大模型落地:从微调到部署的全景式实战指南
引言:大模型时代的挑战与机遇
大型语言模型(LLM)如GPT、LLaMA、ChatGLM等的出现,标志着人工智能进入了一个全新的时代。它们展现出前所未有的通用知识、强大的逻辑推理和流畅的内容生成能力。然而,将这些“无所不知”的通用基座模型直接应用于特定的企业场景(如金融风控、医疗诊断、智能客服)时,往往会面临“隔靴搔痒”的困境:答案可能笼统、缺乏领域深度、甚至包含事实性错误。
因此,大模型落地的核心命题不再是“有没有模型”,而是“如何让通用模型在特定场景下变得专、精、准、稳”。本文将深入探讨实现这一目标的四大关键技术路径:大模型微调 (Fine-tuning)、提示词工程 (Prompt Engineering)、多模态应用 (Multimodal Application) 及 企业级解决方案 (Enterprise Solutions)。我们将结合理论、代码、流程图和实例,为您提供一份全面的实践指南。
第一章:大模型微调 (Fine-Tuning) - 为模型注入领域灵魂
微调是让预训练的大模型适应特定任务或领域的最核心、最有效的方法。它不像提示工程那样只是给模型“临时指令”,而是对模型本身的参数进行“外科手术式”的调整,从根本上改变其行为模式。
1.1 微调的基本原理
想象一下,一个医学预科生(预训练模型)已经具备了丰富的生物学、化学基础知识(通用知识)。要成为一名心外科医生(领域专家),他需要进入医院,在大量的心脏手术案例(领域数据)上进行专项学习和训练(微调)。微调的过程就是利用领域数据,以较小的学习率继续训练模型,避免破坏其已有的通用知识,同时强化其在特定领域的表现。
微调的优势:
效果卓越:通常在特定任务上表现远超零样本或少样本提示。
行为固化:一次微调,永久生效,无需在每次请求时编写复杂的提示。
知识注入:能将训练数据中蕴含的新知识、新风格内化到模型参数中。
微调的挑战:
计算成本高:需要GPU资源,尤其是全参数微调。
数据需求:需要一定数量和质量的有标注数据。
灾难性遗忘:可能在适应新领域时遗忘原有的通用知识。
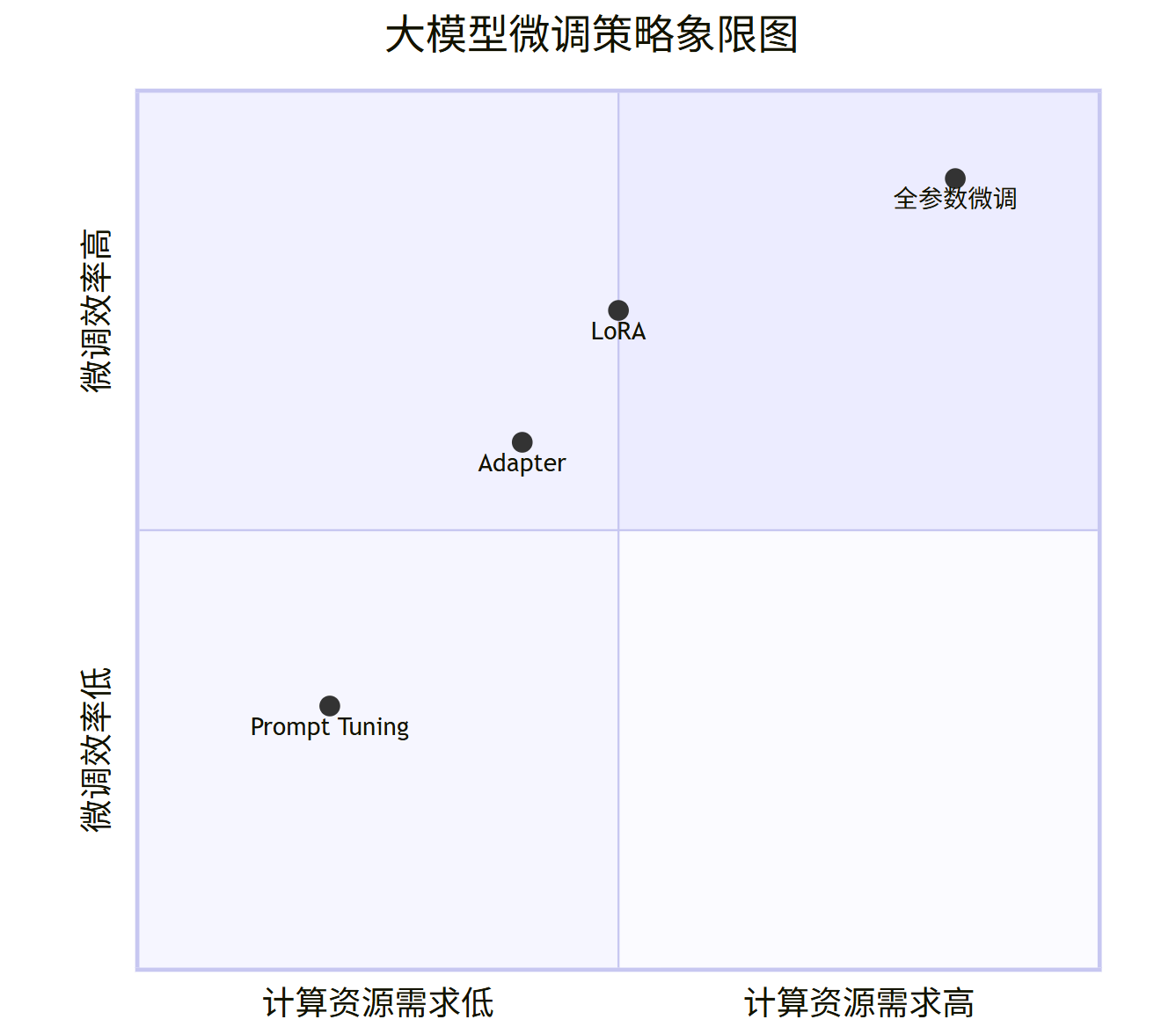
1.2 微调策略全景图
根据计算资源和数据量的不同,我们可以选择不同的微调策略,其计算成本和效率对比如下所示。
quadrantCharttitle 大模型微调策略象限图x-axis "计算资源需求低" --> "计算资源需求高"y-axis "微调效率低" --> "微调效率高""全参数微调": [0.85, 0.9]"LoRA": [0.5, 0.75]"Prompt Tuning": [0.2, 0.3]"Adapter": [0.4, 0.6]
1.3 代码实战:使用PEFT库进行LoRA微调
我们将使用Hugging Face的transformers和peft库,对一个较小的模型(如facebook/opt-125m)进行LoRA微调,以实现一个文本分类任务。
环境准备:
bash
pip install transformers datasets peft accelerate torch
数据集准备(使用IMDB电影评论情感分类数据集):
python
from datasets import load_datasetdataset = load_dataset("imdb")
# 查看数据集结构
print(dataset["train"][0])模型加载与预处理:
python
from transformers import AutoTokenizer, AutoModelForSequenceClassification, DataCollatorWithPadding
import torchmodel_name = "facebook/opt-125m"
