Java-面试八股文-Mysql篇
MySQL篇
1、Select 语句完整的执行顺序 难度系数:⭐
📌 SQL SELECT 语句书写顺序(开发者写的顺序)
SELECT ...
FROM ...
JOIN ...
WHERE ...
GROUP BY ...
HAVING ...
ORDER BY ...
LIMIT ...
📌 实际执行顺序(数据库执行引擎的逻辑顺序)
-
FROM
- 确定查询的数据源(表、视图),并执行
JOIN。 - 如果有别名,此时就已经起作用了。
- 确定查询的数据源(表、视图),并执行
-
ON
- 在
JOIN时,先对关联条件进行过滤。
- 在
-
JOIN
- 执行表连接,生成一个临时表。
-
WHERE
- 对临时表进行行过滤,去掉不符合条件的数据。
-
GROUP BY
- 对过滤后的结果分组。
-
HAVING
- 对分组后的结果进一步过滤。
- 注意:
HAVING针对分组结果,而WHERE针对原始行。
-
SELECT
- 选择要输出的列(可以包含聚合函数)。
-
DISTINCT
- 去重(如果有的话)。
-
ORDER BY
- 对结果排序。
-
LIMIT / OFFSET
- 最终取出指定范围的数据。
📊 举个例子
SELECT deptno, AVG(sal) AS avg_sal
FROM emp
WHERE sal > 1000
GROUP BY deptno
HAVING AVG(sal) > 2000
ORDER BY avg_sal DESC
LIMIT 5;
👉 执行顺序:
- FROM emp → 取出员工表
- WHERE sal > 1000 → 过滤薪资小于 1000 的员工
- GROUP BY deptno → 按部门分组
- HAVING AVG(sal) > 2000 → 过滤掉平均薪资 ≤ 2000 的部门
- SELECT deptno, AVG(sal) → 选择部门号和平均工资
- ORDER BY avg_sal DESC → 按平均工资倒序
- LIMIT 5 → 取前 5 条
2、MySQL事务 难度系数:⭐⭐
1️⃣ 事务的基本要素(ACID)
事务是数据库操作的最小逻辑单元,具备 ACID 四大特性:
-
原子性(Atomicity)
- 事务中的所有操作要么全部成功,要么全部失败。
- 通过 回滚(Rollback) 实现。
-
一致性(Consistency)
- 事务执行前后,数据库必须保持一致性约束。
- 比如转账:A 给 B 转账,A 减少的钱数必须等于 B 增加的钱数。
-
隔离性(Isolation)
- 多个事务并发执行时,彼此互不干扰。
- 通过 锁机制 + 隔离级别 实现。
-
持久性(Durability)
- 事务提交后,对数据库的修改是永久性的,即使系统宕机也能恢复。
- 依赖 redo log(重做日志) 实现。
2️⃣ MySQL 的事务隔离级别
MySQL(InnoDB 引擎)提供了 4 种事务隔离级别(从低到高):
-
读未提交(Read Uncommitted)
- 事务可以读取到其他事务尚未提交的数据。
- 问题:脏读、不可重复读、幻读。
-
读已提交(Read Committed)
- 只能读取其他事务已经提交的数据。
- 避免了 脏读。
- 但仍可能发生 不可重复读、幻读。
- 👉 Oracle 默认隔离级别。
-
可重复读(Repeatable Read)(MySQL 默认)
- 一个事务中多次读取同一条数据,结果一致(避免 不可重复读)。
- 仍可能出现 幻读(比如多了一行数据)。
- 👉 MySQL 的 InnoDB 使用 MVCC + 间隙锁 解决了幻读问题。
-
串行化(Serializable)
- 强制事务串行执行,避免所有并发问题。
- 缺点:效率低,性能差。
3️⃣ 事务的并发问题
事务并发执行时,会出现以下典型问题:
-
脏读(Dirty Read)
- 事务 A 读到了事务 B 尚未提交的数据。
- 如果 B 回滚,则 A 读到的是无效数据。
-
不可重复读(Non-repeatable Read)
- 事务 A 在同一事务中两次读取同一数据,结果不同(因为事务 B 在中间修改并提交了)。
-
幻读(Phantom Read)
