【大语言模型 30】指令微调数据工程:高质量数据集构建
【大语言模型 30】指令微调数据工程:高质量数据集构建
关键词:指令微调、数据工程、数据集构建、数据质量评估、指令-响应对、数据增强、数据平衡、RLHF
摘要:指令微调是大语言模型从预训练到实际应用的关键桥梁,而高质量的指令数据集则是这一过程的基石。本文深入探讨指令微调数据工程的全流程,包括数据来源、格式设计、质量评估维度、构建流程、数据增强技术以及最佳实践。通过系统化的数据工程方法,我们可以构建出多样性强、质量高、对齐度好的指令数据集,从而显著提升模型的指令遵循能力和实用价值。
文章目录
- 【大语言模型 30】指令微调数据工程:高质量数据集构建
- 1. 引言:指令微调的数据基石
- 2. 指令微调数据的基本构成
- 2.1 指令-响应对的核心要素
- 2.2 数据格式与标准化
- 3. 指令微调数据的来源与收集
- 3.1 公开数据集整合
- 3.2 人工标注与合成
- 3.3 多样性与覆盖度设计
- 4. 指令微调数据集构建流程
- 4.1 数据收集与初步筛选
- 4.2 数据清洗与标准化
- 4.3 质量评估与筛选
- 4.4 数据增强与多样化
- 4.5 数据平衡与分布调整
- 4.6 验证与迭代优化
- 5. 指令微调数据质量评估框架
- 5.1 自动化评估指标
- 5.2 人工评估方法
- 5.3 混合评估流程
- 6. 指令微调数据集的应用与最佳实践
- 6.1 与RLHF的结合
- 6.2 领域适应与定制化
- 6.3 数据集构建的最佳实践
- 7. 结论与未来展望
- 参考资料
1. 引言:指令微调的数据基石
在大语言模型(LLM)的发展历程中,预训练赋予模型强大的语言理解和生成能力,而指令微调(Instruction Tuning)则是将这种能力引导向实际应用的关键步骤。ChatGPT、Claude、Llama等当前主流大语言模型的成功,很大程度上归功于高质量的指令微调数据集。
然而,构建一个优质的指令微调数据集绝非易事。它不仅需要覆盖广泛的任务类型和领域知识,还需要确保指令与响应之间的高度对齐,同时平衡数据的多样性与一致性。本文将系统性地探讨指令微调数据工程的各个环节,从数据收集、清洗、增强到质量评估,为构建高效能的指令微调数据集提供全面指南。
2. 指令微调数据的基本构成
2.1 指令-响应对的核心要素
指令微调数据的基本单元是"指令-响应对"(Instruction-Response Pair),它通常包含以下核心要素:
- 指令(Instruction):明确的任务描述或问题,告诉模型应该做什么。
- 响应(Response):对指令的高质量回答或执行结果。
- 上下文(Context):可选的背景信息,为指令提供必要的参考。
- 系统提示(System Prompt):可选的角色设定或行为指导,定义模型的回答风格和限制。
一个典型的指令-响应对示例:
{"instruction": "解释量子计算的基本原理,并说明它与经典计算的主要区别。","response": "量子计算利用量子力学原理进行信息处理。与经典计算使用比特(0或1)不同,量子计算使用量子比特,可以同时处于多个状态的叠加。这种特性使量子计算机能够并行处理大量可能性,理论上可以解决某些经典计算机难以高效解决的问题,如大数分解和复杂系统模拟。然而,量子计算面临量子相干性维持和错误校正等挑战。","context": null,"system": "你是一位专业的科学教育者,擅长将复杂概念简化解释。"
}
2.2 数据格式与标准化
为了便于处理和训练,指令微调数据通常采用结构化的格式存储,主流格式包括:
- JSON格式:最常用的格式,每个样本包含指令、响应等字段。
- JSONL格式:每行一个JSON对象,便于流式处理大规模数据。
- CSV/TSV格式:简单的表格形式,适合基础的指令-响应对。
- 对话格式:针对多轮对话场景,包含完整的对话历史。
标准化处理是确保数据一致性的关键步骤,包括:
- 统一字段命名和数据结构
- 规范化文本格式(如空白字符、标点符号)
- 处理特殊字符和编码问题
- 确保长度适中,避免过长或过短的样本
# 数据标准化示例代码
def standardize_instruction_data(data_item):# 确保基本字段存在if 'instruction' not in data_item or 'response' not in data_item:return None# 标准化文本格式instruction = data_item['instruction'].strip()response = data_item['response'].strip()# 过滤过短的样本if len(instruction) < 10 or len(response) < 20:return None# 构建标准化的数据项standardized_item = {'instruction': instruction,'response': response,'context': data_item.get('context', ''),'system': data_item.get('system', ''),'metadata': {'source': data_item.get('source', 'unknown'),'domain': data_item.get('domain', 'general'),'difficulty': data_item.get('difficulty', 'medium')}}return standardized_item
