SPARK入门
1.基本概念
MapReduce的局限性:
1.为了节约内存大量与磁盘进行交互因此处理时间长
2.解决大规模离线批处理,对于其他场景要与其他组件来结合,功能太单一,维护成本很高
Spark的特点:
把数据放在内存进行计算,解决MapReduce计算慢的问题
All in one框架,提供多种计算场景
SparkStreaming:微批处理,很短的时间进行一次处理,效率接近实时处理

Hadoop迁移到Spark:
Spark提供多种运行模式,可以单独安装Spark框架运行,也可以通过On Yarn来把任务分发给Hadoop,可以解决历史遗留问题
2.Spark的编程
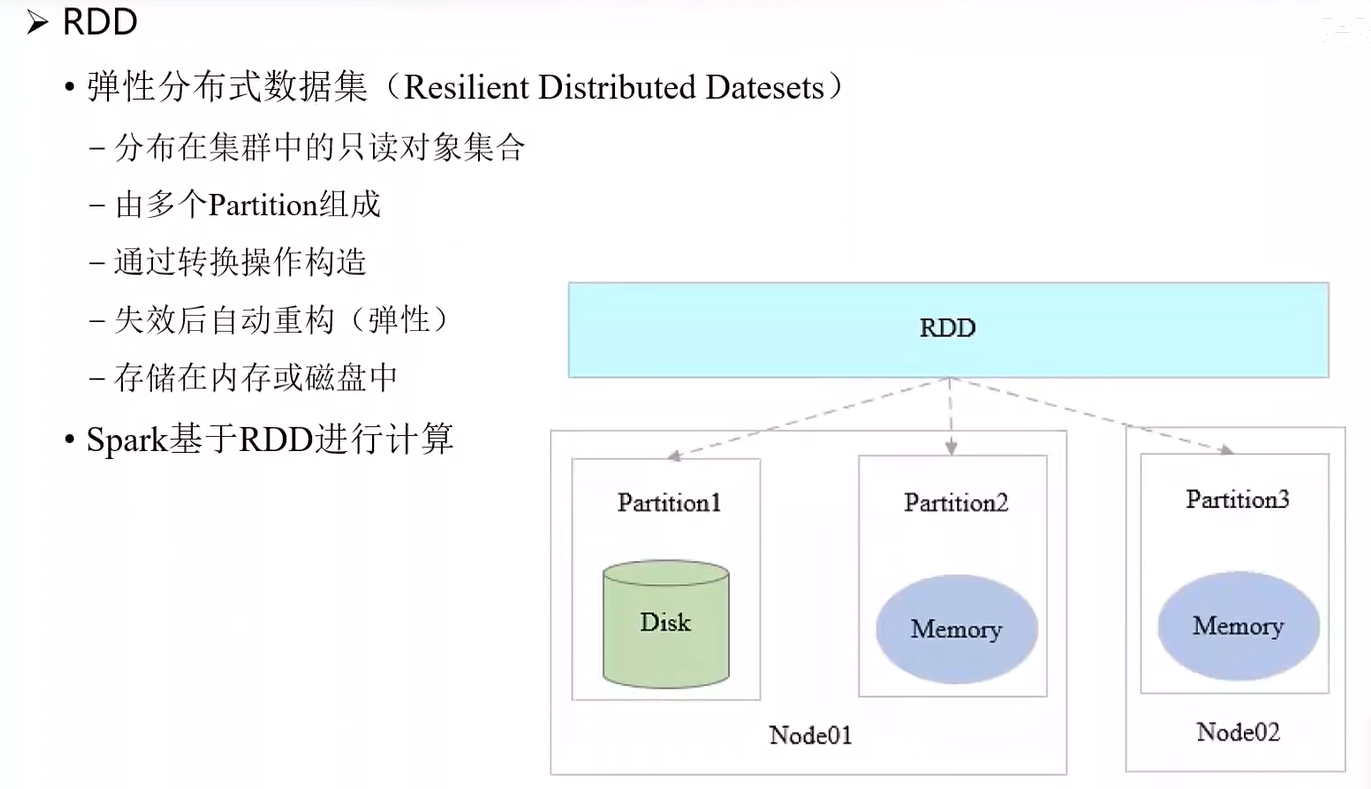
RDD:
Spark基于Rdd来运算
Rdd是只读的,如果要对Rdd进行处理,要把结果保存到新的Rdd中
当某个阶段出现错误,只需从上一个阶段进行数据的重新处理 结果就能恢复
Rdd的操作:
Rdd的操作分为两种分别为Transformation和Action
Transformation是在原有的RDD中发生转换,并没有真正的触发操作
Action是真正触发了结果的输出
如在rdd.map(_+1).saveAsTextFile("hdfs://node01:9000")中:
rdd.map(_+1)是Transformation
saveAsTextFile("hdfs://node01:9000")是Action

RDD之间的关系:
对RDD的操作会让两个RDD之间形成关系
如果是1对1的转换:窄依赖
如果是多对1的转换:宽依赖 数据恢复起来回到前面的节点会很慢
因此要避免使用宽依赖,避免使用它的算子(groupByKey reduceByKey sortByKey)
3.Spark集群
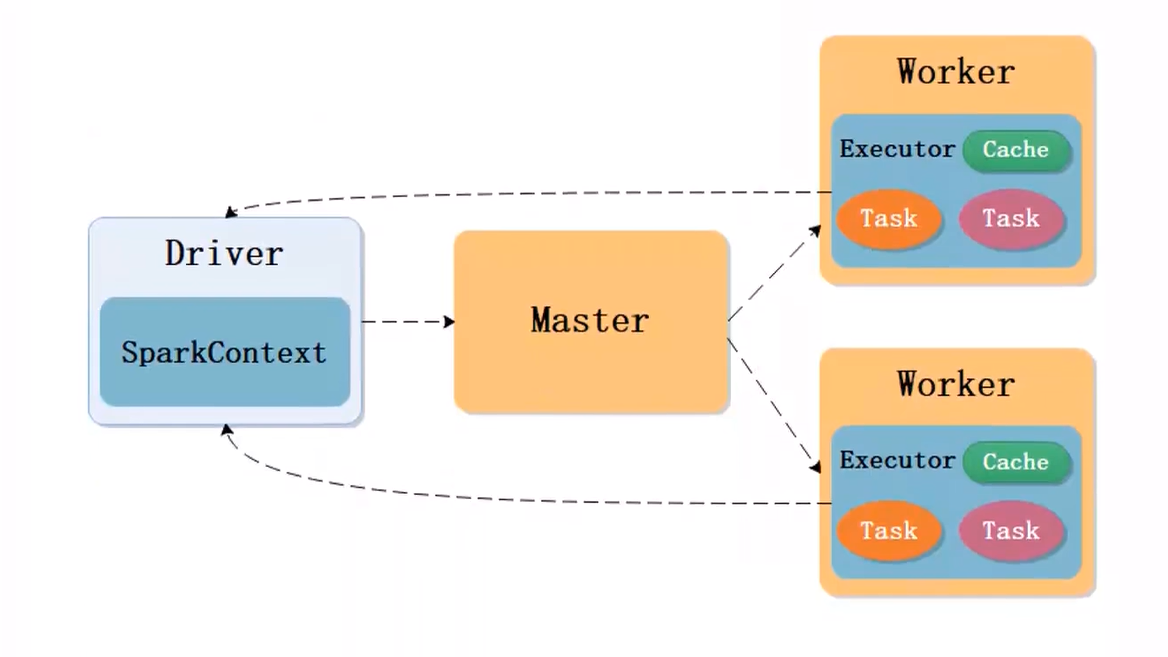
1.Driver 端
Driver 就是用户提交 Spark 应用的地方
SparkContext 是整个应用的入口,负责:
与集群的 Master 通信;
申请资源(Executor);
把 Job 拆分成 Task 并分配到各个 Worker 上执行;
收集执行结果返回给用户。
2.Master 端
Master 是资源调度的管理者。
Driver 启动后会向 Master 申请资源。
Master 负责把集群的空闲资源(CPU、内存)分配给 Driver 的应用使用。
简单来说,Master 不直接执行任务,只负责 协调资源。
3.Worker 端
Worker 是真正执行计算的节点。