- 事务 A 按条件查询一批数据,事务 B 在中间插入或删除了符合条件的新数据,导致 A 再次查询时,结果集的行数不同。
4️⃣ 总结对照表
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 性能 |
|---|---|---|---|---|
| 读未提交 (RU) | ✅ | ✅ | ✅ | 高 |
| 读已提交 (RC) | ❌ | ✅ | ✅ | 较高 |
| 可重复读 (RR) | ❌ | ❌ | ✅(InnoDB 可避免) | 中 |
| 串行化 (Serializable) | ❌ | ❌ | ❌ | 低 |
3、MyISAM和InnoDB的区别 难度系数:⭐
| 对比项 | MyISAM | InnoDB |
|---|---|---|
| 事务支持 | ❌ 不支持事务 | ✅ 支持事务(ACID) |
| 外键支持 | ❌ 不支持外键 | ✅ 支持外键 |
| 锁机制 | 表级锁(table-level lock),并发性能差 | 行级锁(row-level lock),并发性能高 |
| 存储方式 | 数据(.MYD)和索引(.MYI)分开存储 | 数据和索引存在一个表空间(.ibd)里 |
| 主键 | 允许没有主键 | 必须有主键(若未指定,会自动生成一个隐藏主键) |
| 索引结构 | B+Tree 索引(非聚簇),索引和数据分离 | B+Tree 聚簇索引(主键索引和数据存放在一起) |
| 全文索引 | ✅ MySQL 5.6 之前只有 MyISAM 支持 | ✅ 5.6 之后 InnoDB 也支持 |
| 崩溃恢复 | ❌ 数据容易损坏,恢复困难 | ✅ 通过 redo log、undo log 进行崩溃恢复 |
| 存储空间 | 占用空间小,查询速度快 | 占用空间相对大 |
| 适用场景 | 读多写少、不要求事务(如日志、报表) | 写操作多、需要事务安全(如订单、银行系统) |
4、悲观锁和乐观锁的怎么实现 难度系数:⭐⭐
📌 1. 悲观锁(Pessimistic Lock)
-
思想:认为并发冲突概率很大,每次操作都加锁,保证同一时间只能有一个线程操作数据。
-
实现方式:
-
数据库层面(常见做法)
-
使用
SELECT ... FOR UPDATE:BEGIN; SELECT stock FROM product WHERE id = 1 FOR UPDATE; -- 加锁后,其他事务不能修改这行数据 UPDATE product SET stock = stock - 1 WHERE id = 1; COMMIT;👉 这里会对 查询到的记录加排他锁。
-
-
Java 代码层面
- 使用
synchronized、ReentrantLock等机制控制线程并发。
- 使用
-
-
优点:保证安全,适合冲突严重的场景。
-
缺点:性能差,并发度低,可能产生死锁。
📌 2. 乐观锁(Optimistic Lock)
-
思想:认为并发冲突很少,不加锁,通过 版本号 / 时间戳机制 来保证数据一致性。
-
实现方式:
-
版本号机制(最常见)
在表里加version字段:-- 查询时取出 version SELECT stock, version FROM product WHERE id = 1;-- 更新时检查 version 是否一致 UPDATE product SET stock = stock - 1, version = version + 1 WHERE id = 1 AND version = 10;👉 如果
version不一致,说明被别人修改过,更新失败,需要重试。 -
时间戳机制
类似版本号,比较最后修改时间来决定是否更新。
-
-
优点:无锁机制,性能高,适合 读多写少、冲突少 的场景。
-
缺点:一旦冲突多,需要频繁重试,性能会下降。
📊 3. 区别总结
| 特性 | 悲观锁 | 乐观锁 |
|---|---|---|
| 思想 | 假设一定会冲突 | 假设大部分不会冲突 |
| 实现 | for update、数据库排他锁、Java同步锁 | 版本号 / 时间戳机制 |
| 并发性能 | 低 | 高 |
| 适用场景 | 写多、冲突频繁 | 读多写少、冲突少 |
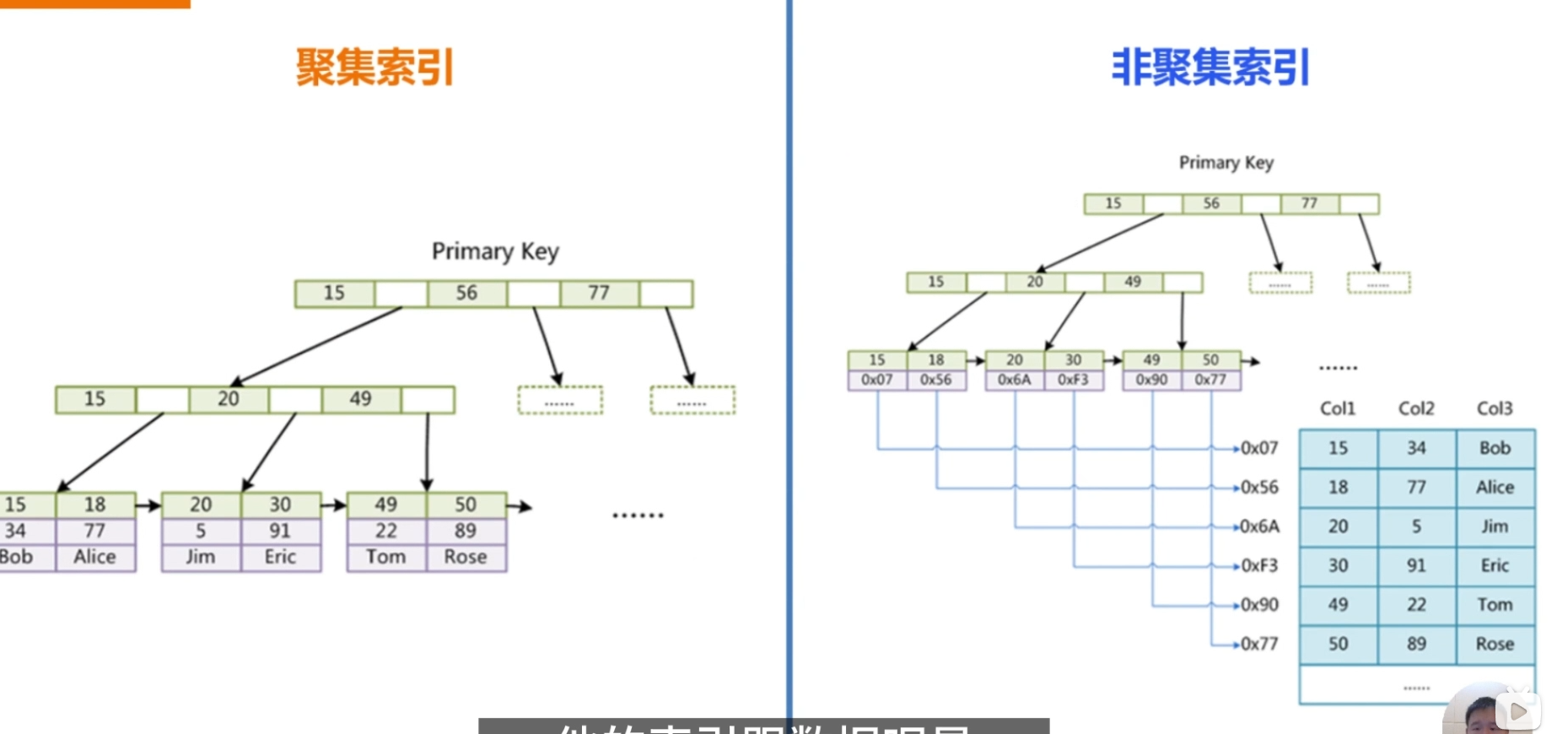