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token # OPT模型没有明确的pad_token,用eos_token代替def tokenize_function(examples):return tokenizer(examples["text"], truncation=True, max_length=512)tokenized_datasets = dataset.map(tokenize_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)# 我们需要将标签映射到模型上
id2label = {0: "NEGATIVE", 1: "POSITIVE"}
label2id = {"NEGATIVE": 0, "POSITIVE": 1}model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2, id2label=id2label, label2id=label2id
)配置LoRA:
python
from peft import LoraConfig, get_peft_model, TaskTypelora_config = LoraConfig(task_type=TaskType.SEQ_CLS, # 序列分类任务inference_mode=False,r=8, # Ranklora_alpha=32,lora_dropout=0.1,target_modules=["q_proj", "v_proj"] # 这是OPT模型中的模块名,不同模型不同 )lora_model = get_peft_model(model, lora_config) lora_model.print_trainable_parameters() # 查看可训练参数比例 # 输出: trainable params: 471,042 || all params: 125,194,242 || trainable%: 0.3763%
训练循环:
python
from transformers import TrainingArguments, Trainertraining_args = TrainingArguments(output_dir="./lora_opt_imdb",learning_rate=1e-4,per_device_train_batch_size=8,per_device_eval_batch_size=8,num_train_epochs=3,weight_decay=0.01,evaluation_strategy="epoch",save_strategy="epoch",load_best_model_at_end=True, )trainer = Trainer(model=lora_model,args=training_args,train_dataset=tokenized_datasets["train"].select(range(1000)), # 为演示只取1000条eval_dataset=tokenized_datasets["test"].select(range(200)),tokenizer=tokenizer,data_collator=data_collator, )trainer.train()
保存与加载:
python
# 保存适配器权重
lora_model.save_pretrained("./lora_opt_imdb_adapter")# 加载:先加载原模型,再加载适配器
from peft import PeftModelbase_model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2, id2label=id2label, label2id=label2id
