评价指标FID/R Precision
1. FID(Fréchet Inception Distance)
用途:衡量生成数据和真实数据在整体分布上的相似度,可判断“生成内容是否真实”。
计算思路:
先把生成的动作序列(或视频)和真实的动作序列都经过一个预训练特征提取模型(类似 Inception 网络在图像里,动作里常用预训练的动作识别网络,比如 I3D 或者 MoViNet)。
把数据投影到特征空间,假设这些特征的分布接近高斯分布。
分别计算 真实分布 和 生成分布 的均值 μ、协方差 Σ。
使用 Fréchet 距离公式计算两个分布的差异:
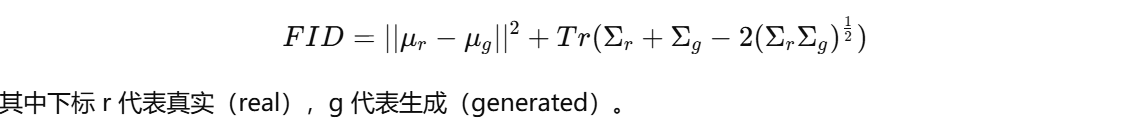
解释:
如果生成分布和真实分布完全一致,FID = 0。
FID 越小,说明生成动作在统计特性上更接近真实动作,看起来更“真实可信”。
但注意 FID 并不直接衡量“语义正确性”,只关注分布层面。比如:生成的动作确实像“人类动作”,但可能和输入文本描述没什么关系,FID 依旧可能很低。
Fréchet 距离
一般的 Fréchet 距离(Fréchet Distance)
在数学上,Fréchet 距离可以理解为:如果有两条曲线,它描述的是“一个人走在曲线 A 上,另一人走在曲线 B 上”,两个人都可以调整步伐快慢,但不能倒退。Fréchet 距离就是在最优走法下,这两人之间的最小可能最大距离。
但在 FID 里,我们其实用的是 Fréchet Inception Distance,它不是曲线距离,而是基于 高斯分布的 Fréchet 距离。
高斯分布情形下的 Fréchet 距离公式
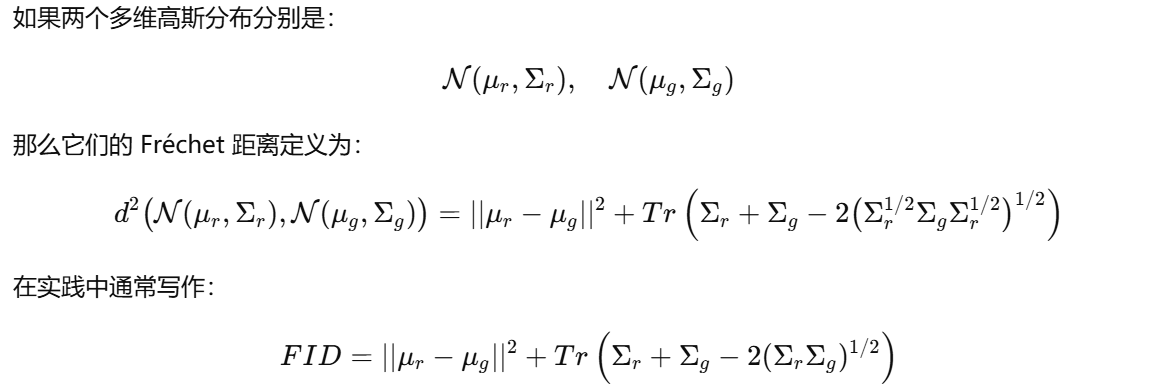

Tr 是 矩阵的迹(trace)




2. R Precision(Retrieval Precision)
用途:衡量生成动作是否和输入的文本描述相匹配,也就是“文本-动作对齐程度”。
计算思路:
对于一条生成的动作序列,准备一组文本候选:
其中 1 条是真实的文本描述(ground truth caption)。
其余若干条是干扰文本(negative samples)。
把动作和这些文本都映射到同一个特征空间(通常用 CLIP-like 的跨模态模型,或者在动作-文本上训练的 joint embedding)。
计算动作与所有候选文本的相似度。
看在前 k 个检索结果里,真实文本是否出现。
常见指标:
R@1(Recall at 1):真实文本是否排在第 1。
R@5:真实文本是否在前 5。
把这些结果平均后,就得到了 R Precision。
解释:
R Precision 高,说明模型不仅生成了“真实的动作”,而且和输入的文本语义契合度高。
举个例子:
文本:“一个人正在挥手”。
如果生成动作看起来像人在走路,FID 可能不差(动作确实像人类动作),但 R Precision 就很低(因为和文本不符)。
如果生成的确是“挥手”,就能拿到更高的 R Precision。
“把动作和文本映射到同一个特征空间”背后的工程做法,基本就是做一个“双塔(dual-encoder)的跨模态对齐”。一端是动作编码器,把一段骨架序列/SMPL 参数/3D 关节轨迹变成一个向量;另一端是文本编码器,把描述句子变成一个向量。两个向量被投到同一维度、同一度量(通常是余弦相似度)下,从而可以直接做匹配与检索。
首先是表示与编码路径。文本侧常见做法是用一个冻结或微调的 Transformer 文本编码器(例如 BERT/roberta 或 CLIP 的文本塔),取 [CLS] 或平均池化后的句向量;动作侧要先把原始序列规范化,例如去除根平移、统一朝向与帧率、对长度做截断/补齐与掩码。编码器可以用时序 Transformer、时空 GCN、或专为人体运动设计的 Motion-Transformer;对可变长序列一般用掩码注意力,再做时间维的池化(mean/max/attention pool)得到一个全局向量。两侧各接一个小的线性投影头,把维度投到同一个 d(例如 d=512),并做 L2 归一化,这样相似度就等于余弦相似度。
训练范式本质上是对比学习,和 CLIP 一样的对齐法。准备一批配对样本 (mi,ti)——第 i 段动作与其真实文本描述。前向后得到批内所有相似度矩阵
损失用对称 InfoNCE:一项让“每个动作更像自己的文本而不像别人的文本”,另一项反向亦然。公式写成:
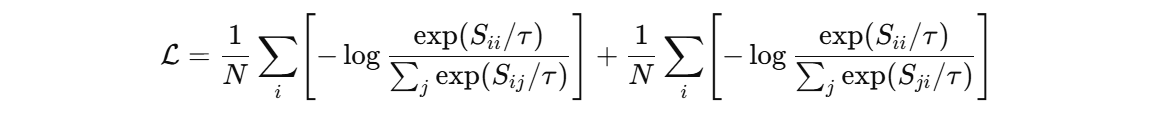
这里 τ 是温度,批内样本天然充当负样本;如果想更强,可以加跨批内存库或“难负样本挖掘”。为了让动作编码器更懂“语义片段”,很多工作会用层级汇聚(片段-句子-段落)或多粒度监督(动作标签+文本描述一起学)。
评测与 R Precision 的落地非常直接。训练好之后,冻结两塔。对一个生成的动作 clip,先用动作编码器得到向量,再把“1 条真描述 + 若干干扰句子”都过文本编码器,算余弦相似度并排序。若真描述在前 k 名内,就记作一次命中,从而得到 R@1/R@5 等。若同一段动作有多条参考描述,可以取这几条的最大相似度或做平均,再参与排名,避免因措辞差异被惩罚。为了稳健,很多人会先用 dual-encoder 做全量快速检索,再用一个交叉编码器(cross-encoder,把文本和动作 token 放在同一模型里做跨模态注意力)对前几十个候选重排;但标准 R Precision 通常只用 dual-encoder 的排名,保证可复现和高效。