5、聚簇索引与非聚簇索引区别 难度系数:⭐⭐
1️⃣ 聚簇索引(Clustered Index)
-
定义:索引和数据存放在一起,索引的叶子节点就是数据。
-
特点:
- 一张表只能有一个聚簇索引(因为数据物理存储只能有一种顺序)。
- InnoDB 默认主键就是聚簇索引。
- 如果没有定义主键,InnoDB 会选择一个唯一的非空索引作为聚簇索引;如果没有,则自动生成一个隐藏的
rowid。
-
优点:
- 通过主键查询效率高(不用回表)。
- 范围查询效率高,因为其数据是按照大小排列的
-
缺点:
- 插入速度依赖插入顺序(最好按主键顺序插入)。
- 更新主键代价大(会导致数据移动)。
2️⃣ 非聚簇索引(Non-Clustered Index,也叫二级索引 / 辅助索引)
-
定义:索引和数据分开存储,索引的叶子节点存储的是 主键值 或 行地址。
-
特点:
- 一张表可以有多个非聚簇索引。
- InnoDB 的二级索引叶子节点存放的是 主键值(不是物理地址)。
- 查询时可能需要 回表(先通过非聚簇索引找到主键,再根据主键去聚簇索引查数据)。
-
优点:
- 可以为多列建立多个辅助索引,加快查询速度。
- 不影响数据的物理存储顺序。
-
缺点:
- 查询可能需要回表,效率略低。
- 占用额外的存储空间。
3️⃣ 直观对比
| 对比项 | 聚簇索引 | 非聚簇索引 |
|---|---|---|
| 数据存储位置 | 索引的叶子节点就是数据行 | 索引的叶子节点存储主键或行地址 |
| 一张表数量 | 只能有一个 | 可以有多个 |
| 查询效率 | 主键查询快(无需回表) | 需要回表(除覆盖索引情况) |
| 存储顺序 | 按主键顺序存储 | 与数据存储无关 |
| 更新代价 | 更新主键开销大 | 较小 |
4️⃣ 举个例子
假设有 user 表:
CREATE TABLE user (id INT PRIMARY KEY,name VARCHAR(50),age INT,INDEX idx_name (name)
) ENGINE=InnoDB;
- 聚簇索引:
id(主键),叶子节点直接存放整行数据。 - 非聚簇索引:
idx_name(name 列),叶子节点存放的是id,查数据时需要回表。
6、什么情况下mysql会索引失效 难度系数:⭐
📌 常见索引失效的情况
-
条件中对索引列做了运算或函数
SELECT * FROM user WHERE YEAR(create_time) = 2024; -- ❌ create_time 上的索引失效,因为用了函数✅ 解决:改写为区间查询
SELECT * FROM user WHERE create_time >= '2024-01-01' AND create_time < '2025-01-01';
-
字符串没有加引号(类型转换导致全表扫描)
SELECT * FROM user WHERE phone = 13888888888; -- ❌ phone 是 VARCHAR,MySQL 会进行隐式类型转换,索引失效✅ 改为:
SELECT * FROM user WHERE phone = '13888888888';
-
使用
!=或<>、NOT IN、NOT LIKE- 索引一般无法利用。
SELECT * FROM user WHERE age != 18;
-
模糊查询以通配符开头
SELECT * FROM user WHERE name LIKE '%abc'; -- ❌ 索引失效 SELECT * FROM user WHERE name LIKE 'abc%'; -- ✅ 索引生效
-
在索引列上使用
OR(如果其中一列没有索引)SELECT * FROM user WHERE id = 1 OR name = 'Tom'; -- ❌ 如果 name 没有索引,则全表扫描
-
联合索引不满足最左前缀原则
CREATE INDEX idx_user_name_age ON user(name, age);- ✅
WHERE name = 'Tom'(用到索引) - ✅
WHERE name = 'Tom' AND age = 20(用到索引) - ❌
WHERE age = 20(没用到索引,违反最左匹配)
