一文了解大模型微调
1.在某个模型基础上做全参数微调,需要多少显存?
一般 n B 的模型,最低需要 16 - 20 n G 的显存。(gpu offload 基本不开的情况下)
2.SFT
监督微调是在预训练模型基础上,利用标注好的特定任务数据集对模型进行进一步训练的过程。预训练模型(如 GPT、BERT 等)已经在大规模的通用数据上进行了训练,学习到了广泛的语言知识和语义表示。但当面对具体的下游任务,如情感分类、机器翻译、信息抽取等时,就需要通过监督微调,让模型适应特定任务的需求,提升在该任务上的性能 。
3.Continue PreTrain
Continue PreTrain 即继续预训练,也被称为持续预训练或增量预训练 ,是在预训练模型基础上进一步开展的预训练过程。
在完成对模型的初始大规模通用数据预训练后(比如 BERT 在海量的文本语料上完成预训练 ,学习到通用的语言模式、语义表示等),基于特定的目标和需求,使用新的、不同类型或领域的数据集对模型再次进行预训练。这些新数据集可能是特定领域的文本(如医学文献、法律条文等)、特定格式的数据,或者是为了弥补初始预训练数据不足而补充的数据。
数据选取:技术标准文档或领域相关数据是领域模型 Continue PreTrain 的关键
领域数据训练后,通用能力往往会有所下降,如何缓解模型遗忘通用能力:通常在领域训练的过程中加入通用数据集,这个比例主要与领域数据量有关系,当数据量没有那么多时,一般领域数据与通用数据的比例在 1:5 到 1:10 之间是比较合适的。
领域模型 Continue PreTrain,如何让模型在预训练过程中就学习到更多的知识:领域模型 Continue PreTrain 时可以同步加入 SFT 数据,即 MIP,Multi-Task Instruction PreTraining。
4.Chat 模型和Base模型
Base 模型
- 全称:通常指基础预训练模型(Base Pre-trained Model)。
- 训练目标:通过海量无标注文本(如书籍、网页、论文等)进行预训练,核心目标是学习通用语言规律(语法、语义、世界知识等),不针对对话交互进行优化
Chat 模型
- 全称:通常指对话模型(Chat Model)。
- 训练目标:在 Base 模型基础上,通过「有监督微调(SFT)」和「人类反馈强化学习(RLHF)」优化,专门针对对话场景设计,目标是理解并遵循人类指令,生成符合交互逻辑的回复。
进行 SFT 操作的时候,基座模型选用 Chat 还是 Base:仅用 SFT 做领域模型时,资源有限就用 Chat 模型基础上训练,资源充足就在 Base 模型上训练(资源 = 数据 + 显卡)。资源充足时可以更好地拟合自己的数据,如果你只拥有小于 10k 数据,建议你选用 Chat 模型作为基座进行微调;如果你拥有 100k 的数据,建议你在 Base 模型上进行微调。
在 Chat 模型上进行 SFT 时,请一定遵循 Chat 模型原有的系统指令 & 数据输入格式。建议不采用全量参数训练,否则模型原始能力会遗忘较多。
领域模型微调领域评测集构建:领域评测集时必要内容,建议有两份,一份选择题形式自动评测、一份开放式形式人工评测。选择题形式可以自动评测,方便模型进行初筛;开放式形式人工评测比较浪费时间,可以用作精筛,并且任务形式更贴近真实场景。
5.如何训练自己的大模型
如果我现在做一个 sota 的中文 GPT 大模型,会分 2 步走:1. 基于中文文本数据在 LLaMA-65B 上二次预训练;2. 加 CoT 和 Instruction 数据,用 FT + LoRA SFT。
提炼下方法,一般分为两个阶段训练:
第一阶段:扩充领域词表,比如金融领域词表,在海量领域文档数据上二次训练 LLaMA 模型;
第二阶段:构造指令微调数据集,在第一阶段的预训练模型基础上做指令精调。还可以把指令微调数据集拼起来成文档格式放第一阶段里面增量预训练,让模型先理解下游任务信息。
