详解多智能体架构:以 Open Deep Research 项目为例
资料来源:火山引擎-开发者社区
背景
业界 AI 大佬们最近对上下文进行了很深入的一番讨论(“争吵”):
1.Cognition 的看法:反对多智能体,推崇上下文工程
- 认为当前 LLM 在处理长上下文和主动沟通方面尚不成熟,强行引入 MAS 会导致上下文割裂、决策分散等风险,反而弱化系统可靠性。
- 主张先构建单体系统并加强上下文工程,再考虑多智能体结构。
2.Anthropic 的看法:探索并行优势,但依赖上下文工程
- 其多智能体研究系统采用 orchestrator‑worker 模式,多个 Agent 分工并行处理,适合用于大范围信息检索与整合任务。
- 但强调必须通过上下文工程实现状态共享与记忆同步,否则容易失控。
3.LangChain 的折中立场:灵活架构,任务导向选择
- 认为共同点是 上下文工程的重要性;而多 Agent 在“读取(Read)”型任务中效果更佳,“写入(Write)”型任务仍建议采用单 Agent。
- 推出 LangGraph 等编排工具,实现对 LLM 调用上下文的精细控制,支持混合架构。
| 阶段/角色 | 核心观点 | 优势 | 局限性或挑战 | | --- | --- | --- | --- | | Cognition / Devin | 单体 + 上下文工程 | 简洁、稳定、可控 | 并行处理能力弱、应对大规模任务时效率低 | | Anthropic | 多智能体协作,依赖上下文工程 | 并行处理能力强,适合信息检索与大任务场景 | 协调复杂,若上下文不共享,易产生碎片化结果 | | LangChain | 灵活组合,任务写作 vs 读取区分 | 平衡优点,实用主义,支持细粒度架构选择 | 系统设计较复杂,需要准确识别任务类型与切换逻辑 |
本文就着重用 LangChain 的核心项目 Open Deep Research(https://github.com/langchain-ai/open\_deep\_research?ref=blog.langchain.com)来讲解下多智能体的架构。
Open Deep Research 的架构演进之路
让我们先从这个项目的发展历程说起,这个演进过程特别有代表性。
第一阶段:单体架构(Simple but Limited)
Open Deep Research 项目最初采用的是单体架构,就像我们大部分 AI 项目的起点一样:
用户查询 → 单个LLM → 工具调用循环 → 生成报告 架构特点:
- 集中式控制流
- 紧密耦合的组件
- 共享内存系统
- 所有逻辑在一个推理引擎中
这个阶段的代码大概是这样的:
