必须 | 提示信息 |
| data | object | 必须 | 返回的数据 |
| |- total | number | 必须 | 总记录数 |
| |- rows | object [] | 必须 | 数据列表 |
| |- id | number | 非必须 | id |
| |- username | string | 非必须 | 用户名 |
| |- name | string | 非必须 | 姓名 |
| |- gender | number | 非必须 | 性别 , 1 男 ; 2 女 |
| |- image | string | 非必须 | 图像 |
| |- job | number | 非必须 | 职位, 说明: 1 班主任,2 讲师, 3 学工主管, 4 教研主管, 5 咨询师 |
| |- salary | number | 非必须 | 薪资 |
| |- entryDate | string | 非必须 | 入职日期 |
| |- deptId | number | 非必须 | 部门id |
| |- deptName | string | 非必须 | 部门名称 |
| |- updateTime | string | 非必须 | 更新时间 |
响应数据样例:
{"code": 1,"msg": "success","data": {"total": 2,"rows": [{"id": 1,"username": "jinyong","password": "123456","name": "金庸","gender": 1,"image": "https://web-framework.oss-cn-hangzhou.aliyuncs.com/2022-09-02-00-27-53B.jpg","job": 2,"salary": 8000,"entryDate": "2015-01-01","deptId": 2,"deptName": "教研部","createTime": "2022-09-01T23:06:30","updateTime": "2022-09-02T00:29:04"},{"id": 2,"username": "zhangwuji","password": "123456","name": "张无忌","gender": 1,"image": "https://web-framework.oss-cn-hangzhou.aliyuncs.com/2022-09-02-00-27-53B.jpg","job": 2,"salary": 6000,"entryDate": "2015-01-01","deptId": 2,"deptName": "教研部","createTime": "2022-09-01T23:06:30","updateTime": "2022-09-02T00:29:04"}]}
}目前我们只考虑分页查询,先不考虑查询条件,而上述的接口文档中,与分页查询相关的参数就两个,一个是page,一个是pageSize。
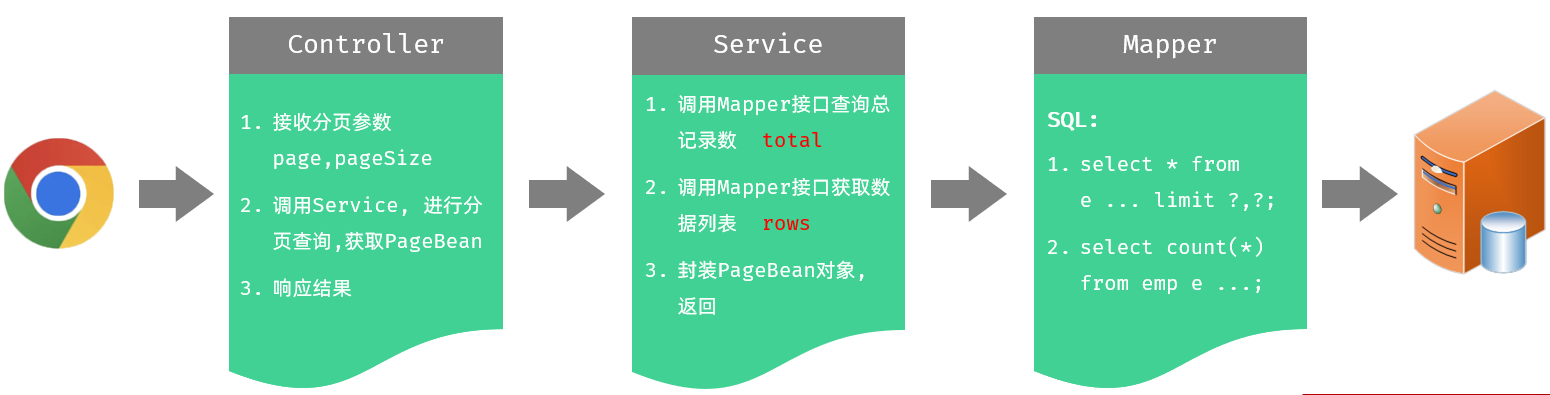
3.3.1.3 思路分析
3.3.1.4 代码实现
1). EmpController
@Slf4j
@RestController