)
loaded_lora_model = PeftModel.from_pretrained(base_model, "./lora_opt_imdb_adapter")# 用于推理时,可以将适配器与模型合并,以减少推理开销
merged_model = loaded_lora_model.merge_and_unload()通过以上步骤,我们成功地对一个通用模型进行了高效的领域定制。LoRA使得我们只用训练不到0.4%的参数,就达到了非常好的效果,极大地节省了资源。
第二章:提示词工程 (Prompt Engineering) - 与模型高效沟通的艺术
提示词工程是与大模型交互最直接、最快速的方式。它不需要改变模型权重,而是通过精心设计和构造输入文本(提示词),来引导模型生成期望的输出。这是一种“激发”模型潜力的艺术。
2.1 核心思想与原则
提示词的核心思想是提供上下文和指令,让模型明白它当前所处的角色、要完成的任务以及输出的格式。一个好的提示词应遵循以下原则:
清晰明确:指令无歧义。
提供上下文:给予模型完成任务所需的背景信息。
设定角色:让模型扮演某个专家角色,如“你是一位资深的医学博士”。
分解任务:将复杂任务拆解成模型易于执行的子步骤。
示例示范:提供少量示例(Few-Shot Learning),展示输入输出的格式和质量。
2.2 高级提示技巧
除了基本的指令,还有许多高级技巧可以大幅提升提示效果。
零样本(Zero-Shot):直接给出指令,不提供示例。依赖模型的内化知识。
Prompt:
将以下中文翻译成英文:今天天气真好。
少样本(Few-Shot):提供几个输入输出的示例,让模型从中学习模式。
Prompt:
text
翻译中文到英文: 输入:你好 -> 输出:Hello 输入:我爱你 -> 输出:I love you 输入:今天天气真好 -> 输出:
思维链(Chain-of-Thought, CoT):要求模型逐步推理,而不是直接给出答案。这对于数学、逻辑问题至关重要。
Prompt:
Q: 一个篮子里有5个苹果,小明拿走了2个,又放进去3个。现在篮子里还有几个苹果?请逐步思考。A:
首先,篮子里有5个苹果。然后,小明拿走了2个,所以剩下5-2=3个。接着,他又放进去3个,所以现在有3+3=6个。因此,答案是6。
自洽性(Self-Consistency):对同一个问题用CoT生成多个推理路径,然后取最多数的答案作为最终结果,提高准确率。
生成知识提示(Generate Knowledge Prompting):先让模型生成一些可能与问题相关的知识或事实,然后再利用这些知识来回答问题。
2.3 代码实战:构建一个复杂的提示词引擎
我们将使用LangChain,一个强大的LLM应用开发框架,来构建一个复杂的提示流程。
安装LangChain:
bash
pip install langchain openai # 或者使用其他模型,如 Anthropic、Hugging Face Hub
构建一个包含角色、步骤和示例的复杂提示词:
python
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI # 或者使用 ChatOpenAI
import osos.environ["OPENAI_API_KEY"] = "your-api-key"# 1. 定义提示模板
template = """
你是一位经验丰富、乐于助人的{domain}专家。
你的任务是根据用户输入,生成一个符合要求的{output_type}。请按照以下步骤执行:
1. 首先,分析输入的核心意图和关键信息。
2. 其次,根据这些信息,构建出{output_type}的核心框架。
3. 然后,使用专业、{tone}的语言填充内容。