- ✅
-
索引字段参与隐式类型转换
SELECT * FROM user WHERE id = '1001'; -- ❌ id 是 INT,但用了字符串,会导致索引失效
-
范围查询影响后续索引列的使用
CREATE INDEX idx_user_name_age ON user(name, age); SELECT * FROM user WHERE name > 'Tom' AND age = 20; -- ❌ name 范围查询后,age 索引失效
-
数据区分度太低(索引选择性差)
- 比如
gender(只有 M/F),即使有索引,也可能全表扫描,因为优化器判断走索引不划算。
- 比如
- IS NULL / IS NOT NULL 使用不当
IS NULL有时能用索引,IS NOT NULL基本不用索引。
📊 总结口诀
- 函数运算要避免,隐式转换要小心
- 不等、OR、前模糊,索引基本挂掉
- 联合索引最左前缀,范围之后不再用
- 区分度低索引没用,优化器说了算
7、B+tree 与 B-tree区别 难度系数:⭐⭐
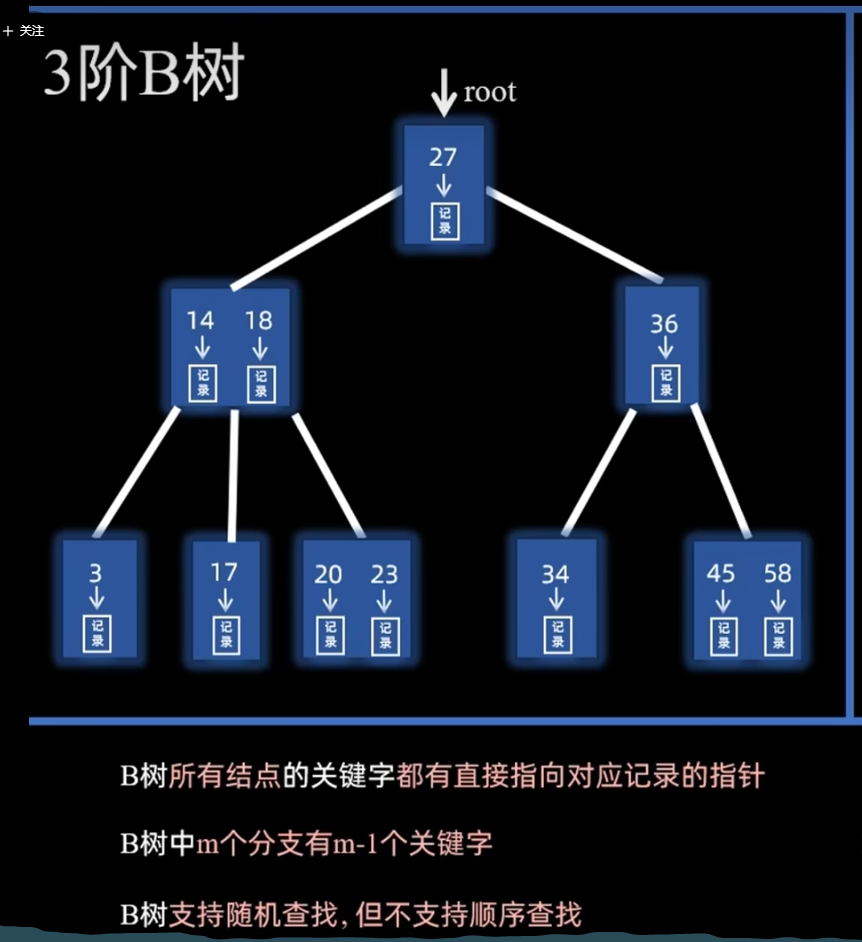
📌 1. B-Tree(多路平衡查找树)
- 每个节点存储 key 和数据(data)。
- 叶子节点和非叶子节点都能存储数据。
- 查询时:可能在非叶子节点就找到数据,不一定要到叶子节点。
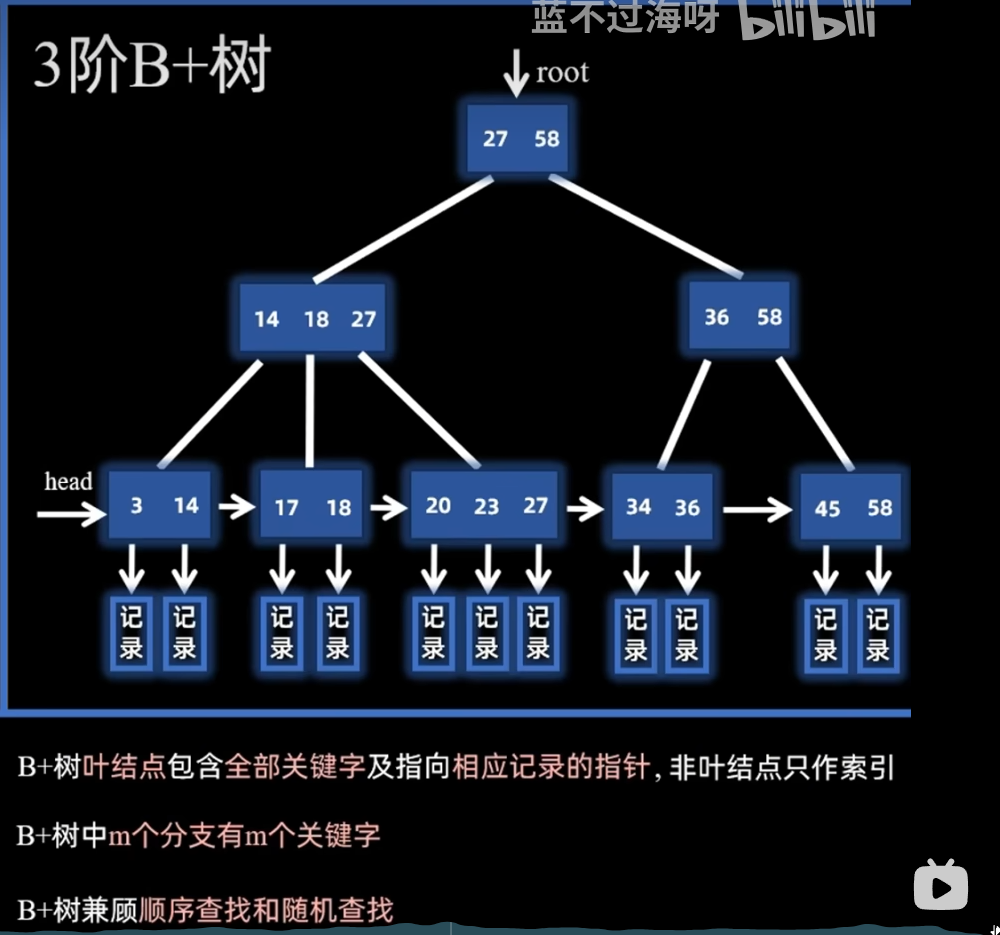
📌 2. B+Tree(B-Tree 的变种,MySQL 默认索引结构)
- 非叶子节点只存储 key,不存储数据。
- 所有数据存放在叶子节点,且叶子节点之间用 链表相连。
- 查询时:必须到叶子节点才能取到数据。
📊 3. 区别总结表
| 对比项 | B-Tree | B+Tree |
|---|---|---|
| 数据存放 | 索引节点和叶子节点都存数据 | 只有叶子节点存数据,非叶子节点只存键值 |
| 磁盘读写 | 数据可能分散在各层节点 | 数据都在叶子节点,非叶子节点更小,可放更多 key,减少磁盘 IO |
| 查询效率 | 查询可能在中间节点结束,性能不稳定 | 所有查询都到叶子节点,查询路径稳定 |
| 范围查询 | 不方便,需要中序遍历 | 叶子节点有链表,范围查询高效 |
| 适用场景 | 适合内存索引(数据量小) | 适合数据库、文件系统(磁盘存储) |
📌 4. 为什么 MySQL/InnoDB 选择 B+Tree?
-
磁盘 IO 更少
- 非叶子节点只存 key,单个节点能容纳更多索引值,树的高度更低,减少磁盘访问次数。
- MySQL 一次查询一般只需 2~3 次磁盘 IO。
-
范围查询更高效
- B+Tree 的叶子节点有链表结构,扫描范围数据时可以顺序遍历,而 B-Tree 需要复杂的中序遍历。
-
查询性能稳定
- B-Tree 查询可能停在中间节点,而 B+Tree 必须到叶子节点,查询路径一致,性能更稳定。
✅ 总结口诀:
- B-Tree:索引+数据混合,查找可能中途结束
- B+Tree:索引和数据分离,叶子节点链表,范围查询快,IO 更少
9、如何处理慢查询 难度系数:⭐⭐
一、慢查询优化思路
慢查询主要原因:全表扫描、索引缺失、锁等待、数据量大。处理思路:
1. 优化 SQL
- 避免
SELECT *,只查询需要字段 - 避免子查询,可考虑用 JOIN 或临时表
- 避免复杂函数在 WHERE 条件中,例如
WHERE YEAR(date)=2025→ 可用date BETWEEN '2025-01-01' AND '2025-12-31'
2. 建立索引
- 常用字段建立索引,如
WHERE条件字段、排序字段、连接字段 - 注意索引选择性,不要盲目建立索引
- 查看执行计划:
EXPLAIN SELECT ...;

如果一条SQL执行很慢,我们通常会使用MySQL的EXPLAIN命令来分析这条SQL的执行情况。通过key和key_len可以检查是否命中了索引,如果已经添加了索引,也可以判断索引是否有效。通过type字段可以查看SQL是否有优化空间,比如是否存在全索引扫描或全表扫描。通过extra建议可以判断是否出现回表情况,如果出现,可以尝试添加索引或修改返回字段来优化。
