DreamForge
提出了一种新颖的框架,旨在解决自动驾驶场景下生成真实感强的长时多视角视频序列所面临的挑战。DreamForge 的核心创新之处在于,将基于扩散的自回归模型与可控性、运动感知及时间一致性相关的先进技术相结合。
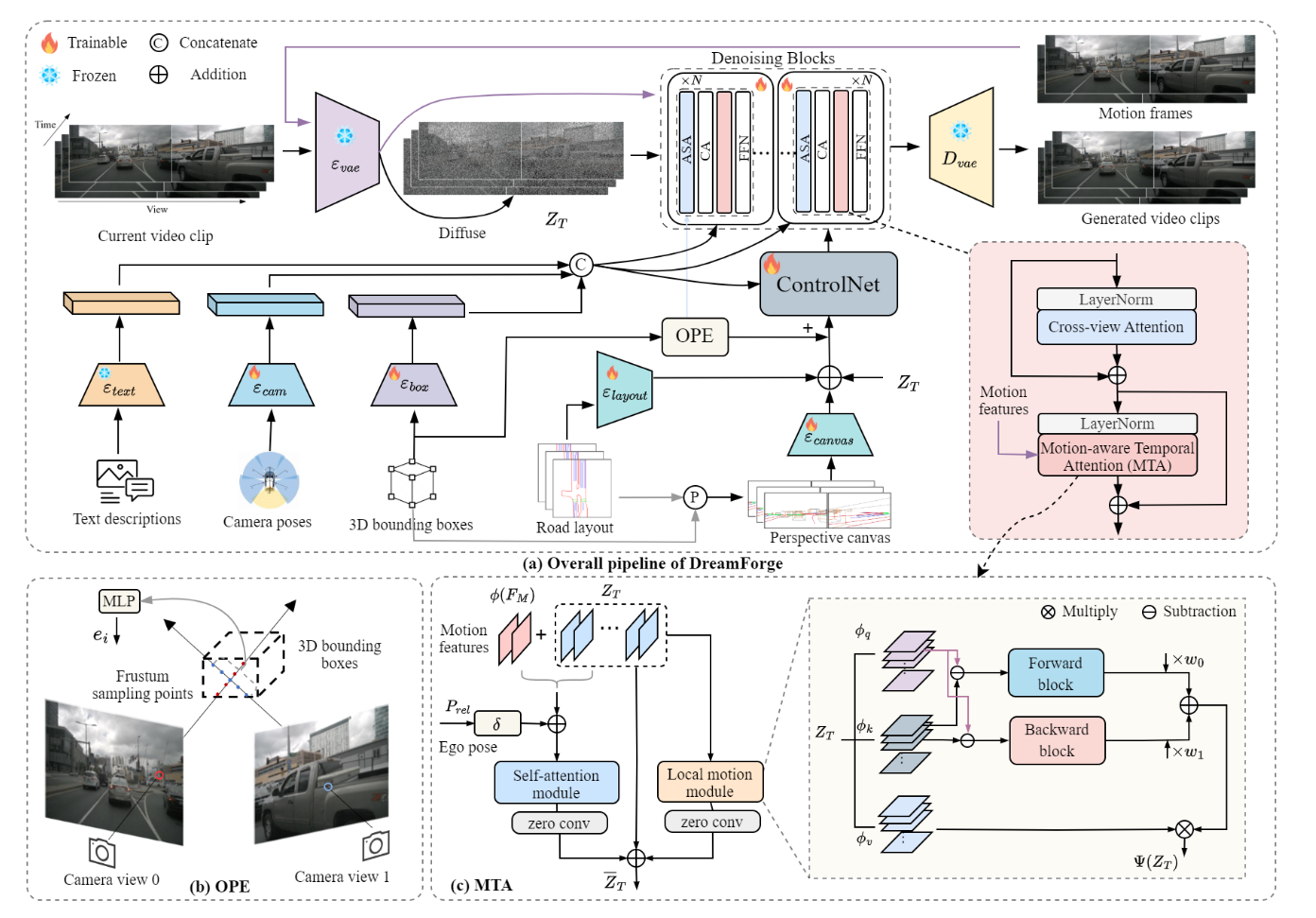
核心贡献总结
- 最先进的生成框架:DreamForge 借助扩散模型改进多视角驾驶场景的生成效果,解决了传统视频生成模型中普遍存在的问题,尤其是长视频连贯性问题。
- 提升可控性:通过引入透视引导(Perspective Guidance)和目标级位置编码(Object-wise Position Encoding)技术,丰富了对街道景观和前景目标的建模,使生成结果在几何准确性和上下文真实性上均有提升。
- 基于运动感知的时间一致性:运动感知时间注意力(Motion-Aware Temporal Attention)机制能有效捕捉运动动态,确保帧间过渡更平滑,并且能够生成比训练时所用视频序列更长的视频。
- 与仿真平台的集成:DreamForge 已与 DriveArena 仿真环境集成,通过为开环和闭环场景提供更真实的驾驶体验,助力提升基于视觉的驾驶智能体(agent)的评估效果。
方法体系
1. 改进的条件可控性
DreamForge 采用多种创新技术,捕捉生成驾驶视频所需的各类条件信息:
- 基于 ControlNet 的条件编码:利用场景描述、相机姿态、三维边界框信息对场景的上下文信息进行编码,其中还引入了高斯噪声,以实现共享的条件表示。
- 透视引导(PG):将道路布局和三维边界框投影到相机视图中,有助于生成上下文丰富且几何准确的图像。
- 目标级位置编码(OPE):通过多相机视角间的局部三维关联,增强对前景目标的建模,确保目标表示的一致性,并更好地呈现空间关系。
2. 运动感知自回归生成
DreamForge 的生成能力源于其运动感知自回归框架:
- 运动感知时间注意力(MTA):该组件通过融合局部和全局运动动态,从相邻帧中计算运动特征。MTA 利用从先前视频中采样的运动帧进行运算,从而为场景生成过程中的动态信息提供上下文支撑。
- 自回归视频生成:系统采用逐帧生成的方式构建视频序列,同时保持时间一致性。前一帧的生成结果会作为下一帧的输入,这使得即使模型主要基于较短序列训练,也能生成较长的视频片段。
3. 与 DriveArena 的集成
该研究将 DreamForge 与 DriveArena 平台集成。DriveArena 是一个模块化平台,支持各类基于视觉的驾驶智能体在动态生成的环境中评估性能,既可用于开环仿真场景,也可用于闭环仿真场景。此次集成旨在在真实场景下验证模型效果,并提升模型的运行指标。
实验设计与结果
评估指标
研究通过多种指标对 DreamForge 的性能进行定量评估,包括:
- 弗雷歇 inception 距离(FID):用于衡量生成样本与真实样本的质量差异。
- 弗雷歇视频距离(FVD):评估视频的长期质量,尤其关注运动一致性。
- 下游任务性能:采用平均精度均值(mAP)和交并比均值(mIoU)等指标,评估模型在目标检测、分割等实际任务中的表现。
定量结果
结果显示,在多种场景下,DreamForge 的性能显著优于现有方法(如 MagicDrive):不仅在视频生成质量上有提升,还解决了以往长视频生成中 “以时间一致性为代价” 的问题,成功生成了超过 200 帧的视频序列。
定性结果
大量案例研究的视觉输出表明,DreamForge 能够适应多种场景条件,与基准模型相比,其生成结果在目标清晰度、道路真实性以及场景整体视觉效果上均具有明显优势。
结论
本文提出的 DreamForge 框架,标志着多视角驾驶场景视频生成技术的重大进步。通过将自回归过程与运动感知、上下文编码技术相结合,DreamForge 不仅提升了合成驾驶场景的真实感,更为自动驾驶和仿真技术的进一步应用奠定了基础。未来的研究方向将聚焦于优化对快速环境变化的表示,例如生成场景中的天气变化和动态光照条件等。