[Ai Agent] 本地知识库检索运用
相关专栏:AI Agent实战
前言:
在前一篇文章[Ai Agent] 从零开始搭建第一个智能体-CSDN博客 中,我们已经初步掌握了如何创建一个简单的智能体。在本文中,我们会深入了解本地知识库的功能以及如何使用。
如果想跳过概念理解,可以直接看本文的(三、实战运用本地知识库),会有详细图文教学如何使用。
一、本地知识库是什么
假设这样一个场景:你做好了一个智能体客服,希望客服跟它交流时代替人工。但此时的商品是已售罄的,客服不知道,直接跟客户讲现在就可以下单。为了预防这种情况,我们就需要让智能体拥有我们为其专门添加的知识库,让它能像真正的人一样熟知各种应知晓的业务信息。
而这种知识库,就是一个系统化的信息存储库,包含各种知识、规则和数据,旨在支持智能体的决策和推理过程。它可以是结构化的(如数据库)或非结构化的(如文档和文本)。
为了更好的了解它,我们还需要引入一个新概念:RAG:在Ai Agent里必须知晓的概念。
二、了解RAG与它的运作原理
RAG(Retrieval-Augmented Generation)是一种结合了信息检索和自然语言生成的技术,旨在提高生成模型的性能和准确性。
简单讲,RAG就是先翻书(知识库),把找到的答案塞进脑子里,再开口回答。这样它的准确性就能大大提高。
RAG 模型把两件事串成一条流水线:
