秋招 AI 方向 —— 华为机考
- 题目及答案
- 单选题
- 多选题
- 机器学习编程题
- 1. 标签样本数量
- 2. F1 值最优的决策树剪枝
- 知识点
- 线性代数
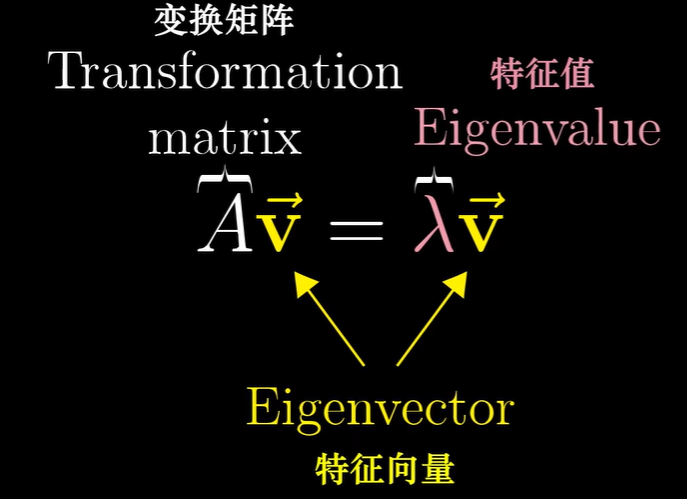
- 特征值和特征向量
- 特征值 VS 奇异值
- 矩阵的秩
- 线性方程组的迭代解法(Jacobi)
- 线性方程组的迭代解法(Gauss–Seidel)
- LU 分解和 QR 分解
- SVD 分解
- SVD 把任意变换分成“旋转 → 缩放 → 旋转”
- 线性代数中的常见矩阵类型
- 实对称矩阵
- 正交矩阵和旋转的关系?
- 概率论
- 朴素贝叶斯(Naive Bayes)
- AI
- 卷积、池化、全连接层和激活函数
- XGBoost 算法
2025 年 8 月 27 日 算法岗笔试题的 15 道单选题 + 5 道多选题 + 2 道机器学习编程题。
题目及答案
单选题
-
下面这段代码执行的功能是什么?
function forward(x, W, b):logits = Wx+bexp_values = exp(logits)return exp_values / sum(exp_values)AAA. 全连接层 + SigmoidSigmoidSigmoid 激活
BBB. 全连接层 + 全局池化操作
CCC. 全连接层 + SoftmaxSoftmaxSoftmax 激活
DDD. 全连接层 + 均值池化操作
答案:CCC,实现的是全连接(线性变换)之后接 SoftmaxSoftmaxSoftmax 激活,把 logitslogitslogits 转成一组概率。
-
TransformerTransformerTransformer 中位置编码的主要作用是?
AAA. 归一化输入
BBB. 引入序列顺序信息
CCC. 增加非线性
DDD. 减少计算量
答案:BBB,自注意力不含位置信息,位置编码用于给模型注入序列顺序。
-
线性方程组 4x+y=6x+3y=34x+y = 6x+3y=34x+y=6x+3y=3 初始解 (x0,y0)=(0,0)(x_0, y_0)=(0,0)(x0,y0)=(0,0),进行一次 JavobiJavobiJavobi 迭代后,(x1,y1)(x_1, y_1)(x1,y1) 是:
AAA. (0,0)(0, 0)(0,0)
BBB. (2,0.5)(2, 0.5)(2,0.5)
CCC. (1,1)(1, 1)(1,1)
DDD. (1.5,1)(1.5, 1)(1.5,1)
答案:DDD,详见下文 Jacobi 迭代
-
关于大模型的"幻觉”(HallucinationHallucinationHallucination)现象,下列说法错误的是
AAA. 模糊或复杂的提示词输入可能导致幻觉
BBB. 指模型生成看似合理但与事实不符的内容
CCC. 增加训练数据的多样性可以完全消除幻觉
DDD. 检索增强生成技术可缓解幻觉问题
答案:CCC,训练多样性只能降低但不能“完全消除”幻觉。
-
已知矩阵 AAA 是 333 阶不可逆矩阵,α1,α2\alpha_1, \alpha_2α1,α2是齐次线性方程组 Ax=0Ax=0Ax=0 的基础解系,α3\alpha_3α3 是矩阵 AAA 属于特征值 λ=2\lambda = 2λ=2 的特征向量,则不是矩阵特征向量的是:
AAA. α1+2α2\alpha_1 + 2 \alpha_2α1+2α2
BBB. −5α3-5 \alpha_3−5α3
CCC. 3α1−4α23 \alpha_1 - 4 \alpha_23α1−4α2
DDD. 2α1+α32 \alpha_1 + \alpha_32α1+α3
答案:DDD,详见下文 特征值和特征向量
-
在 KmeansKmeansKmeans 算法(采用欧式距离)中,存在 444 个簇,簇 C1C_1C1 的中心为 [1,1][1, 1][1,1],簇 C2C_2C2 的中心为 [1,−1][1, -1][1,−1],簇 C3C_3C3 的中心为 [−1,−1][-1, -1][−1,−1],簇 C4C_4C4 的中心为 [−1,1][-1, 1][−1,1],则样本 [2,−2][2, -2][2,−2] 属于:
AAA. 簇 C3C_3C3
BBB. 簇 C1C_1C1
CCC. 簇 C2C_2C2
DDD. 簇 C4C_4C4
答案:CCC,计算到各中心的欧式(平方)距离,到 C2C_2C2 的距离为 2, 最小。
-
矩阵 A=[123456789]A = \begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \\ 7 & 8 & 9 \end{bmatrix}A=147258369 的零空间维度是?
AAA. 111
BBB. 222
CCC. 000
DDD. 333
答案:AAA,矩阵 AAA 的秩为 rank(A)=2rank(A) = 2rank(A)=2,第三行与前两行相关,零空间维数为 3−2=13-2=13−2=1。详见下文 矩阵的秩。
-
对于一个 n×nn \times nn×n 的实对称矩阵 AAA,以下哪个说法是正确的?
AAA. AAA 的特征值一定都是实数
BBB. AAA 的奇异值一定都是复数
CCC. AAA 不能进行 QRQRQR 分解
DDD. AAA 一定可以进行 LULULU 分解
答案:AAA,详见下文 实对称矩阵、LU 分解和 QR 分解。
-
关于奇异值分解(SVDSVDSVD),以下说法错误的是:
AAA. 奇异值矩阵 ∑\sum∑ 的对角元素非负且按降序排列
BBB. SVDSVDSVD 适用于任意 m×nm \times nm×n 矩阵
CCC. 左奇异向量是 AATA A^TAAT 的特征向量
DDD. SVDSVDSVD 唯一确定,即分解结果 U,∑,VU, \sum, VU,∑,V 唯一
答案:DDD,详见下文 SVD 分解
-
若某项目有 nnn 位选手,每两人之间都要进行一次对战(即总共进行 (n2)\binom{n}{2}(2n) 场比赛),最终按胜场数排名,胜场数最高的前 mmm 人晋级决赛,第 mmm 名若出现胜场数并列,则需进行加赛,因此不能保证晋级。请问,一个选手最少需要赢几场才能确保晋级?⌈∗⌉\lceil * \rceil⌈∗⌉ 表示向上取整
AAA. ⌈(2n−m−1)2⌉\lceil\frac{(2n-m-1)}{2}\rceil⌈2(2n−m−1)⌉
BBB. ⌈(m−1)2⌉\lceil\frac{(m-1)}{2}\rceil⌈2(m−1)⌉
CCC. ⌈(m−1)+(n−1)+1m−n+1⌉\left\lceil \frac{(m-1)+(n-1)+1}{m-n+1} \right\rceil⌈m−n+1(m−1)+(n−1)+1⌉
DDD. ⌈(m−1)nm⌉\left\lceil \frac{(m-1)n}{m} \right\rceil⌈m(m−1)n⌉
答案:DDD。晋级需确保胜场数大于剩余 n−mn-mn−m 人可能胜场,公式推导得 ⌈(m−1)nm⌉\left\lceil \frac{(m-1)n}{m} \right\rceil⌈m(m−1)n⌉。
-
任何一个连续型随机变量的概率密度中 ϕ(x)\phi(x)ϕ(x) 一定满足
AAA. 在定义域内单调不减
BBB. ϕ(x)≥1\phi(x) \geq 1ϕ(x)≥1
CCC. 0≤ϕ(x)≤10 \leq \phi(x) \leq 10≤ϕ(x)≤1
DDD. ∫−∞+∞ϕ(x)dx=1\int_{-\infty}^{+\infty} \phi(x)\, dx = 1∫−∞+∞ϕ(x)dx=1
答案:DDD。概率密度函数要求非负且积分为 1。
-
在支持向量机(SVMSVMSVM)中,假设你正在处理一个非线性可分的数据集,并选择了径向基函数(RBFRBFRBF)作为核函数。如果调整参数 CCC (正则化参数)和 γ\gammaγ (核系数)的值,以下哪一项最准确地描述了这两个参数对模型复杂度和泛化能力的影响?