classSimpleResearcher: defresearch(self, query): # 单个LLM处理所有任务 for i in range(max\_iterations): # 生成搜索查询 search\_query = self.llm.generate\_query(query, context) # 执行搜索 results = self.search\_tool(search\_query) # 分析结果,决定下一步 next\_action = self.llm.analyze\_and\_plan(results, context) if next\_action == "finish": break # 生成最终报告 return self.llm.generate\_report(all\_context)
遇到的问题:
1.上下文爆炸:复杂研究任务很快就达到 token 限制
2.效率低下:只能串行处理,无法并行化
3.质量不稳定:同时处理多个子主题,容易混乱
4.深度不够:为了控制 token,不得不限制研究深度
这些问题让 Langchain 团队意识到:单体架构在处理复杂研究任务时有根本性的局限 。
第二阶段:流水线架构(Better Organization)
为了解决单体架构的问题,项目引入了流水线架构 :
需求分析 → 信息收集 → 数据分析 → 报告生成 架构改进:
classPipelineResearcher: def\_\_init\_\_(self): self.scoper = ScopeAgent() self.collector = CollectionAgent() self.analyzer = AnalysisAgent() self.writer = WriterAgent() defresearch(self, query): # 阶段1:需求澄清 brief = self.scoper.clarify\_requirements(query) # 阶段2:信息收集 raw\_data = self.collector.collect\_information(brief) # 阶段3:数据分析 insights = self.analyzer.analyze(raw\_data) # 阶段4:报告生成 report = self.writer.generate\_report(brief, insights) return report
解决的问题:
- 清晰的职责分工
- 标准化的接口
- 可重用的组件
新的挑战:
- 仍然是串行处理,效率不高
- 信息收集阶段仍然受上下文限制
- 复杂推理任务表现不佳
第三阶段:多智能体架构(Current State)
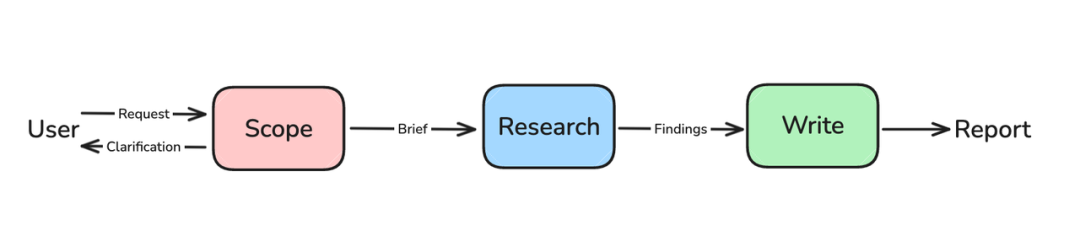
最终,项目演进到了多智能体架构 ,这也是本文要重点分析的:
监督者代理 → 多个专家代理并行工作 → 结果整合
关键突破:
1.上下文隔离:每个专家代理有独立的上下文窗口
2.并行处理:多个代理可以同时工作
3.专业化分工:每个代理专注特定领域