public class EmpController {@Autowiredprivate EmpService empService;/*** 分页查询* @param page* @param pageSize* @return*/@GetMapping("/emps")public Result page(@RequestParam(defaultValue = "1") Integer page,@RequestParam(defaultValue = "10") Integer pageSize){log.info("分页查询:{},{}",page,pageSize);PageBean pagebean = empService.page(page,pageSize);return Result.success(pagebean);}
}
当前端没有返回page和pageSize数据时,我们需要设置一个初始的默认值:
@RequestParam(defaultValue = "默认值") //设置请求参数默认值
2). EmpServiceImpl
@Service
public class EmpServiceImpl implements EmpService {@Autowiredprivate EmpMapper empMapper;/*** 分页查询* @param page 当前页码* @param pageSize 每页显示数量* @return*/@Overridepublic PageBean page(Integer page, Integer pageSize) {//1.调用mapper获取总记录数 total//select count(*) from empLong total = empMapper.count();//要包装的实体类total是Long类型,所以接收的数据用Long//2.调用mapper获取分页列表数据 rows//select e.name,e.gender,e.image,d.name,e.job// from emp e left join dept d// on e.dept_id = d.id limit 0,5;Integer start = (page - 1) * pageSize; //计算开始索引List<Emp> empList = empMapper.page(start,pageSize);//3.封装PageBean对象并返回return new PageBean(total,empList);}
}
3). EmpMapper
@Mapper
public interface EmpMapper {/*** 统计员工的记录数* @return*/@Select("select count(*) from emp")Long count();/*** 分页查询员工数据* @param start* @param pageSize* @return*/@Select("select e.*,d.name deptName from emp e left join dept d on e.dept_id = d.id limit #{start},#{pageSize}")//注意部门名称一定要起别名,要对应Emp对象中的属性名List<Emp> page(Integer start, Integer pageSize);
}
3.3.2 分页插件
3.3.2.1 介绍
前面我们只进行了基础的分页查询,我们发现分页查询起来比较繁琐。我们在进行分页查询时,查询用户信息、订单信息、商品信息等等都是需要进行分页查询的。
分页查询的思路和步骤是比较固定的。在Mapper接口中定义两个方法执行不同的两个SQL语句:
- 查询总记录数
- 指定页码的数据列表