Master 分配资源后,Worker 会启动 Executor(执行进程)。
一个 Executor 内部:
Task:Driver 下发的具体计算单元(比如 map、reduce、filter 等操作的子任务)。
Cache:RDD 的缓存结果存放在这里,可以加快后续任务的计算速度。
4.任务执行流程
1.用户在 Driver 程序中创建 SparkContext。
2.Driver 向 Master 注册并请求资源。
3.Master 在集群上选择可用的 Worker,并在 Worker 上启动 Executor 进程。
4.Driver 把任务(Task)分发到这些 Executor。
5.Executor 在 Worker 节点上并行执行 Task,必要时会把数据缓存到本地(Cache)。
6.执行结果会返回给 Driver,Driver 汇总后提供给用户。
4.Spark的运行模式
Local 模式
单机运行,通常用于测试
Spark 程序以多线程方式直接运行在本地
Standalone 模式
Spark 集群独立运行,不依赖第三方资源管理系统(如 YARN、Mesos)
采用 Master/Slave 架构
Driver 在 Worker 中运行,Master 只负责集群管理
ZooKeeper 负责 Master HA,避免单点故障
适用于集群规模不大、数据量不大的情况
YARN 模式
Spark 运行在 Hadoop YARN 之上,依赖 YARN 作为资源管理和调度系统
提供两种部署模式:
Client 模式:Driver 运行在提交任务的客户端上
Cluster 模式:Driver 运行在 YARN 的 NodeManager 上(更常用)
YARN 负责分配资源(CPU、内存),Spark 在 YARN 上启动 Executor
适用于企业大数据生产环境,能与 HDFS、Hive 等 Hadoop 生态紧密集成
缺点:依赖 Hadoop 环境,部署和配置相对复杂
Kubernetes 模式
Spark 运行在 Kubernetes 集群上,K8s 负责容器的调度和资源管理
Driver 和 Executor 都以 Pod 的形式运行在 Kubernetes 集群中
支持弹性伸缩和容器化部署,适合云原生场景
可以和云服务(如 AWS、GCP、阿里云)结合,方便大规模任务调度
缺点:需要熟悉 K8s,配置复杂度较高
Mesos 模式(现在较少使用)
Spark 运行在 Apache Mesos 之上,由 Mesos 负责资源管理
可以同时管理多种框架(Spark、Hadoop、Flink 等),共享资源池
适合多框架共存的环境
缺点:社区活跃度下降,实际使用越来越少