腾讯浑元最新技术:具有表征对齐的多模态扩散,用于高保真拟音音频生成
2025年8月28日,腾讯混元团队宣布开源端到端视频音效生成模型HunyuanVideo-Foley。该模型能够依据输入的视频内容及文字描述,自动生成与画面高度同步的高品质音效,有效解决了AI生成视频缺乏同步音频的沉浸感问题。
此模型的开源意味着视频内容创作者(包括短视频创作者、电影制作人、广告创意人员和游戏开发者)能够更方便地获得专业级别的音频配音能力,真正实现“看懂画面、读懂文字、配准声音
基于表征对齐的多模态扩散模型实现高保真拟音音频生成
作者:腾讯混元,浙江大学 ,南京航空航天大学
项目网站 模型下载 演示空间 代码仓库 论文链接
摘要
当前视频生成技术虽能产生视觉上逼真的内容,但缺乏同步音频严重影响了沉浸感。为解决视频到音频(V2A)生成中的关键挑战,包括多模态数据稀缺、模态不平衡以及现有V2A方法中音频质量有限等问题,我们提出了HunyuanVideo-Foley,一个端到端的文本-视频到音频(TV2A)框架,能够合成与视觉动态和语义语境精确对齐的高保真音频。我们的方法包含三项核心创新:(1)通过自动化标注构建100k小时多模态数据集的可扩展数据流水线;(2)通过双流时序融合和跨模态语义注入解决模态竞争的新型多模态扩散变换器;(3)使用自监督音频特征进行表征对齐(REPA)来指导潜在扩散训练,有效提高生成稳定性和音频质量。综合评估表明,HunyuanVideo-Foley在音频保真度、视觉对齐和分布匹配方面实现了新的最先进性能。
数据流水线

筛选视频-音频数据的数据流水线。工作流程展示了从原始视频数据库到筛选后的视频-音频数据库的处理步骤。
方法概述

HunyuanVideo-Foley模型架构概览。 所提出的模型通过混合框架整合编码后的文本(CLAP)、视觉(SigLIP-2)和音频(DAC-VAE)输入,该框架包含多模态变换器块后接单模态变换器块。混合变换器块通过同步特征和时间步嵌入进行调制和门控。使用预训练的ATST-Frame计算来自单模态变换器块的潜在表征的REPA损失。生成的音频潜在表示通过DAC-VAE解码器解码为音频波形。
实验结果

视频到音频评估的雷达图。包含在三个评估集上的结果:Kling-Audio-Eval、VGGSound-Test和MovieGen-Audio-Bench,表明HunyuanVideo-Foley实现了全面优势。
Kling-Audio-Eval客观评估结果
| 方法 | FDPaNNs↓ | FDPaSST↓ | KL↓ | IS↑ | PQ↑ | PC↓ | CE↑ | CU↑ | IB↑ | DeSync↓ | CLAP↑ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| FoleyCrafter | 22.30 | 322.63 | 2.47 | 7.08 | 6.05 | 2.91 | 3.28 | 5.44 | 0.22 | 1.23 | 0.22 |
| V-AURA | 33.15 | 474.56 | 3.24 | 5.80 | 5.69 | 3.98 | 3.13 | 4.83 | 0.25 | 0.86 | 0.13 |
| Frieren | 16.86 | 293.57 | 2.95 | 7.32 | 5.72 | 2.55 | 2.88 | 5.10 | 0.21 | 0.86 | 0.16 |
| MMAudio | 9.01 | 205.85 | 2.17 | 9.59 | 5.94 | 2.91 | 3.30 | 5.39 | 0.30 | 0.56 | 0.27 |
| ThinkSound | 9.92 | 228.68 | 2.39 | 6.86 | 5.78 | 3.23 | 3.12 | 5.11 | 0.22 | 0.67 | 0.22 |
| HunyuanVideo-Foley ( ours) | 6.07 | 202.12 | 1.89 | 8.30 | 6.12 | 2.76 | 3.22 | 5.53 | 0.38 | 0.54 | 0.24 |
VGGSound-Test客观评估结果
| 方法 | FDPaNNs↓ | FDPaSST↓ | KL↓ | IS↑ | PQ↑ | PC↓ | CE↑ | CU↑ | IB↑ | DeSync↓ | CLAP↑ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| FoleyCrafter | 20.65 | 171.43 | 2.26 | 14.58 | 6.33 | 2.87 | 3.60 | 5.74 | 0.26 | 1.22 | 0.19 |
| V-AURA | 18.91 | 291.72 | 2.40 | 8.58 | 5.70 | 4.19 | 3.49 | 4.87 | 0.27 | 0.72 | 0.12 |
| Frieren | 11.69 | 83.17 | 2.75 | 12.23 | 5.87 | 2.99 | 3.54 | 5.32 | 0.23 | 0.85 | 0.11 |
| MMAudio | 7.42 | 116.92 | 1.77 | 21.00 | 6.18 | 3.17 | 4.03 | 5.61 | 0.33 | 0.47 | 0.25 |
| ThinkSound | 8.46 | 67.18 | 1.90 | 11.11 | 5.98 | 3.61 | 3.81 | 5.33 | 0.24 | 0.57 | 0.16 |
| HunyuanVideo-Foley ( ours) | 11.34 | 145.22 | 2.14 | 16.14 | 6.40 | 2.78 | 3.99 | 5.79 | 0.36 | 0.53 | 0.24 |
MovieGen-Audio-Bench主客观评估结果
| 方法 | PQ↑ | PC↓ | CE↑ | CU↑ | IB↑ | DeSync↓ | CLAP↑ | MOS-Q↑ | MOS-S↑ | MOS-T↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| FoleyCrafter | 6.27 | 2.72 | 3.34 | 5.68 | 0.17 | 1.29 | 0.14 | 3.36±0.78 | 3.54±0.88 | 3.46±0.95 |
| V-AURA | 5.82 | 4.30 | 3.63 | 5.11 | 0.23 | 1.38 | 0.14 | 2.55±0.97 | 2.60±1.20 | 2.70±1.37 |
| Frieren | 5.71 | 2.81 | 3.47 | 5.31 | 0.18 | 1.39 | 0.16 | 2.92±0.95 | 2.76±1.20 | 2.94±1.26 |
| MMAudio | 6.17 | 2.84 | 3.59 | 5.62 | 0.27 | 0.80 | 0.35 | 3.58±0.84 | 3.63±1.00 | 3.47±1.03 |