-
检索器——像图书馆管理员,根据你的问题去外部知识库(数据库、文档、网页都行)瞬间找出最相关的几段资料;
-
生成器——像会写作的学霸,把管理员递过来的资料连同问题一起塞进ai大模型,让模型按资料内容组织一段自然语言回复。
用户先提问→管理员找书→学霸用书里的信息写答案,于是回答既实时又准确,还能随书库更新而更新。
而管理员(检索器)+学霸(生成器)俩结合起来,就是RAG模型,共同完成整套对客户的回复逻辑。
三、实战运用本地知识库
(1)搭建一个本地知识库并运用
本文假设读者已知如何创建一个最基础的智能体
(如果不知道,建议先看我的上篇文章[Ai Agent] 从零开始搭建第一个智能体-CSDN博客 了解)
进到个人空间后,点击工作空间-资源库-之前的任意一个对话流

进来后,点击最下方的添加节点,再点击知识库检索。
(这里略提一下添加节点:节点里提供的,要么是已封装了功能,要么是等待你封装功能。简单讲就是专门赋能用)
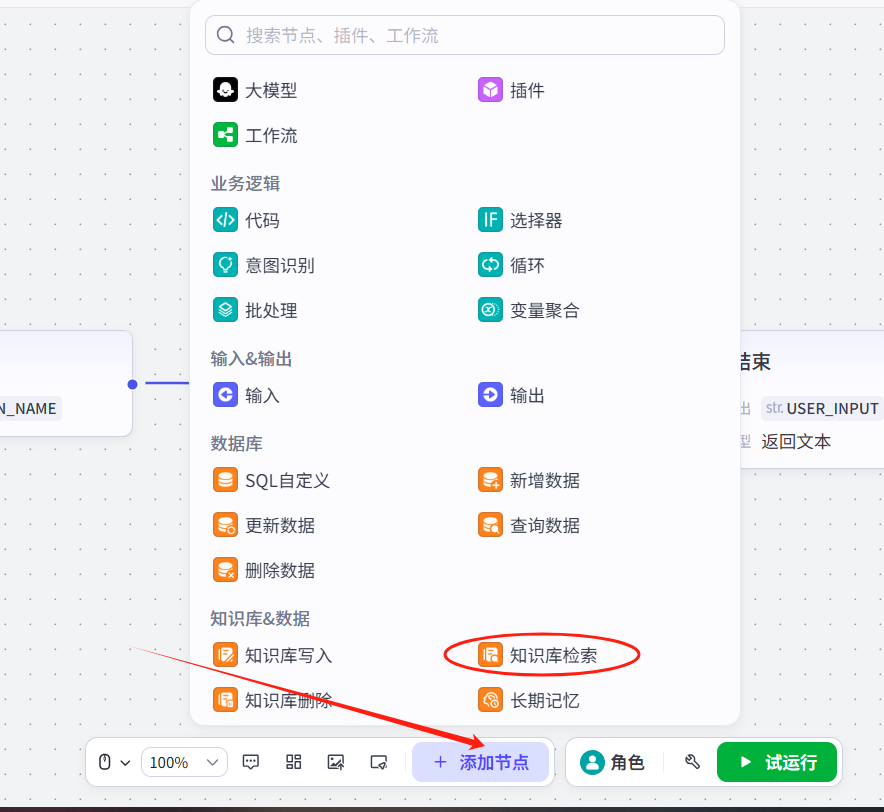
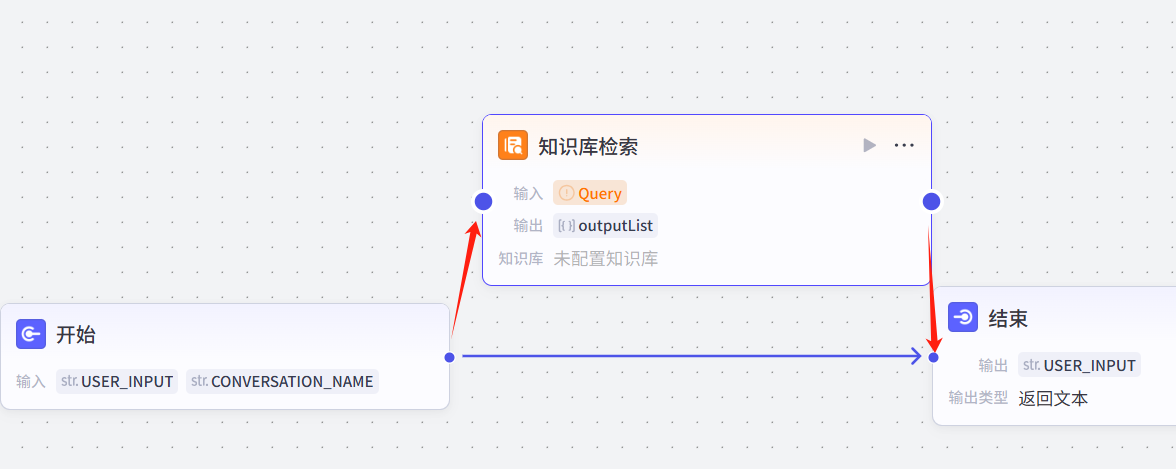
出来后,把线头改成这样的顺序,即开始-检索-结束,再把原箭头去掉。
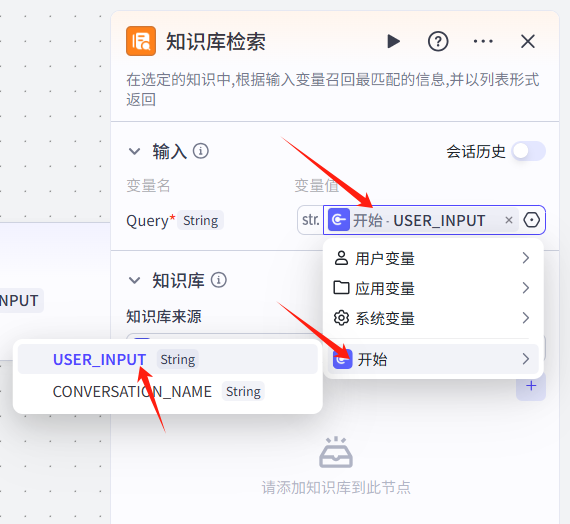