3. 指令微调数据的来源与收集
3.1 公开数据集整合
目前已有多个高质量的公开指令微调数据集,可以作为构建自己数据集的基础:
- Stanford Alpaca:基于Self-Instruct方法生成的52K指令-响应对。
- Anthropic’s HH-RLHF:包含约160K人类反馈数据的对话数据集。
- OpenAI’s WebGPT:基于网络搜索的问答数据集。
- FLAN Collection:Google的指令微调数据集合,涵盖多种任务类型。
- Dolly 2.0:Databricks开源的指令微调数据集,由人类专家创建。
- Open Assistant:一个大规模的众包指令数据集,包含多语言支持。
整合这些数据集时,需要注意:
- 数据许可和使用限制
- 格式统一和字段映射
- 去重和冲突解决
- 质量筛选和平衡采样
3.2 人工标注与合成
对于特定领域或任务,往往需要定制化的指令数据,主要获取方式包括:
-
专家标注:由领域专家创建高质量的指令-响应对,质量高但成本较高。
-
众包标注:通过众包平台收集大量标注,成本较低但需要严格的质量控制。
-
模型辅助生成:利用现有强大模型生成指令-响应对,主要方法有:
- Self-Instruct:让模型自己生成指令,然后回答这些指令。
- Evol-Instruct:通过演化算法不断提升指令的复杂度和多样性。
- Complex-Instruct:专注于生成需要复杂推理能力的指令。
# Self-Instruct简化实现示例
def generate_instruction_data(base_model, num_samples=100, seed_tasks=None):if seed_tasks is None:seed_tasks = ["解释什么是机器学习","写一首关于春天的诗","分析气候变化的主要原因"]generated_data = []existing_instructions = set(seed_tasks)# 使用种子任务初始化for task in seed_tasks:response = base_model.generate(f"指令: {task}\n回答:")generated_data.append({"instruction": task, "response": response})# 生成新指令和响应while len(generated_data) < num_samples:# 让模型生成新指令prompt = "请生成一个新的、有创意的指令,该指令可以测试语言模型的能力。指令应该不同于以下已有指令:\n"for i in range(min(5, len(existing_instructions))):prompt += f"- {list(existing_instructions)[i]}\n"prompt += "\n新指令:"new_instruction = base_model.generate(prompt).strip()# 检查是否是新指令if new_instruction in existing_instructions:continue# 生成响应response = base_model.generate(f"指令: {new_instruction}\n回答:")# 添加到数据集generated_data.append({"instruction": new_instruction, "response": response})existing_instructions.add(new_instruction)return generated_data
3.3 多样性与覆盖度设计
高质量的指令数据集应当具备广泛的多样性和覆盖度,主要考虑以下维度:
-
任务类型多样性:
- 文本生成(创意写作、摘要、翻译等)
- 问答(开放域、封闭域)
- 分类和情感分析
- 推理和逻辑任务
- 代码生成与解释
- 多模态任务(如图像描述)
-
领域知识覆盖:
- 科学技术(计算机、物理、生物等)
- 人文社科(历史、文学、哲学等)
- 商业金融
- 医疗健康
- 法律法规
- 日常生活
-
复杂度梯度:
- 简单事实性问题
- 中等复杂度的分析问题
- 高复杂度的推理和创造性任务
-
指令形式变化:
- 直接问题
