WebRTC音频QoS方法五(音频变速算法之Accelerate、FastAccelerate、PreemptiveExpand算法实现)
一、概述介绍
实时传输网络条件下,音频渲染过程中常常会出现音频数据堆积和断流现象。如果不采取有效的优化措施,这将导致音频的端到端延时加剧,甚至频繁出现断音现象,从而严重影响用户体验。因此,WebRTC在保证不严重失真情况下引入变速算法进行平滑。
1、累积数据过多时,通过Accelerate算法,不影响用户体验情况下,减少这些数据播放时长。
2、BUF数据不足时,通过Expand算法,增加数据播放时长。让用户感知不到音频数据的波动。
下面首先走读一下音频Accelerate、FastAccelerate、PreemptiveExpand算法实现。
二、加速算法
1、加速条件
因为Accelerate算法需要保证尽量不失真的平滑播放,所以不是所有送到Accelerate数据,都能进行Accelerate处理。
数据进行Accelerate处理需要满足如下条件:
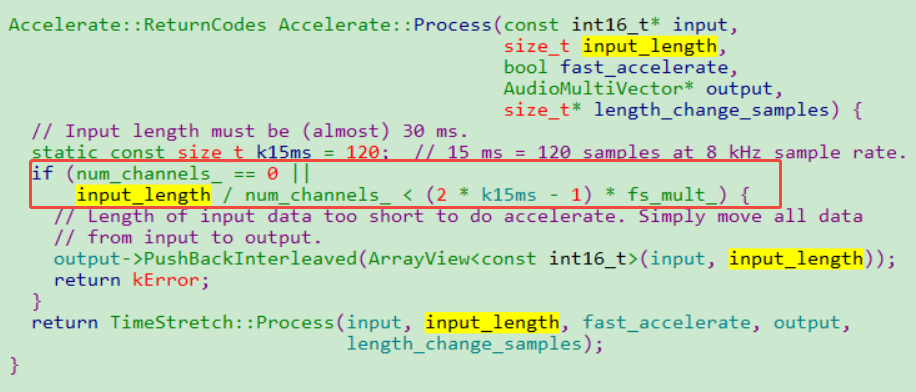
1、数组量要足够,算法限制数量量一定要大于30ms。
Accelerate::Process不会处理小于30ms的数据,直接把源PCM数据拷贝到输出buffer。
决策的时候,也会根据缓存数据量进行处理调整。
NetEqImpl::GetDecision

2、本段音频数据是非活动语音,或者有强相关性音频数据。
非活动语音很好是容易做加速的,非活动语音一般是背景噪音或者舒适噪音,没有信息。大面积剪切,都不会影响通话信息的传递。
相关性音频实际上比较的是波形相似程度。周期相同,波形完全一样的的音频,就是强相关音频,两个周期音频可以直接交叉叠加为一个周期,从而减少播放时长。
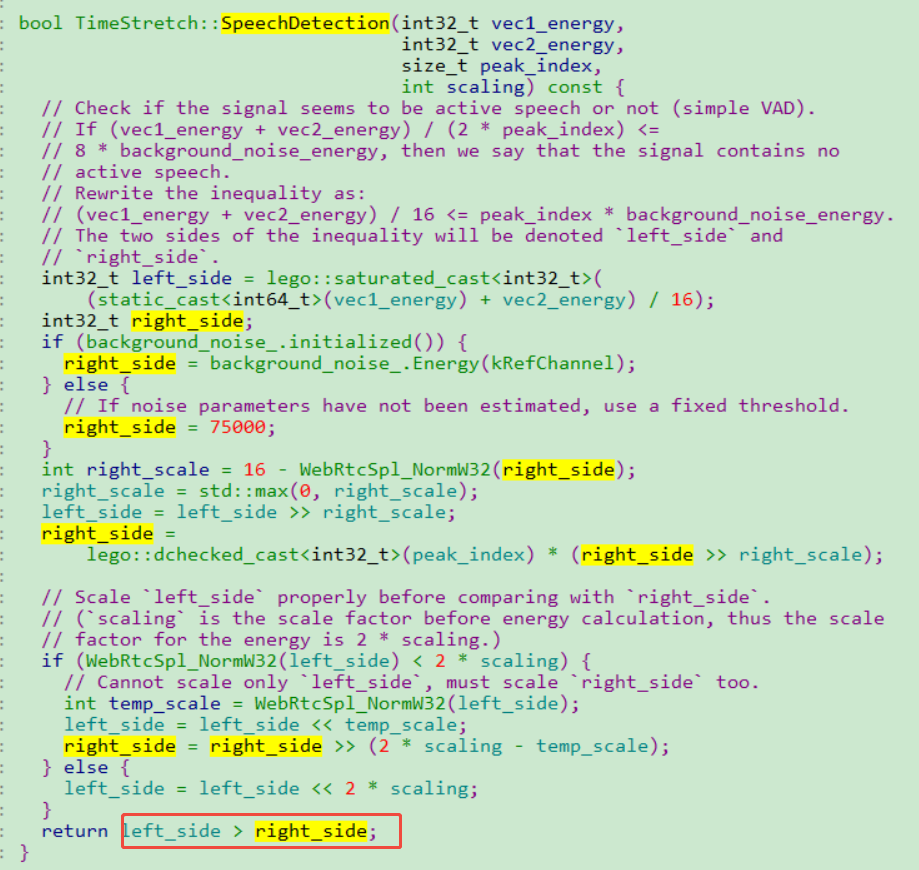
1)非活动语音判断
使用的VAD检测算法,判断当前音频数据的能量值是否小于噪音的能量值
输入信号还利用峰值索引位置,将音频数据信号截成两段。
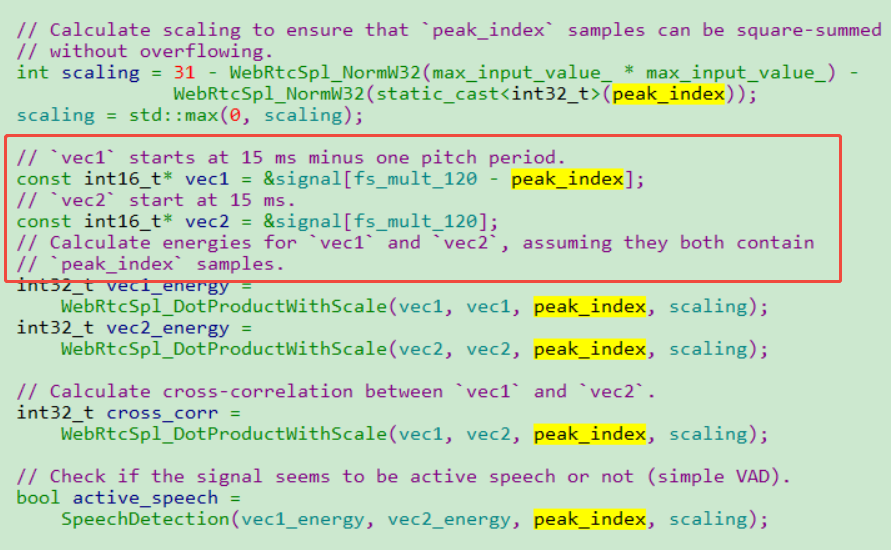
音频数据能量峰值索引的计算,使用的是抛物线拟合算法实现。该算法在离散采样的信号中能更精确地计算峰值的位置(peak_index)和峰值的幅度(peak_value),用于提升信号峰值检测的精度。
因为在数字信号处理中,信号的峰值往往不会恰好落在离散的采样点上,而是可能位于两个采样点之间。直接取采样点中的最大值会导致误差,而抛物线拟合通过对峰值附近的几个采样点拟合一条抛物线,利用抛物线的顶点来估计真实峰值的位置和幅度,从而提高精度。
详细实现细节在DspHelper::ParabolicFit函数。
void DspHelper::ParabolicFit(int16_t* signal_points,int fs_mult,size_t* peak_index,int16_t* peak_value) {uint16_t fit_index[13];if (fs_mult == 1) {fit_index[0] = 0;fit_index[1] = 8;fit_index[2] = 16;} else if (fs_mult == 2) {fit_index[0] = 0;fit_index[1] = 4;fit_index[2] = 8;fit_index[3] = 12;fit_index[4] = 16;} else if (fs_mult == 4) {fit_index[0] = 