4.智能协调:监督者根据任务复杂度动态分配
让我们看看典型的研究场景是如何解决的:
场景:对比 OpenAI、Anthropic、DeepMind 的 AI 安全理念
单体架构时代:
# 所有信息挤在一个上下文里
search\_queries = [ 'OpenAI AI safety framework', 'Anthropic constitutional AI approach', 'DeepMind technical safety research'
] for query in search\_queries: results = search(query) # 结果越来越多 context += results # 上下文越来越大! # 上下文污染,token爆炸,质量下降
多智能体时代:
# 每个代理专注一个公司,独立的上下文
agent\_openai = SpecialistAgent(focus="OpenAI safety")
agent\_anthropic = SpecialistAgent(focus="Anthropic safety")
agent\_deepmind = SpecialistAgent(focus="DeepMind safety") # 并行执行,各自深度研究 results = await asyncio.gather( agent\_openai.deep\_research(), agent\_anthropic.deep\_research(), agent\_deepmind.deep\_research()
) # 监督者整合结果
final\_report = supervisor.synthesize\_comparison(results)
这个演进过程给我们一个重要启示:多智能体不是一开始就需要的,而是在单体架构遇到根本性限制时的自然演进 。
深入解析:多智能体架构的设计精髓
了解了演进过程后,让我们深入分析当前的多智能体架构是如何设计的。这里体现了很多上下文工程的核心思想。
LangChain 团队在最新版本中设计了一个三阶段架构:
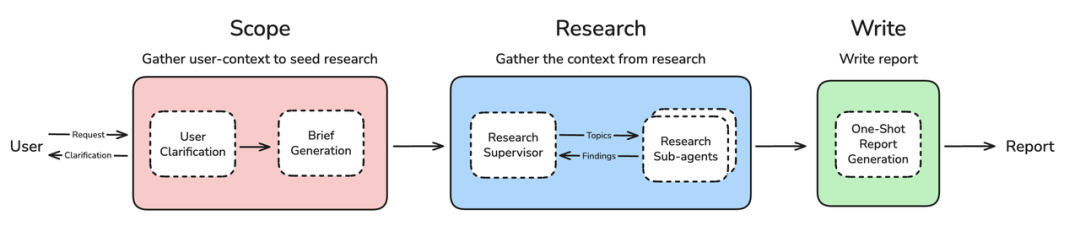
Phase 1: Scope(范围界定)
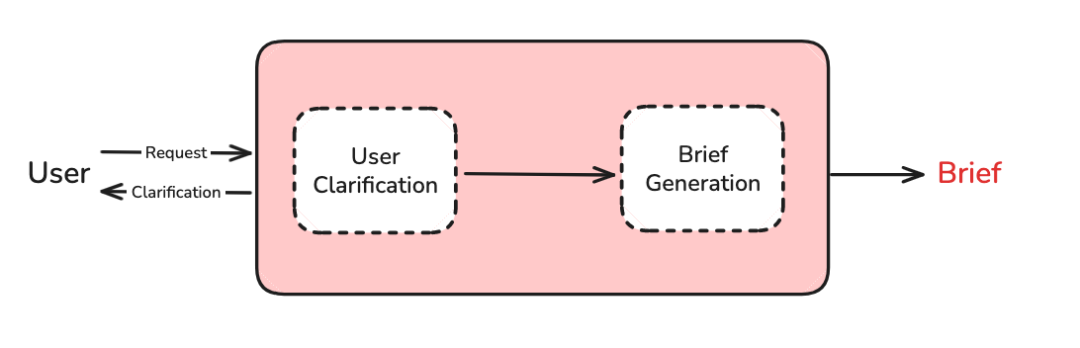
Scope 需要规划当前处于任务的哪个阶段;
用户需求 → 需求澄清 → 研究简报生成
这个阶段完美体现了上下文工程中的"压缩"策略 :
实际案例
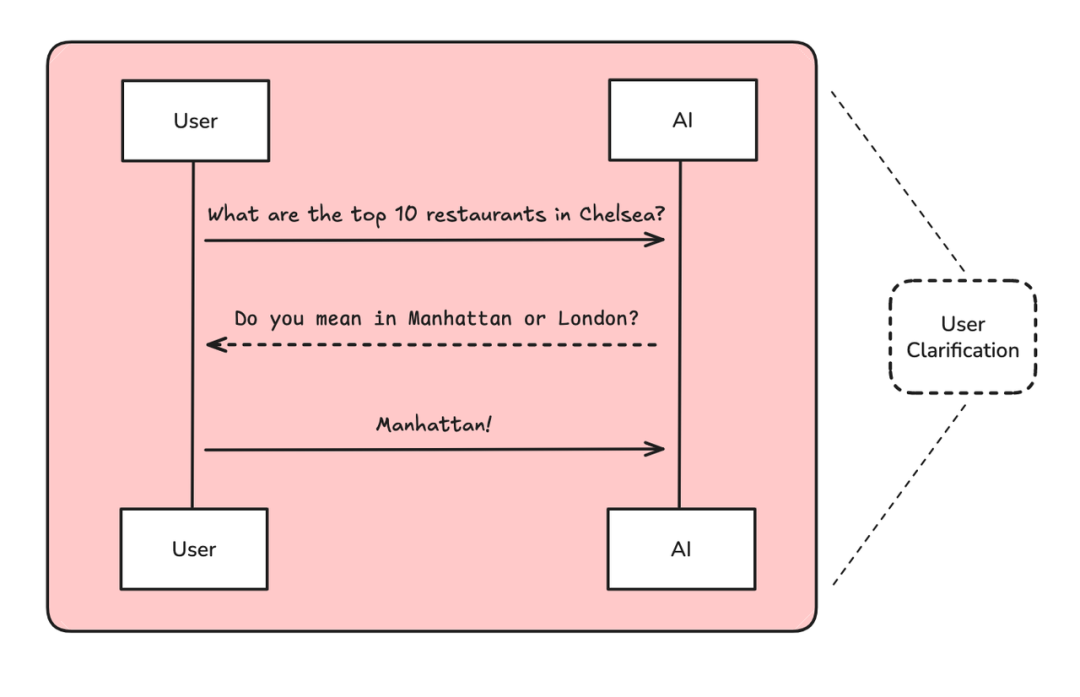
这张图很明显的展示了通过聊天模型主动获取缺失信息的过程;
用户:"切尔西区排名前十的餐厅有哪些?"
系统:"你是说在曼哈顿还是伦敦?"
用户:"曼哈顿"
系统:"明白了,我来为您生成详细的餐厅简报..."