在右边这一栏,输入的变量值为空,我们为其设置变量值就是开始的USER_INPUT
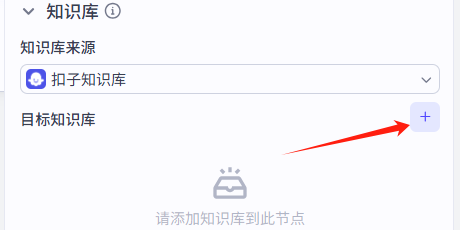
点击+,再点击创建知识库 -- 为其添加知识库
这里就可以添加知识库了。这里假设为其添加个excel的知识库。填写相关信息后点击创建并导入。
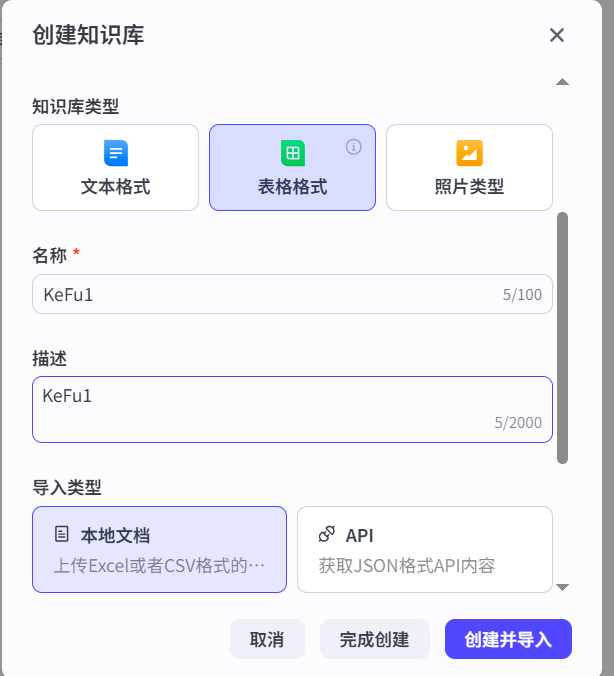

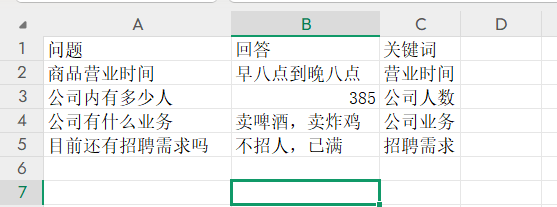
在上传这里上传一个excel文件,笔者自己大概写一个如下的简单格式:
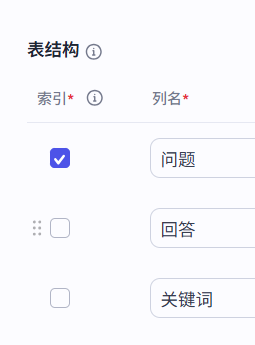 选择问题作为索引,权重更高识别率更好。其他默认,一直点击下一步
选择问题作为索引,权重更高识别率更好。其他默认,一直点击下一步

数据加载完成后,可以选择新增一行,这里再添加个第五行的相关信息。
全部完成后,即可退出。
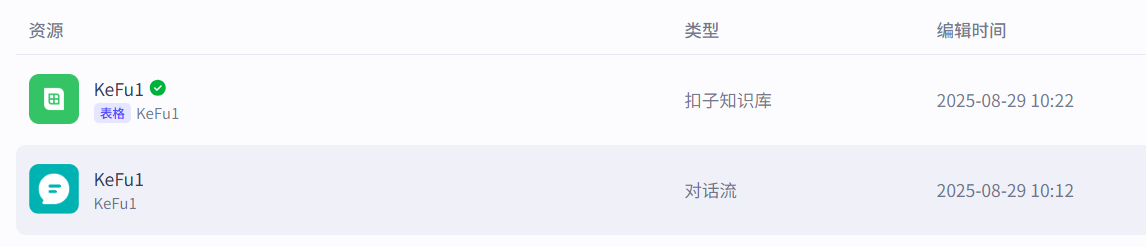
这里上方就是我们新增的一个可用于配置的知识库。再回到下边这个对话流接着进行我们的配置:
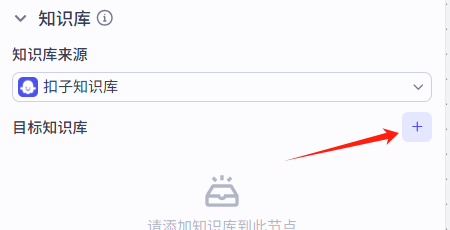

配置完成后,会有如下页面,先按默认设置就行。
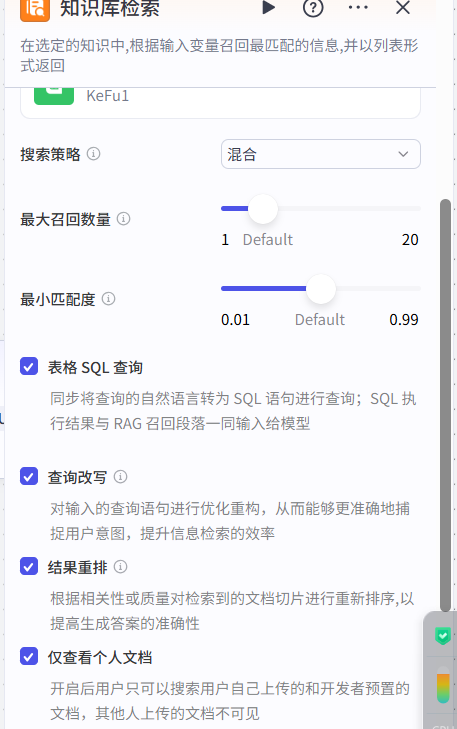