- 角色扮演场景
- 步骤引导式任务
- 多步骤复合任务
4. 指令微调数据集构建流程
构建高质量指令微调数据集是一个系统工程,需要遵循一套完整的流程:
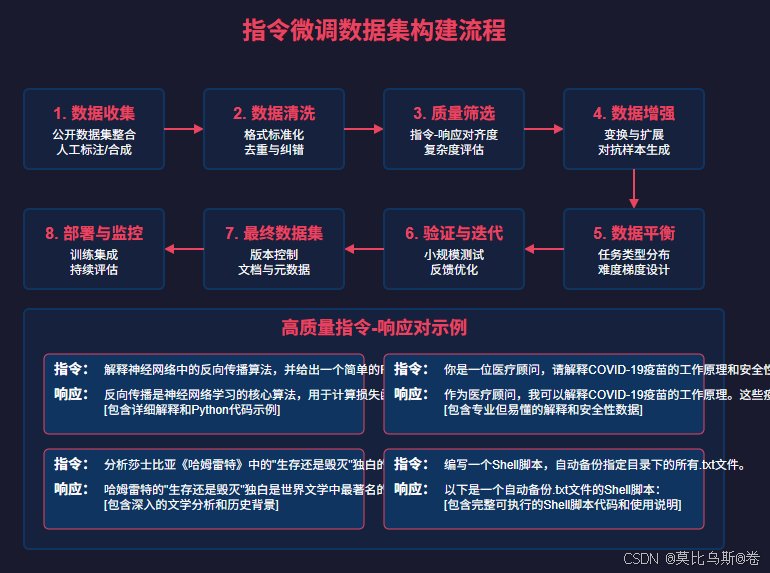
4.1 数据收集与初步筛选
数据收集阶段的关键步骤:
- 确定目标和范围:明确数据集的用途、规模和覆盖领域。
- 多源数据整合:结合公开数据集、人工标注和模型生成数据。
- 初步质量筛选:
- 过滤明显低质量样本(如过短、无意义的内容)
- 检查基本格式和完整性
- 移除重复或高度相似的样本
# 初步质量筛选示例
def initial_quality_filter(data_items):filtered_data = []seen_instructions = set()for item in data_items:# 检查必要字段if 'instruction' not in item or 'response' not in item:continueinstruction = item['instruction'].strip()response = item['response'].strip()# 长度检查if len(instruction) < 10 or len(response) < 20:continue# 去重检查(使用简化的方法,实际可能需要更复杂的相似度计算)instr_hash = hash(instruction.lower())if instr_hash in seen_instructions:continueseen_instructions.add(instr_hash)filtered_data.append(item)return filtered_data
4.2 数据清洗与标准化
数据清洗是确保数据集质量的关键环节:
-
文本清洗:
- 修正拼写和语法错误
- 规范化标点符号和空白字符
- 处理特殊字符和HTML标签
-
结构标准化:
- 统一字段名称和数据格式
- 确保所有样本具有一致的结构
- 添加必要的元数据(如来源、领域分类)
-
内容规范化:
- 确保指令明确且具有可执行性
- 检查响应是否完整且与指令相关
- 调整过长的内容,保持适当长度
4.3 质量评估与筛选
质量评估是构建优质数据集的核心环节,需要从多个维度进行:
-
指令质量评估:
- 明确性:指令是否清晰、无歧义
- 可执行性:模型是否能理解并执行该指令
- 多样性:是否覆盖不同类型和难度的任务
-
响应质量评估:
- 准确性:内容是否正确无误
- 完整性:是否完整回答了指令要求
- 流畅性:语言是否自然流畅
- 有用性:对用户是否有实际价值
-
指令-响应对齐度:
- 相关性:响应是否与指令高度相关
- 遵循度:是否严格遵循了指令的所有要求
- 风格一致性:是否符合指定的回答风格
质量评估可以通过以下方式实施:
- 人工评估:专家审核或众包评分
- 自动化评估:使用NLP指标或模型辅助评分
- 混合评估:结合自动初筛和人工复核
# 使用强模型辅助评估质量的示例
def evaluate_instruction_quality(item, evaluator_model):instruction = item['instruction']response = item['response']# 评估指令质量instruction_quality_prompt = f"""评估以下指令的质量,从1-10打分,考虑其明确性、可执行性和价值:指令:{instruction}评分(1-10):"""instruction_score = float(evaluator_model.generate(instruction_quality_prompt).strip())# 评估响应质量response_quality_prompt = f"""评估以下响应的质量,从1-10打分,考虑其准确性、完整性和流畅性:指令:{instruction}响应:{response}评分(1-10):"""response_score = float(evaluator_model.generate(response_quality_prompt).strip())# 评估指令-响应对齐度alignment_prompt = f"""评估以下响应与指令的对齐程度,从1-10打分,考虑响应是否完全满足指令要求:指令:{instruction}响应:{response}对齐度评分(1-10):"""alignment_score = float(evaluator_model.generate(alignment_prompt).strip())# 计算综合质量分数quality_score = (instruction_score + response_score + alignment_score) / 3return {'instruction_score': instruction_score,'response_score': response_score,'alignment_score': alignment_score,'quality_score': quality_score}