上下文工程的核心应用:
- Write Context:将冗长对话保存为结构化的研究简报
- Compress Context:避免 token 浪费,聚焦核心需求
- Select Context:为后续研究提供明确的"北极星"
这种设计解决了我们在上下文工程中提到的"上下文爆炸"问题。
Phase 2: Research(研究执行)
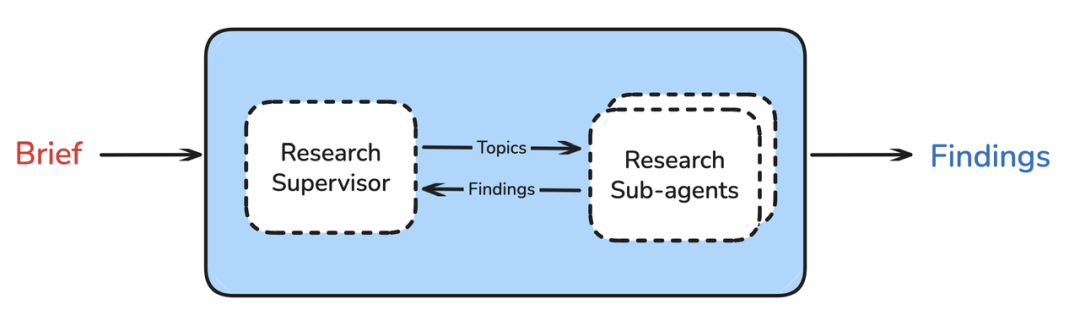
这是上下文工程"隔离"策略 的完美体现:
研究监督者 → 任务分解 → 多个子代理并行研究 → 结果整合
监督者的职责(智能分配上下文)
classResearchSupervisor: defdelegate\_research(self, brief): # 分析研究简报,判断是否需要并行化 subtopics = self.analyze\_parallelization\_needs(brief) if len(subtopics) > 1: # 创建专门的子代理,每个有独立上下文窗口 sub\_agents = [ ResearchAgent(topic=topic, focus=focus, isolated\_context=True) for topic, focus in subtopics ] # 并行执行研究,避免上下文冲突 results = self.parallel\_execute(sub\_agents) else: # 单线程深度研究 results = self.single\_thread\_research(brief) return self.evaluate\_completeness(results, brief)
子代理的上下文管理模式
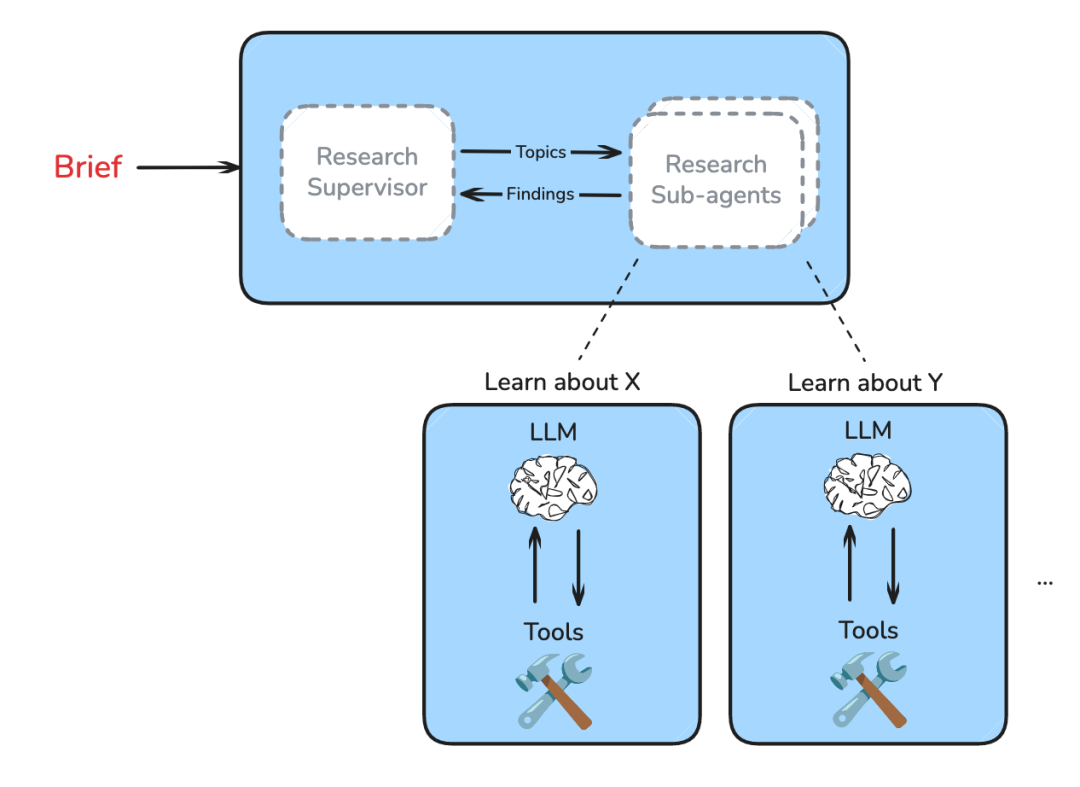
每个子代理都有明确的上下文边界:
- 专注单一主题:独立的上下文窗口,避免主题间的干扰
- 工具调用循环:搜索→分析→再搜索,上下文逐步积累
- 结果清理:最后压缩清理,只返回精华信息
这就是我们在上下文工程中提到的 "Isolate Context"策略 的实际应用!