4. 最后,检查并润色成品,确保其准确、流畅。以下是几个示例:
{examples}现在,请处理以下输入:
输入:{user_input}
输出:
"""prompt = PromptTemplate(input_variables=["domain", "output_type", "tone", "examples", "user_input"],template=template,
)# 2. 准备示例
few_shot_examples = """
示例1:
输入:撰写一篇关于人工智能在医疗领域应用的博客文章开头段落。
输出:人工智能(AI)正以前所未有的速度重塑医疗健康的未来。从通过医学影像精准识别病灶,到加速新药研发的进程,AI技术已成为推动医疗行业变革的关键力量。本文将深入探讨...示例2:
输入:为我们的新咖啡店“Sunrise Cafe”写一条吸引年轻人的社交媒体推文。
输出:早安!☀️ 厌倦了连锁店的千篇一律?来#SunriseCafe,唤醒你的味蕾!我们采用单一产地精品咖啡豆,现磨现萃,为你带来独一无二的清晨体验。周末前50名顾客享8折优惠!#精品咖啡 #都市生活
"""# 3. 填充模板,生成最终提示
final_prompt = prompt.format(domain="市场营销",output_type="社交媒体广告文案",tone="活泼、吸引人",examples=few_shot_examples,user_input="为我们的新产品‘智能冥想手环’写一条Facebook广告,突出其能监测压力并提供实时冥想指导的功能。"
)print("生成的最终提示词:")
print(final_prompt)# 4. 将最终提示词发送给LLM
llm = OpenAI(model_name="gpt-3.5-turbo-instruct") # 或者使用 ChatOpenAI(model_name="gpt-4")
response = llm(final_prompt, max_tokens=256)
print("\n模型的回复:")
print(response)输出可能类似于:
text
首先,分析输入:核心意图是推广“智能冥想手环”,关键信息是“监测压力”和“实时冥想指导”。 其次,构建框架:广告应以吸引眼球的问句开头,引入产品,突出核心功能,并给出行动号召(CTA)。 然后,填充内容:使用活泼的语气,并加入相关标签。 最终输出: 压力爆表?智能冥想手环懂你!💙 这款创新手环7x24小时监测你的压力水平,并在你需要时通过App提供个性化的冥想指导练习,帮你从内而外恢复平静。现在购买,享受首发优惠!#正念冥想 #健康科技 #压力管理 #智能穿戴 [链接]
这个例子展示了如何通过结构化模板、角色扮演、步骤分解和少样本示例,动态地构建出高质量的提示词,从而可靠地获得符合复杂要求的输出。
第三章:多模态应用 (Multimodal Application) - 打破信息的次元壁
现实世界的信息本质是多模态的:文本、图像、音频、视频等。多模态大模型(Multimodal Large Language Model, MLLM)旨在打破这些模态间的壁垒,让模型能够同时理解和生成不同模态的信息。
3.1 多模态模型的核心能力
视觉问答(VQA):根据图片内容回答问题。
输入:一张图片 + “图片里的人在做什么?”
输出:“他在骑自行车。”
图像描述(Image Captioning):为给定的图像生成一段文字描述。
文本生成图像(Text-to-Image Generation):根据文本描述生成相应的图像。如Stable Diffusion, DALL-E。
多模态对话:在对话中同时理解图像和文本上下文。
文档理解:解析包含文字和图表(如表格、流程图)的文档,并提取或总结信息。
3.2 技术架构:如何实现多模态?