当然,有低成本方案,因为我们有 LoRA 利器,第一阶段和第二阶段都可以用 LoRA 训练,如果不用 LoRA,就全参微调,大概 7B 模型需要 8 卡 A100,用了 LoRA 后,只需要单卡 3090 就可以了。
6.预训练和 SFT 操作有什么不同
下面使用一个具体的例子进行说明。
问题:描述计算机主板的功能 回答:计算机主板是计算机中的主要电路板。它是系统的支撑。
进行预训练的时候会把这句话连接起来,用前面的词来预测后面出现的词。在计算损失的时候,问句中的损失也会被计算进去。
进行 SFT 操作则会构建下面这样一条训练语料。
输入:描述计算机主板的功能 [BOS] 计算机主板是计算机中的主要电路板。它是系统的支撑。[EOS]
标签:[……][BOS] 计算机主板是计算机中的主要电路板。它是系统的支撑。[EOS]
其中 [BOS] 和 [EOS] 是一些特殊字符,在计算损失时,只计算答句的损失。在多轮对话中,也是一样的,所有的问句损失都会被忽略,而只计算答句的损失。
因此 SFT 的逻辑和原来的预训练过程是一致的,但是通过构造一些人工的高质量问答语料,可以高效地教会大模型问答的技巧。
7.Prompting
(1)为什么需要提示学习(Prompting)
在面对特定的下游任务时,如果进行 Full FineTuning(即对预训练模型中的所有参数都进行微调),太过低效;而如果采用固定预训练模型的某些层,只微调接近下游任务的那几层参数,又难以达到较好的效果。
(2)什么是提示学习(Prompting)
Prompt 提供上下文和任务相关信息,以帮助模型更好地理解要求,并生成正确的输出。
实例一:问答任务中,prompt 可能包含问题或话题的描述,以帮助模型生成正确的答案。
实例二:在情感分析任务中,让模型做情感分类任务的做法通常是在句子前面加入前缀 “该句子的情感是” 即可,通过这种方式,将情感分类任务转换为一个 “填空” 任务,在训练过程中,BERT 可以学习到这个前缀与句子情感之间的关联。例如,它可以学习到 “该句子的情感是积极的” 和 “该句子的情感是消极的” 之间的差异。
(3)提示学习(Prompting)有哪些方法
Prefix - tuning(前缀微调)
基本概念
Prefix - tuning 是一种轻量级的微调方法,其核心思想是在预训练模型的输入层之前,人为地插入一段连续的可训练向量,即 “前缀” 。这个前缀会参与到模型的整个计算过程中,引导模型生成符合特定任务需求的输出。在整个微调过程中,预训练模型的原始参数是被冻结的,只对前缀向量进行更新训练。实现过程
插入前缀向量:对于给定的输入序列x,假设前缀向量为p,模型的输入变为[p;x](这里 “;” 表示拼接操作)。例如在文本生成任务中,对于输入文本 “请描述一下春天”,会在前插入一段前缀向量。
训练前缀向量:在训练过程中,利用任务相关的标注数据,通过反向传播算法,只更新前缀向量p的参数,而预训练模型本身的参数保持不变。以情感分类任务为例,给定标注好的带有情感倾向(积极或消极)的文本数据,模型根据插入前缀后的输入进行预测,计算预测结果与真实标签之间的损失,再基于这个损失来更新前缀向量的参数,使得模型在后续遇到类似任务时,能根据前缀的引导做出更准确的预测。
优势
降低计算成本:由于只需要更新前缀向量的参数,相比全量参数微调(Full Fine - Tuning),极大地减少了需要训练的参数数量,降低了计算资源的需求和训练时间成本。
跨任务迁移性好:不同的任务可以通过设计不同的前缀向量来适配,且在切换任务时,无需重新训练整个模型的参数,只需要更新对应任务的前缀向量。
局限性
性能上限:虽然 Prefix - tuning 在很多任务上表现良好,但由于预训练模型的参数被冻结,其性能可能无法达到全量参数微调的上限 。
前缀设计挑战:需要针对不同的任务精心设计前缀的长度、初始化方式等,不合适的前缀设计可能影响模型的性能。
Prompt - tuning(提示微调)
基本概念