大致讲解下:
搜索策略:
• 混合:同时用“语义 + 全文”两条路去找,先各跑一遍,再把结果合并。
• 语义:只用向量相似度(意思相近)。
• 全文:只用关键词字面匹配(字面对得上)。
最大召回数量:
• 不管用哪种策略,最多先拉回多少条候选文档,后面再精排。
最小匹配度:
• 低于这个分数(或相似度阈值)的结果直接丢弃,防止拉回一堆不相关的内容。
其他的相关设置自己大概了解下即可。
点击结束,变量名更改为outpur,变量值选中为output,回答内容为{{outpu}}
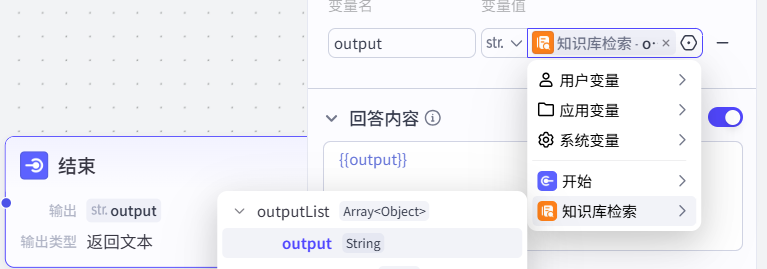
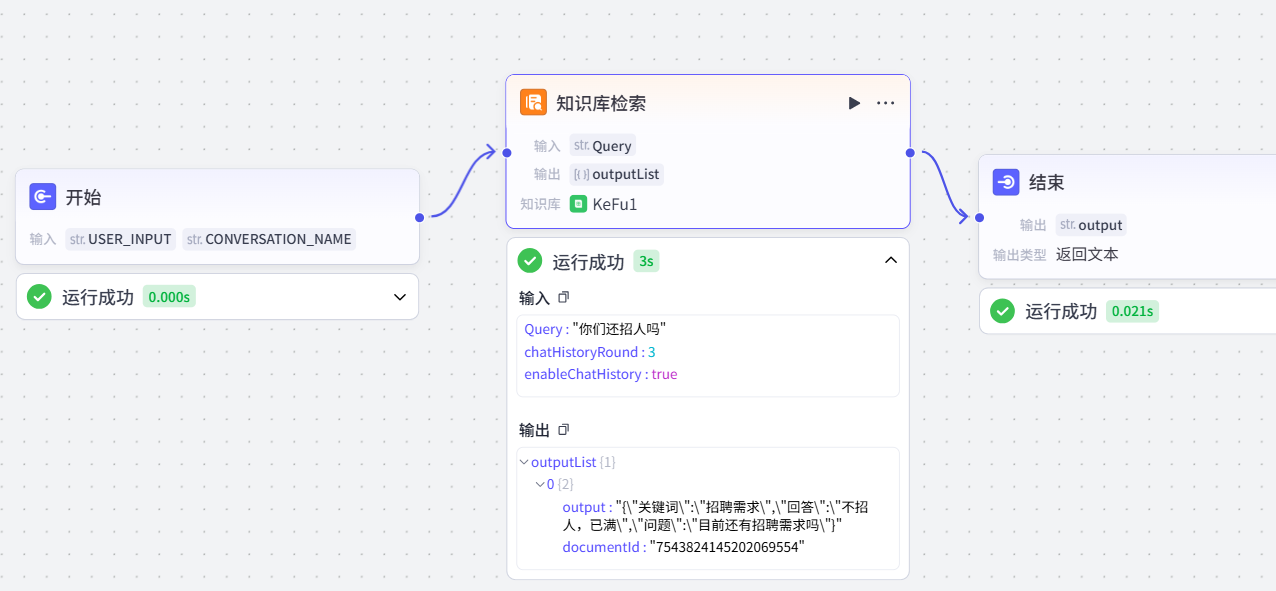
如上,我们点击试运行,问个相关我们知识库的问题:
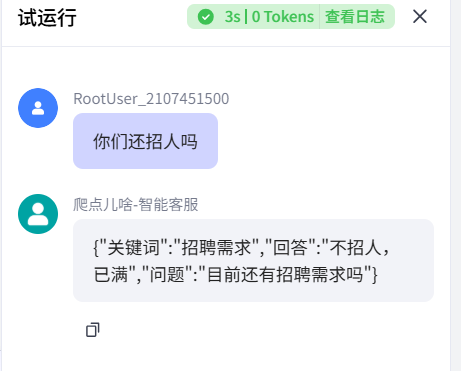 没问题。初步成功,接下来把回复话语再优化下。
没问题。初步成功,接下来把回复话语再优化下。
(2)优化回复逻辑
看到这个json数据很多程序员可能就想上手了,但别急,啥代码都不用写,我们接着往下做:
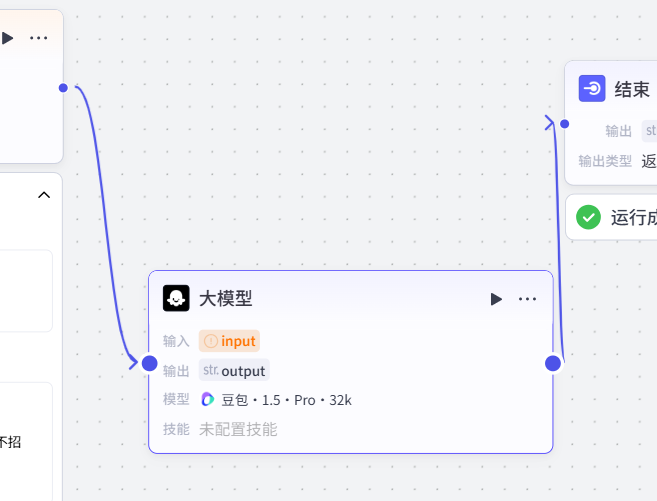
看图:这里我们想把回复话语润色下,就再结束-知识库中间加一个功能:大模型
