Linux初始——编译器gcc
编译器
- gcc编译器
- 编译器自举
- 动静态库
- 动静态库的差异
gcc编译器
众所周知,代码运行的前提是经过四个步骤的
- 预处理,其进行宏替换,去注释,条件编译,头文件展开的工作,在gcc的选项中对应gcc -E,其就会生成预处理后的代码,正常的后缀为i,虽然Linux并不以后缀为识别文件的标准,但存在后缀会更好一些。
- 编译,生成汇编代码,对应gcc -S,后缀为s
- 汇编,生成机器可识别代码,对应gcc -c,后缀为o,虽然在汇编之后代码已经成为了二进制代码,但是仍然无法运行,因为没有进行连接,即使只有一个源文件也是需要连接的,
- 连接,生成可执行文件或库文件,对应gcc,即不带选项就会直接生成可执行代码。
编译器自举
众所周知后,计算机语言发展历史为
首先计算机是二进制的原因是二进制足够的简单,历史上出现过三进制的计算机,但也被抛进了历史的垃圾堆。
而CPU为什么能够执行二进制,编写的二进制代码其实是一个指令集,而CPU是能够识别并执行这些指令集的,每一个二进制序列都是一个命令,CPU的解码单元就是为此而生的。
那么为什么会出现后续的汇编语言再到C语言呢?
原因就是人们很难去理解二进制,所以会出现汇编语言,使得一些指令被翻译成人类可以识别的语言,比如0111(加法),在汇编中变为了add,0101(移动),在汇编中变为了mov,这样相比于人们难以理解的二进制代码变为了一个个文字,使得计算机更加的能贴近人们的生活,也让程序员能够更加便捷的去编写代码,同样C语言的诞生也是如此。
但汇编语言在其被发明的时候,计算机为什么能够执行汇编代码?难道在汇编语言被发明的时候就出现了汇编的编译器吗?并不是,而是在出现汇编语言的时候,先使用二进制去写一份汇编语言的编译器,之后在此基础上,在用汇编语言来写一份自己的编译器,此为编译器自举。
动静态库
在上述我们已经了解到在经过汇编后的二进制代码是无法被执行的,但为什么二进制代码无法被执行呢?因为编写的代码会套用很多库文件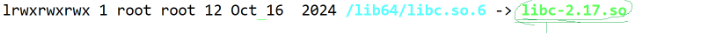
比如图示中的libc-2.17.so就是C标准库,如果没有进行连接将库与二进制代码连接起来,那么源代码中关于库的相关代码就无法运行。

像代码在连接过程去自己寻找标准库连接的就是动态库,如果我们将标准库复制到源代码中,此时不在经过连接就可以直接运行,这种就是静态库,但与此同时,可执行程序的体积将会扩大。当然静态库并不是直接将库给拷贝到源文件中,而是在编译时选择 -static选项,是强制要求编译器采用静态连接的方式进行编译。
动静态库的差异
如上述所说,采用动静态库的第一个差异就是可执行文件的体积差异,但如果库丢失或损坏,那么经过动态连接的程序是无法执行的,但如果是静态连接,是不受影响的,当然编译器默认都是采用动态连接动态库的,这种更高效一些。