0;fit_index[1] = 2;fit_index[2] = 4;fit_index[3] = 6;fit_index[4] = 8;fit_index[5] = 10;fit_index[6] = 12;fit_index[7] = 14;fit_index[8] = 16;} else {fit_index[0] = 0;fit_index[1] = 1;fit_index[2] = 3;fit_index[3] = 4;fit_index[4] = 5;fit_index[5] = 7;fit_index[6] = 8;fit_index[7] = 9;fit_index[8] = 11;fit_index[9] = 12;fit_index[10] = 13;fit_index[11] = 15;fit_index[12] = 16;}// num = -3 * signal_points[0] + 4 * signal_points[1] - signal_points[2];// den = signal_points[0] - 2 * signal_points[1] + signal_points[2];int32_t num =(signal_points[0] * -3) + (signal_points[1] * 4) - signal_points[2];int32_t den = signal_points[0] + (signal_points[1] * -2) + signal_points[2];int32_t temp = num * 120;int flag = 1;int16_t stp = kParabolaCoefficients[fit_index[fs_mult]][0] -kParabolaCoefficients[fit_index[fs_mult - 1]][0];int16_t strt = (kParabolaCoefficients[fit_index[fs_mult]][0] +kParabolaCoefficients[fit_index[fs_mult - 1]][0]) /2;int16_t lmt;if (temp < -den * strt) {lmt = strt - stp;while (flag) {if ((flag == fs_mult) || (temp > -den * lmt)) {*peak_value =(den * kParabolaCoefficients[fit_index[fs_mult - flag]][1] +num * kParabolaCoefficients[fit_index[fs_mult - flag]][2] +signal_points[0] * 256) /256;*peak_index = *peak_index * 2 * fs_mult - flag;flag = 0;} else {flag++;lmt -= stp;}}} else if (temp > -den * (strt + stp)) {lmt = strt + 2 * stp;while (flag) {if ((flag == fs_mult) || (temp < -den * lmt)) {int32_t temp_term_1 =den * kParabolaCoefficients[fit_index[fs_mult + flag]][1];int32_t temp_term_2 =num * kParabolaCoefficients[fit_index[fs_mult + flag]][2];int32_t temp_term_3 = signal_points[0] * 256;*peak_value = (temp_term_1 + temp_term_2 + temp_term_3) / 256;*peak_index = *peak_index * 2 * fs_mult + flag;flag = 0;} else {flag++;lmt += stp;}}} else {*peak_value = signal_points[1];*peak_index = *peak_index * 2 * fs_mult;}
}2)数据相关性判断
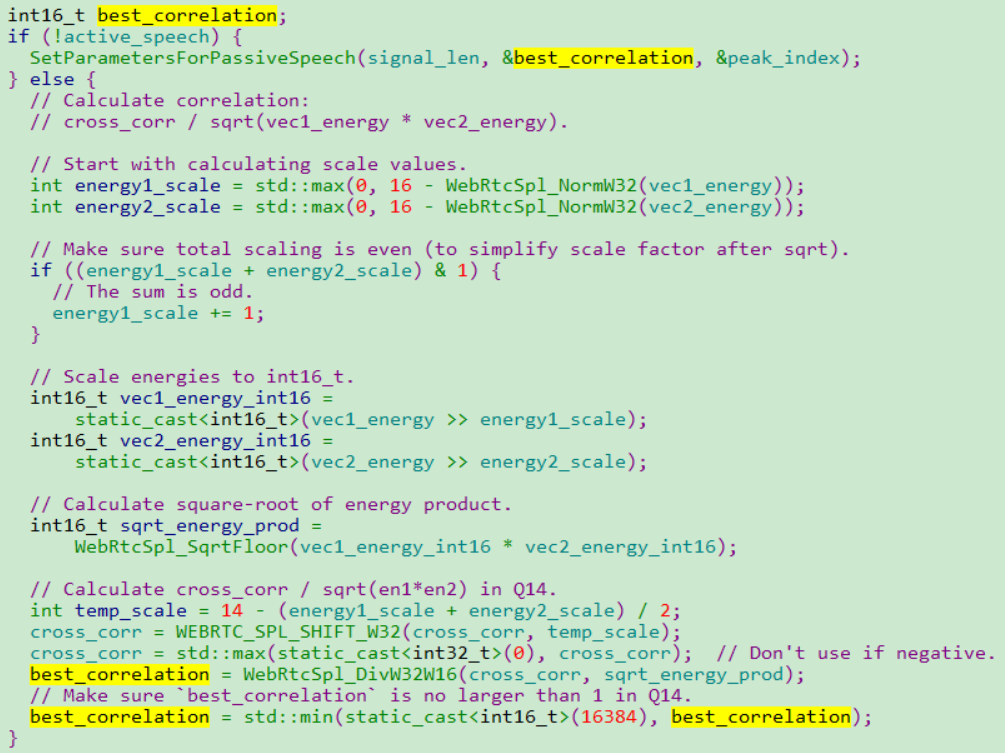
核心参数best_correlation:量化两个音频片段(vec1 和 vec2)的归一化相似程度,其计算原理基于归一化互相关(Normalized Cross-Correlation),目的是判断信号片段是否具有足够的周期性,以支持后续的时间拉伸(加速)操作。取值范围在 0~16384(Q14 定点数格式,16384 对应 1.0):
值越接近16384,两个片段越相似(周期性越强),越适合通过 “复制 - 重叠” 进行时间拉伸;
值越低,说明片段相似性差,强行拉伸可能导致失真。
在函数TimeStretch::Process
2、加速原理
1)加速算法详细操作流程
三段式音频构建:拷贝基础段 → 复制周期段 → 交叉淡入淡出 → 拷贝剩余段
核心函数:
Accelerate::ReturnCodes Accelerate::CheckCriteriaAndStretch(const int16_t* input,size_t input_length,size_t peak_index,int16_t best_correlation,bool active_speech,bool fast_mode,AudioMultiVector* output) const {// Check for strong correlation or passive speech.// Use 8192 (0.5 in Q14) in fast mode.const int correlation_threshold = fast_mode ? 8192 : kCorrelationThreshold;if ((best_correlation > correlation_threshold) || !active_speech) {// Do accelerate operation by overlap add.// Pre-calculate common multiplication with `fs_mult_`.// 120 corresponds to 15 ms.size_t fs_mult_120 = fs_mult_ * 120;if (fast_mode) {// Fit as many multiples of `peak_index` as possible in fs_mult_120.// TODO(henrik.lundin) Consider finding multiple correlation peaks and// pick the one with the longest correlation lag in this case.peak_index = (fs_mult_120 / peak_index) * peak_index;}RTC_DCHECK_GE(fs_mult_120, peak_index); // Should be handled in Process().