- 确认查询走了索引
3. 表结构优化
- 垂直拆分(字段多 → 拆表)
- 水平拆分(行数多 → 分表/分区)
- 避免 BLOB/TEXT 大字段频繁查询
4. 缓存
- 对热点数据使用 Redis/Memcached 缓存
- 避免重复计算复杂查询
5. 配置优化
- 调整 InnoDB 缓冲池:
SHOW VARIABLES LIKE 'innodb_buffer_pool_size';
- 增加连接数或慢查询阈值,视业务需求
二、监控与验证
- 优化前后对比:
SHOW PROFILES;
- MySQL 5.7+ 可使用
performance_schema查看详细 SQL 执行时间
- 持续监控:
- 定期分析慢查询日志
- 使用监控工具(如 Grafana + Prometheus)跟踪 SQL 响应时间
💡 总结
- 开启慢查询日志并收集 SQL
- 分析慢查询日志定位耗时 SQL
- 优化 SQL、建立索引、优化表结构或缓存
- 调整配置,持续监控
10、数据库分表操作 难度系数:⭐
一、为什么要分表
当单表数据量过大时,会导致:
- 查询慢(全表扫描耗时高)
- 写入压力大(锁竞争、事务冲突)
- 备份恢复困难
解决方法之一就是 分表(horizontal 或 vertical)。
二、分表策略
1. 水平分表(Horizontal Sharding)
-
概念:按行拆分,把一张大表拆成多张小表,字段相同。
-
常用规则:
-
按范围分表
user_0: id 1~10000 user_1: id 10001~20000 -
按哈希分表
表名 = user_{id % 4} # 4 张表
-
-
特点:适合写入量大、查询条件可以定位到单表的场景。
2. 垂直分表(Vertical Partitioning)
-
概念:按字段拆分,把表中的列拆到不同表中。
-
示例:
user_basic(id, name, age) user_detail(id, address, phone, avatar) -
特点:减少单表宽表列数,优化查询、降低存储压力。
3. 分库分表
- 在分表基础上进一步将表拆到不同库上(适用于海量数据)。
三、数据库分表操作示例
1. 创建分表
水平分表示例:
CREATE TABLE user_0 (id BIGINT PRIMARY KEY,name VARCHAR(50),age INT
);CREATE TABLE user_1 LIKE user_0; -- 复制结构
垂直分表示例:
CREATE TABLE user_basic (id BIGINT PRIMARY KEY,name VARCHAR(50),age INT
);CREATE TABLE user_detail (id BIGINT PRIMARY KEY,address VARCHAR(100),phone VARCHAR(20),avatar VARCHAR(200)
);
2. 插入数据
水平分表
-- 假设用 id % 2 决定表
INSERT INTO user_0 (id, name, age) VALUES (1, 'Tom', 25);
INSERT INTO user_1 (id, name, age) VALUES (2, 'Jerry', 22);
垂直分表
INSERT INTO user_basic (id, name, age) VALUES (1, 'Tom', 25);
INSERT INTO user_detail (id, address, phone, avatar) VALUES (1, 'Tokyo', '12345', '/avatar/1.png');
3. 查询数据
- 水平分表:需根据规则查询
SELECT * FROM user_0 WHERE id = 1;
- 垂直分表:使用 JOIN 查询
SELECT b.id, b.name, b.age, d.address
FROM user_basic b
JOIN user_detail d ON b.id = d.id
WHERE b.id = 1;
四、注意事项
- 应用层需要知道分表规则,动态选择表。
- 水平分表最好有分表键(如 id)定位数据,避免全表扫描。