目前主流的多模态模型通常采用以下架构:
graph LRA[输入图像] --> B[视觉编码器<br>(ViT, CNN)]C[输入文本] --> D[文本编码器<br>(BERT, LLM)]B --> E[特征融合器<br>(Cross-Attention, Perceiver)]D --> EE --> F[联合表示]F --> G[文本解码器<br>(LLM)]G --> H[输出文本]
编码阶段:不同模态的输入通过各自的编码器(Encoder)被映射到同一个隐空间(Latent Space)的向量表示。
融合阶段:通过交叉注意力(Cross-Attention)等机制,让文本特征和图像特征进行充分交互。
解码阶段:基于融合后的联合表示,由解码器(通常是语言模型)生成最终的文本输出。
3.3 代码实战:使用BLIP模型进行图像描述和视觉问答
我们将使用Hugging Face transformers 库中的BLIP模型,这是一个非常强大的多模态视觉-语言模型。
安装依赖:
bash
pip install transformers torch Pillow
图像描述(Image Captioning):
python
from transformers import BlipProcessor, BlipForConditionalGeneration
from PIL import Image
import requests# 加载模型和处理器
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")# 准备图像
# 方式1:从本地文件加载
image = Image.open("path/to/your/image.jpg")
# 方式2:从URL下载
url = "https://huggingface.co/datasets/Narsil/image_dummy/raw/main/parrots.png"
image = Image.open(requests.get(url, stream=True).raw)
image.show() # 显示图片# 处理与生成
# 无条件图像描述
inputs = processor(image, return_tensors="pt")
out = model.generate(**inputs, max_length=50)
caption = processor.decode(out[0], skip_special_tokens=True)
print("Generated Caption:", caption)# 条件图像描述(提供文本上下文)
text = "a photography of"
inputs = processor(image, text=text, return_tensors="pt")
out = model.generate(**inputs, max_length=50)
conditional_caption = processor.decode(out[0], skip_special_tokens=True)
print("Conditional Caption:", conditional_caption)视觉问答(Visual Question Answering):
我们将使用BLIP的VQA版本。
python
from transformers import BlipProcessor, BlipForQuestionAnswering# 加载VQA模型
processor_vqa = BlipProcessor.from_pretrained("Salesforce/blip-vqa-base")
model_vqa = BlipForQuestionAnswering.from_pretrained("Salesforce/blip-vqa-base")# 准备图像和问题
question = "How many parrots are in the picture?"
# question = "图片里有多少只鹦鹉?"# 处理与生成
inputs = processor_vqa(image, question, return_tensors="pt")
out = model_vqa.generate(**inputs, max_length=50)
answer = processor_vqa.decode(out[0], skip_special_tokens=True)
print(f"Q: {question}")
print(f"A: {answer}")输出示例:
图像描述:
"two parrots sitting on a perch"视觉问答:
Q: “How many parrots are in the picture?”