在Service当中,调用Mapper接口的两个方法,分别获取:总记录数(Long total)、查询结果列表(List rows),然后在将获取的数据结果封装到PageBean对象中。
我们可以使用现成的分页插件完成分页查询操作。对于Mybatis来讲现在最主流的就是PageHepler
PageHelper是第三方提供的Mybatis框架中的一款功能强大、方便易用的分页插件,支持任何形式的单标、多表的分页查询。
官网:MyBatis 分页插件 PageHelper
那接下来,我们可以对比一下,使用PageHelper分页插件进行分页 与 原始方式进行分页代码实现的上的差别。
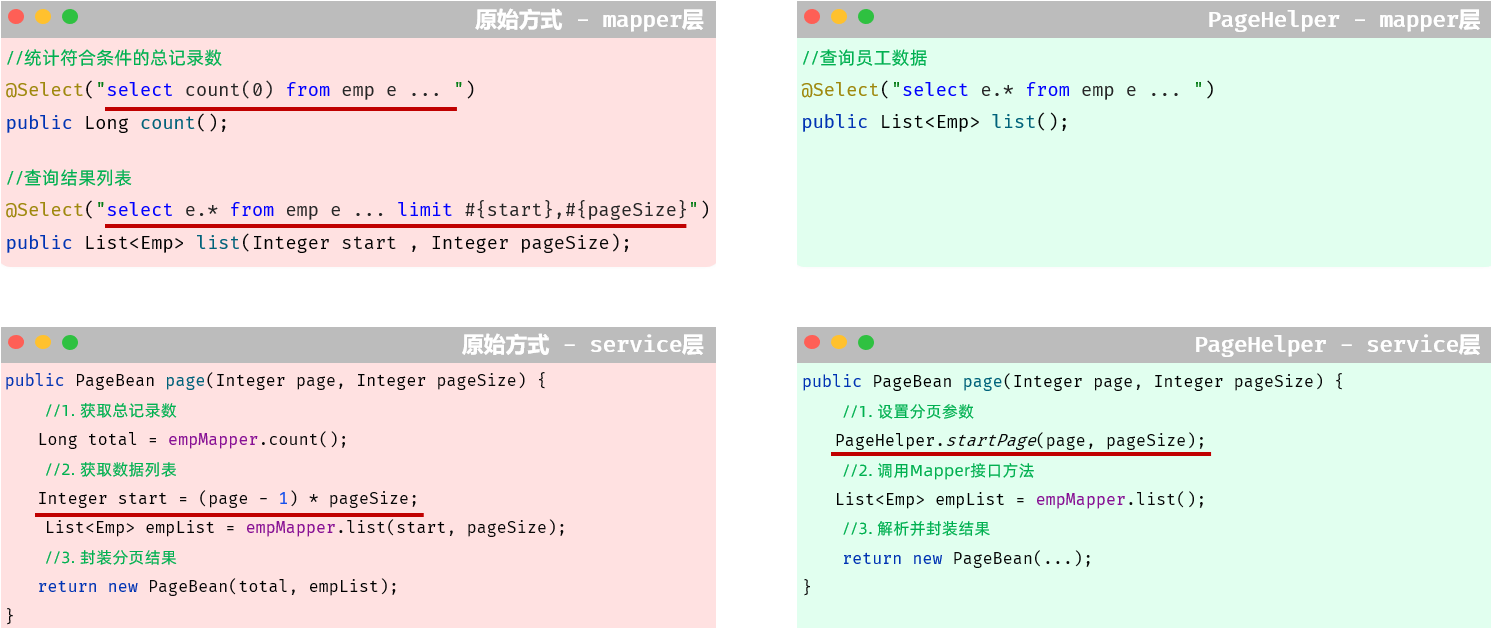
-
Mapper接口层:
-
原始的分页查询功能中,我们需要在Mapper接口中定义两条SQL语句。
-
PageHelper实现分页查询之后,只需要编写一条SQL语句,而且不需要考虑分页操作,就是一条正常的查询语句。
-
-
Service层:
-
需要根据页码、每页展示记录数,手动的计算起始索引。
-
无需手动计算起始索引,直接告诉PageHelper需要查询那一页的数据,每页展示多少条记录即可。
-
3.3.2.2 代码实现
1、在pom.xml引入依赖
<!--分页插件PageHelper-->
<dependency><groupId>com.github.pagehelper</groupId><artifactId>pagehelper-spring-boot-starter</artifactId><version>1.4.7</version>
</dependency>2、EmpMapper
@Mapper
public interface EmpMapper {/*** 统计员工的记录数* @return*/
// @Select("select count(*) from emp")
// Long count();/*** 分页查询员工数据* @param start* @param pageSize* @return*/
// @Select("select e.*,d.name deptName from emp e left join dept d on e.dept_id = d.id limit #{start},#{pageSize}")
// //注意部门名称一定要起别名,要对应Emp对象中的属性名
// List<Emp> page(Integer start, Integer pageSize);@Select("select e.*,d.name deptName from emp e left join dept d on e.dept_id = d.id")List<Emp> list();
}3、EmpServiceImpl
@Service
public class EmpServiceImpl implements EmpService {@Autowiredprivate EmpMapper empMapper;/*** 分页查询* @param page 当前页码* @param pageSize 每页显示数量* @return*/@Overridepublic PageBean page(Integer page, Integer pageSize) {//1.设置分页参数PageHelper.startPage(page,pageSize);//2.调用mapper的列表查询方法List<Emp> empList = empMapper.list();Page p = (Page) empList;//强转为Page对象,Page对象中封装了分页数据,继承了ArrayList//运行后并不会替换select语句//分页只会对PageHelper.startPage()下面的第一条select语句进行处理,必须再加一个PageHelper.startPage(page,pageSize);