- 垂直分表不要拆太细,否则频繁 JOIN 反而影响性能。
💡 总结
- 水平分表 → 拆行
- 垂直分表 → 拆列
- 分表操作后,查询需要结合规则或 JOIN
11、什么叫覆盖索引?
在 MySQL 里,覆盖索引(Covering Index) 指的是:
👉 查询所需要的数据全部在索引里就能拿到,而不用再回表(访问数据页)。
📌 举个例子
假设有一张用户表:
CREATE TABLE user (id INT PRIMARY KEY,name VARCHAR(50),age INT,email VARCHAR(100),INDEX idx_name_age (name, age)
);
1. 覆盖索引的情况
SELECT name, age
FROM user
WHERE name = 'Tom';
- 查询条件:
name='Tom' - 需要返回的字段:
name, age - 这两个字段 都在
idx_name_age索引里
✅ 所以直接从索引就能拿到结果,不需要回表。
这就是 覆盖索引。
2. 非覆盖索引的情况
SELECT name, age, email
FROM user
WHERE name = 'Tom';
- 查询条件:
name='Tom' - 需要返回的字段:
name, age, email email不在idx_name_age索引中
❌ 所以 MySQL 需要先通过索引找到对应的主键,再去表数据页查出email→ 这个过程叫 回表。
📌 特点
- 效率更高:减少磁盘 I/O,因为不需要回表。
- 常用场景:日志查询、报表统计等 只查索引字段 的场景。
📌 怎么判断是否用到覆盖索引?
用 EXPLAIN 看执行计划,如果 Extra 中有:
Using index
说明走了覆盖索引(只用索引就完成查询)。
如果出现:
Using where; Using index
说明虽然用索引了,但还需要过滤条件。
12、MySQL超大分页怎么处理?
📌 为什么超大分页慢?
- MySQL 的分页是先扫描出 offset + limit 这么多行,再丢掉前面的 offset 行,只返回 limit 行。
- 当 offset 很大时(例如百万级),会造成 大量无效扫描。
- 如果还要回表,那就更慢。
📌 常见优化方案
延迟关联(最常用)
通过覆盖索引先定位 主键 id,然后再回表取数据。
例子:
-- 大表分页,先用索引获取 id 列(覆盖索引,不回表)
SELECT id
FROM orders
WHERE create_time >= '2024-01-01'
ORDER BY create_time
LIMIT 1000000, 10;-- 再用 id 去回表拿需要的其他字段
SELECT o.*
FROM orders o
JOIN (SELECT id FROM orders WHERE create_time >= '2024-01-01' ORDER BY create_time LIMIT 1000000, 10
) t ON o.id = t.id;
✅ 优点:前半部分只扫描索引(很小),大大减少 I/O。
✅ 这是 覆盖索引 + 子查询 的典型用法。
13、索引创建原则有哪些?
-
针对数据量较大、且查询比较频繁的表建立索引。
单表超过 10 万数据(增加用户体验)。
-
针对常作为查询条件(WHERE)、排序(ORDER BY)、分组(GROUP BY)操作的字段建立索引。
-
尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高。
-
如果是字符串类型的字段,字段的长度较长,可以针对字段的特点,建立前缀索引。
-
尽量使用联合索引,减少单列索引。查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率。
-
要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率。
-
如果索引列不能存储 NULL 值,请在创建表时使用 NOT NULL 约束它。当优化器知道每列是否包含 NULL 值时,它可以更好地确定哪个索引最有效地用于查询。
14、谈谈你对sql优化的经验

15、mysql中redolog和undulog是什么用的,解释一下?