AAA. 减小 CCC 增加正则化强度,使模型更简单;减小 γ\gammaγ 使决策边界更加平滑,但可能导致欠拟合
BBB. 减小 CCC 减少正则化强度,使模型更复杂;减小 γ\gammaγ 使决策边界更加灵活,但可能导致过拟合
CCC. 增大 CCC 减少正则化强度,使模型更复杂;增大 γ\gammaγ 使决策边界更加灵活,但可能导致过拟合
DDD. 增大 CCC 增加正则化强度,使模型更简单;增大 γ\gammaγ 使决策边界更加平滑,但可能导致欠拟合
答案:CCC,增大 CCC →\rightarrow→ 减弱正则 →\rightarrow→ 模型更复杂;增大 γ\gammaγ →\rightarrow→ 边界更灵活;均增加过拟合风险。详见 支持向量机
-
TokenizerTokenizerTokenizer 的核心作用是什么?
AAA. 把文本翻译成中文
BBB. 把文本变成浮点向量
CCC. 把文本翻译成英文
DDD. 把文本变成整数序列
答案:DDD。
-
设 AAA、BBB 为随机事件,且 P(A)=0.5P(A)=0.5P(A)=0.5,P(B)=0.6P(B)=0.6P(B)=0.6,P(B∣A)=0.8P(B|A)=0.8P(B∣A)=0.8,则 P(B∪A)=P(B \cup A) =P(B∪A)=
AAA. 0.70.70.7
BBB. 1.11.11.1
CCC. 0.30.30.3
DDD. 0.80.80.8
答案:AAA。容斥原理(加法规则),基本公式为:P(B∪A)=P(A)+P(B)−P(A∩B)P(B \cup A) = P(A) + P(B) - P(A \cap B)P(B∪A)=P(A)+P(B)−P(A∩B),又由条件概率,P(A∩B)=P(B∣A)P(A)P(A\cap B) = P(B|A)P(A)P(A∩B)=P(B∣A)P(A),可得 0.5+0.6−0.8⋅0.5=0.70.5 + 0.6 - 0.8 \cdot 0.5 = 0.70.5+0.6−0.8⋅0.5=0.7。
-
设总体 XXX 的概率分布为 P(X=1)=1−θ2P(X=1)=\frac{1-\theta}{2}P(X=1)=21−θ,P(X=2)=P(X=3)=1+θ4P(X=2)=P(X=3)=\frac{1+\theta}{4}P(X=2)=P(X=3)=41+θ,利用来自总体的样本值 2,2,1,3,1,3,1,22,2,1,3,1,3,1,22,2,1,3,1,3,1,2,可得 θ\thetaθ 的最大似然估计值为
AAA. 1/21/21/2
BBB. 3/53/53/5
CCC. 1/41/41/4
DDD. 2/52/52/5
答案:CCC。
多选题
-
对线性方程组:{5x+y=2x+3y=4\begin{cases} 5x + y = 2 \\ x + 3y = 4 \end{cases}{5x+y=2x+3y=4 使用高斯-赛德尔迭代法,初始值 (x(0),y(0))=(0,0)(x^{(0)}, y^{(0)}) = (0, 0)(x(0),y(0))=(0,0)。下列结果正确的是?
AAA. 经过两步迭代:x(2)=0.08,y(2)=1.28x^{(2)} = 0.08, y^{(2)} = 1.28x(2)=0.08,y(2)=1.28
BBB. x(1)=0.4x^{(1)} = 0.4x(1)=0.4
CCC. 迭代矩阵的谱半径 ρ(BGs)>1\rho (B_{Gs}) > 1ρ(BGs)>1,方法发散
DDD. y(1)=1.2y^{(1)} = 1.2y(1)=1.2
答案:BBB、DDD,详见下文 Gauss–Seidel 迭代
-
你想使用朴素贝叶斯分类器来过滤垃圾邮件。该模型的核心是贝叶斯公式 P(class∣features)∝P(features∣class)∗P(class)P(\text{class}|\text{features}) \propto P(\text{features}|\text{class}) * P(\text{class})P(class∣features)∝P(features∣class)∗P(class)。为了让这个模型有效工作,你需要从训练数据中估计哪些概率值?
AAA.在给定类别下,每个特征(例如,每个单词)出现的条件概率 P(单词∣类别)P(单词|类别)P(单词∣类别)。
BBB. 每个类别的先验概率 P(类别)P(类别)P(类别),例如 P(垃圾邮件)P(垃圾邮件)P(垃圾邮件) 和 P(正常邮件)P(正常邮件)P(正常邮件)。
CCC. 特征之间的联合概率 P(单词1,单词2∣类别)P(单词1,单词2|类别)P(单词1,单词2∣类别)。
DDD. 每个特征的边缘概率 P(单词)P(单词)P(单词)。
答案:AAA、BBB,详见下文 朴素贝叶斯
-
在卷积神经网络(CNN)中,以下操作属于线性变换的是:
AAA. 卷积操作
BBB. 激活函数 ReLUReLUReLU
CCC. 全连接层
DDD. 池化操作
答案:AAA、CCC,激活函数本来就是为了引入非线性的,最大池化显然也是非线性的。详见下文 卷积、池化、全连接层和激活函数
-
下面关于决策树、XGBoostXGBoostXGBoost 算法的说法,正确的有?
AAA. XGBoostXGBoostXGBoost 不支持正则化机制,无法控制树的复杂度,因此在高维稀疏数据上容易过拟合。
BBB. 决策树通过最小化节点不纯度进行分裂,因此深度越大,训练误差越小,模型泛化性能也越好。
CCC. XGBoostXGBoostXGBoost 在每轮迭代中对损失函数进行二阶泰勒展开,利用梯度和 HessianHessianHessian 信息构建新弱学习器,提升收敛速度与预测精度。
DDD. 基尼不纯度用于衡量节点中样本的类别纯度,其值越大表示样本类别越混杂,常用于分类树的分裂标准。
答案:CCC、DDD,详见下文 XGBoost 算法
-
一位工程师正在为一个包含大量专业术语(如医疗、法律文书)的知识库构建一个 RAGRAGRAG(检索增强生成)系统。在设计和调试文本处理与检索流程时,他得出了一系列结论。请判断下列结论中,哪些是准确的?
AAA. 一个标准的 RAGRAGRAG 系统在处理用户请求时,其信息流是:先将用户的文本查询转换为一个查询向量,用此向量在数据库中检索出最相似的若干个文档块的向量,然后将这些文档块的原始文本(而非它们的向量)与原始查询一同作为上下文,提供给大语言模型(LLMLLMLLM)生成最终答案。
BBB. 在进行文档切分(ChunkingChunkingChunking)时,选择一个极小的、固定的切分尺寸(如 323232 个 tokentokentoken)是最佳策略,因为它能最大化每个文本块(chunkchunkchunk)的语义集中度,从而确保向量检索的精准性。
CCC. 使用一个在通用网络文本上预训练的 TokenizerTokenizerTokenizer 处理这些专业文档时,许多专业术语会被切分成多个通用子词(sub−wordsub-wordsub−word)。这种切分会“稀释"原术语的特定义,可能导致其生成的 EmbeddingEmbeddingEmbedding 向量质量下降。
DDD. 为了优化线上服务的推理速度和成本,可以采用一个强大的重量级模型来离线处理所有文档并生 EmbeddingEmbeddingEmbedding,同时在线上使用一个轻量级模型来实时编码用户的查询(QueryQueryQuery),只要这两个模型都属于同一系列(如都是 BERTBERTBERT 的变体)即可。
答案:AAA、CCC。
AAA 正确:RAGRAGRAG 流程为查询向量化检索文本后送 LLMLLMLLM;CCC 正确:通用 tokenizertokenizertokenizer 切分专业术语会稀释语义;BBB 错误:块过小破坏上下文;DDD 错误:离线在线模型需一致确保向量空间对齐。详见 检索增强生成:RAG
机器学习编程题
1. 标签样本数量
【题目内容】
KNNKNNKNN 算法的核心思想是,如果一个样本在特征空间中的 KKK 个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。请按照下面的步理,实现 KNNKNNKNN 算法。
KNNKNNKNN 算法说明:
计算待分类点到其他样本点的距离;
通过距离进行排序,选择距离最小的 KKK 个点;提取这 KKK 个临近点的类别,根据少数服从多数的原则,将 占比最多的那个标签 赋值给 待分类样本点的 labellabellabel。
本题说明:
1、给定数据集中,默认每一类标签都存在数据,不存在某类型数量为 000 的场景;
2、为消除不同特征权重问题,给出数据均已做好归一化处理,并保留两位小数;
3、出现并列第一的情形时,取并列第一的样本中,最近邻居的标签返回;
4、距离函数定义为:dx,y=∑i=1n(xi−yi)2d_{x,y} = \sqrt{\sum_{i=1}^n(x_i-y_i)^2}dx,y=∑i=1n(xi−yi)2。
【输入描述】
第 111 行:kmnskmnskmns :kkk 代表每次计算时选取的最近邻居个数(不大于 202020 ),mmm 代表样本数量(不大于 200200200 ),nnn 代表样本维度(不包括标签,不大于 555 ),sss 代表类别个数(不于 555);
第 222 行:待分类样本。
第 333 行 ~ 第 m+2m+2m+2 行:mmm 个样本,每一行 n+1n+1n+1 列,最后一列为类别标签 labellabellabel。
【输出描述】
输出待分类样本的类别标签及距离最小的 KKK 个点中的该标签样本数量。
【样例1】
输入:
3 10 2 3
0.81 0.64
0.19 0.2 1.0
0.18 0.14 0.0
0.76 0.58 1.0
0.4 0.16 1.0
0.98 0.85 0.0
0.42 0.97 1.0
0.75 0.26 1.0
0.24 0.06 1.0
0.97 0.8 0.0
0.21 0.1 2.0
输出:
0 2
【说明】
第 111 行输入说明输入了 m=10m=10m=10 个样本,每个样本有 n=2n=2n=2 个维度的数据(去除最后一列标签),共有 s=3s=3s=3 种类别;
第 222 行输入待分类样本的 nnn 维数据;
从第 333 行到第 121212 行的前两列数据为输入的 m=10m=10m=10 个样本,每个样本有 n=2n=2n=2 个维度的数据 + 最后一列的标签数据;
待分类样本 [0.81,0.64][0.81, 0.64][0.81,0.64] 最近的前 k=3k=3k=3 个邻居分别为:[0.76,0.58],[0.98,0.85],[0.97,.08][0.76, 0.58],[0.98, 0.85], [0.97,.08][0.76,0.58],[0.98,0.85],[0.97,.08],分别有 222 个 000 号标签和 111 个 111 号标签,000 号标签占多,返回 000 以及标签 000 的样本数量 222。
【样例2】
输入:
6 10 2 4
0.78 0.63
0.57 0.07 1.0
0.5 0.13 1.0
0.83 0.07 3.0
0.27 0.87 3.0
0.81 0.44 2.0
0.21 0.73 3.0
0.45 0.91 1.0
0.12 0.22 2.0
0.25 0.48 0.0
0.54 0.87 1.0
输出:
1 2
【说明】
本样例的距离最小的 666 个样本中,标签 111 和标签 333 出现次数都是 222 次,并列第一;虽然 [0.8,0.44][0.8,0.44][0.8,0.44] 距离样本最近,但其标签 222 不是出现最多的,排除在下一轮统计样本中此时需要从标签 111 和标签 333 中的样本中,选取距离最近的 [0.54,0.87][0.54,0.87][0.54,0.87] 的标签 111 作为返回值,并同时返回标签 111 的样本数量 222。
【解题思路】
2. F1 值最优的决策树剪枝
知识点
线性代数
特征值和特征向量
3Blue1Brown 特征向量与特征值
比如下面这个 二维空间中的线性变换,把 iii 基向量变换到 (3,0)(3, 0)(3,0),把 jjj 基向量变换到 (1,2)(1, 2)(1,2),如果用矩阵来表示该线性变换,它的列就是这两个变换后的基向量,
大部分向量在变换中都离开了 其张成的空间,即该向量所在的直线,不过 某些向量在变换中的确留在了其张成的空间,意味着 矩阵对它的作用仅仅是拉伸或压缩而已,如同一个标量。例如,iii 基向量变成了原来的 3 倍,仍留在 xxx 轴上,xxx 轴上的任何其他向量都只是被拉伸为原来的 3 倍;还有一个 (−1,1)(-1, 1)(−1,1),它在变换中也留在自己张成的空间里,最终被拉伸为 2 倍。
这些特殊向量(留在它们张成的空间),就被称为变换的 特征向量,每个特征向量对应的其在变换中拉伸或压缩比例的值,叫做该特征向量的 特征值。
考虑一个 三维空间中的旋转,如果你能找到这个旋转的 特征向量,也就是留在它张成的空间里的向量,那么你找到的就是 旋转轴。

当且仅当 矩阵所代表的变换将空间压缩到更低的维度时,才会存在一个非零向量,使得矩阵和它的乘积为零向量,而 空间压缩对应的就是矩阵的行列式为零。
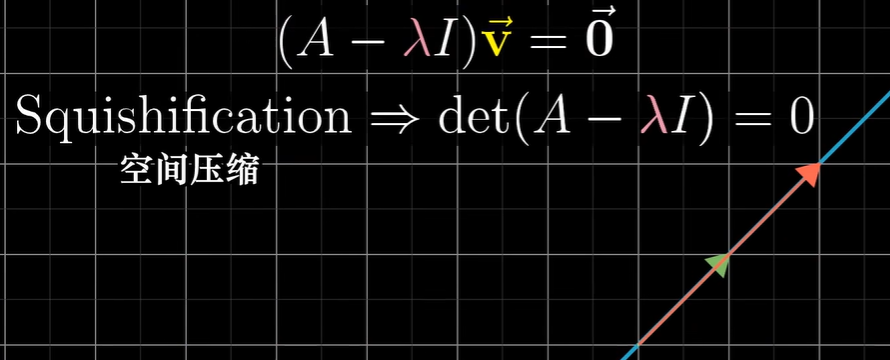



- 同一特征值对应的特征向量 的 任意非零线性组合 仍然是 该特征值的特征向量(构成该特征值的特征子空间)。
- 不同特征值对应的特征向量 之间一般 线性无关,且它们的 非平凡线性组合通常不是特征向量(除非组合恰好退化成某一特征子空间内的向量)。
本题中,已知 α1,α2\alpha_1,\alpha_2α1,α2 是齐次方程 Ax=0A x=0Ax=0 的基础解系,说明 Aα1=0,Aα2=0A\alpha_1=0,\;A\alpha_2=0Aα1=0,Aα2=0。所以 α1,α2\alpha_1,\alpha_2α1,α2 都是对应特征值 λ=0\lambda=0λ=0 的特征向量,且任意非零线性组合(例如 α1+2α2\alpha_1+2\alpha_2α1+2α2、3α1−4α23\alpha_1-4\alpha_23α1−4α2)仍然是特征值 0 的特征向量。
已知 α3\alpha_3α3 是对应特征值 λ=2\lambda=2λ=2 的特征向量,所以任意非零标量倍数(例如 −5α3-5\alpha_3−5α3)仍是特征向量。
检查 DDD:v=2α1+α3v=2\alpha_1+\alpha_3v=2α1+α3。Av=2Aα1+Aα3=2⋅0+2α3=2α3.A v = 2A\alpha_1 + A\alpha_3 = 2\cdot 0 + 2\alpha_3 = 2\alpha_3.Av=2Aα1+Aα3=2⋅0+2α3=2α3. 若 vvv 是某个特征值 θ\thetaθ 对应的特征向量,则需满足 Av=θv=θ(2α1+α3)A v = \theta v = \theta(2\alpha_1+\alpha_3)Av=θv=θ(2α1+α3)。比较两边得到
2α3=2θα1+θα3.2\alpha_3 = 2\theta\alpha_1 + \theta\alpha_3. 2α3=2θα1+θα3.
由于 α1\alpha_1α1(属于 eigenspace λ=0\lambda=0λ=0)与 α3\alpha_3α3(属于 eigenspace λ=2\lambda=2λ=2)是线性无关的(不同特征值对应的特征向量线性无关),上式在 α1,α3\alpha_1,\alpha_3α1,α3 基下等价于两个标量方程:
2θ=0,θ=2,2\theta = 0,\qquad \theta = 2, 2θ=0,θ=2,
不可能同时成立。因此 2α1+α32\alpha_1+\alpha_32α1+α3 不是任何特征值的特征向量(除非它是零向量,但明显不是)。
特征值 VS 奇异值
-
特征值 / 特征向量(eigen):告诉有没有 固定方向(不改变方向、只被缩放或反向)的向量,以及对应的缩放因子 λ\lambdaλ。适合分析 把某些方向保持不变的变换(尤其对称矩阵很有用)。
特征值 / 特征向量(Av=λvAv=\lambda vAv=λv)
- 含义:存在方向 vvv(称特征向量),作用 AAA 后只把 vvv 缩放(或反向)为 λv\lambda vλv。
- 特征值可以为负或复数(例如 旋转的特征值是复数 cosθ±isinθ\cos\theta\pm i\sin\thetacosθ±isinθ),不一定非负。
-
奇异值 / 奇异向量(singular):告诉任意线性变换把 单位球 变成 椭球 时,椭球的半轴长度(非负),以及这些轴在输入/输出空间的方向。奇异值总是非负实数,对任意矩阵都存在。
奇异值 / 奇异向量(SVD 的语境)
- 定义:奇异值 σi\sigma_iσi 是 矩阵 ATAA^T AATA 的非负特征值的平方根:
σi=eigenvaluei(ATA).\sigma_i = \sqrt{\text{eigenvalue}_i(A^T A)}. σi=eigenvaluei(ATA).
对应的右奇异向量 viv_ivi 是 ATAA^T AATA 的特征向量,左奇异向量 uiu_iui 是 AATA A^TAAT 的特征向量。 - 存在性:对任意矩阵(方阵或非方阵、可逆或不可逆)都存在 SVD,因此 奇异值总有定义且为非负实数。
- 几何意义(最重要的直观):把单位球 {x:∥x∥=1}\{x:\|x\|=1\}{x:∥x∥=1} 在变换 AAA 下映成一个椭球。这个椭球的 半轴长度 就是奇异值 σ1≥σ2≥⋯\sigma_1\ge\sigma_2\ge\cdotsσ1≥σ2≥⋯。
- VVV 的列(右奇异向量)给出输入空间中被映为这些半轴方向的原始方向;
- UUU 的列(左奇异向量)给出输出空间中椭球半轴的方向;
- Σ\SigmaΣ 的对角元就是相应的伸缩长度(奇异值)。
- 性质:奇异值非负;按大小排序,最大奇异值等于算子范数(spectral norm,最大放大倍数)。如果最小奇异值为 0,说明矩阵欠秩(不可逆)。
- 定义:奇异值 σi\sigma_iσi 是 矩阵 ATAA^T AATA 的非负特征值的平方根:
几何图像:
- 特征值/向量 = “哪条直线被直接拉长/缩短 不改变方向”;
- 奇异值/向量 = “把单位圆(球)变成椭圆(椭球):奇异值是半轴长度,左右两个正交方向分别是输入与输出的主方向”。
矩阵的秩
3Blue1Brown 逆矩阵、列空间与零空间
当变换的结果是一条直线时,也就是说结果是一维的,称这个 变换的秩 为 1;如果变换后的向量落在一个二维平面上,称这个 变换的秩 为 2,所以说,秩 代表 变换后空间的维数。如果一个三维变换的行列式为零,并且 变换结果仍旧充满整个三维空间,那么它的秩为 3。
矩阵的列告诉了基向量变换后的位置,这些 变换后的基向量张成的空间 就是所有可能的变换结果,换句话说,列空间就是矩阵的列所张成的空间。所以秩的更精确的定义是列空间(或行空间)的维数,表示列向量(或行向量)中 线性无关向量的最大个数。
当秩达到最大值时,意味着秩与列数相等,称之为 “满秩”。注意,零向量一定被包含在列空间中,因为线性变换必须保持原点位置不变。
对一个满秩变换来说,唯一能在变换后落在原点的就是零向量自身,但对一个 非满秩的矩阵 来说,它 将空间压缩到一个更低的维度上。
矩阵 A=[123456789]A=\begin{bmatrix}1&2&3\\[4pt]4&5&6\\[4pt]7&8&9\end{bmatrix}A=147258369,对其做 初等行变换 到 行最简阶梯形:
- R2←R2−4R1R_2\leftarrow R_2-4R_1R2←R2−4R1, R3←R3−7R1R_3\leftarrow R_3-7R_1R3←R3−7R1:
[1230−3−60−6−12].\begin{bmatrix}1&2&3\\0&-3&-6\\0&-6&-12\end{bmatrix}.1002−3−63−6−12. - R3←R3−2R2R_3\leftarrow R_3-2R_2R3←R3−2R2:
[1230−3−6000].\begin{bmatrix}1&2&3\\0&-3&-6\\0&0&0\end{bmatrix}.1002−303−60. - 将第2行除以 −3-3−3:R2←R2/(−3)R_2\leftarrow R_2/(-3)R2←R2/(−3),得到
[123012000].\begin{bmatrix}1&2&3\\0&1&2\\0&0&0\end{bmatrix}.100210320. - 用第2行消去第1行的第2列:R1←R1−2R2R_1\leftarrow R_1-2R_2R1←R1−2R2,得到行最简阶梯形
[10−1012000].\begin{bmatrix}1&0&-1\\0&1&2\\0&0&0\end{bmatrix}.100010−120.
从上面的行简化结果可以看出 主元(pivot)在第 1 列和第 2 列,共 2 个,所以矩阵的秩 rank(A)=2\operatorname{rank}(A)=2rank(A)=2。
矩阵是 3×33\times33×3,由 秩-零空间维数定理(Rank–Nullity):rank(A)+nullity(A)=n=3.\text{rank}(A)+\text{nullity}(A)=n=3.rank(A)+nullity(A)=n=3.
因此零空间(nullspace)的维度为 nullity(A)=3−2=1.\text{nullity}(A)=3-2=1.nullity(A)=3−2=1.
可以顺便写出零空间的一个基:设 x=[x1,x2,x3]Tx=[x_1,x_2,x_3]^Tx=[x1,x2,x3]T 满足 Ax=0Ax=0Ax=0。由行约简得到方程组
x1−x3=0,x2+2x3=0.x_1 - x_3 =0,\qquad x_2 + 2x_3 =0. x1−x3=0,x2+2x3=0.
令自由变量 x3=tx_3=tx3=t,得到 x=t[1−21].x = t\begin{bmatrix}1\\-2\\1\end{bmatrix}.x=t1−21. 所以零空间是一维,基向量可取 [1,−2,1]T[1,-2,1]^T[1,−2,1]T。
- 若 rank(A)=n\text{rank}(A)=nrank(A)=n(方阵满秩),则 AAA 可逆(det(A)≠0\det(A)\neq0det(A)=0);否则不可逆(本题 detA=0\det A=0detA=0)。
- 线性方程组 Ax=bAx=bAx=b 可解性的判定与秩有关:若 rank(A)=rank([A∣b])\operatorname{rank}(A)=\operatorname{rank}([A\;|\;b])rank(A)=rank([A∣b]) 则有解;否则无解。解的自由度(自由变量个数)等于 n−rank(A)n-\operatorname{rank}(A)n−rank(A)。
线性方程组的迭代解法(Jacobi)
Jacobi 迭代的思想:把 每个未知量用“其他未知量”的旧值表示 出来,然后 并行更新所有未知量。
对于第 iii 个未知量 xix_ixi,要得到一个 显式的更新公式
xi(k+1)=(常数)+∑j≠i(系数)⋅xj(k)x_i^{(k+1)} = \text{(常数)} + \sum_{j\ne i} \text{(系数)}\cdot x_j^{(k)} xi(k+1)=(常数)+j=i∑(系数)⋅xj(k)
为了得到这样的显式公式,必须把第 iii 个方程 整理成“关于 xix_ixi 的等式”(即把 xix_ixi 单独放左边,右边只含常数和其他变量)。
本题中,第一个方程要写成 x=⋯x=\cdotsx=⋯,第二个写成 y=⋯y=\cdotsy=⋯。方程组是
{4x+y=6,x+3y=3.\begin{cases} 4x+y=6,\\ x+3y=3. \end{cases} {4x+y=6,x+3y=3.
对第一个方程“解出 xxx”,对第二个方程“解出 yyy”得到
x=6−y4,y=3−x3x=\frac{6-y}{4}, \quad y=\frac{3-x}{3} x=46−y,y=33−x
这就是 Jacobi 的 更新公式:
x(k+1)=6−y(k)4,y(k+1)=3−x(k)3.x^{(k+1)}=\frac{6-y^{(k)}}{4},\qquad y^{(k+1)}=\frac{3-x^{(k)}}{3}. x(k+1)=46−y(k),y(k+1)=33−x(k).
注意 右边都用到的是上一轮的 x(k),y(k)x^{(k)},y^{(k)}x(k),y(k)。这正是 Jacobi 并行更新的要点。
矩阵/通用形式:设 Ax=bA\mathbf x=\mathbf bAx=b。把 AAA 分解为对角 DDD、严格下三角 LLL、严格上三角 UUU:A=D+L+UA=D+L+UA=D+L+U。Jacobi 迭代写成
x(k+1)=D−1(b−(L+U)x(k)).\mathbf x^{(k+1)} = D^{-1}\bigl(\mathbf b - (L+U)\mathbf x^{(k)}\bigr). x(k+1)=D−1(b−(L+U)x(k)).
这也说明:每一步要用 D−1D^{-1}D−1(即把对角元素取倒数)去“解出”每个分量 xix_ixi,因此每个方程都被整理为“关于自身未知量”的显式表达式。
前提条件:对角元素不能为 0(否则无法求 D−1D^{-1}D−1);收敛性通常还需要一定条件(例如严格对角占优或谱半径 < 1)。
给定初始解 (x(0),y(0))=(0,0)(x^{(0)},y^{(0)})=(0,0)(x(0),y(0))=(0,0),代入得到一次迭代的值:
- x(1)=6−y(0)4=6−04=64=1.5.x^{(1)} = \dfrac{6 - y^{(0)}}{4} = \dfrac{6-0}{4} = \dfrac{6}{4} = 1.5.x(1)=46−y(0)=46−0=46=1.5.
- y(1)=3−x(0)3=3−03=1.y^{(1)} = \dfrac{3 - x^{(0)}}{3} = \dfrac{3-0}{3} = 1.y(1)=33−x(0)=33−0=1.
所以 (x1,y1)=(1.5,1)(x_1,y_1)=(1.5,\,1)(x1,y1)=(1.5,1)。
补充:与 Gauss–Seidel 的区别
- Jacobi:计算 x(k+1)x^{(k+1)}x(k+1) 和 y(k+1)y^{(k+1)}y(k+1) 时都只用上一次的值 x(k),y(k)x^{(k)},y^{(k)}x(k),y(k)(并行更新)。
- Gauss–Seidel:先用上一次值算出 x(k+1)x^{(k+1)}x(k+1),再马上用这个新的 x(k+1)x^{(k+1)}x(k+1) 去算 y(k+1)y^{(k+1)}y(k+1)(顺序更新)。
在本例,如果用 Gauss–Seidel,从 (0,0)(0,0)(0,0) 一次迭代会得到 x(1)=1.5x^{(1)}=1.5x(1)=1.5,然后 y(1)=(3−1.5)/3=0.5y^{(1)}=(3-1.5)/3=0.5y(1)=(3−1.5)/3=0.5,结果为 (1.5,0.5)(1.5,\,0.5)(1.5,0.5)。
Jacobi 有用 因为它 简单、并行友好且对稀疏问题天然适配,虽然单独用时可能慢,但它是构造更复杂高效方法(如 multigrid、预条件 Krylov 方法)里的重要模块。
-
求解 大型稀疏线性方程组 Ax=bA \mathbf x=bAx=b,尤其是来自 偏微分方程(PDE)离散化 的问题(如 Poisson、热传导、流体动力学等)。这些问题 矩阵很大、稀疏,直接解(LU)成本高且内存占用大,迭代法更合适。
-
并行 / 分布式计算场景:Jacobi 的并行化开销小,适合在多核/多机上实现。
线性方程组的迭代解法(Gauss–Seidel)
考察点:需要会写 Gauss–Seidel 的逐分量更新公式、做几步迭代,并能判断迭代矩阵的谱半径或用对角占优等充分条件判断收敛性。
-
写出 Gauss–Seidel 的更新公式(按行顺序代入最新值):
{x(k+1)=2−y(k)5,y(k+1)=4−x(k+1)3.\begin{cases} x^{(k+1)}=\dfrac{2-y^{(k)}}{5},\\[6pt] y^{(k+1)}=\dfrac{4-x^{(k+1)}}{3}. \end{cases} ⎩⎨⎧x(k+1)=52−y(k),y(k+1)=34−x(k+1). -
从 (x(0),y(0))=(0,0)(x^{(0)},y^{(0)})=(0,0)(x(0),y(0))=(0,0) 进行迭代:
-
第一步:
x(1)=2−05=0.4,y(1)=4−0.43=3.63=1.2.x^{(1)}=\frac{2-0}{5}=0.4,\qquad y^{(1)}=\frac{4-0.4}{3}=\frac{3.6}{3}=1.2. x(1)=52−0=0.4,y(1)=34−0.4=33.6=1.2.所以 x(1)=0.4x^{(1)}=0.4x(1)=0.4(BBB 正确),y(1)=1.2y^{(1)}=1.2y(1)=1.2(DDD 正确)。
-
第二步:
x(2)=2−y(1)5=2−1.25=0.85=0.16,x^{(2)}=\frac{2-y^{(1)}}{5}=\frac{2-1.2}{5}=\frac{0.8}{5}=0.16, x(2)=52−y(1)=52−1.2=50.8=0.16,y(2)=4−x(2)3=4−0.163=1.28.y^{(2)}=\frac{4-x^{(2)}}{3}=\frac{4-0.16}{3}=1.28. y(2)=34−x(2)=34−0.16=1.28.
因此 AAA 中的 x(2)=0.08x^{(2)}=0.08x(2)=0.08 是错误的。
-
-
收敛性(谱半径)判断:令 A=(5113)A=\begin{pmatrix}5&1\\1&3\end{pmatrix}A=(5113)。Gauss–Seidel 的迭代矩阵是
BGs=−(D+L)−1UB_{Gs}=-(D+L)^{-1}U BGs=−(D+L)−1U对本例可计算出(或注意到是上三角形式)
BGs=(0−150115),B_{Gs}=\begin{pmatrix}0 & -\tfrac15\\[4pt]0 & \tfrac{1}{15}\end{pmatrix}, BGs=(00−51151),特征值为 000 和 1/151/151/15,所以谱半径 ρ(BGs)=1/15<1\rho(B_{Gs})=1/15<1ρ(BGs)=1/15<1。因此迭代收敛,选项 C(ρ>1\rho>1ρ>1)错误。
(另外也可用充分条件判断:矩阵对角占优,故 Gauss–Seidel 收敛。)
关于迭代矩阵,更具体的求解过程如下:
- 矩阵分解 A=D+L+UA=D+L+UA=D+L+U
把矩阵 A=(5113)A=\begin{pmatrix}5&1\\[2pt]1&3\end{pmatrix}A=(5113) 分成 对角、严格下三角和严格上三角 三部分:
D=(5003),L=(0010),U=(0100).D=\begin{pmatrix}5&0\\[2pt]0&3\end{pmatrix},\quad L=\begin{pmatrix}0&0\\[2pt]1&0\end{pmatrix},\quad U=\begin{pmatrix}0&1\\[2pt]0&0\end{pmatrix}. D=(5003),L=(0100),U=(0010).
Gauss–Seidel 的逐分量更新可写成矩阵形式
(D+L)x(k+1)=−Ux(k)+b,(D+L)x^{(k+1)} = -U x^{(k)} + b, (D+L)x(k+1)=−Ux(k)+b,
移项得到
x(k+1)=−(D+L)−1Ux(k)+(D+L)−1b.x^{(k+1)} = -(D+L)^{-1}U\,x^{(k)} + (D+L)^{-1}b. x(k+1)=−(D+L)−1Ux(k)+(D+L)−1b.
因此迭代矩阵就是
BGs=−(D+L)−1U.B_{Gs}=-(D+L)^{-1}U. BGs=−(D+L)−1U.- 计算 (D+L)−1(D+L)^{-1}(D+L)−1 与 BGsB_{Gs}BGs
先写出 D+LD+LD+L:
D+L=(5013).D+L=\begin{pmatrix}5&0\\[2pt]1&3\end{pmatrix}. D+L=(5103).
计算 D+LD+LD+L 矩阵的逆:(5013)(1001)=(1013)(15001)=(1003)(150−151)=(1001)(150−11513)\begin{pmatrix}5&0\\[2pt]1&3\end{pmatrix}\begin{pmatrix}1&0\\[2pt]0&1\end{pmatrix} = \begin{pmatrix}1&0\\[2pt]1&3\end{pmatrix}\begin{pmatrix}\frac{1}{5}&0\\[2pt]0&1\end{pmatrix} = \begin{pmatrix}1&0\\[2pt]0&3\end{pmatrix}\begin{pmatrix}\frac{1}{5}&0\\[2pt]-\frac{1}{5}&1\end{pmatrix} = \begin{pmatrix}1&0\\[2pt]0&1\end{pmatrix}\begin{pmatrix}\frac{1}{5}&0\\[2pt]-\frac{1}{15}&\frac{1}{3}\end{pmatrix}(5103)(1001)=(1103)(51001)=(1003)(51−5101)=(1001)(51−151031)
BGs=−(D+L)−1U=(0−150115).B_{Gs}=-(D+L)^{-1}U= \begin{pmatrix}0&-\tfrac{1}{5}\\[2pt]0&\tfrac{1}{15}\end{pmatrix}.BGs=−(D+L)−1U=(00−51151).- 求特征值(谱半径)
注意这个 BGsB_{Gs}BGs 是上三角矩阵(非零条目在对角线上和右上角),所以它的特征值就是对角线元素:
λ1=0,λ2=115.\lambda_1 = 0,\qquad \lambda_2 = \frac{1}{15}. λ1=0,λ2=151.
谱半径 是 特征值绝对值的最大值:
ρ(BGs)=max(∣0∣,∣1/15∣)=115<1.\rho(B_{Gs})=\max(|0|,|1/15|)=\frac{1}{15}<1. ρ(BGs)=max(∣0∣,∣1/15∣)=151<1.
结论:谱半径小于 1,Gauss–Seidel 方法对本例收敛。
LU 分解和 QR 分解
| 分解 | 形式 | 是否总存在 | 应用 |
|---|---|---|---|
| LU | PA=LUPA=LUPA=LU | 不一定(必须允许行交换) | 解线性方程组(快速求解) |
| QR | A=QRA=QRA=QR | 对任意矩阵都存在 | 最小二乘问题,数值稳定计算 |
LU 分解(Lower–Upper Decomposition):把一个矩阵 AAA 分解成 下三角矩阵 LLL 和 上三角矩阵 UUU 的乘积:
A=LUA = LU A=LU
有时为了保证分解存在,需要引入置换矩阵 PPP:
PA=LUPA = LU PA=LU
这叫 带主元的 LU 分解。
LU 分解其实就是把 高斯消元 的过程“打包”成一个分解:
- 消元得到的系数记录在 LLL 里;
- 最后得到的上三角结果就是 UUU。
好处:解线性方程组 Ax=bAx=bAx=b 时,不用每次都重新消元,可以用分解快速解:
Ax=b⇒LUx=b⇒Ly=b⇒Ux=yAx=b \;\Rightarrow\; LUx=b \;\Rightarrow\; Ly=b \;\Rightarrow\; Ux=y Ax=b⇒LUx=b⇒Ly=b⇒Ux=y
两次三角方程求解即可(代价低很多)。例如,A=[2347]A=\begin{bmatrix}2 & 3 \\4 & 7\end{bmatrix}A=[2437]
做消元:用第 1 行消去第 2 行,系数是 4/2=24/2=24/2=2。于是:
L=[1021],U=[2301]L = \begin{bmatrix} 1 & 0 \\ 2 & 1 \end{bmatrix}, \quad U = \begin{bmatrix} 2 & 3 \\ 0 & 1 \end{bmatrix} L=[1201],U=[2031]
QR 分解(Orthogonal–Upper Triangular Decomposition):把一个矩阵 AAA 分解为,
A=QRA = QR A=QR
QQQ:正交矩阵(列向量正交且单位化,满足 Q⊤Q=IQ^\top Q = IQ⊤Q=I),RRR:上三角矩阵。
适用于任意矩阵(方阵/矩阵都可以)。
QR 分解本质上是 对列向量做 Gram–Schmidt 正交化:
- 把 AAA 的列向量变成一组正交单位向量(放在 QQQ 中);
- 正交化过程中得到的投影系数就是 RRR。
在几何意义上,QQQ 是旋转/反射(不会改变长度和角度),RRR 则包含缩放、组合的信息。
比如求解超定方程组(最小二乘问题):
minx∥Ax−b∥2\min_x \|Ax-b\|_2 xmin∥Ax−b∥2
用 QR 分解可以变成简单的三角系统求解。数值稳定性比 LU 分解更好,所以在科学计算中很常用。A=[111−1]A=\begin{bmatrix} 1 & 1 \\ 1 & -1 \\ \end{bmatrix} A=[111−1]
对列向量做 Gram–Schmidt:
- 第 1 列 [1,1]T[1,1]^T[1,1]T,归一化:12[1,1]T\tfrac{1}{\sqrt{2}}[1,1]^T21[1,1]T。
- 第 2 列 [1,−1]T[1,-1]^T[1,−1]T,与第 1 列正交(本来就正交),归一化:12[1,−1]T\tfrac{1}{\sqrt{2}}[1,-1]^T21[1,−1]T。
于是:
Q=12[111−1],R=[2002]Q=\frac{1}{\sqrt{2}} \begin{bmatrix} 1 & 1 \\ 1 & -1 \end{bmatrix}, \quad R=\begin{bmatrix} \sqrt{2} & 0 \\ 0 & \sqrt{2} \end{bmatrix} Q=21[111−1],R=[2002]
SVD 分解
SVD 写为
A=UΣV⊤,A=U\Sigma V^\top, A=UΣV⊤,
其中 Σ=diag(σ1,σ2,…)\Sigma=\operatorname{diag}(\sigma_1,\sigma_2,\dots)Σ=diag(σ1,σ2,…),通常要求 σ1≥σ2≥⋯≥0\sigma_1\ge\sigma_2\ge\cdots\ge0σ1≥σ2≥⋯≥0。(约定奇异值矩阵 Σ\SigmaΣ 的对角元素非负且按降序排列,便于比较大小/截断)
- 右奇异向量 viv_ivi 是 ATAA^T AATA 的特征向量,满足
ATAvi=σi2vi.A^T A v_i = \sigma_i^2 v_i. ATAvi=σi2vi. - 左奇异向量 uiu_iui 是 AATA A^TAAT 的特征向量,滿足
AATui=σi2ui.A A^T u_i = \sigma_i^2 u_i. AATui=σi2ui.
也可以从基本 SVD 等式推导:
Avi=σiui,ATui=σivi.A v_i = \sigma_i u_i,\qquad A^T u_i = \sigma_i v_i. Avi=σiui,ATui=σivi.
把第二个式子代入第一个得到 AATui=σi2uiA A^T u_i=\sigma_i^2 u_iAATui=σi2ui;同样得到 ATAvi=σi2viA^T A v_i=\sigma_i^2 v_iATAvi=σi2vi。
SVD 把任意变换分成“旋转 → 缩放 → 旋转”
任何矩阵 AAA 都可以写成 A=UΣV⊤A=U\Sigma V^\topA=UΣV⊤,其中 U,VU,VU,V 正交(旋转/反射),Σ\SigmaΣ 非负对角(缩放)。
- 先用 V⊤V^\topV⊤ 把输入坐标系旋转到“奇异向量基”,再用 Σ\SigmaΣ 按坐标轴缩放(这些坐标轴就是椭球主轴),最后 用 UUU 把结果旋转到输出坐标系。
- 因此 SVD 给了最自然的几何分解:任意线性变换 = 两次正交变换(旋转/反射)夹一个纯拉伸。
例 1:纯缩放 A=(3001)A=\begin{pmatrix}3&0\\0&1\end{pmatrix}A=(3001)
- 特征值:3, 1(对应方向 e1,e2e_1,e_2e1,e2),奇异值同为 3,1(因为 A 是对角且非负)。
- 作用:把单位圆拉成半轴长度 3 与 1 的椭圆,主方向不变。
例 2:纯旋转 R=R(θ)R=R(\theta)R=R(θ)(如 θ=90∘\theta=90^\circθ=90∘)
- 特征值:复数(没有实特征向量)
- 奇异值:都等于 1(不改变长度)
- 作用:把单位圆映为同样的单位圆,只改变方向。
例 3:一般矩阵
任何 AAA 的 SVD A=UΣV⊤A=U\Sigma V^\topA=UΣV⊤ 说明 AAA 含有“旋转-拉伸-旋转”成分。如果把一个向量 xxx 投影在 VVV 基下,先缩放各分量(由 Σ\SigmaΣ 给出),再用 UUU 旋转回输出空间。
为什么在实际中常用奇异值(SVD)?
- 总是存在(对任意矩阵),稳定且能处理 非方阵。
- 给出最优低秩近似(Eckart–Young 定理):截取前 kkk 个奇异值对应的分解,能得到最佳的秩-kkk 近似。
- 用于 数值稳定性分析(条件数 κ(A)=σmax/σmin\kappa(A)=\sigma_{\max}/\sigma_{\min}κ(A)=σmax/σmin)。
- 在数据分析(PCA)、图像压缩、最小二乘、伪逆(Moore–Penrose)等都有广泛应用。
线性代数中的常见矩阵类型
-
对称矩阵 (Symmetric Matrix):矩阵等于它的转置。
A=A⊤A = A^\top A=A⊤
特点是主对角线对称,
[123245356]\begin{bmatrix} 1 & 2 & 3 \\ 2 & 4 & 5 \\ 3 & 5 & 6 \end{bmatrix} 123245356 -
实对称矩阵 (Real Symmetric Matrix):元素全是实数的对称矩阵。特征值一定是实数;可以正交对角化(存在正交矩阵 QQQ,使得 A=QΛQ⊤A = Q \Lambda Q^\topA=QΛQ⊤)。
-
正交矩阵 (Orthogonal Matrix):列(行)向量两两正交且单位化,不改变向量长度
Q⊤Q=I⇔Q−1=Q⊤Q^\top Q = I \quad \Leftrightarrow \quad Q^{-1} = Q^\top Q⊤Q=I⇔Q−1=Q⊤
表示旋转或反射变换,比如二维旋转矩阵:
Q=[cosθ−sinθsinθcosθ]Q = \begin{bmatrix} \cos\theta & -\sin\theta \\ \sin\theta & \cos\theta \end{bmatrix} Q=[cosθsinθ−sinθcosθ] -
正定矩阵 (Positive Definite Matrix):对任意非零向量 xxx,
x⊤Ax>0x^\top A x > 0 x⊤Ax>0
所有特征值都大于 0;常见于协方差矩阵、能量函数等。 -
半正定矩阵 (Positive Semi-Definite, PSD):
x⊤Ax≥0x^\top A x \geq 0 x⊤Ax≥0
特征值 ≥0\geq 0≥0。 -
对角矩阵 (Diagonal Matrix):主对角线以外全为 0。
[100040007]\begin{bmatrix} 1 & 0 & 0 \\ 0 & 4 & 0 \\ 0 & 0 & 7 \end{bmatrix} 100040007 -
单位矩阵 (Identity Matrix):对角线全是 1,其余为 0。任何矩阵乘它不变。
-
零矩阵 (Zero Matrix):全部元素为 0。
-
上/下三角矩阵 (Triangular Matrix):上三角矩阵 的主对角线下方为 0;下三角矩阵 的主对角线上方为 0。
-
奇异矩阵 (Singular Matrix):行列式为 0,不可逆。
-
正交投影矩阵 (Projection Matrix):把向量投影到某个子空间。
P2=PP^2 = P P2=P -
幂等矩阵 (Idempotent Matrix):
A2=AA^2 = A A2=A -
酉矩阵 (Unitary Matrix):复数域上的“正交矩阵”,在复数向量空间中保持长度。
U∗U=IU^\ast U = I U∗U=I -
厄米矩阵 (Hermitian Matrix):复数域上的“对称矩阵”,转置并共轭,特征值一定是实数。
A=A∗A = A^\ast A=A∗
实对称矩阵
把矩阵想成“把向量拉伸/压缩并旋转”的变换。对称矩阵 的特别之处是:它不会把伸长的方向“扭曲成复杂的相位”,它的“伸缩因子”是纯粹的实数(没有复数的“旋转+缩放”混合)。也就是说,对称变换可以被理解为 在一组正交方向上只做实数伸缩。
对称 = “没有复相位”,所以特征值都是实数。
若 AAA 是实对称的,特征向量可以取正交,且 奇异值等于特征值的绝对值(因为 ATA=A2A^TA=A^2ATA=A2 在对称情形下成立,所以 σi=∣λi∣\sigma_i=|\lambda_i|σi=∣λi∣)。
正交矩阵和旋转的关系?
对任意实向量 uuu,其欧几里得范数平方定义为内积自身:∥u∥2=uTu.\| u\|^2 = u^T u.∥u∥2=uTu.
正交矩阵 定义:一个 n×nn\times nn×n 的实矩阵 QQQ 若满足
Q⊤Q=QQ⊤=In,Q^\top Q = Q Q^\top = I_n, Q⊤Q=QQ⊤=In,
就称为 正交矩阵。等价地,Q−1=Q⊤Q^{-1}=Q^\topQ−1=Q⊤。
正交矩阵表示 “长度和角度都不变” 的线性变换——本质上是旋转或反射(以及它们的组合)。把向量用 QQQ 变换后,向量的长度不变,任意两向量之间的内积也不变。
- 正交矩阵 QQQ 满足 Q⊤Q=IQ^\top Q=IQ⊤Q=I。因此对任意向量 xxx,∥Qx∥2=x⊤Q⊤Qx=x⊤x=∥x∥2\|Qx\|^2 = x^\top Q^\top Q x = x^\top x = \|x\|^2∥Qx∥2=x⊤Q⊤Qx=x⊤x=∥x∥2。→ 说明它保持长度,也保持夹角(因为内积不变)。这正是旋转(或反射)应有的性质。
旋转(在欧几里得空间)由 正交矩阵 QQQ 表示,满足 Q⊤Q=IQ^\top Q=IQ⊤Q=I 且 detQ=1\det Q = 1detQ=1(若 det=−1\det=-1det=−1 则是反射+旋转)。
-
性质:旋转不改变向量长度(∥Qx∥=∥x∥\|Qx\|=\|x\|∥Qx∥=∥x∥),所以奇异值全是 1。
-
特征值:二维旋转角度 θ\thetaθ 的矩阵
R(θ)=(cosθ−sinθsinθcosθ)R(\theta)=\begin{pmatrix}\cos\theta & -\sin\theta\\ \sin\theta & \cos\theta\end{pmatrix} R(θ)=(cosθsinθ−sinθcosθ)的特征值是 e±iθ=cosθ±isinθe^{\pm i\theta}=\cos\theta\pm i\sin\thetae±iθ=cosθ±isinθ —— 通常是复数,所以没有非零的实特征向量(除非 θ=0\theta=0θ=0 或 π\piπ)。
几何上:旋转改变方向但不改变长度;特征向量要求“不改变方向”,因此旋转通常 没有实特征向量。
概率论
朴素贝叶斯(Naive Bayes)
参考:Naive Bayes, Clearly Explained 和 Gaussian Naive Bayes, Clearly Explained,Bayes and Naive Bayes Classifier
朴素贝叶斯分类器用的是贝叶斯公式
P(class∣features)∝P(features∣class)P(class).P(\text{class}\mid\text{features}) \propto P(\text{features}\mid\text{class})\,P(\text{class}). P(class∣features)∝P(features∣class)P(class).
-
P(class)P(\text{class})P(class) 是类别先验(例如 P(spam)P(\text{spam})P(spam)、P(Normal)P(\text{Normal})P(Normal)),必须从训练集估计。常用估计:
P^(class)=#train docs in class#all train docs.\hat P(\text{class})=\frac{\#\text{train docs in class}}{\#\text{all train docs}}. P^(class)=#all train docs#train docs in class. -
对于 P(features∣class)P(\text{features}\mid\text{class})P(features∣class),朴素贝叶斯作条件独立假设,把联合条件概率分解为各特征的乘积:
P(features∣class)=∏iP(featurei∣class).P(\text{features}\mid\text{class})=\prod_i P(\text{feature}_i\mid\text{class}). P(features∣class)=i∏P(featurei∣class).
因此需要估计每个特征(例如每个单词)在该类别下出现的条件概率。常见估计(多项式朴素贝叶斯):
P^(w∣c)=count(win class c)+α∑w′count(w′in c)+αV,\hat P(w|c)=\frac{\text{count}(w\text{ in class }c)+\alpha}{\sum_{w'}\text{count}(w'\text{ in }c)+\alpha V}, P^(w∣c)=∑w′count(w′ in c)+αVcount(w in class c)+α,
其中 α\alphaα 为拉普拉斯平滑参数,VVV 为词表大小。
为什么联合概率 P(word1,word2∣class)P(\text{word}_1,\text{word}_2\mid\text{class})P(word1,word2∣class))不是必须的?
朴素贝叶斯 恰恰是 通过条件独立假设把联合概率拆成各个 P(wordi∣class)P(\text{word}_i\mid\text{class})P(wordi∣class) 的乘积。 如果你去估计二元或更高阶的联合概率(即放弃独立假设),模型会变得非常复杂、参数爆炸并且需要大量数据(或采用 n-gram、交互特征等替代方法)。但标准朴素贝叶斯不需要直接估计这些高阶联合分布。
为什么边缘概率 P(word)P(\text{word})P(word) 不是必须的?
在比较不同类别的后验时:
P(class∣features)=P(features∣class)P(class)P(features).P(\text{class}\mid\text{features})=\frac{P(\text{features}\mid\text{class})P(\text{class})}{P(\text{features})}. P(class∣features)=P(features)P(features∣class)P(class).
分母 P(features)P(\text{features})P(features) 对所有类别相同,因此在做判别(选概率最大的类别)时可以忽略它(只用分子比较)。所以不必单独估计每个特征的边缘概率 P(word)P(\text{word})P(word)。当然,如果想要 真正的归一化后验概率,可以通过
P(features)=∑cP(features∣c)P(c)P(\text{features})=\sum_{c} P(\text{features}\mid c)P(c) P(features)=c∑P(features∣c)P(c)
间接算出,但这不是训练时必须单独估计 P(word)P(\text{word})P(word) 的理由。
- 要避免零概率问题,常用拉普拉斯平滑(α>0\alpha>0α>0)。
- 有两种常见特征模型:多项式 NB(考虑词频)和伯努利 NB(考虑词是否出现)。估计公式略有不同,但核心都是估计 P(word∣class)P(\text{word}|class)P(word∣class) 与 P(class)P(class)P(class)。
- 如果需要捕捉词间依赖,可引入 n-gram 或交互特征,但那就超出“朴素”贝叶斯的假设了。
AI
卷积、池化、全连接层和激活函数
线性算子 的定义是:对任意向量(或函数)x,yx,yx,y 和标量 a,ba,ba,b,有
T(ax+by)=aT(x)+bT(y).T(ax+by)=aT(x)+bT(y). T(ax+by)=aT(x)+bT(y).
-
卷积满足这个性质:若 TTT 表示与固定核 kkk 的卷积,则
T(ax+by)=k∗(ax+by)=a(k∗x)+b(k∗y)=aT(x)+bT(y),T(ax+by)=k*(ax+by)=a(k*x)+b(k*y)=aT(x)+bT(y), T(ax+by)=k∗(ax+by)=a(k∗x)+b(k∗y)=aT(x)+bT(y),
所以卷积是线性变换。 -
全连接层 核心是矩阵乘法 y=Wxy=W xy=Wx,这满足线性性(矩阵乘法是线性的)。实际神经网络里常在后面加上偏置 bbb,变为 y=Wx+by = W x + by=Wx+b,这叫仿射变换(affine),严格来说含偏置时不是“线性”而是“仿射”。
在考试语境中通常把“全连接层”视为线性变换(或把权重部分当作线性)。
-
ReLU:ReLU(x)=max(0,x)\operatorname{ReLU}(x)=\max(0,x)ReLU(x)=max(0,x)。
检验加法性:ReLU(1)=1,ReLU(−1)=0\operatorname{ReLU}(1)=1,\ \operatorname{ReLU}(-1)=0ReLU(1)=1, ReLU(−1)=0,但 ReLU(1+(−1))=ReLU(0)=0\operatorname{ReLU}(1+(-1))=\operatorname{ReLU}(0)=0ReLU(1+(−1))=ReLU(0)=0。
1+0≠01+0 \ne 01+0=0,因此不满足线性性,ReLU 是非线性(尽管它是分段线性的)。 -
池化:常见的 max pooling 是非线性的(取最大值,不满足加法性),例如 max(1,0)=1,max(−1,0)=0\max(1,0)=1,\ \max(-1,0)=0max(1,0)=1, max(−1,0)=0 但 max(1+(−1),0)=max(0,0)=0\max(1+(-1),0)=\max(0,0)=0max(1+(−1),0)=max(0,0)=0,不满足线性性。
注意例外:如果题目中特指 average pooling(均值池化),那是线性的(平均是加权和/矩阵乘法的一种),但一般说“池化”在 CNN 语境中默认是 max pooling,所以视为非线性。
XGBoost 算法
XGBoost = GBDT + 二阶近似 + 正则化 + 工程优化
- Boosting 思想:不是一次性训练一个很强的模型,而是逐步迭代训练很多“弱模型”(如浅树),每次 让新的模型去修正前一轮的误差,最后把它们加起来形成一个强模型。
- XGBoost:是对 梯度提升树(GBDT) 的改进实现,特点是:
- 用二阶导数(梯度 + Hessian)提升优化精度;
- 加入正则化,控制树的复杂度,防止过拟合;
- 利用高效的工程优化(稀疏感知、分块并行、缓存等),速度快。
假设我们要学一个预测函数:
y^(t)(x)=∑k=1tfk(x),fk∈F\hat y^{(t)}(x)=\sum_{k=1}^t f_k(x), \quad f_k \in \mathcal{F} y^(t)(x)=k=1∑tfk(x),fk∈F
其中每个 fkf_kfk 是一棵回归树(叶子节点有一个预测值)。

训练目标函数:
L=∑il(yi,y^i)+∑kΩ(fk)\mathcal{L} = \sum_{i} l(y_i,\hat y_i) + \sum_k \Omega(f_k) L=i∑l(yi,y^i)+k∑Ω(fk)
- 第一项:损失函数(例如平方误差、逻辑损失等);
- 第二项:正则化 Ω(f)=γT+12λ∑jwj2\Omega(f)=\gamma T+\tfrac{1}{2}\lambda\sum_j w_j^2Ω(f)=γT+21λ∑jwj2,惩罚树叶子数 TTT 和叶子权重 wjw_jwj 的大小,防止过拟合。
在第 ttt 次迭代时,要加一个新树 ftf_tft,但直接最优化很难。XGBoost 的关键 是:对损失函数做 二阶泰勒展开(近似):
L(t)≈∑i[gift(xi)+12hift(xi)2]+Ω(ft),\mathcal{L}^{(t)} \approx \sum_i \big[g_i f_t(x_i) + \tfrac{1}{2} h_i f_t(x_i)^2 \big] + \Omega(f_t), L(t)≈i∑[gift(xi)+21hift(xi)2]+Ω(ft),
其中
- gi=∂y^(t−1)l(yi,y^i(t−1))g_i = \partial_{\hat y^{(t-1)}} l(y_i,\hat y^{(t-1)}_i)gi=∂y^(t−1)l(yi,y^i(t−1)) (一阶梯度);
- hi=∂y^(t−1)2l(yi,y^i(t−1))h_i = \partial^2_{\hat y^{(t-1)}} l(y_i,\hat y^{(t-1)}_i)hi=∂y^(t−1)2l(yi,y^i(t−1)) (二阶 Hessian)。
这样就把复杂的 损失最小化问题,化简成 只依赖梯度和二阶信息的优化问题。

如何生长一棵树?
- 训练时需要决定:在哪个特征、哪个阈值上分裂。
- XGBoost 定义了一个 分裂增益函数(Gain),衡量分裂前后目标函数下降多少:
Gain=12[GL2HL+λ+GR2HR+λ−(GL+GR)2HL+HR+λ]−γGain = \frac{1}{2}\left[\frac{G_L^2}{H_L+\lambda} + \frac{G_R^2}{H_R+\lambda} - \frac{(G_L+G_R)^2}{H_L+H_R+\lambda}\right] - \gamma Gain=21[HL+λGL2+HR+λGR2−HL+HR+λ(GL+GR)2]−γ
其中 GGG、HHH 是分裂后左右子树上的梯度和 Hessian 总和。
选择 Gain 最大的分裂方式,直到叶子数或深度达到限制。
防止过拟合的机制:
- 正则化项:λ\lambdaλ 控制叶子权重的平滑,γ\gammaγ 控制是否值得新开一个叶子;
- Shrinkage(学习率):每轮只加一小步,避免过拟合;
- 子采样:随机采样数据行、特征列,减少相关性;
- 树深限制:避免树过深。
工程优化(为什么 XGBoost 特别快)
- 稀疏感知:能自动处理缺失值、稀疏特征;
- 并行化分裂搜索:不同特征的分裂点可以并行搜索;
- Block 结构:数据按列存储,缓存友好;
- 支持分布式训练。