Prompt - tuning 也是一种微调预训练模型以适应下游任务的技术,它通过优化离散的提示(Prompt)或者可微的提示嵌入(Prompt Embedding),使得预训练模型能够更好地利用自身已学习到的知识来完成特定任务。与 Prefix - tuning 不同的是,Prompt - tuning 的实现方式更加灵活多样,可以是离散的文本提示(如在文本前添加一段自然语言描述),也可以是连续的可训练向量形式。实现过程
离散提示:在一些简单的任务中,可以直接使用自然语言构建离散的提示。比如在文本分类任务中,在输入文本前添加 “这段文本表达的情感是”,然后让模型预测填空内容(积极、消极等)。在训练过程中,通过调整模型的参数(可以是部分参数微调,也可以结合其他技术如 LoRA),使得模型能够根据提示和输入文本做出正确的分类。
连续提示嵌入:类似于 Prefix - tuning,通过在输入中加入可训练的连续向量作为提示嵌入。但 Prompt - tuning 在提示嵌入的设计和使用上更加灵活,它可以与其他微调技术结合使用,并且在提示嵌入的初始化和更新方式上有更多的选择。例如,可以基于预训练模型的词嵌入来初始化提示嵌入,然后在训练过程中根据任务需求进行更新。
优势
灵活性高:可以根据不同任务的特点和需求,选择不同形式的提示,无论是离散文本还是连续向量,都能找到合适的方式来引导模型。
利用先验知识:通过设计合适的提示,可以更好地引导预训练模型利用其在大规模数据上学习到的先验知识,从而在少量标注数据的情况下也能取得较好的性能。
局限性
提示工程复杂:设计有效的提示需要一定的专业知识和经验,不同的提示可能对模型性能产生巨大差异,需要进行大量的实验和优化。
难以大规模应用:在处理大规模任务和数据时,离散提示的构建和连续提示嵌入的优化都可能面临计算和管理上的挑战。
指示微调(Prompt-tuning)与 fine-tuning 区别是什么: 1.Fine-tuning 需要改变预训练阶段模型参数,可能带来灾难性遗忘问题。 2.指示微调(Prompt-tuning)不改变预训练阶段模型参数,而是通过微调寻找更好的连续 prompt,来引导已学习到的知识使用。
P - tuning
基本原理
P - tuning 是一种将离散提示(Prompt)参数化的方法。传统的离散提示是固定的自然语言文本,例如在情感分类任务中使用 “这句话的情感是 [MASK]”,其中 [MASK] 是需要模型预测填充的部分。而 P - tuning 将提示转换为连续的向量表示,使得提示可以在训练过程中进行优化。具体来说,它在预训练模型的输入层之前,引入了一系列可训练的连续向量,这些向量被称为 “软提示(Soft Prompt)”。实现方式
提示构建:对于一个给定的任务,先确定提示的结构,比如在文本分类任务中,在输入文本前插入软提示向量。假设输入文本为x,软提示向量为p,则实际输入到模型中的序列为[p;x](“;” 表示拼接操作)。
训练过程:在训练阶段,预训练模型的大部分参数被冻结,只对软提示向量进行更新。通过反向传播算法,根据任务的损失函数(如分类任务中的交叉熵损失)来调整软提示向量的参数,使得模型能够根据软提示的引导,更准确地完成任务。例如在命名实体识别任务中,软提示向量经过训练后,能引导模型更好地识别出文本中的人名、地名等实体。
优势
灵活性高:相较于固定的离散提示,软提示可以在训练中动态调整,能够更好地适应不同的任务需求。
降低计算成本:不需要更新预训练模型的全部参数,只需更新软提示向量,大大减少了训练所需的计算资源和时间。
局限性
性能瓶颈:由于预训练模型大部分参数被冻结,在一些复杂任务上,模型的表现可能会受到一定限制,无法充分发挥预训练模型的全部潜力。
P - tuning v2
改进背景
P - tuning v2 是对 P - tuning 的进一步改进。研究发现,在 P - tuning 中,当预训练模型的参数大部分被冻结时,模型在复杂任务上的表现不佳。P - tuning v2 旨在解决这个问题,使得模型在只更新少量参数的情况下,也能在复杂任务上取得接近全量参数微调的效果。核心改进点