在 MySQL(尤其是 InnoDB 存储引擎)里,Redo Log 和 Undo Log 是保证事务 ACID 特性的两个关键日志机制,但它们的作用完全不同:
1. Redo Log(重做日志)
👉 主要用于保证 持久性(Durability)。
-
作用:
在事务提交时,InnoDB 会先把修改写入 redo log,再异步写入磁盘上的数据文件。即使数据库崩溃,重启后可以根据 redo log 把尚未刷入磁盘的数据恢复过来。 -
特点:
- 记录的是 物理级别的页修改(某个数据页上的哪个偏移量被修改成了什么值)。
- 解决的是 “已提交事务的数据丢失” 的问题。
- 采用循环写的方式(固定大小,写满后覆盖旧日志)。
-
流程(WAL - Write Ahead Logging):
- 事务执行时,修改缓存在内存(Buffer Pool);
- 同时记录修改到 redo log buffer;
- 事务提交时,先把 redo log buffer 持久化到磁盘;
- 后续后台线程(如 checkpoint)再把 Buffer Pool 的脏页写入数据文件。
2. Undo Log(回滚日志)
👉 主要用于保证 原子性(Atomicity)和一致性(Consistency)。
-
作用:
- 事务回滚:当事务失败或用户执行 ROLLBACK 时,根据 undo log 把数据恢复到修改前的样子。
- 多版本并发控制(MVCC):在事务隔离级别为 READ COMMITTED / REPEATABLE READ 时,undo log 中保存了旧版本数据,其他事务可以通过它读到事务修改前的快照。
-
特点:
- 记录的是 逻辑操作(反向操作)。
例如:UPDATE t SET age=20 WHERE id=1,undo log 会记录一条“把 id=1 的 age 改回原值(假设是18)”的操作。 - 在事务回滚时执行这些反向操作即可。
- 记录的是 逻辑操作(反向操作)。
-
存储位置:
Undo log 存放在undo tablespace里(以前在 ibdata 文件中,MySQL 8.0 支持独立的 undo 表空间)。
3. 二者的区别总结
| 特性 | Redo Log | Undo Log |
|---|---|---|
| 主要目的 | 保证 持久性 | 保证 原子性 + MVCC |
| 记录内容 | 物理日志:页修改后的值 | 逻辑日志:如何撤销操作 |
| 使用时机 | 崩溃恢复(Crash Recovery) | 事务回滚、快照读 |
| 方向 | 重做已完成的操作 | 撤销未完成的操作 |
| 存储位置 | InnoDB 日志文件(ib_logfile) | Undo 表空间(undo tablespace) |
✅ 简单记忆:
- Redo Log:事务提交后,万一宕机,“重做” 事务,让结果不丢。
- Undo Log:事务失败或回滚时,“撤销” 事务,让结果恢复。
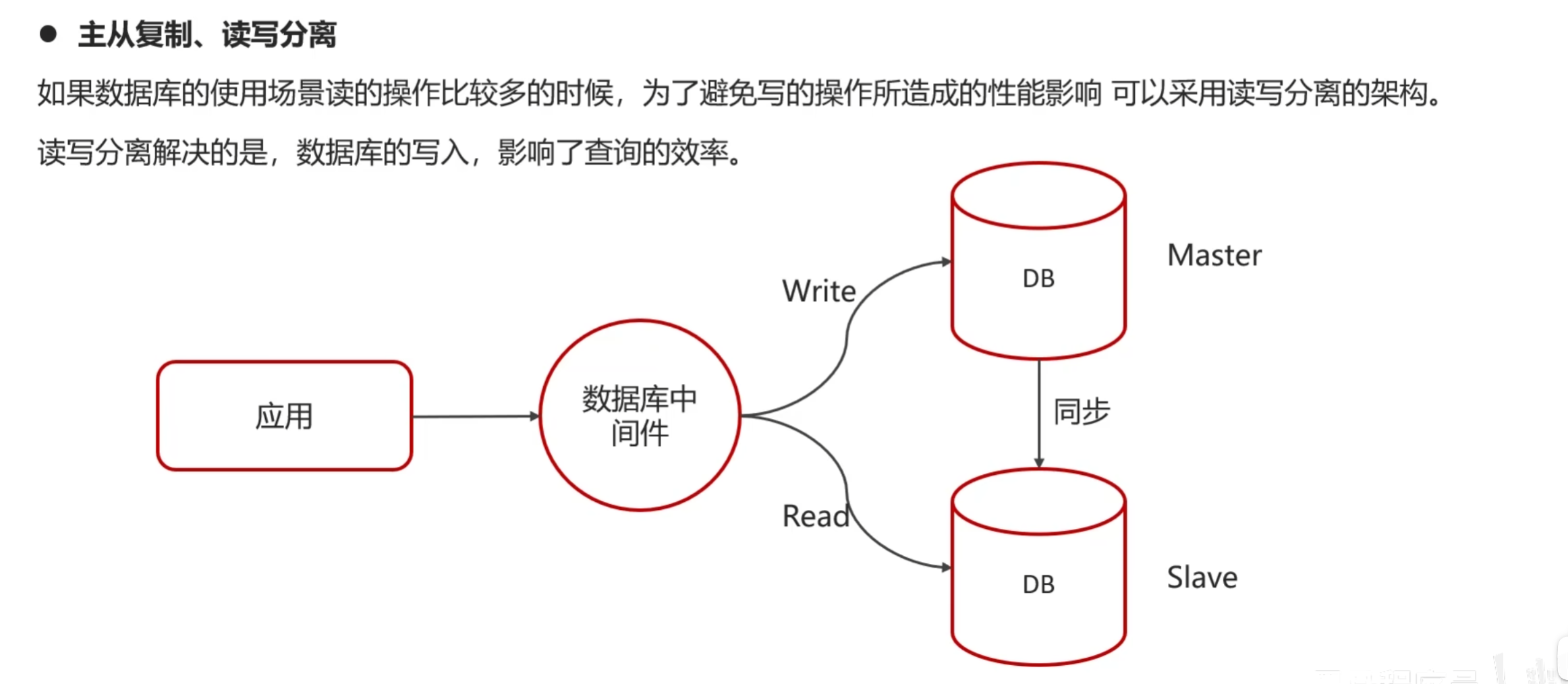
16、MySQL 的主从同步的原理流程
MySQL 的 主从同步(Replication)是高可用与读写分离的核心机制,主要基于 binlog(二进制日志) 来实现。原理大致是:主库把数据更改记录到 binlog,从库通过 IO 线程和 SQL 线程读取并重放这些日志,从而保持和主库数据一致。
可以分为 3 个阶段(经典的 异步复制 模式):
1. 主库(Master)写入 Binlog
-
当主库执行一条事务性 SQL(比如
INSERT/UPDATE/DELETE)时:- 在事务提交时,先写入 binlog(二进制日志);
- 再提交事务,返回客户端成功。