Phase 3: Write(报告生成)
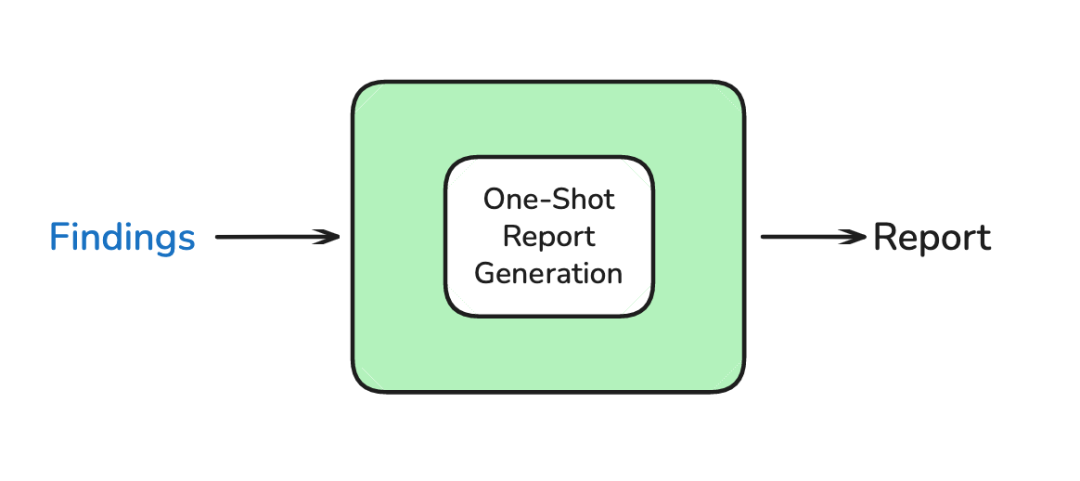
研究简报 + 所有研究发现 → 一次性生成完整报告
这个阶段体现了上下文工程中"Select Context"的智慧 :
关键设计思想:
- 集中式写作:不让子代理各自写片段(避免协调混乱)
- 精选上下文:只把压缩后的研究发现和原始简报给到写作 LLM
- 一次性生成:确保报告的逻辑连贯性和风格一致性
这解决了我们之前提到的"上下文冲突"和"协调复杂性"问题。
核心经验:什么时候该用多智能体?
适合多智能体的场景
1.子任务高度独立
对比分析:OpenAI vs Anthropic vs DeepMind的AI安全理念 子任务分解:
- Agent A:专门研究OpenAI的安全框架 - Agent B:专门研究Anthropic的Constitutional AI - Agent C:专门研究DeepMind的技术路线
为什么有效?