更深层次的提示融合:P - tuning v2 不再仅仅将软提示向量添加到输入层,而是让软提示向量参与到预训练模型的多个隐藏层中。这样可以使软提示与预训练模型的内部表示更好地融合,增强模型对提示信息的利用能力。例如,在处理长文本生成任务时,软提示在多个隐藏层的参与,能让模型更准确地把握文本的语义和逻辑,生成更连贯、合理的文本。
更灵活的参数更新策略:P - tuning v2 不仅更新软提示向量的参数,还会对预训练模型中的一些关键组件(如注意力机制中的权重等)进行少量更新。这种策略在不显著增加计算成本的前提下,提高了模型对下游任务的适应性,使其在复杂任务上也能有较好的表现。
优势
优异的性能表现:在多种复杂的自然语言处理任务(如文本生成、复杂问答等)中,P - tuning v2 在只更新少量参数(相比全量参数微调)的情况下,能够取得接近甚至超过全量参数微调的效果。
通用性强:适用于多种不同类型的预训练语言模型,并且在不同规模的数据集上都能展现出良好的性能提升效果。
局限性
虽然相比 P - tuning 有了很大改进,但在面对极其复杂且数据量极大的任务时 ,与全量参数微调相比,仍然可能存在一定的性能差距,并且在提示向量和模型部分参数的联合优化过程中,需要仔细调整超参数以达到最佳效果。
8.LORA
(1)什么是 LoRA
介绍:通过低秩分解来模拟参数的改变量,从而以极小的参数量来实现大模型的间接训练。
(2) LoRA 的思路是什么
- 在原模型旁边增加一个旁路,通过低秩分解(先降维再升维)来模拟参数的更新量;
- 训练时,原模型固定,只训练降维矩阵 A 和升维矩阵 B;
- 推理时,可将 BA 加到原参数上,不引入额外的推理延迟;
- 初始化,A 采用高斯分布初始化,B 初始化为全 0,保证训练开始时旁路为 0 矩阵;
- 可插拔式的切换任务,当前任务 W0+B1A1,将 θW 部分减掉,换成 B2A2,即可实现任务切换;
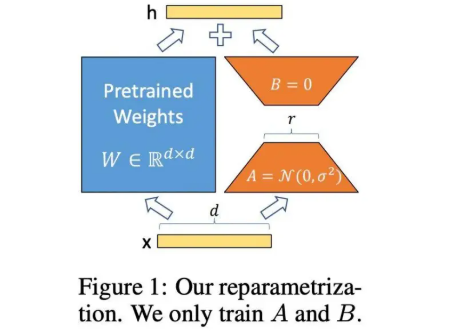
假设模型中某一权重矩阵为W∈Rd×k(d和k是矩阵维度,可能很大,比如d=k=5120)。
全量微调时,我们会直接更新W,即W′=W+ΔW,其中ΔW∈Rd×k是参数变化量(需要训练的矩阵)。
此时ΔW的参数量是d×k(例如万),这对大模型的所有层来说,总量依然巨大。
LoRA 通过低秩分解,将高维矩阵ΔW分解为两个低维矩阵的乘积:ΔW≈BA
其中,A∈Rr×k:输入侧的低秩矩阵(r是 “秩”,远小于d和k,通常取r=8,16,32)。
B∈Rd×r:输出侧的低秩矩阵。
此时,需要训练的参数是A和B的参数总和:d×r+r×k=r(d+k)。
当r=16、d=k=5120时,参数量为16×(5120+5120)=16×10240=163840(约 16 万),仅为原ΔW参数量的0.6%!
(3)LoRA 微调参数量怎么确定
LoRA 模型中可训练参数的结果数量取决于低秩更新矩阵的大小,其主要由 r 和原始权重矩阵的形状确定。实际使用过程中,通过选择不同的 lora_target 决定训练的参数量。
以 Llama 为例
--lora_target q_proj,k_proj,v_proj,o_proj,gate_proj,up_proj,down_proj
(4)Rank 如何选取
Rank 的取值效果上 Rank 在 4 - 8 之间最好,再高并没有效果提升。不过论文的实验是面向下游单一监督任务的,因此在指令微调上根据指令分布的广度,Rank 选择还是需要在 8 以上的取值进行测试。
(5)alpha 参数如何选取
alpha 其实是个缩放参数,本质和 learning rate 相同,所以为了简化默认让 alpha=rank,只调整 r,这样可以简化超参。
(6)LoRA 高效微调如何避免过拟合
减小 r 或增加数据集大小可以帮助减少过拟合,还可以尝试增加优化器的权重衰减率或 LoRA 层的 dropout 值。