A: “two”
这个简单的例子展示了多模态模型如何无缝地连接视觉和语言信息。在企业应用中,这可以用于:
电商:自动为商品图片生成描述标签,或回答用户关于商品的疑问(“这个沙发有红色的吗?”)。
社交媒体:自动为用户上传的图片生成ALT文本,方便视障人士访问。
医疗:辅助分析医学影像报告(需专门训练的医疗模型)。
自动驾驶:理解复杂交通场景并做出决策。
第四章:企业级解决方案 - 构建可靠、可扩展的AI系统
将单个模型能力整合成一个能在真实生产环境中稳定、高效、安全运行的系统,是企业落地的最后一公里,也是最复杂的一环。
4.1 企业级挑战与核心组件
一个企业级大模型解决方案远不止一个API调用。它必须解决以下挑战:
性能与延迟:高并发下的响应速度。
成本控制:Token消耗、计算资源的成本优化。
可控性与安全性:防止有害输出、数据泄露、注入攻击。
可观测性:日志、监控、追踪(Logging, Monitoring, Tracing)。
持续集成与部署(CI/CD):模型的版本管理、灰度发布、回滚。
其核心架构通常如下图所示:
flowchart TDA[客户端 Web/iOS/Android] --> B[API Gateway<br>认证、限流、路由]B --> C[应用服务器<br>业务逻辑]C --> D[提示词工厂<br>动态构建Prompt]D --> E{推理路由}E -- 低成本/简单任务 --> F[云托管大模型API<br>e.g. OpenAI, Anthropic]E -- 高敏感/定制任务 --> G[自托管大模型<br>e.g. vLLM, TGI]E -- 特定领域任务 --> H[微调模型专区<br>LoRA Adapters]F & G & H --> I[输出处理<br>格式化和后处理]I --> J[安全与审查层<br>内容过滤、PII脱敏]J --> K[缓存层<br>存储常见响应]K --> CC --> A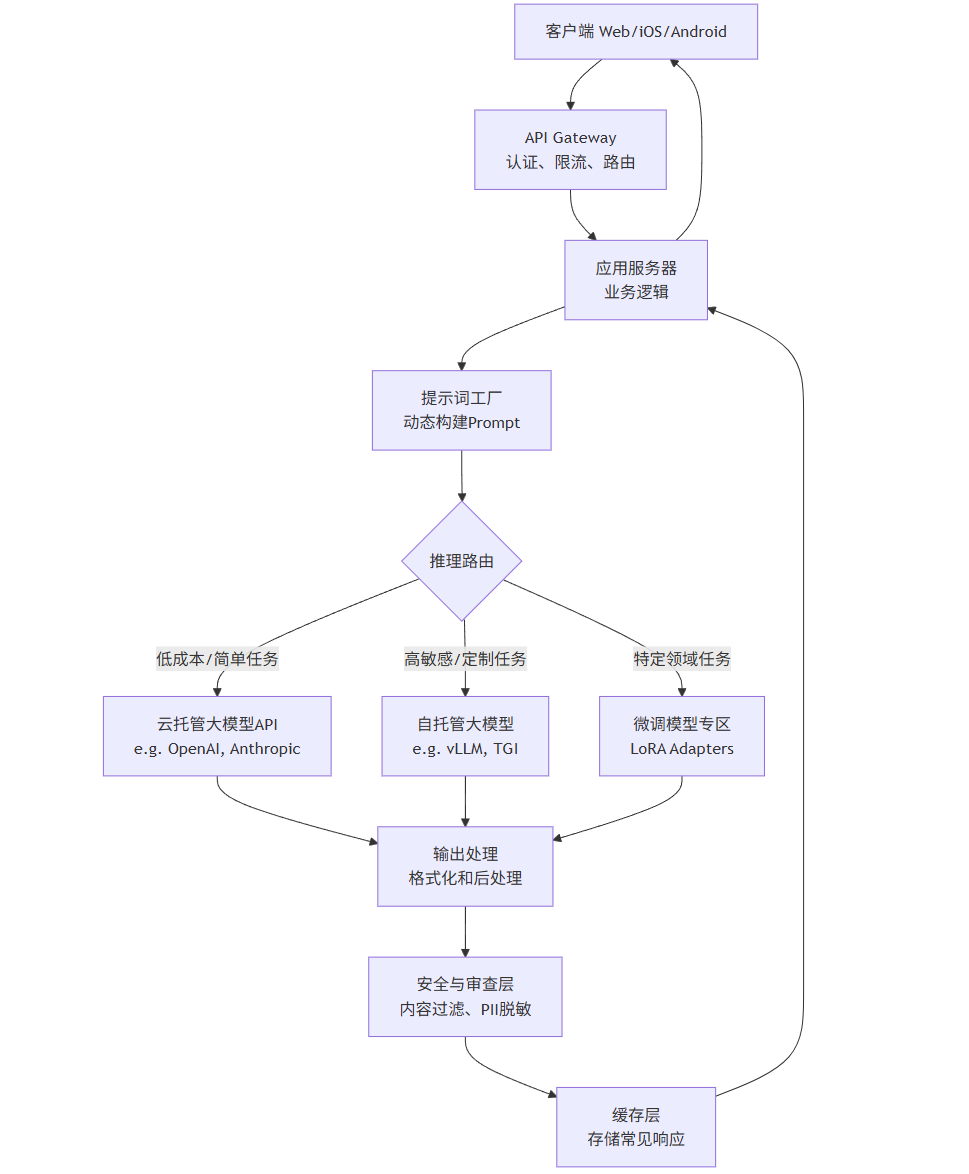
4.2 代码实战:使用LangChain和FastAPI构建企业级应用骨架
我们将使用FastAPI构建一个高性能的Web API,并使用LangChain来编排LLM调用链,集成安全检查和缓存。
安装依赖:
bash
pip install fastapi uvicorn langchain openai python-multipart redis
构建FastAPI应用:
python
# main.py
from fastapi import FastAPI, HTTPException, Depends, Security
from fastapi.security import APIKeyHeader
from pydantic import BaseModel, Field
from typing import Optional, List
import redis
import os
from langchain.cache import RedisCache
from langchain.globals import set_llm_cache
from langchain.llms import OpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.output_parsers import CommaSeparatedListOutputParser# --- 配置和初始化 ---
app = FastAPI(title="Enterprise LLM API")
API_KEY_NAME = "X-API-KEY"
api_key_header = APIKeyHeader(name=API_KEY_NAME, auto_error=False)# 依赖项:验证API Key
async def get_api_key(api_key: str = Security(api_key_header)):if api_key != os.getenv("OUR_API_KEY"): # 简单的验证,实际应使用更安全的方式raise HTTPException(status_code=403, detail="Could not validate credentials")return api_key# 配置Redis缓存
redis_client = redis.Redis(host='localhost', port=6379, db=0)
set_llm_cache(RedisCache(redis_client))# --- Pydantic模型定义 ---