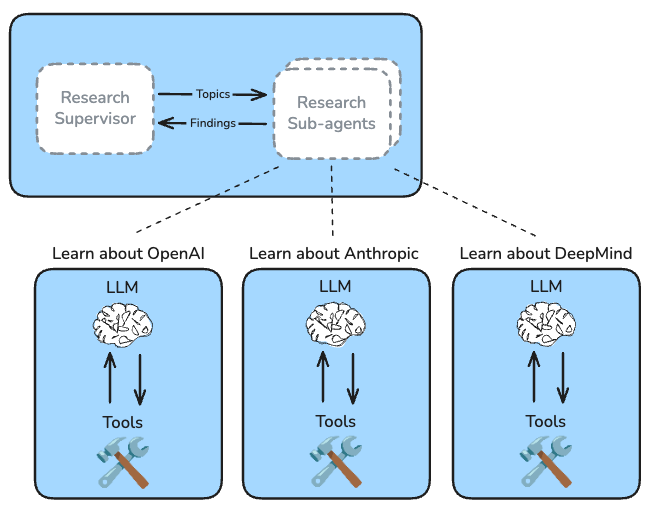
- 每个代理有独立的 context window
- 避免了"上下文冲突"(context clash)
- 可以并行执行,提高效率
2.需要不同深度的研究策略
classFlexibleResearchSupervisor: defdecide\_strategy(self, brief): complexity = self.assess\_complexity(brief) if complexity == "simple": return"single\_agent\_quick\_research" elif complexity == "medium": return"parallel\_research\_2\_agents" elif complexity == "complex": return"deep\_parallel\_research\_5\_agents"
比如:用户不希望简单问题等 10 分钟,但复杂问题需要深度挖掘。监督者可以灵活调节研究深度。
不适合多智能体的场景
1.需要紧密协作的任务
LangChain 团队踩过的坑:
❌ 错误做法:让多个子代理分别写报告的不同章节
结果:章节之间逻辑不连贯,风格不统一 ✅ 正确做法:多代理只负责研究,一个LLM负责写作
结果:报告逻辑清晰,风格统一
2.简单的单线程任务
用户:"GPT-4是什么时候发布的?"
这种问题用多智能体就是杀鸡用牛刀。
实战经验:LangChain 多智能体研究系统
LangChain 的多智能体研究系统:
架构设计
classMultiAgentResearchSystem: def\_\_init\_\_(self): self.supervisor = ResearchSupervisor() self.agent\_pool = AgentPool(max\_agents=5) self.context\_manager = ContextEngineer() defresearch(self, user\_query): # 阶段1:范围界定 brief = self.scope\_phase(user\_query) # 阶段2:智能体研究 research\_findings = self.research\_phase(brief) # 阶段3:报告生成 report = self.write\_phase(brief, research\_findings) return report defresearch\_phase(self, brief): # 监督者决定研究策略 strategy = self.supervisor.plan\_research(brief) if strategy.parallel: # 创建专门的子代理 agents = [ self.create\_specialist\_agent(subtopic) for subtopic in strategy.subtopics ] # 并行执行 raw\_findings = self.parallel\_research(agents) # 上下文工程:清理和压缩结果 clean\_findings = [ self.context\_manager.compress\_findings(finding) for finding in raw\_findings ] else: # 单代理深度研究 clean\_findings = self.single\_agent\_research(brief) return clean\_findings
上下文工程的关键作用
我们发现,多智能体系统最大的挑战不是协调,而是token管理 :
classContextEngineer: defcompress\_findings(self, raw\_research): """子代理研究结果压缩""" compression\_prompt = f""" 请从以下研究材料中提取最核心的信息: 原始材料:{raw\_research} 要求: 1. 保留关键事实和数据 2. 去除重复和无关信息 3. 保持引用来源 4. 控制在500tokens以内 """ return self.llm.generate(compression\_prompt) defgenerate\_brief(self, chat\_history): """对话历史压缩成研究简报""" brief\_prompt = f""" 基于以下用户对话,生成聚焦的研究简报: 对话历史:{chat\_history} 研究简报应包含: - 核心研究问题 - 具体要求和边界 - 期望的输出格式 - 成功标准 """ return self.llm.generate(brief\_prompt)
实际效果数据
根据 GitHub 仓库 langchain‑ai/open_deep_research 的说明(2025 年 8 月 2 日更新):
- 在 DeepResearch Bench 排行榜中,Open Deep Research 排名第六。
- 本次评估其 RACE 总分为 0.4344。
- 是当前表现最好的完全开源 Deep Research Agent。
踩坑经验:多智能体的陷阱
协调复杂性陷阱
错误做法:
# 让多个代理协作完成一个紧密耦合的任务
agent1.write\_introduction()