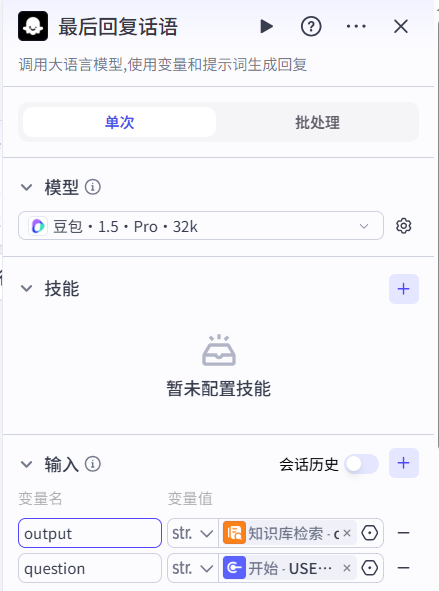
点击大模型,把标题改一下,再把输入里写入俩变量,
知识库返回的数据-命名为outpur,用户最初输入的问题-命名为question。
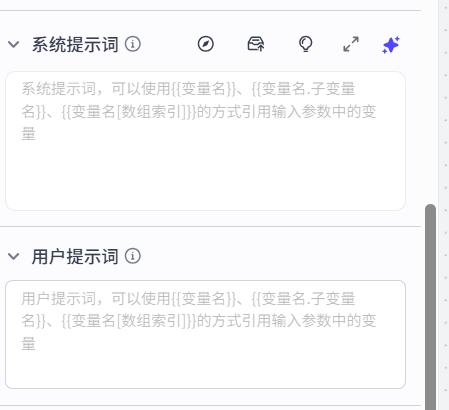 再把这两个地方填写完整。这里就是写各种大白话,让ai干事情,但还是需要区分下俩地方。
再把这两个地方填写完整。这里就是写各种大白话,让ai干事情,但还是需要区分下俩地方。
系统提示词:专用于给ai加设定,让它不要干一些乱七八糟的事,如下:
(此处设置的比较糙,如果涉及到具体业务肯定要加非常多的提示词,这里仅做简单演示)
你是一名客服助手,仅依据实时注入的知识表回答用户提问;禁止编造任何表外内容。回答时先匹配用户问题与知识表“问题”或“关键词”字段,完全匹配则直接输出对应“回答”,无匹配则回复“暂无相关信息,请联系人工客服。”回答须简洁,不超20字,不得解释。
用户提示词:用于把具体数据给大模型,如果你不把刚才我们设定的俩变量给到它,它没数据啥都干不了,如下:
用来回答的数据:{{output}}
用户的问题:{{question}}}
 输出格式改为文本。
输出格式改为文本。
同时别忘了在结束那里也需要加入大模型的变量值: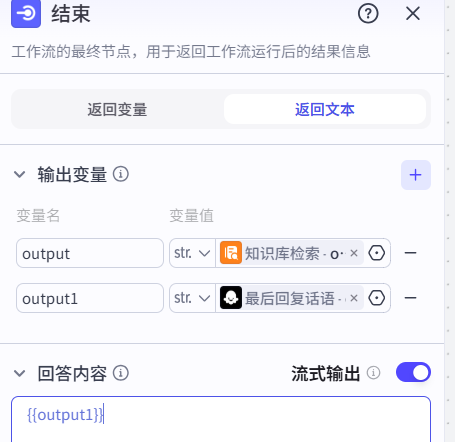
试运行下:
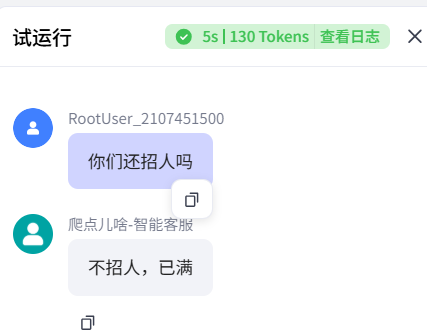 没问题,运行成功。
没问题,运行成功。
(3)加入在线文档
知识库里不仅我们本地添加,还可以添加一些在线网页的数据。下面做演示:
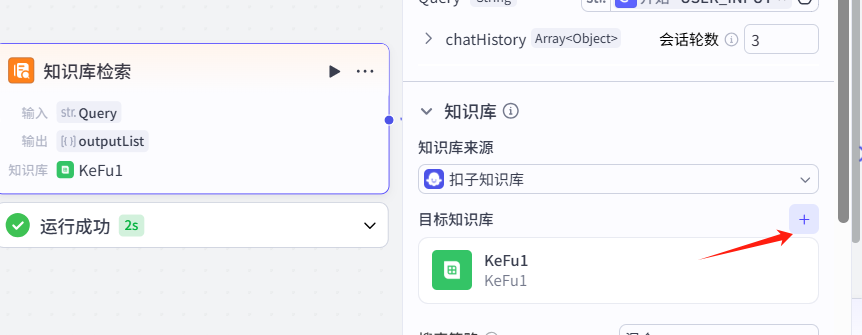
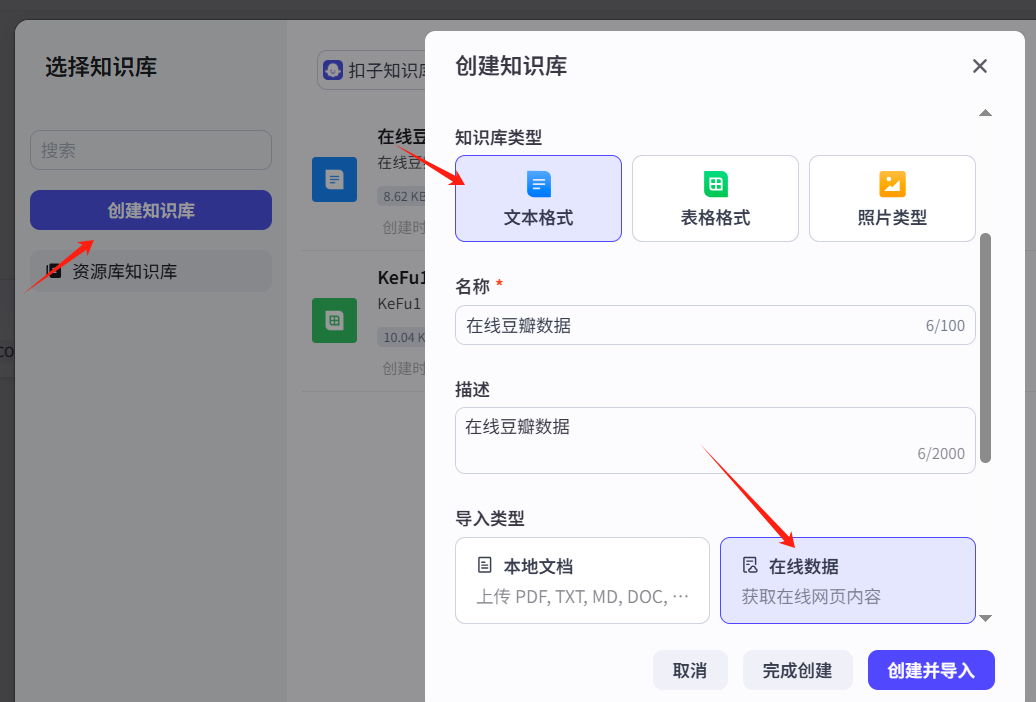
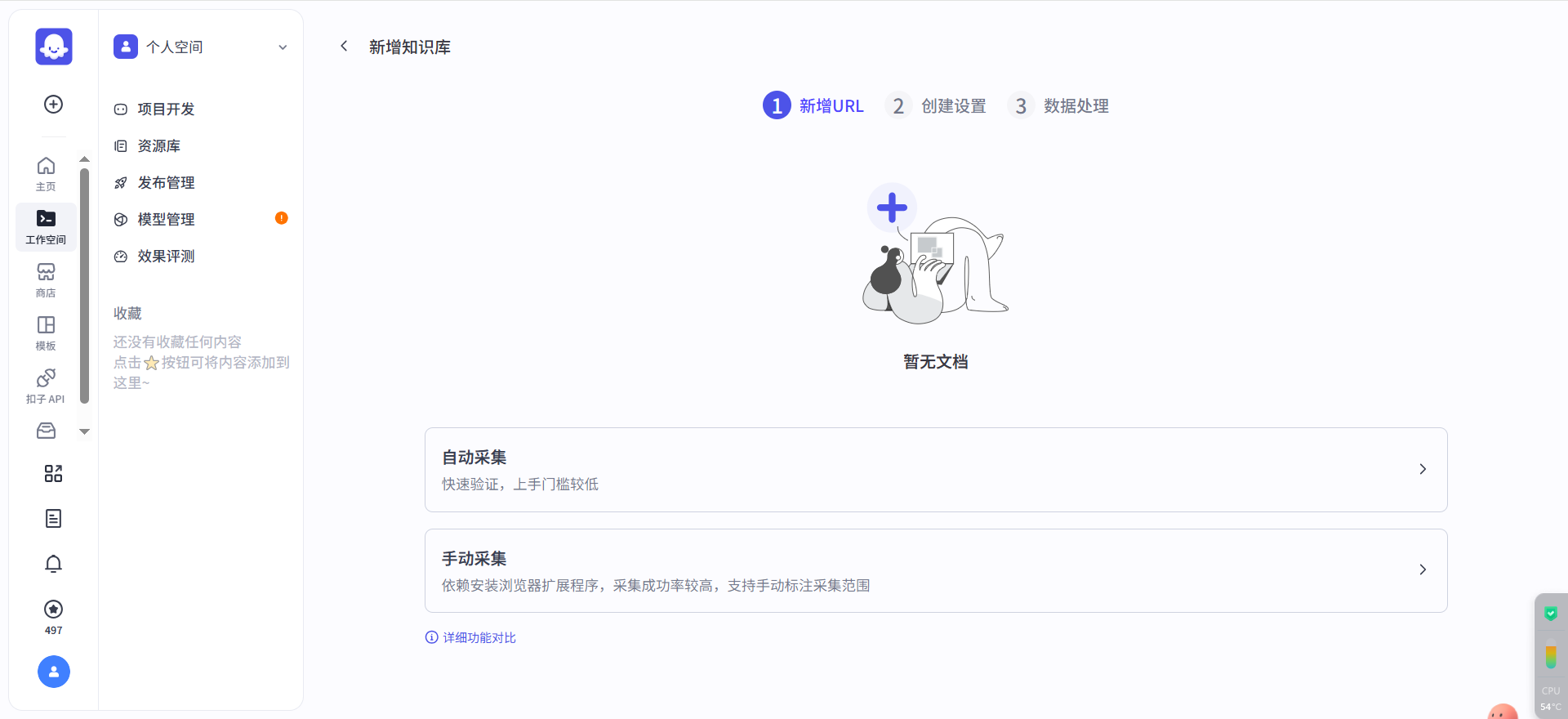
进到这个页面,实际上就是个爬虫了,爬取你想要的那个在线网页数据。先以简易为主,我们选择自动采集。我们这里以豆瓣电影top250为例:豆瓣电影 Top 250,一路下一步,再点击确认。
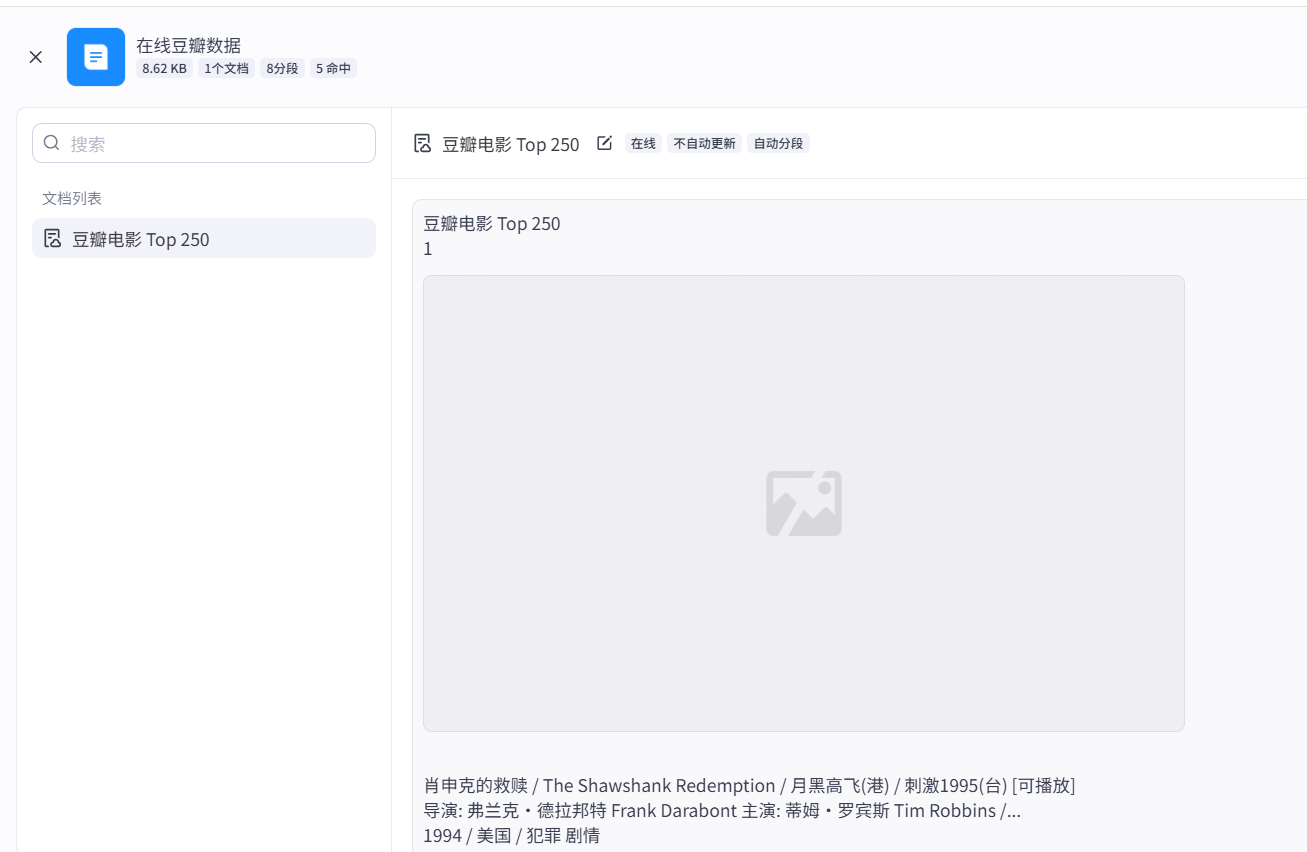
这里就可以看到各种引入的数据了。
再返回到我们刚才的对话流里的知识库检索,为其添加这个在线知识库: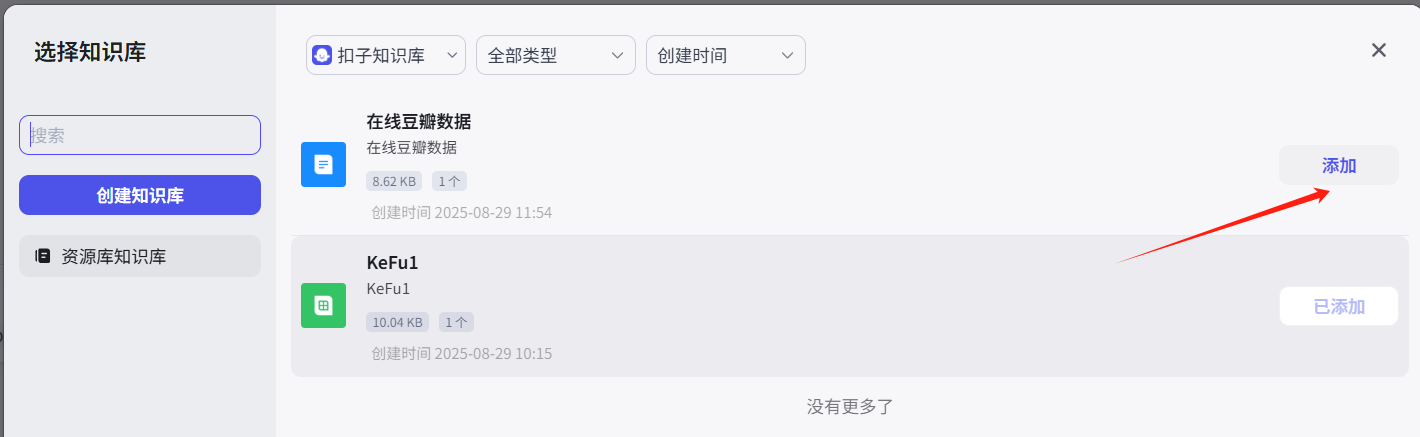 ,再点击试运行:
,再点击试运行:
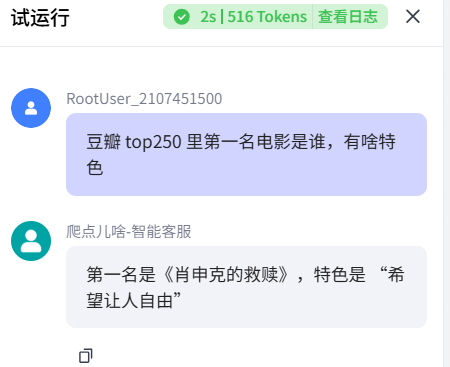 运行成功。
运行成功。
(4)加入图片
上面加入的知识库都是文字,我们这里再加入个图片的知识库检索。希望客服智能体回复的时候,附带上相关的图片。