4.4 数据增强与多样化
数据增强技术可以显著提升数据集的规模和多样性:
-
变换技术:
- 回译:将文本翻译成另一种语言再翻译回来,产生表达变化
- 释义:使用不同表达方式重写相同内容
- 风格转换:改变语言风格但保持核心内容
-
组合与拆分:
- 将复杂指令拆分为多个简单指令
- 将相关的简单指令组合成复杂指令
-
对抗样本生成:
- 创建容易混淆或误导模型的指令
- 设计需要特定推理能力的挑战性任务
-
模板化变异:
- 基于模板生成结构相似但内容不同的样本
- 替换关键词和实体,保持指令结构
# 使用回译进行数据增强的示例
def augment_by_backtranslation(item, translator_model):instruction = item['instruction']# 翻译成中间语言(如法语)to_french_prompt = f"将以下英文翻译成法语:\n{instruction}"french_version = translator_model.generate(to_french_prompt)# 翻译回原始语言to_english_prompt = f"将以下法语翻译成英文:\n{french_version}"back_translated = translator_model.generate(to_english_prompt)# 创建新的数据项new_item = item.copy()new_item['instruction'] = back_translatednew_item['metadata'] = item.get('metadata', {}).copy()new_item['metadata']['augmentation'] = 'backtranslation'return new_item
4.5 数据平衡与分布调整
数据平衡是确保模型全面能力的关键:
-
任务类型平衡:
- 确保不同任务类型的样本数量相对均衡
- 避免某类任务过度主导数据集
-
难度梯度分布:
- 设计从简单到复杂的难度梯度
- 确保各难度级别的样本比例合理
-
领域知识覆盖:
- 平衡不同领域的知识覆盖
- 根据应用场景调整特定领域的比重
-
长度分布调整:
- 确保指令和响应长度分布合理
- 包含足够的长文本样本以训练长文生成能力
# 数据平衡示例:根据任务类型进行平衡采样
def balanced_sampling(data_items, target_distribution, max_samples):# 按任务类型分组task_groups = {}for item in data_items:task_type = item.get('metadata', {}).get('task_type', 'general')if task_type not in task_groups:task_groups[task_type] = []task_groups[task_type].append(item)# 根据目标分布进行采样balanced_dataset = []for task_type, percentage in target_distribution.items():if task_type not in task_groups:continuetarget_count = int(max_samples * percentage / 100)available_count = len(task_groups[task_type])# 如果可用样本不足,全部使用if available_count <= target_count:balanced_dataset.extend(task_groups[task_type])else:# 随机采样到目标数量sampled = random.sample(task_groups[task_type], target_count)balanced_dataset.extend(sampled)return balanced_dataset
4.6 验证与迭代优化
数据集构建是一个迭代过程,需要不断验证和优化:
-
小规模测试:
- 使用数据集的子集进行快速微调测试
- 评估模型在各类任务上的表现
-
错误分析:
- 识别模型表现不佳的指令类型
- 分析数据集中的潜在问题和偏差
-
数据集迭代:
- 基于测试结果调整数据分布
- 增加表现不佳领域的高质量样本
- 优化指令和响应的质量
-
版本控制:
- 为数据集建立版本控制系统
- 记录每次迭代的变更和改进
- 进行A/B测试比较不同版本的效果
5. 指令微调数据质量评估框架