// PageHelper.startPage(page,pageSize);
// List<Emp> empList1 = empMapper.list();//3.封装PageBean对象并返回return new PageBean(p.getTotal(),p.getResult());//return new PageBean(p.getTotal(),p);//return new PageBean(p.getTotal(),empList);}3.3.2.3 实现机制
我们打开Idea的控制台,可以看到在进行分页查询时,输出的SQL语句。

我们看到执行了两条SQL语句,而这两条SQL语句,其实是从我们在Mapper接口中定义的SQL演变而来的。
- 第一条SQL语句,用来查询总记录数。

其实就是将我们编写的SQL语句进行的改造增强,将查询返回的字段列表替换成了 count(0) 来统计总记录数。
- 第二条SQL语句,用来进行分页查询,查询指定页码对应 的数据列表。

其实就是将我们编写的SQL语句进行的改造增强,在SQL语句之后拼接上了limit进行分页查询,而由于测试时查询的是第一页,起始索引是0,所以简写为limit ?。
而PageHelper在进行分页查询时,会执行上述两条SQL语句,并将查询到的总记录数,与数据列表封装到了 Page<Emp> 对象中,我们再获取查询结果时,只需要调用Page对象的方法就可以获取。
注意:
1. PageHelper实现分页查询时,SQL语句的结尾一定一定一定不要加分号(;).。
2. PageHelper只会对紧跟在其后的第一条SQL语句进行分页处理。
3.4 分页查询(带条件)
3.4.1 需求
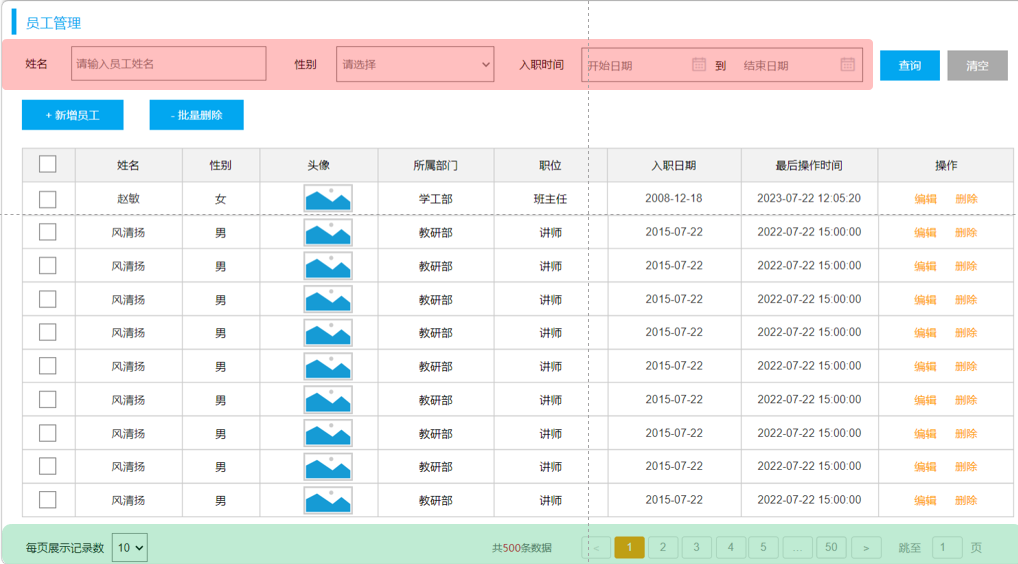
员工列表页面的查询,不仅仅需要考虑分页,还需要考虑查询条件,分页查询我们实现之后,现在我们要考虑的是在分页查询的基础上,再加上条件查询。
-
姓名:模糊匹配
-
性别:精确匹配
-
入职日期:范围匹配
select e.*, d.name deptName from emp as e left join dept as d on e.dept_id = d.id
where e.name like concat('%','张','%') -- 条件1:根据姓名模糊匹配and e.gender = 1 -- 条件2:根据性别精确匹配and e.entry_date = between '2000-01-01' and '2010-01-01' -- 条件3:根据入职日期范围匹配
order by update_time desc;而且上述的三个条件,都是可以传递,也可以不传递的,也就是动态的。
1). 如果用户仅输入了姓名,则SQL为:
select e.*, d.name deptName from emp as e left join dept as d on e.dept_id = d.id where e.name like ? 2). 如果用户仅选择了性别,则SQL为:
select e.*, d.name deptName from emp as e left join dept as d on e.dept_id = d.id where e.gender = ?3). 如果用户输入了姓名 和 性别 , 则SQL为:
select e.*, d.name deptName from emp as e left join dept as d on e.dept_id = d.id where e.name like ? and e.gender = ?我们需要使用前面学习的Mybatis中的动态sql
3.4.2 思路分析
3.4.3 功能开发
通过查看接口文档:员工列表查询
请求路径:/emps
请求方式:GET
请求参数:
| 参数名称 | 是否必须 | 示例 | 备注 |
|---|---|---|---|
| name | 否 | 张 | 姓名 |
| gender | 否 | 1 | 性别 , 1 男 , 2 女 |
| begin | 否 | 2010-01-01 | 范围匹配的开始时间(入职日期) |
| end | 否 | 2020-01-01 | 范围匹配的结束时间(入职日期) |
| page | 是 | 1 | 分页查询的页码,如果未指定,默认为1 |
| pageSize | 是 | 10 | 分页查询的每页记录数,如果未指定,默认为10 |
在原有分页查询的代码基础上进行改造。
3.4.3.1 Controller
方式一:在Controller方法中通过多个方法形参,依次接收这几个参数
@GetMapping("/emps")public Result page(String name, Integer gender,@DateTimeFormat(pattern = "yyyy-MM-dd") LocalDate begin,@DateTimeFormat(pattern = "yyyy-MM-dd") LocalDate end,@RequestParam(defaultValue = "1") Integer page,@RequestParam(defaultValue = "10") Integer pageSize){log.info("分页查询:{},{},{},{},{},{}",name,gender,begin,end,page,pageSize);PageBean pagebean = empService.page(name,gender,begin,end,page,pageSize);return Result.success(pagebean);}场景:如果参数个数比较少,建议直接接收即可。如果参数个数比较多,这种接收方式不便于维护管理。
方式二:在Controller方法中通过实体对象封装多个参数。(实体属性与请求参数名保持一致)
1). 定义实体类
@Data
@AllArgsConstructor
@NoArgsConstructor
public class EmpQueryParam {private Integer page = 1;private Integer pageSize = 10;private String name;private Integer gender;@DateTimeFormat(pattern = "yyyy-MM-dd")private LocalDate begin;@DateTimeFormat(pattern = "yyyy-MM-dd")private LocalDate end;
}