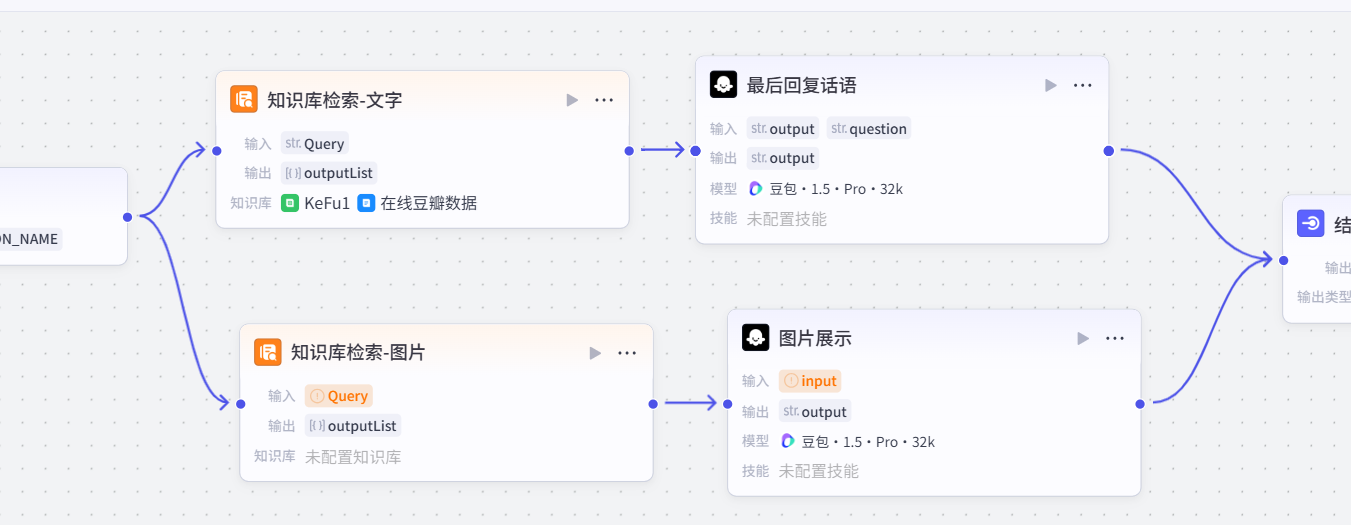
新写布局如上所示,并改一下相关标题。
这里就是并行,文字与图片逻辑都会走,最终汇总到结束输出。
点进知识库检索-图片,配置好输入,再新建一个图片知识库: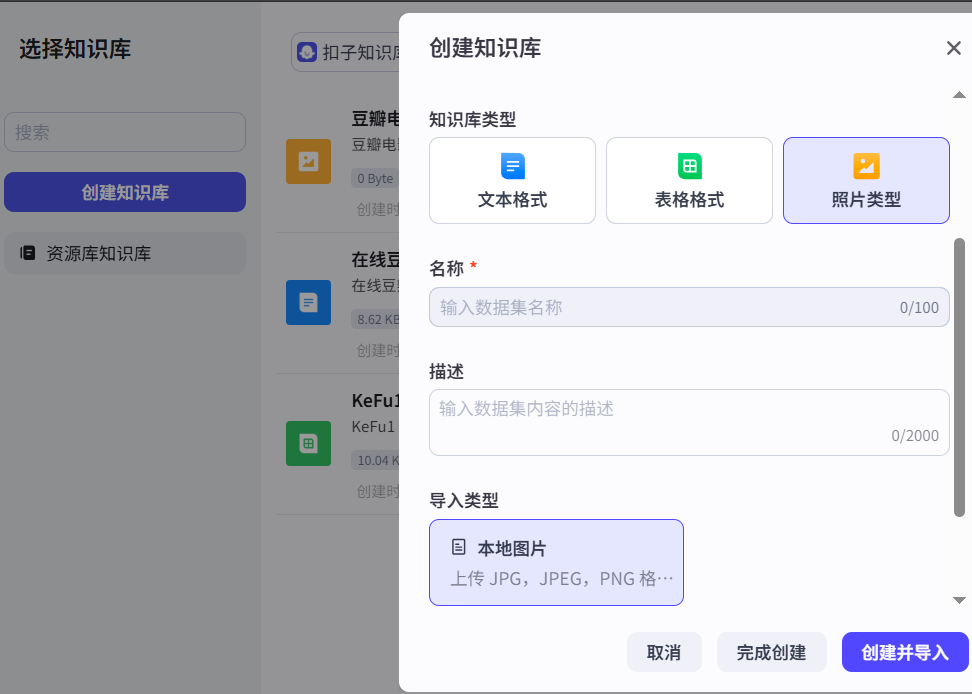
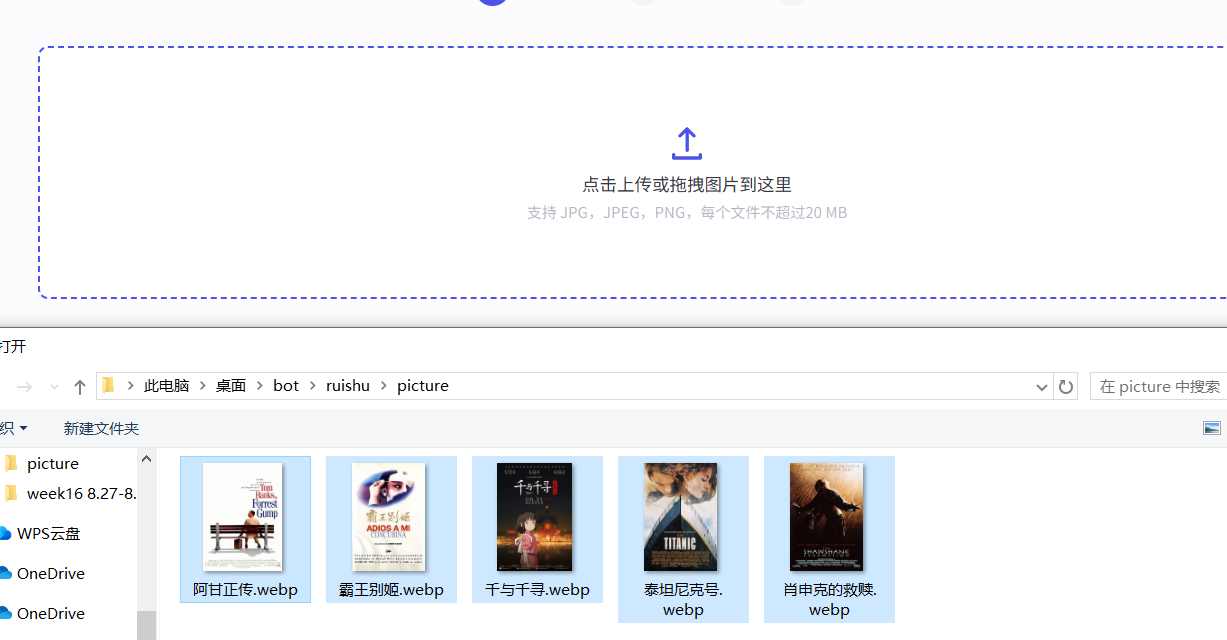
选择你确定好的几个图片传上去
(注:这里记得不要手动改图片格式,你二次更改过的格式coze不认,这个我踩了坑)。
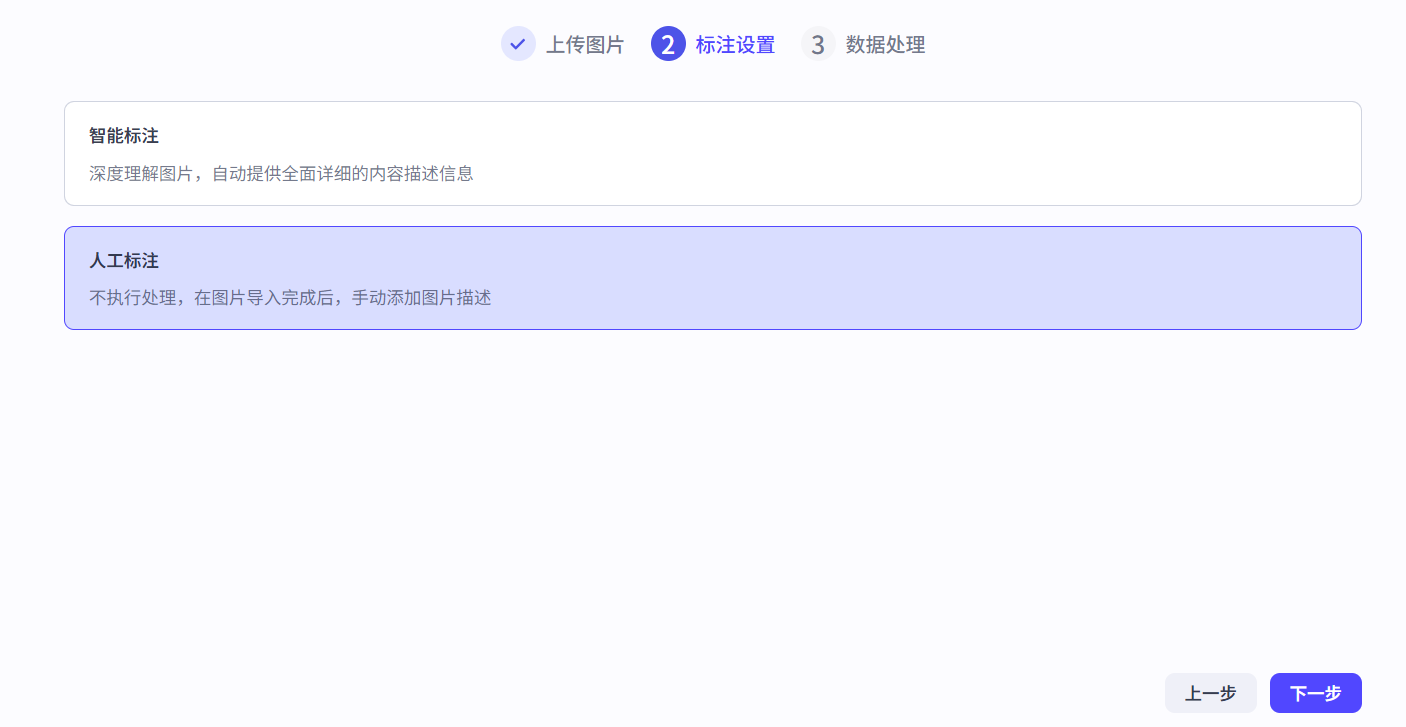
这里选择人工标注。此处图片不像刚才那些数据可以被ai分析比较准确,最好还是我们自己标注下。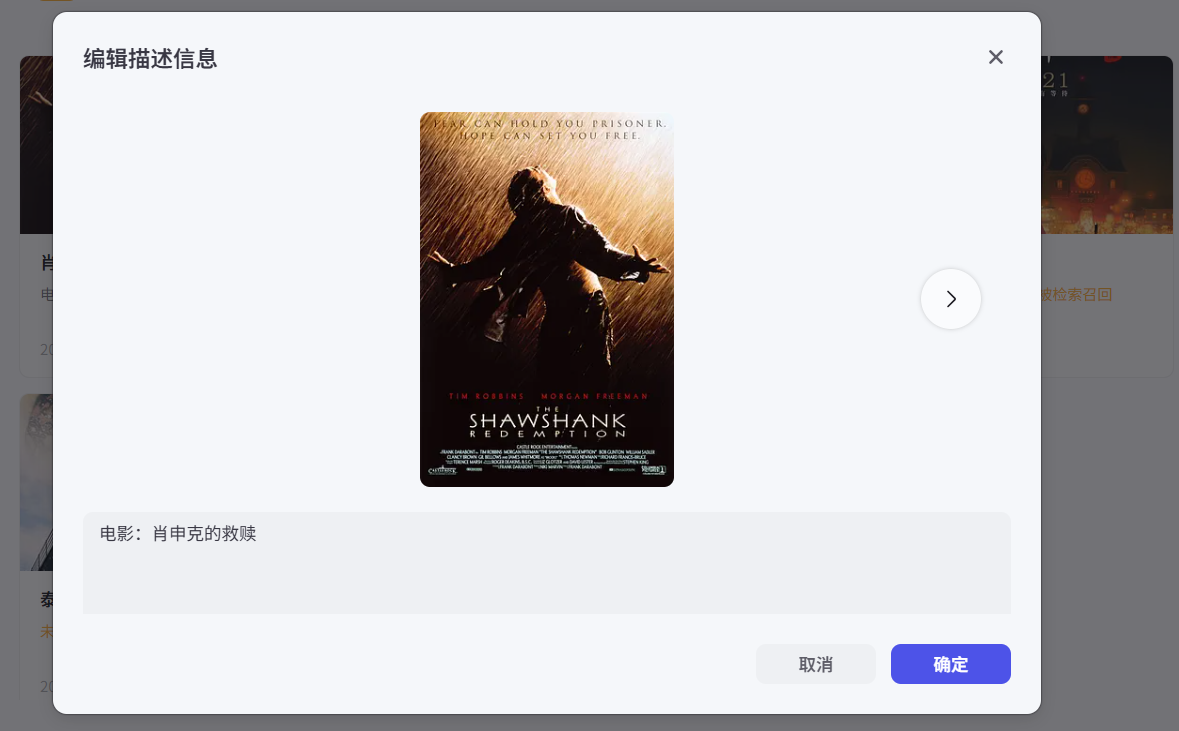 如图,为其逐个标注所有相关信息。完成后回到我们的对话流继续。
如图,为其逐个标注所有相关信息。完成后回到我们的对话流继续。
现在再把刚才的图片知识库配置给知识库检索-图片: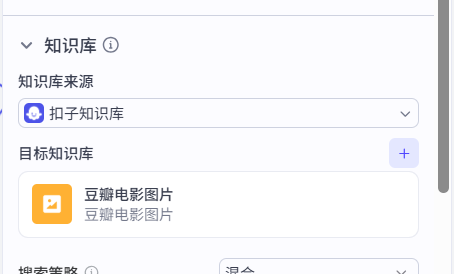
再在大模型里略微调整一下,跟第一个大模型相似的做法:
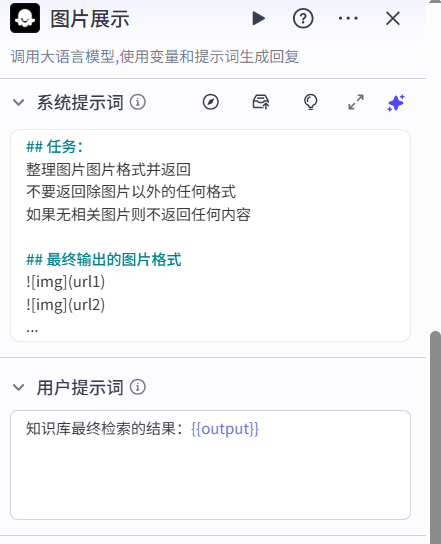
