【2025ICCV】Vision Transformers 最新研究成果
论文题目:EA-ViT: Efficient Adaptation for Elastic Vision Transformer
1. 研究背景与问题
- 问题:Vision Transformers (ViTs) 在多种视觉任务中表现优异,但部署到不同资源约束的设备(如移动端、云端)需训练多个尺寸的模型,导致训练成本高、存储开销大。
- 现有局限:
- 剪枝+微调方法需为每个设备单独训练模型(成本高)。
- 动态网络结构(如 DynaBERT、HydraViT)仅支持有限子模型尺寸,且需在预训练阶段引入弹性(迁移到下游任务时仍需微调)。
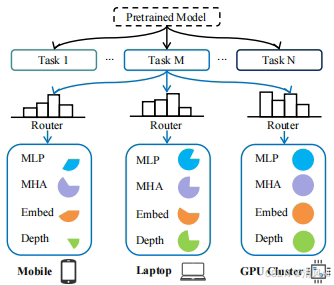
▲ 图1:通过路由模块生成任务特定的弹性子模型,适应不同设备算力约束。
2. EA-ViT 核心方法
阶段1:课程式弹性适配(Curriculum Elastic Adaptation)
-
多维弹性架构: