大数据毕业设计选题推荐-基于大数据的大气和海洋动力学数据分析与可视化系统-Spark-Hadoop-Bigdata
✨作者主页:IT研究室✨
个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。
☑文末获取源码☑
精彩专栏推荐⬇⬇⬇
Java项目
Python项目
安卓项目
微信小程序项目
文章目录
- 一、前言
- 二、开发环境
- 三、系统界面展示
- 四、代码参考
- 五、系统视频
- 结语
一、前言
本系统以“基于大数据的大气和海洋动力学数据分析与可视化”为主线,依托 Hadoop 分布式存储与 Spark 内存计算,把横跨 140 余年的全球海平面、温室气体、海冰、ENSO 等多源异构数据先落到 HDFS,再以 Spark SQL/Pandas 完成清洗与聚合,借助 Spring Boot/Django 后端统一对外暴露 REST,前端 Vue+ECharts 把复杂指标实时渲染成交互式大屏。用户可在秒级内完成“全球温度异常趋势”“北极海冰融化速率”“CO₂ 排放-浓度因果链”等场景的可视化探索,同时支持时间轴拖拽、区域钻取和聚类回放,整套流程在 MySQL 中仅保留元数据与结果缓存,计算层与存储层松耦合,方便后续算法或数据源的平滑扩展。
近几十年,海平面抬升、极地冰盖收缩、厄尔尼诺事件频发不断登上新闻头条,学界与公众都渴望一把“放大镜”去透视这些现象背后的长周期规律。传统单机工具面对动辄上亿条船舶报、卫星报、地面观测的耦合数据时,常常力不从心;而气象海洋部门内部又存在业务系统分散、口径不一、更新滞后等痛点。把 Hadoop/Spark 的分布式能力和经典气候科学指标结合起来,恰好能在“海量”与“高时效”之间找到一条折中路线,为个人研究、课堂案例乃至小型决策团队提供一条可复制的技术路径。
毕业设计体量有限,系统更像一块“试验田”:对研究者,它把繁琐的数据清洗脚本封装成可调度的 Spark Job,省下大量重复劳动;对课堂,学生可以像拖拽 PPT 一样切换时空维度,直观感受 ENSO 相位与全球均温的错位节奏;对政策制定辅助,它用简洁的 REST 把“近十年海平面加速度”一键推送到任何 BI 工具,免去了层层上报的等待。虽然算力、模型深度尚不能与国家级超算平台比肩,但把复杂气候数据“平民化”到浏览器里,本身就是对公共科普与跨学科交流的一次温和助力。
二、开发环境
- 大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
- 开发语言:Python+Java(两个版本都支持)
- 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
- 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
- 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
- 数据库:MySQL
三、系统界面展示
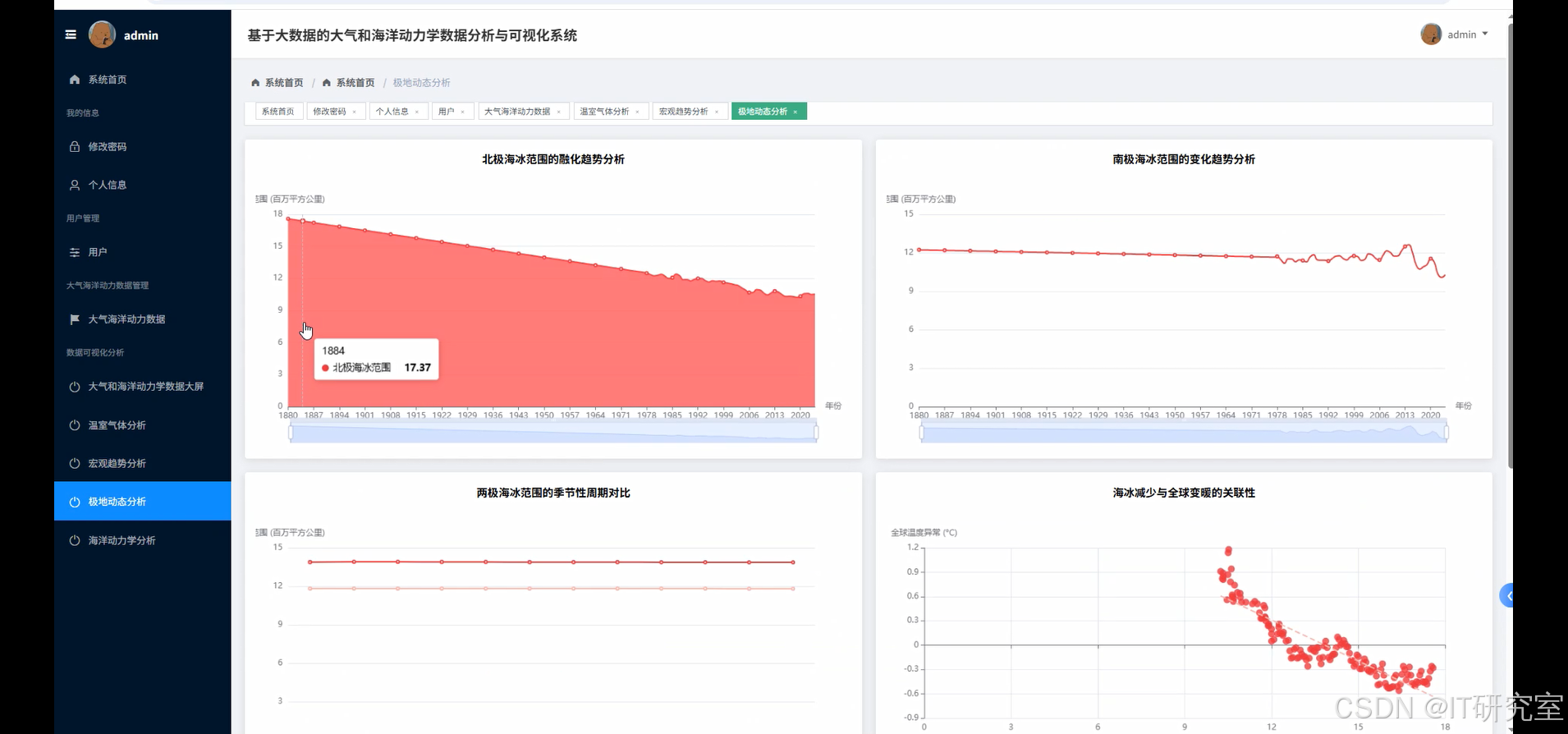
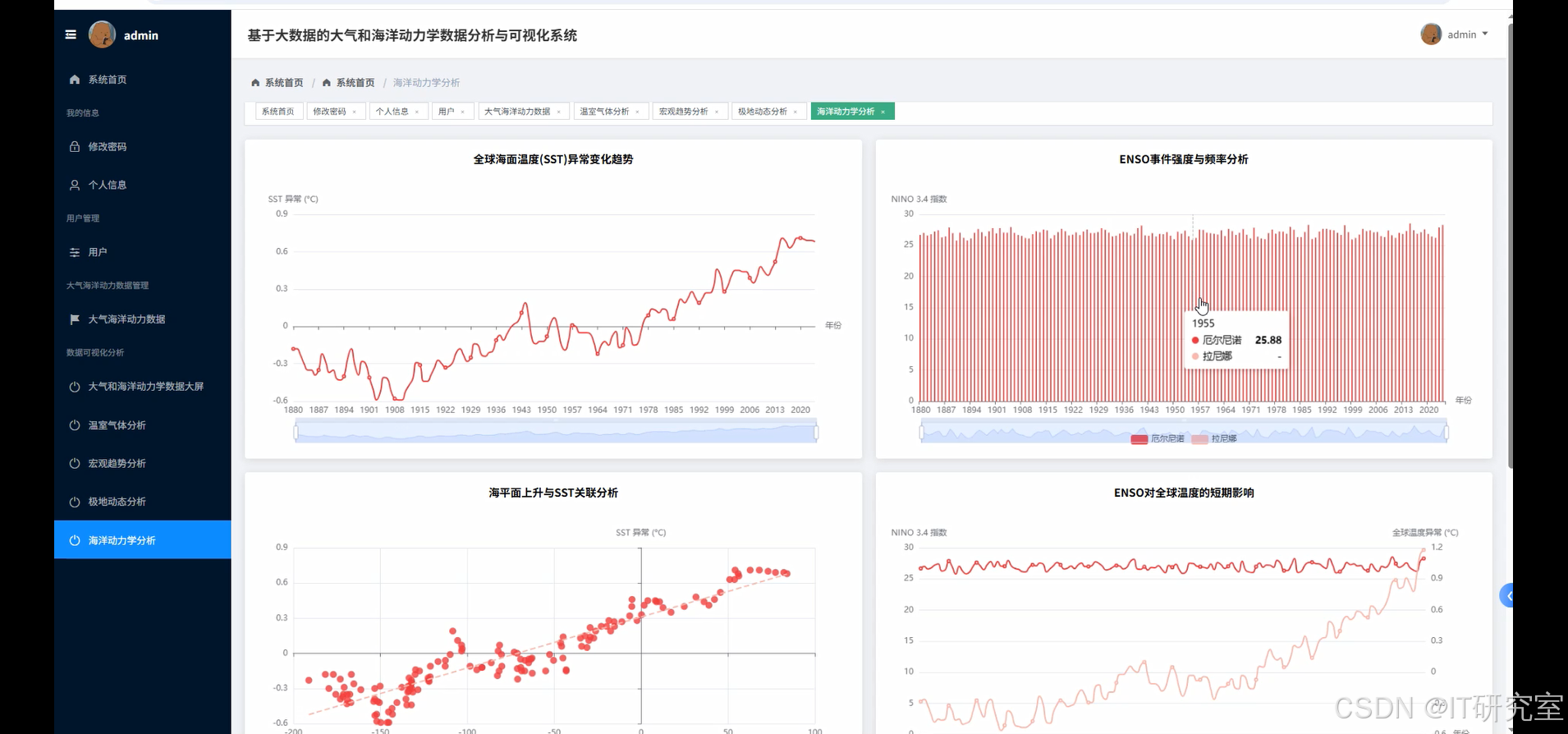
- 基于大数据的大气和海洋动力学数据分析与可视化系统界面展示:
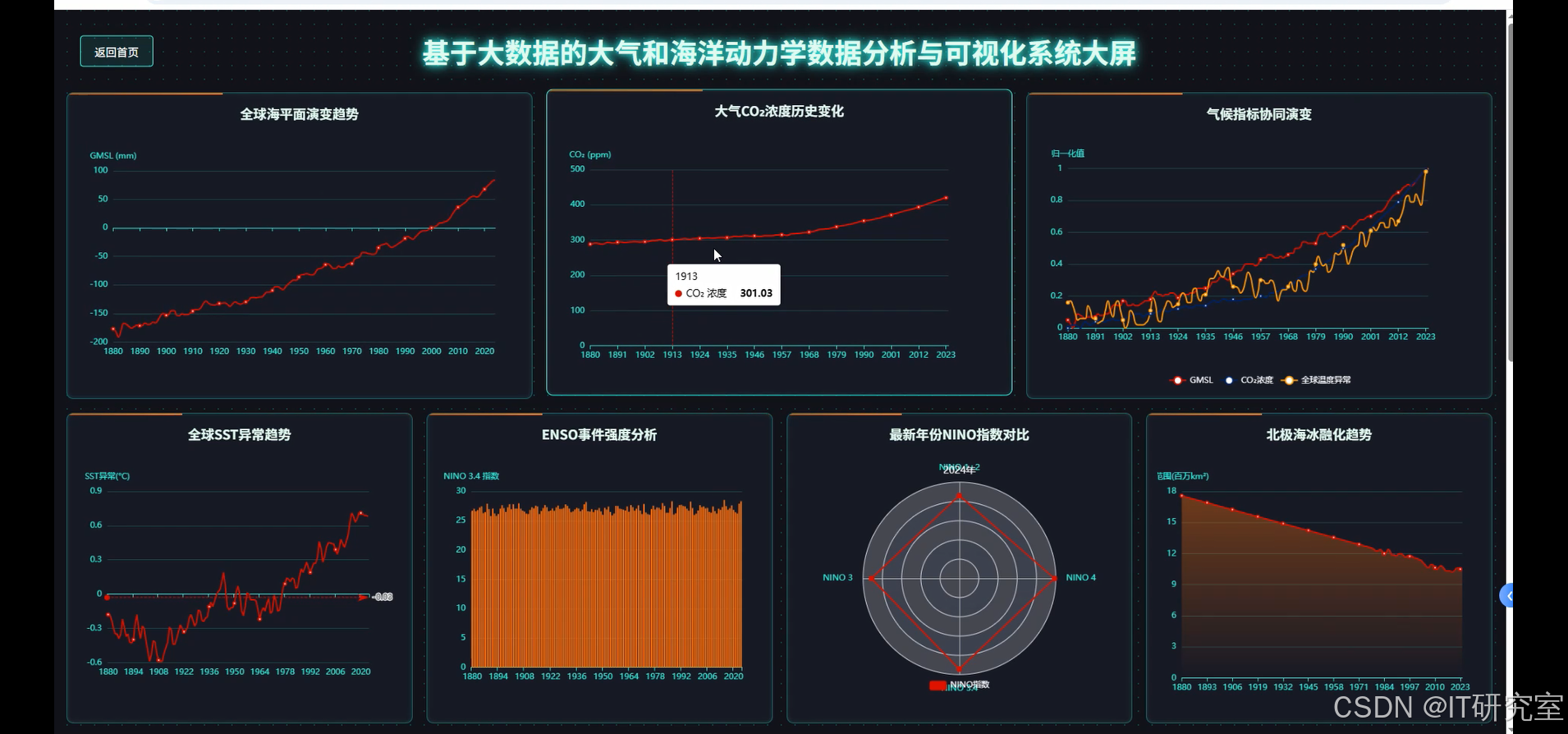
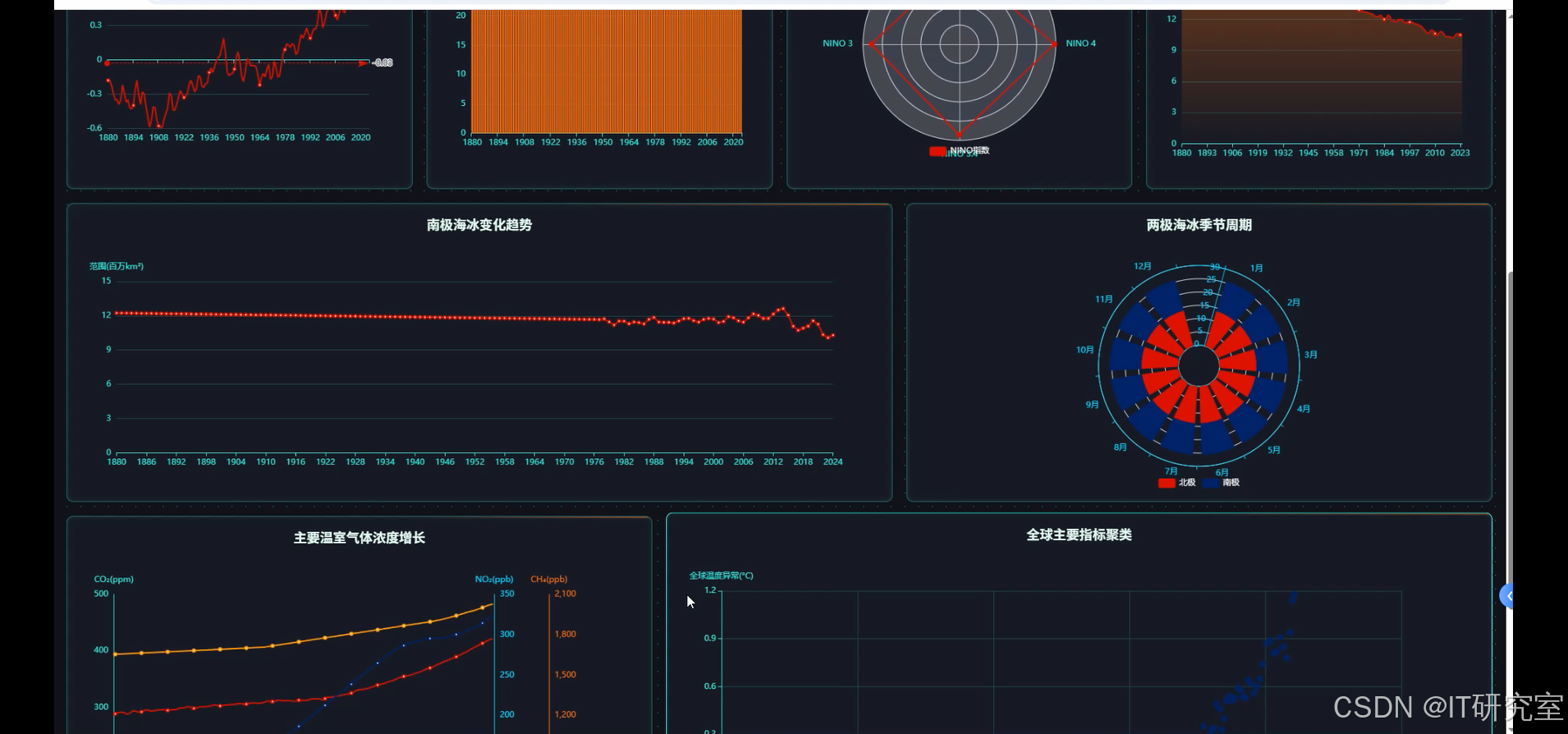
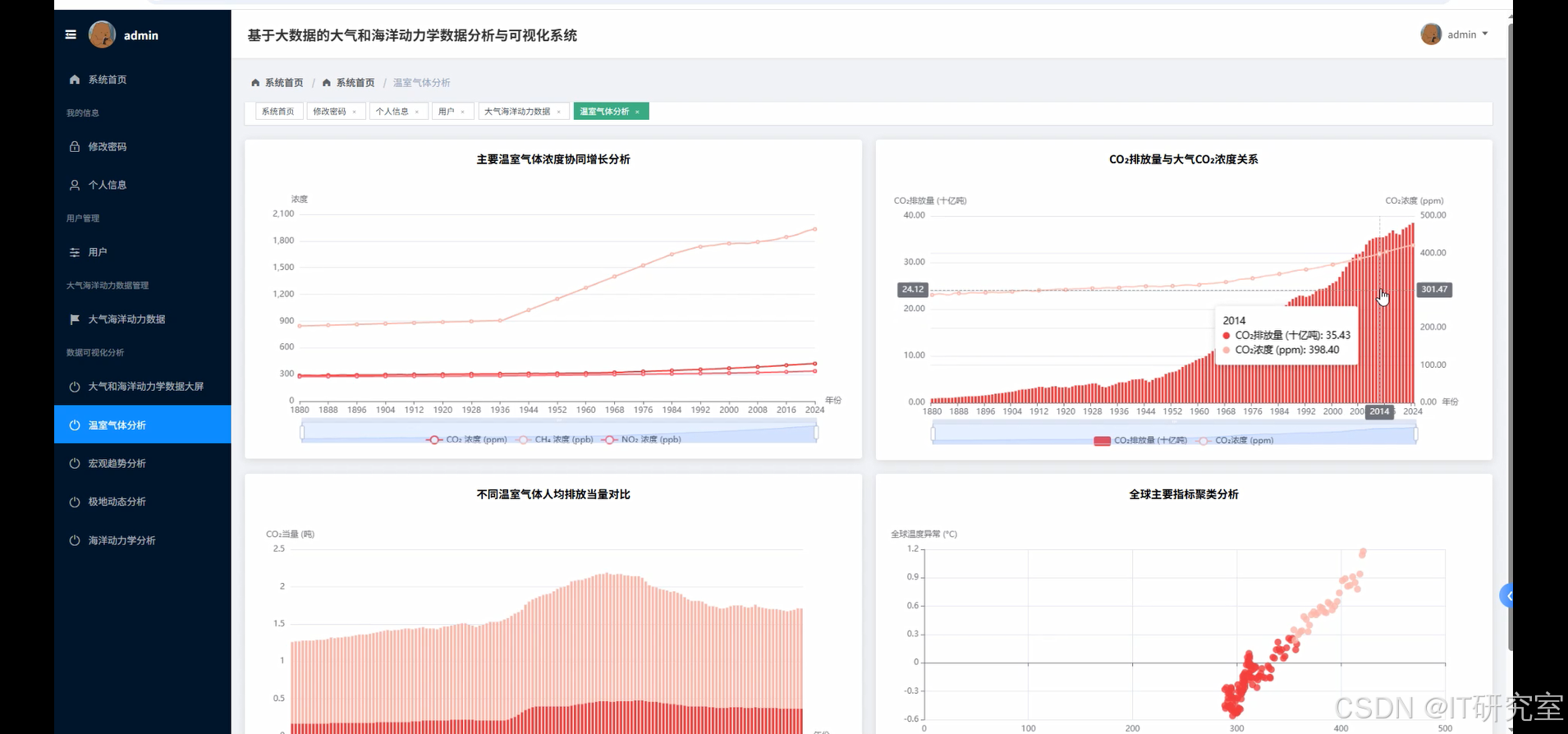
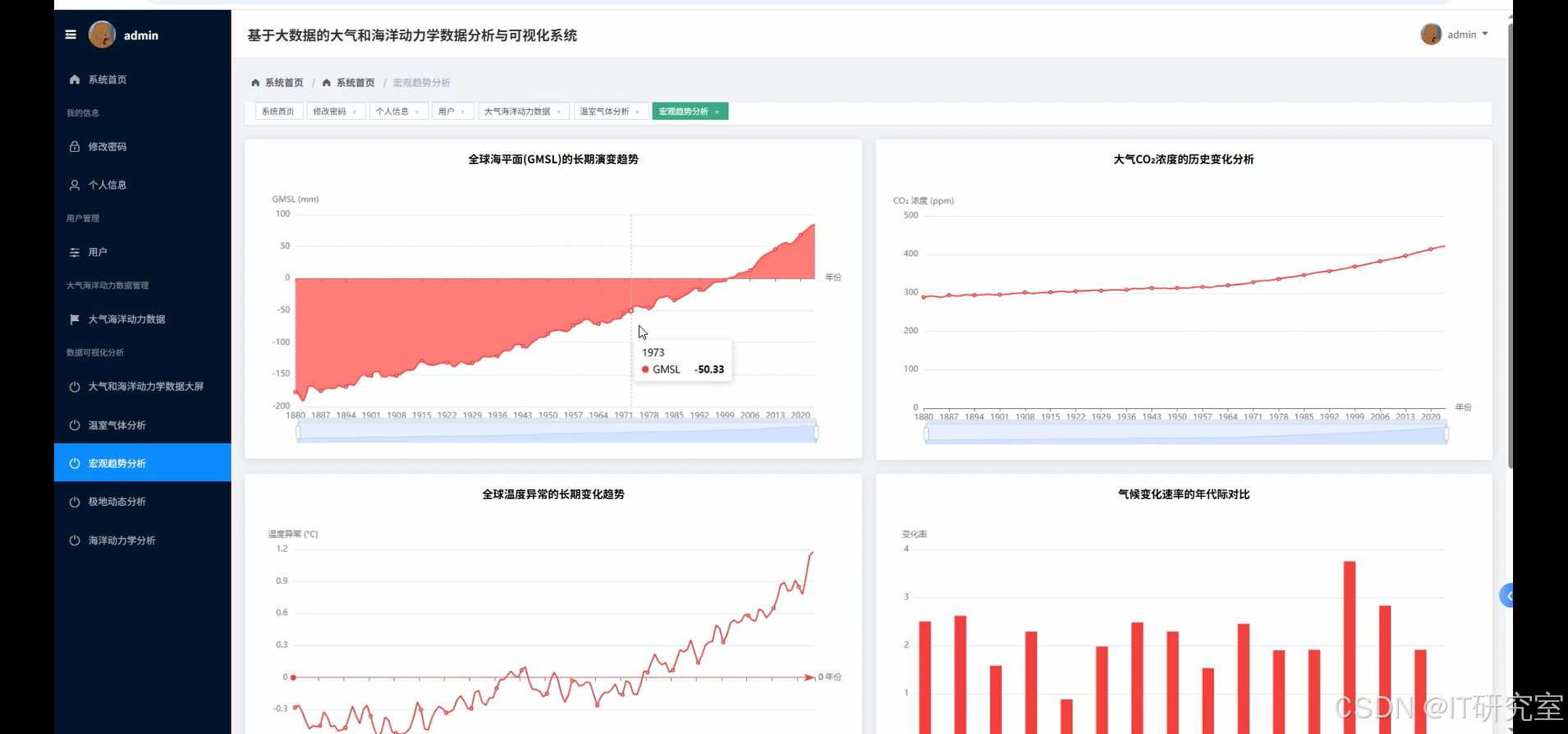
四、代码参考
- 项目实战代码参考:
from pyspark.sql import SparkSession
from pyspark.sql.functions import year, avg, col, when, lag, corr, stddev, sum as _sum
from pyspark.sql.window import Window
spark = SparkSession.builder.appName("ClimateCore").config("spark.executor.memory","4g").getOrCreate()
df = spark.read.csv("hdfs:///climate/All_Feature_Data.csv", header=True, inferSchema=True)
def global_trend_aggregation():
yearly = df.withColumn("yr", year(col("Date"))).groupBy("yr").agg(avg("GMSL").alias("gmsl"), avg("CO2 conc.").alias("co2"), avg("Global avg temp. anomaly relative to 1961-1990").alias("temp_anom"))
win = Window.orderBy("yr")
trend = yearly.withColumn("gmsl_prev", lag("gmsl").over(win)).withColumn("co2_prev", lag("co2").over(win)).withColumn("temp_prev", lag("temp_anom").over(win))
trend = trend.withColumn("gmsl_rate", (col("gmsl")-col("gmsl_prev"))).withColumn("co2_rate", (col("co2")-col("co2_prev"))).withColumn("temp_rate", (col("temp_anom")-col("temp_prev")))
return trend.select("yr","gmsl","co2","temp_anom","gmsl_rate","co2_rate","temp_rate").orderBy("yr")
def enso_impact_on_global_temp():
enso = df.withColumn("yr", year(col("Date"))).select("yr","Nino 3.4","Global avg temp. anomaly relative to 1961-1990")
enso = enso.withColumn("phase", when(col("Nino 3.4")>0.5,"ElNino").when(col("Nino 3.4")<-0.5,"LaNina").otherwise("Neutral"))
impact = enso.groupBy("phase").agg(avg("Global avg temp. anomaly relative to 1961-1990").alias("mean_temp"), stddev("Global avg temp. anomaly relative to 1961-1990").alias("std_temp"), corr("Nino 3.4","Global avg temp. anomaly relative to 1961-1990").alias("corr"))
return impact
def arctic_sea_ice_extreme_analysis():
ice = df.withColumn("yr", year(col("Date"))).groupBy("yr").agg(avg("North Sea Ice Extent Avg").alias("avg_ext"), avg("North Sea Ice Extent Min").alias("min_ext"), avg("North Sea Ice Extent Max").alias("max_ext"))
ice = ice.withColumn("range", col("max_ext")-col("min_ext"))
win = Window.orderBy("yr")
ice = ice.withColumn("avg_prev", lag("avg_ext").over(win)).withColumn("min_prev", lag("min_ext").over(win)).withColumn("max_prev", lag("max_ext").over(win))
ice = ice.withColumn("avg_change", col("avg_ext")-col("avg_prev")).withColumn("min_change", col("min_ext")-col("min_prev")).withColumn("max_change", col("max_ext")-col("max_prev"))
return ice.select("yr","avg_ext","min_ext","max_ext","range","avg_change","min_change","max_change").orderBy("yr")
五、系统视频
基于大数据的大气和海洋动力学数据分析与可视化系统项目视频:
大数据毕业设计选题推荐-基于大数据的大气和海洋动力学数据分析与可视化系统-Spark-Hadoop-Bigdata
结语
大数据毕业设计选题推荐-基于大数据的大气和海洋动力学数据分析与可视化系统_大数据-Spark-Hadoop-Bigdata
想看其他类型的计算机毕业设计作品也可以和我说都有 谢谢大家!
有技术这一块问题大家可以评论区交流或者私我~
大家可以帮忙点赞、收藏、关注、评论啦~
源码获取:⬇⬇⬇
精彩专栏推荐⬇⬇⬇
Java项目
Python项目
安卓项目
微信小程序项目