class TextGenerationRequest(BaseModel):prompt: str = Field(..., description="The main user instruction")max_tokens: Optional[int] = 256temperature: Optional[float] = 0.7class ContentCheckRequest(BaseModel):text: str = Field(..., description="Text to be checked for safety")class ContentCheckResponse(BaseModel):is_safe: boolreasons: Optional[List[str]] = None# --- 核心逻辑 ---
# 1. 定义一个简单的安全审查函数
def safety_check(text: str) -> ContentCheckResponse:"""检查文本是否包含有害内容"""banned_words = ["hate", "violence", "self-harm"] # 示例列表,实际应更复杂found_reasons = []for word in banned_words:if word in text.lower():found_reasons.append(f"Detected banned word: {word}")is_safe = len(found_reasons) == 0return ContentCheckResponse(is_safe=is_safe, reasons=found_reasons if not is_safe else None)# 2. 定义一个LangChain链来生成内容
llm = OpenAI(model_name="gpt-3.5-turbo-instruct", temperature=0.7)
output_parser = CommaSeparatedListOutputParser()
prompt_template = PromptTemplate(template="Generate creative ideas for {topic}.\n{format_instructions}",input_variables=["topic"],partial_variables={"format_instructions": output_parser.get_format_instructions()}
)
idea_chain = LLMChain(llm=llm, prompt=prompt_template, output_parser=output_parser)# --- API端点 ---
@app.post("/generate-ideas", summary="Generate creative ideas")
async def generate_ideas(topic: str,request_api_key: str = Depends(get_api_key) # 依赖注入进行认证
):try:# 执行链,LangChain会自动处理缓存result = idea_chain.run(topic=topic)return {"topic": topic, "ideas": result}except Exception as e:raise HTTPException(status_code=500, detail=str(e))@app.post("/generate-text", response_model=dict, summary="Generate text with safety check")
async def generate_text(request: TextGenerationRequest,request_api_key: str = Depends(get_api_key)
):# 0. (可选) 检查用户输入本身是否安全input_check = safety_check(request.prompt)if not input_check.is_safe:raise HTTPException(status_code=400, detail=f"Input content rejected: {input_check.reasons}")# 1. 调用模型生成文本generated_text = llm(request.prompt, max_tokens=request.max_tokens, temperature=request.temperature)# 2. 