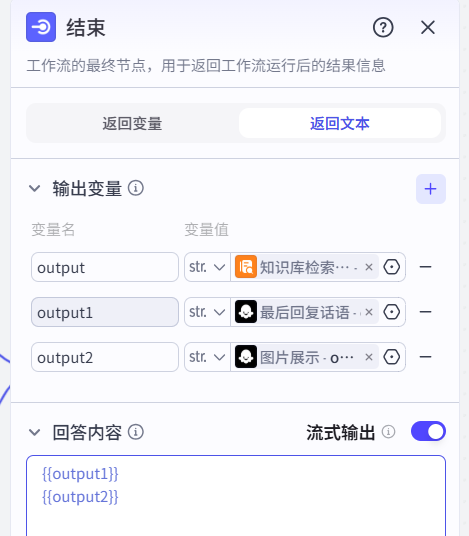
最后在结束里加入新的图片展示的输出数据,一切完成后我们试运行下:
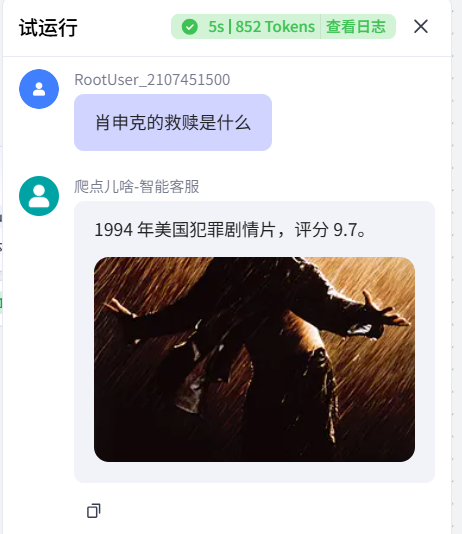 运行成功。
运行成功。
四、小结
通过本文的实战操作,我们不仅了解了本地知识库和 RAG(检索增强生成)的基本概念,更掌握了如何在 Coze 平台上实际运用它们。
本地知识库就像是给你的 AI 智能体配备了一本专属的“百科全书”,让它能够获取和利用你提供的特定信息,从而回答更专业、更精准的问题。它解决了大语言模型可能存在的“信息滞后”和“胡编乱造”问题,确保智能体输出的内容真实可靠。
RAG 模型的运作方式,即“检索器”加“生成器”的结合,完美地解释了智能体如何高效地利用这些知识:它先从知识库中精准地找到相关信息,再结合这些信息生成流畅、自然的回复。
此外,我们还学习了如何整合不同类型的知识源,包括:
-
本地文件:如 Excel 表格,用于结构化的数据问答。
-
在线网页:通过爬虫技术,让智能体实时获取网络上的公开信息。
-
图片:通过手动标注,让智能体能够理解并关联图片信息,在回复中展示相关图片。
总而言之,熟练运用本地知识库是构建一个更聪明、更实用、更值得信赖的 AI 智能体的关键一步。它使得智能体不仅拥有强大的语言能力,还具备了深厚的专业知识,能够真正成为你的得力助手。