2). Controller方法中通过实体类,封装多个参数
@GetMapping("/emps")public Result page(EmpQueryParam param){log.info("分页查询:{},{},{},{},{},{}",param.getName(),param.getGender(),param.getBegin(),param.getEnd(),param.getPage(),param.getPageSize());PageBean pagebean = empService.page(param);return Result.success(pagebean);}场景:请求参数比较多时,可以将多个参数封装到一个对象中。
3.4.3.2 Service
在EmpServiceImpl中实现page方法进行分页条件查询
@Overridepublic PageBean page(EmpQueryParam param) {//1.设置分页参数PageHelper.startPage(param.getPage(),param.getPageSize());//2.调用mapper的列表查询方法List<Emp> empList = empMapper.list(param);Page p = (Page) empList;//强转为Page对象,Page对象中封装了分页数据,继承了ArrayListreturn new PageBean(p.getTotal(),p.getResult());}3.4.3.3 Mapper
在EmpMapper中增加如下接口方法 (前面实现的分页查询的方法可以注释了)
//基于xml开发动态sql
List<Emp> list(EmpQueryParam param);创建EmpMapper接口对应的映射配置文件 EmpMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.itheima.mapper.EmpMapper"><select id="list" resultType="com.itheima.entity.Emp">select e.*, d.name deptNamefrom emp eleft join dept d on e.dept_id = d.id<where><if test="name != null and name != ''">e.name like concat('%',#{name},'%')</if><if test="gender != null">and e.gender = #{gender}</if><if test="begin != null and end != null">and e.entry_date between #{begin} and #{end}</if>order by e.update_time desc</where></select>
</mapper>
<where>标签的作用:
自动根据条件判断是否添加
where关键字可以自动去除掉第一个条件前面多余的
and或or
注意:这里e.name like concat('%',#{name},'%') ,不能直接用e.name like '%#{name}%' ,#符号不能在百分号和引号之间,需要用concat函数拼接字符串。
3.4.4 功能测试
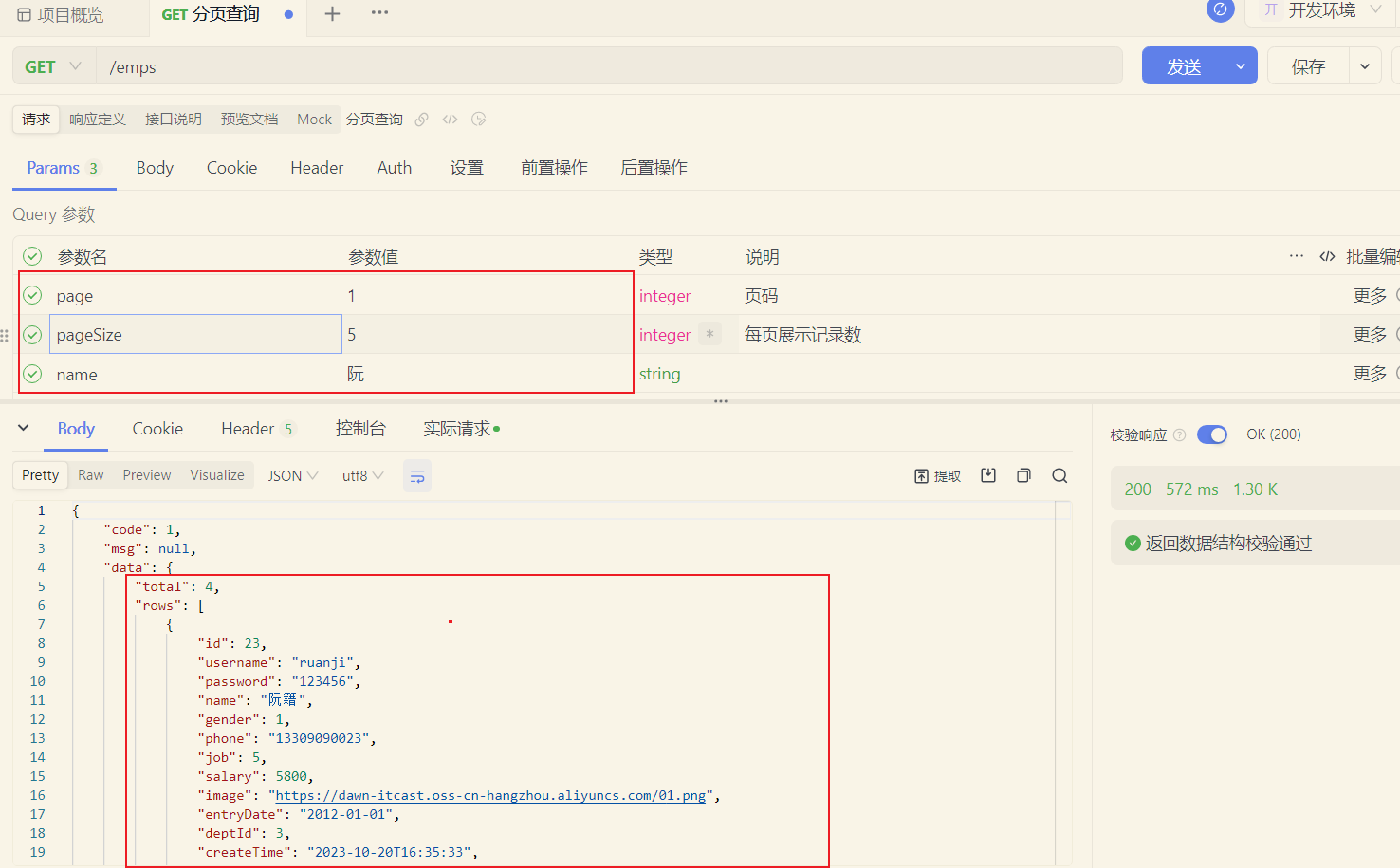
控制台SQL语句:

3.4.5 前后端联调