对输出进行安全审查output_check = safety_check(generated_text)if not output_check.is_safe:# 记录日志并返回错误,而不是返回有害内容# logger.warning(f"Unsafe content generated for prompt: {request.prompt}")raise HTTPException(status_code=500, detail=f"Generated content rejected: {output_check.reasons}")return {"generated_text": generated_text}@app.post("/check-content", response_model=ContentCheckResponse, summary="Check text content safety")
async def check_content(request: ContentCheckRequest,request_api_key: str = Depends(get_api_key)
):return safety_check(request.text)if __name__ == "__main__":import uvicornuvicorn.run(app, host="0.0.0.0", port=8000)运行应用:
bash
OUR_API_KEY="supersecretkey" uvicorn main:app --reload
使用API:
获取创意点子:
bash
curl -X 'POST' \'http://127.0.0.1:8000/generate-ideas?topic=weekend%20activities' \-H 'X-API-KEY: supersecretkey' # 响应: {"topic":"weekend activities","ideas":["Hiking","Reading a book","Visiting a museum","Trying a new recipe"]}生成文本并自动安全检查:
bash
curl -X 'POST' \'http://127.0.0.1:8000/generate-text' \-H 'X-API-KEY: supersecretkey' \-H 'Content-Type: application/json' \-d '{"prompt": "Write a story about a friendly robot", "max_tokens": 100}'
这个示例展示了企业级应用的关键要素:
API认证:通过API Key保护端点。
输入/输出审查:防止生成或处理有害内容。
缓存:使用Redis缓存常见查询结果,降低成本和延迟。
结构化输出:使用Pydantic模型定义清晰的输入/输出模式,便于前端集成和文档生成(FastAPI会自动生成
/docs接口文档)。错误处理:使用HTTP异常码和清晰的信息处理各种错误情况。
在实际部署中,你还需要考虑:
使用更强大的模型网关:如
vLLM或TGI(Text Generation Inference) 来高效地自托管模型。集成分布式追踪:使用
OpenTelemetry来追踪一个请求在所有微服务中的流转。设置速率限制:防止API被滥用。
容器化:使用Docker和Kubernetes进行容器编排和部署。
结论:选择正确的技术路径
大模型落地不是一项单一技术,而是一个需要综合考量业务需求、技术资源和约束的系统工程。四种技术路径并非互斥,而是相辅相成的:
| 技术 | 适用场景 | 资源需求 | 灵活性 | 效果 |
|---|---|---|---|---|
| 提示词工程 | 快速原型、简单任务、黑盒模型 | 低 | 高 | 中等 |
| 微调 | 专业领域、独特风格、极致性能 | 高 | 中 | 高 |
| 多模态 | 理解或生成图像、音频等 | 中-高 | 中 | 依赖任务 |
| 企业级架构 | 生产环境、大规模应用 | 高 | 中 | N/A (赋能) |
决策流程建议:
从提示词工程开始:它总是最快、最便宜的起点。尝试使用思维链、少样本学习等高级技巧,看是否能满足需求。
如果提示词效果不足:考虑微调。如果数据敏感或需要极低延迟,优先选择自托管模型+LoRA等PEFT方法。
如果业务涉及图像、音频等:寻找或训练多模态模型。
无论选择哪种模型技术,都必须将其纳入企业级解决方案的框架中,确保其可靠性、安全性和可扩展性。
大模型技术日新月异,但万变不离其宗。理解这些核心技术的原理、优劣和实现方式,将帮助您和您的企业在这个充满机遇的时代,稳健地迈出智能化的每一步。