构建一个系统化的质量评估框架对于指令数据集至关重要:

5.1 自动化评估指标
自动化评估可以高效处理大规模数据:
-
文本统计指标:
- 词汇多样性(如Type-Token Ratio)
- 句法复杂度(平均句长、从句比例等)
- 实体和关键词覆盖率
-
NLP评估指标:
- BLEU、ROUGE(对于有参考答案的任务)
- BERTScore(语义相似度评估)
- Perplexity(流畅度评估)
-
模型辅助评分:
- 使用强大模型(如GPT-4)评估质量
- 多维度打分(准确性、相关性、有用性等)
- 一致性检查(多次生成结果的稳定性)
# 计算词汇多样性的示例函数
def calculate_lexical_diversity(text):words = text.lower().split()unique_words = set(words)if len(words) == 0:return 0return len(unique_words) / len(words)# 使用BERTScore评估语义相似度
def calculate_bert_score(candidate, reference, model):from bert_score import scoreP, R, F1 = score([candidate], [reference], lang="en", model_type=model)return {'precision': P.item(),'recall': R.item(),'f1': F1.item()}
5.2 人工评估方法
人工评估仍是质量控制的金标准:
-
专家评审:
- 由领域专家评估指令和响应质量
- 使用标准化评分表进行多维度评分
- 提供定性反馈和改进建议
-
众包评估:
- 设计清晰的评估指南和标准
- 使用多人独立评分取平均值
- 实施质量控制机制(如一致性检查)
-
用户测试:
- 收集真实用户对模型回答的反馈
- 分析用户满意度和实用性评价
- 识别实际应用中的问题和不足
5.3 混合评估流程
结合自动化和人工评估的混合流程最为有效:
-
多阶段筛选:
- 第一阶段:自动化初筛(过滤明显低质量样本)
- 第二阶段:模型辅助评分(使用强模型打分)
- 第三阶段:人工抽样验证(对关键样本人工审核)
-
持续改进循环:
- 评估 → 识别问题 → 优化数据 → 再评估
- 建立反馈机制,不断提升数据质量
-
多维度质量分数:
- 综合多个评估维度的加权分数
- 设定质量阈值,筛选高质量样本
# 混合评估流程示例
def hybrid_evaluation_pipeline(data_items):# 第一阶段:自动化初筛filtered_items = []for item in data_items:# 基本质量检查instruction_length = len(item['instruction'].split())response_length = len(item['response'].split())diversity_score = calculate_lexical_diversity(item['response'])# 设定基本阈值if instruction_length < 5 or response_length < 20 or diversity_score < 0.4:continuefiltered_items.append(item)# 第二阶段:模型辅助评分scored_items = []for item in filtered_items:# 使用评估模型打分quality_scores = evaluate_with_model(item, evaluator_model)item['quality_scores'] = quality_scores# 设定质量阈值if quality_scores['overall'] >= 7.0:scored_items.append(item)# 第三阶段:人工抽样验证# 从高分样本中随机抽取一部分进行人工验证sample_size = min(len(scored_items) // 10, 100) # 抽取10%或最多100个样本validation_sample = random.sample(scored_items, sample_size)# 人工验证结果用于调整自动评分系统# ...return scored_items
6. 指令微调数据集的应用与最佳实践
6.1 与RLHF的结合
指令微调数据集通常与人类反馈强化学习(RLHF)结合使用:
-
SFT与RLHF的协同:
- 先使用高质量指令数据进行监督微调(SFT)
- 再使用人类偏好数据进行RLHF优化
-
偏好数据收集:
- 基于指令数据生成多个模型回答
- 收集人类对这些回答的排序偏好
- 构建奖励模型和强化学习训练
-
迭代优化循环:
- SFT → 偏好收集 → RLHF → 评估 → 数据优化 → 再SFT
6.2 领域适应与定制化
针对特定领域的指令微调数据构建:
-
领域知识富集:
- 收集特定领域的专业指令-响应对
- 确保专业术语和知识的准确性
- 覆盖领域内的常见任务和问题
-
风格与语气定制:
- 根据目标应用定制响应风格
- 调整专业性与通俗性的平衡
- 设计符合品牌调性的回答模式
-
安全与合规考量:
- 确保数据符合行业规范和法规
- 避免敏感信息和潜在偏见
- 加入安全边界测试样本
6.3 数据集构建的最佳实践
总结指令微调数据集构建的关键最佳实践:
-
质量优先于数量:
- 宁可数据量小但质量高
- 严格的质量控制比盲目扩大规模更重要
-
多样性与平衡并重:
- 确保任务类型、领域和难度的多样性
- 避免数据分布偏斜导致的能力不均衡
-
持续评估与迭代:
- 建立完整的评估-优化循环
- 根据模型表现不断调整数据集
-
元数据与版本控制:
- 为每个样本添加详细元数据
- 实施严格的版本控制和变更记录
-
结合自动化与人工审核:
- 利用自动化工具提高效率
- 保留关键环节的人工审核
7. 结论与未来展望
高质量的指令微调数据集是大语言模型从通用能力到专业应用的关键桥梁。通过系统化的数据工程方法,我们可以构建出多样性强、质量高、对齐度好的指令数据集,从而显著提升模型的指令遵循能力和实用价值。
未来指令微调数据工程的发展方向包括:
-
自动化数据生成与评估:更先进的自动化工具将简化数据构建流程。
-
多模态指令数据:扩展到图像、音频等多模态指令微调。
-
个性化指令适应:针对个人偏好和使用习惯的定制化指令数据。
-
跨语言指令数据:构建多语言、跨语言的指令数据集。
-
动态数据集:根据模型使用反馈动态调整的自适应数据集。
通过不断创新和优化指令微调数据工程,我们将能够开发出更加智能、有用且安全的大语言模型,为各行各业带来更大的价值。
参考资料
- Wei, J., et al. (2022). Finetuned Language Models Are Zero-Shot Learners. ICLR 2022.
- Ouyang, L., et al. (2022). Training language models to follow instructions with human feedback. NeurIPS 2022.
- Wang, Y., et al. (2022). Self-Instruct: Aligning Language Models with Self-Generated Instructions. arXiv:2212.10560.
- Taori, R., et al. (2023). Stanford Alpaca: An Instruction-following LLaMA model. https://github.com/tatsu-lab/stanford_alpaca.
- Anthropic. (2022). Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback.
- Databricks. (2023). Dolly: A Large Language Model Trained on a Large Corpus of Human-Generated Text.
2022). Finetuned Language Models Are Zero-Shot Learners. ICLR 2022. - Ouyang, L., et al. (2022). Training language models to follow instructions with human feedback. NeurIPS 2022.
- Wang, Y., et al. (2022). Self-Instruct: Aligning Language Models with Self-Generated Instructions. arXiv:2212.10560.
- Taori, R., et al. (2023). Stanford Alpaca: An Instruction-following LLaMA model. https://github.com/tatsu-lab/stanford_alpaca.
- Anthropic. (2022). Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback.
- Databricks. (2023). Dolly: A Large Language Model Trained on a Large Corpus of Human-Generated Text.
- LAION. (2023). Open Assistant: A Conversational AI for Everyone. https://open-assistant.io/.