// Copy first part; 0 to 15 ms.output->PushBackInterleaved(ArrayView<const int16_t>(input, fs_mult_120 * num_channels_));// Copy the `peak_index` starting at 15 ms to `temp_vector`.AudioMultiVector temp_vector(num_channels_);temp_vector.PushBackInterleaved(ArrayView<const int16_t>(&input[fs_mult_120 * num_channels_], peak_index * num_channels_));// Cross-fade `temp_vector` onto the end of `output`.output->CrossFade(temp_vector, peak_index);// Copy the last unmodified part, 15 ms + pitch period until the end.output->PushBackInterleaved(ArrayView<const int16_t>(&input[(fs_mult_120 + peak_index) * num_channels_],input_length - (fs_mult_120 + peak_index) * num_channels_));if (active_speech) {return kSuccess;} else {return kSuccessLowEnergy;}} else {// Accelerate not allowed. Simply move all data from decoded to outData.output->PushBackInterleaved(ArrayView<const int16_t>(input, input_length));return kNoStretch;}
}| 步骤 | 代码逻辑 | 操作目的 |
| 1、 | output->PushBackInterleaved(input, fs_mult_120 * num_channels_); | 拷贝0~15ms 的基础段到输出:作为加速音频的起始部分,确保开头无失真。 |
| 2、 | AudioMultiVector temp_vector(num_channels_); temp_vector.PushBackInterleaved(&input[fs_mult_120 * num_channels_], peak_index * num_channels_); | 提取15ms 后的一个完整基音周期:作为 “复制单元”,后续叠加到基础段末尾。 |
| 3、 | output->CrossFade(temp_vector, peak_index); | 交叉淡入淡出:将 temp_vector 与 output 末尾重叠拼接,消除拼接噪声。 |
| 4、 | output->PushBackInterleaved(&input[(fs_mult_120 + peak_index) * num_channels_], input_length - (fs_mult_120 + peak_index) * num_channels_); | 拷贝剩余音频段:15ms + 基音周期后的音频无需处理,直接拼接,完成加速。 |