agent2.write\_analysis() # 不知道introduction写了什么
agent3.write\_conclusion() # 不知道analysis的结果
正确做法:
# 多代理只做独立的研究,集中式整合 findings = parallel\_research([agent1, agent2, agent3])
report = single\_writer.synthesize(findings)
成本失控陷阱
多智能体系统 token 消耗确实更高,需要精心设计:
classCostOptimizer: defoptimize\_agent\_usage(self, brief): complexity = self.assess\_complexity(brief) if complexity < 0.3: return"single\_agent"# 简单问题不浪费 elif complexity < 0.7: return"2\_agent\_parallel"# 中等复杂度 else: return"full\_multi\_agent"# 复杂问题全力以赴
结果质量不一致
不同子代理可能有不同的"理解偏差":
classQualityController: defensure\_consistency(self, sub\_findings): # 质量检查点 for finding in sub\_findings: ifnot self.meets\_quality\_standard(finding): # 要求子代理重新研究 finding = self.request\_refinement(finding) return sub\_findings
设计原则:我们的多智能体最佳实践
1.明确边界原则
- ✅ 每个代理有清晰的职责边界
- ✅ 子任务之间相对独立
- ❌ 让代理处理有依赖关系的任务
2.监督者智能化原则
智能监督者负责
- 任务分解
- 路由与协调
- 并行/串行调度
- 质量与预算控制
- 异常重试与升级
3.上下文工程优先原则
在多智能体系统中,上下文工程的重要性 > 协调算法:
- 研究简报要保持简洁、聚焦
- 子代理输出需要清理、压缩
- 避免无效 token 消耗和上下文污染
4.质量控制原则
由「质量闸口」来判断研究结果是否足够深入:
- 计算研究覆盖度,与目标简报进行对比
- 如果覆盖度 < 0.8,则触发额外研究
- 否则通过审核并输出结果
未来展望:多智能体的发展方向
自适应代理分配
根据工作负载智能调整代理数量:
classAdaptiveAgentPool: defauto\_scale\_agents(self, workload): optimal\_agents = self.predict\_optimal\_count(workload) if optimal\_agents > self.current\_agents: self.spawn\_additional\_agents(optimal\_agents - self.current\_agents) elif optimal\_agents < self.current\_agents: self.retire\_excess\_agents(self.current\_agents - optimal\_agents)
跨领域专业化
为不同领域创建专门的代理:
classDomainSpecialistFactory: defcreate\_specialist(self, domain): specialist\_config = { 'academic\_research': AcademicResearchAgent, 'market\_analysis': MarketAnalysisAgent, 'technical\_review': TechnicalReviewAgent, 'legal\_compliance': LegalComplianceAgent } return specialist\_config[domain]()
智能协调算法
优化代理间的协调和依赖关系:
retail\_enter\_domain\_model (信息获取型) ↓ 提供 enter\_node\_name\_list 参数
retail\_shop\_qual\_audit\_info (依赖调用型) check\_business\_license\_duplicate (独立调用型)
核心总结
通过 Open Deep Research 项目的演进历程,我们看到了 AI 工程化的清晰路径:
单体LLM → 流水线架构 → 多智能体架构
关键启示:
- 多智能体不是一开始就需要的,而是在遇到根本性限制时的自然演进
- 上下文工程是多智能体架构的理论基础
- 成功的多智能体系统本质上是上下文隔离策略的极致应用
写在最后
Open Deep Research 项目的演进历程给我们最重要的启示是:每一次架构变迁都是为了解决具体问题而自然涌现的 。
从单体到流水线,再到多智能体,技术选择的背后是对复杂性管理的不断深化。不要为了技术而技术,要为了解决问题而技术。
作者团队
我们来自字节跳动的电商即时零售技术团队,专注于构建统一的 AI 基座与智能化服务体系,通过多模态技术与自动化平台,为商家和平台提供高效、可扩展的解决方案,助力商家提升经营能力、降低运营成本。
团队研究与落地方向包括:知识问答与治理、AI 内容创作与供给、AI Infra 与原子能力建设。