-
binlog 记录的是逻辑操作(如“在 t 表插入一行数据”)。
2. 从库(Slave)I/O 线程拉取 Binlog
- 从库会启动一个 I/O 线程,连接主库;
- 主库会为每个从库分配一个 Binlog Dump 线程,不断把主库 binlog 里的更新事件发送给从库;
- 从库收到后写入本地的 relay log(中继日志)。
3. 从库(Slave)SQL 线程重放 Relay Log
- 从库的 SQL 线程 读取 relay log;
- 将其中的逻辑操作(binlog event)转化为真正的 SQL 执行,从而更新从库的数据,保持与主库一致。
⚖️ 总结
| 阶段 | 组件 | 功能 |
|---|---|---|
| 主库写日志 | Binlog | 记录所有更新事件 |
| 传输日志 | Binlog Dump 线程 + 从库 I/O 线程 | 把主库 binlog 复制到从库 relay log |
| 重放日志 | 从库 SQL 线程 | 执行 relay log,更新从库数据 |
17、MySQL分库操作怎么实现的?
分库是指:当单个数据库的存储、计算能力达到瓶颈时,把数据按照一定的规则拆分到多个数据库实例中,以达到 扩展性能、提高并发、减轻单库压力 的目的。
🚀 MySQL 分库的实现方式
1. 垂直分库(Vertical Partitioning)
👉 按照 业务模块 拆分数据库。
-
做法:
-
把不同业务表放到不同数据库里,比如:
- 用户库(user_db) → 存用户信息表
- 订单库(order_db) → 存订单表
- 支付库(pay_db) → 存支付表
-
-
优点:
- 业务清晰,模块间耦合度低。
- 容易实施,改动成本相对较小。
-
缺点:
- 单库内的数据量依旧可能过大(如订单表),需要配合水平分库。
2. 水平分库(Horizontal Sharding)
👉 按照 数据规则 拆分,把同一张表的数据分布到多个数据库。
-
做法:
比如订单表数据太大,可以按 user_id 取模 分库:- user_id % 2 = 0 → 存 order_db_0
- user_id % 2 = 1 → 存 order_db_1
-
优点:
- 单库数据量减小,性能提升明显。
-
缺点:
- 查询可能需要跨库(如统计总订单数)。
- 分布式事务、全局主键生成、分页查询等需要额外处理。
3. 分库后的关键问题 & 解决方案
分库不是简单“复制粘贴”,需要解决以下问题:
-
数据路由
-
客户端执行 SQL 时,如何知道该去哪个库?
-
解决方案:
- 在应用层引入中间件(如 Sharding-JDBC、MyCAT)。
- 按业务规则(哈希、范围、时间)路由。
-
-
分布式事务
-
一个业务操作涉及多个库怎么办?
-
解决方案:
- 避免跨库事务(尽量按业务归属划分)。
- 使用分布式事务协调器(如 Seata、XA 协议、TCC 事务)。
-
-
全局唯一主键
-
不同库的自增 ID 不能冲突。
-
解决方案:
- UUID(缺点:长、无序)。
- Redis / Snowflake 算法生成分布式 ID。
- 数据库号段方式(各库分配不同 ID 段)。
-
-
跨库查询 / 聚合问题
-
分页、统计、排序时可能涉及多个库。
-
解决方案:
- 应用层分别查询后合并结果。
- 借助中间件做分布式查询。
-
# ⚖️ 总结
-
分库方式:
- 垂直分库:按业务模块拆分数据库;
- 水平分库:按数据规则拆分同一业务表。
-
实现工具:
- 中间件:Sharding-JDBC(轻量级、嵌入应用)、MyCAT(代理型)、Vitess 等。
-
关键问题:数据路由、分布式事务、全局 ID、跨库查询。