| ThinkSound | 6.04 | 3.73 | 3.81 | 5.59 | 0.18 | 0.91 | 0.20 | 3.20±0.97 | 3.01±1.04 | 3.02±1.08 |
| HunyuanVideo-Foley ( ours) | 6.59 | 2.74 | 3.88 | 6.13 | 0.35 | 0.74 | 0.33 | 4.14±0.68 | 4.12±0.77 | 4.15±0.75 |
实验结果表明,HunyuanVideo-Foley在多个评估数据集上均取得了优越的性能,在音频质量、时序对齐和跨模态一致性等关键指标上 consistently 优于基线方法。
结果与对比
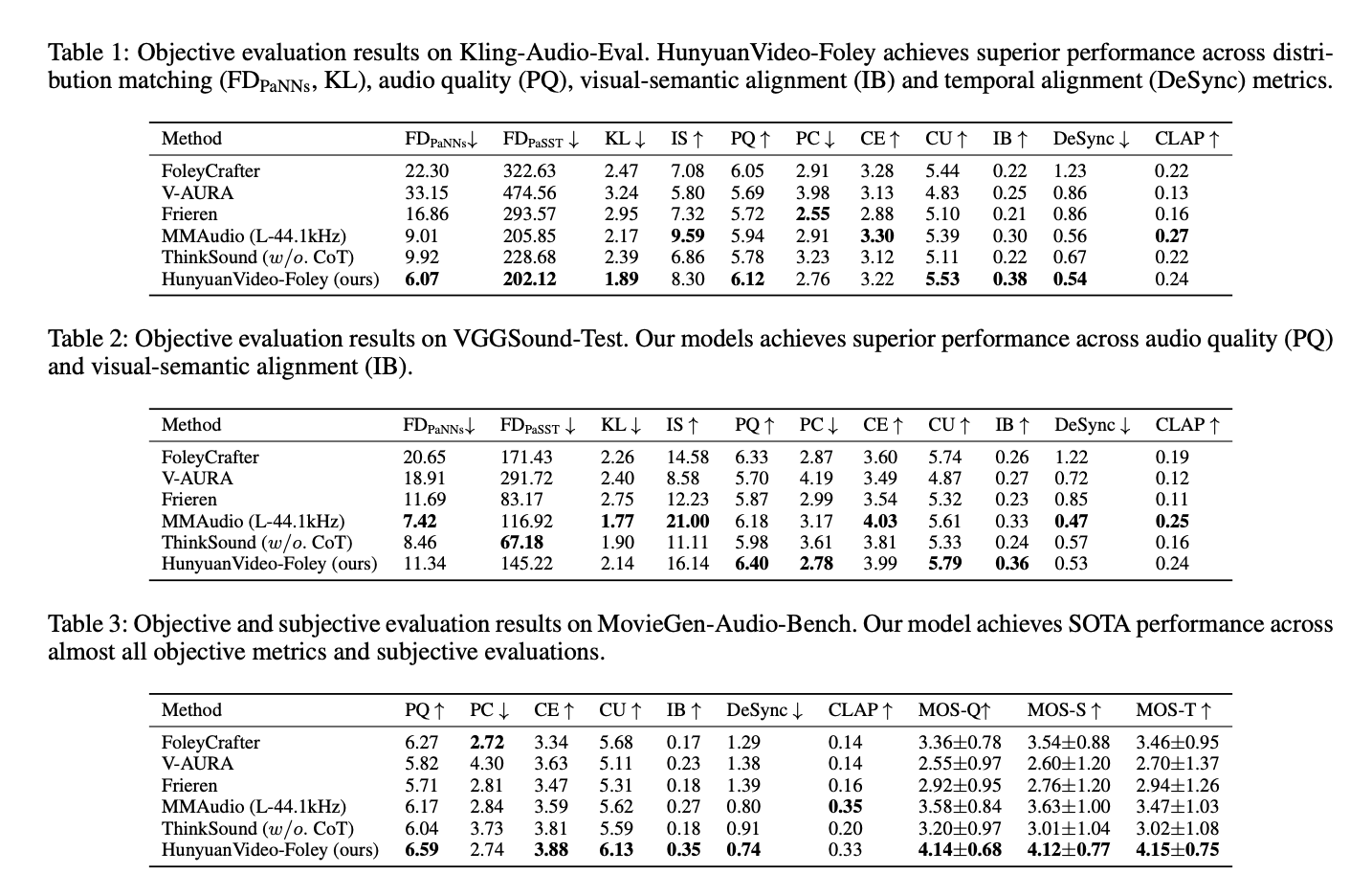
我们的HunyuanVideo-Foley框架相比现有方法展现出卓越性能。以下是不同方法生成的视频-音频对比:更多视频例子:https://szczesnys.github.io/hunyuanvideo-foley/
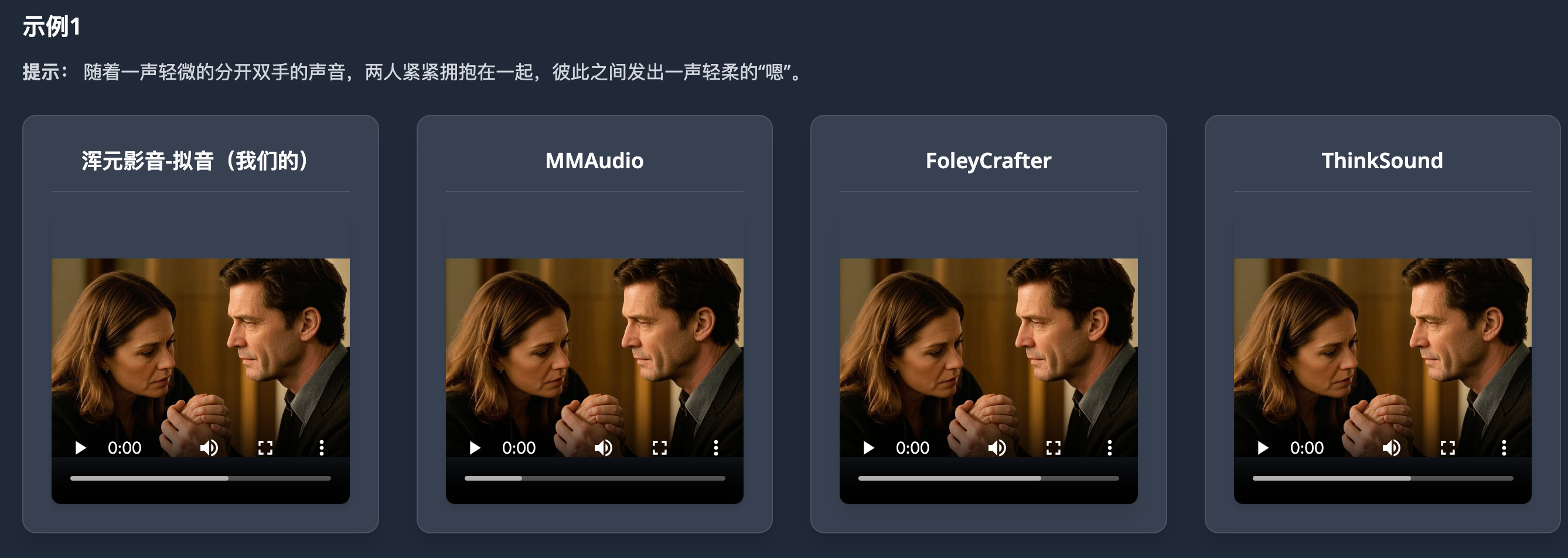
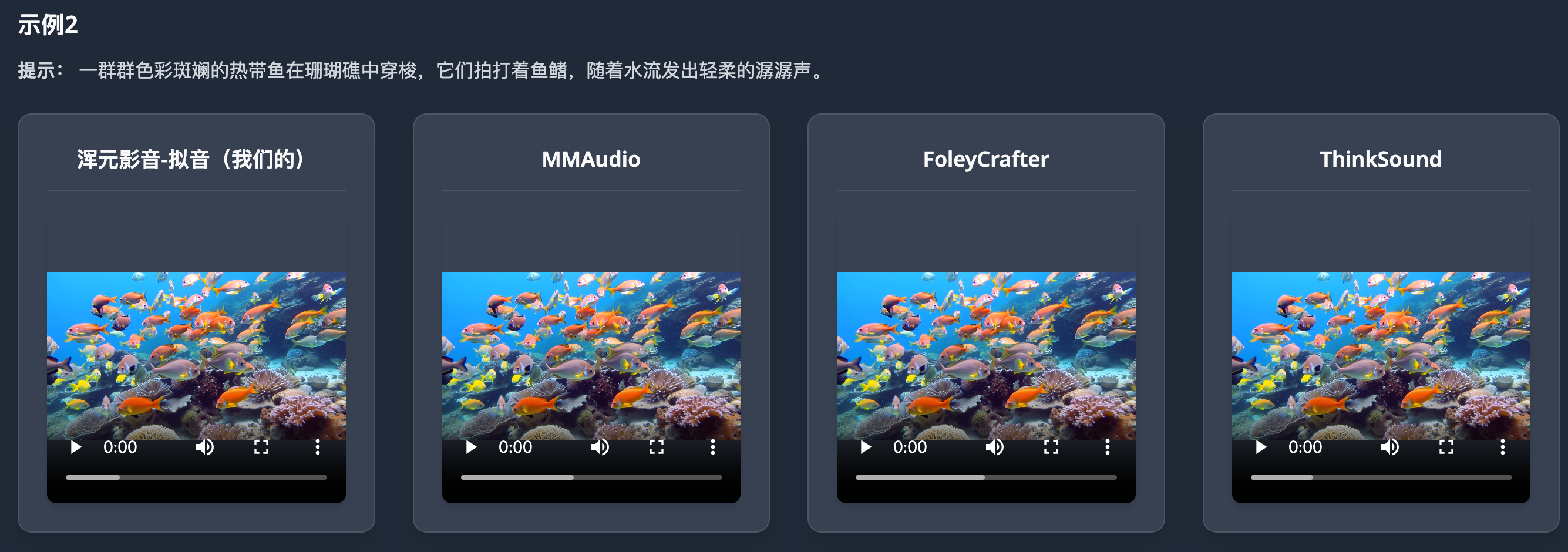
应用场景:赋能多元行业创作
HunyuanVideo-Foley的视频音效生成能力正为多元行业带来高效便捷的解决方案:
-
短视频创作:能自动适配搞笑段子、生活vlog、AI视频等内容的场景氛围,一键生成贴合画面节奏的背景音效,让创意表达更具感染力。
-
电影制作:助力电影制作团队突破传统音效制作的周期与成本瓶颈,快速构建环境音、拟音等细节丰富的声效场景,实现降本提效的后期制作升级。
-
广告创意:为汽车广告自动合成引擎启动、加速行驶等音效,强化产品质感与品牌印象。
-
游戏开发:实时生成森林鸟鸣、雨滴落地等环境音效,增强玩家沉浸式体验。
-
在线教育:为科普视频加入火山喷发、雷电交加等生动音效,激发学习兴趣与记忆效果
HunyuanVideo-Foley的发布标志着AI视频生成从“只能看”迈向“既能看又能听”的新阶段。其卓越的多模态理解能力、专业级的音频保真度以及强大的泛化性能,使其成为视频内容创作领域的革命性工具。