梯度下降,梯度消失,梯度爆炸
什么是梯度下降?
梯度下降是指,对网络中的一些动态参数,如权重等进行求偏导然后更新找到最小误差的一个过程。
新x=旧x−学习率∗梯度
(对模型的每一个可学习参数(通常是权重 w和偏置 b)求偏导数,目的是最小化损失函数(Loss Function)。
我们要求的是:损失函数 L关于某个特定参数(例如 w)的偏导数 ∂L/∂w。)
梯度下降和反向传播有什么区别?
(反向传播,找到或求出梯度的一个过程, 梯度下降,利用梯度进行更新权重参数和偏置的过程)


梯度下降的算法有哪些?
常见的就是Adam 优化器(优化算法),他结合了动量法和自适应学习率算法,具有 收敛快,鲁棒性好的特点。
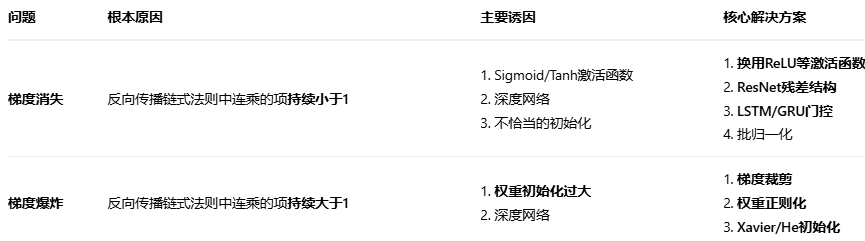
梯度爆炸,梯度消失,这是什么意思,怎么回事,一般什么时候会出现这些现象?
梯度爆炸, 梯度消失都是在反向传播过程中,由于链式法则的传递,让梯度传递过程中被指数级放大(NaN)或减小(0)的过程。
梯度爆炸会造成模型权重剧烈波动,极度不稳定,无法收敛。
梯度消失会导致梯度接近0,更新量也为0,若为训练后期,则达到稳定,若为前中期,则无法继续训练到模型(即网络退化成浅层网络)。
诱因:1)激活函数的选择(如Sigmod,Tanh激活函数,因为两者的导数值域分别为(0,025],和(0,1], |x|的值稍过大,就会处于饱和区,从而使得梯度爆炸或消失,ReLu就不会,因为在>0部分,梯度恒为1)。
2)权重初始化:初始化值过大就会容易梯度爆炸, 过小就会容易梯度消失。
3)网络过深:网络越深 链式法则反向传播的时候,就容易被指数级放大或缩小
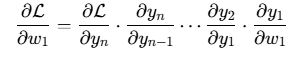
4)优化器与学习率 :虽然不直接导致梯度爆炸,但可能会使权重更新步伐太大,导致权重 值进入一个“不稳定区”,间接引发后续的梯度爆炸。
5)数据本身包含异常值或量级差别很大,导致梯度过大。
解决方案: 1)——使用更有效地激活函数,如:ReLU,Leaky ReLU, ELU,Swish等
3)——使用残差连接,其可以绕过某些层进行传播,来缓解梯度消失或爆炸。
5)——使用门控设计来控制信息的流动和记忆(让过分奇异的值无法进入)
1)——批归一化,通过规范化每一层输入,使得激活函数的分布更加稳定。
梯度裁剪,即设置一个梯度阈值,过大或过小的不能通过
权重正则化——加入权重L1或L2范数惩罚项,惩罚过大的权重值,从而间接抑制梯度爆炸