2)交叉淡入淡出函数作用
void AudioVector::CrossFade(const AudioVector& append_this,size_t fade_length) {// Fade length cannot be longer than the current vector or `append_this`.RTC_DCHECK_LE(fade_length, Size());RTC_DCHECK_LE(fade_length, append_this.Size());fade_length = std::min(fade_length, Size());fade_length = std::min(fade_length, append_this.Size());size_t position = Size() - fade_length + begin_index_;// Cross fade the overlapping regions.// `alpha` is the mixing factor in Q14.// TODO(hlundin): Consider skipping +1 in the denominator to produce a// smoother cross-fade, in particular at the end of the fade.int alpha_step = 16384 / (static_cast<int>(fade_length) + 1);int alpha = 16384;for (size_t i = 0; i < fade_length; ++i) {alpha -= alpha_step;array_[(position + i) % capacity_] =(alpha * array_[(position + i) % capacity_] +(16384 - alpha) * append_this[i] + 8192) >>14;}RTC_DCHECK_GE(alpha, 0); // Verify that the slope was correct.// Append what is left of `append_this`.size_t samples_to_push_back = append_this.Size() - fade_length;if (samples_to_push_back > 0)PushBack(append_this, samples_to_push_back, fade_length);
}若直接拼接两个音频片段(基础段末尾 + 复制段开头)会因相位不连续产生 “点击噪声”(Click Noise),人耳对这种突变非常敏感。交叉淡入淡出通过 “重叠部分平滑过渡” 解决该问题:
重叠长度 = peak_index(即一个基音周期的长度);
过渡逻辑:output 末尾的采样点线性衰减(从 1→0),temp_vector 开头的采样点线性增益(从 0→1);
效果:两段音频无缝衔接,无明显噪声。
所以web RTC这种尽量不保证失真情况下的变速算法,能追回的时间长度完全取决与音频本身的内容,一个基音周期的时长。无法给出绝对量化的值。
kAccelerate和kFastAccelerate使用的是同一套加速算法,不同的是,判断音频相关性的阈值门槛不同。

fast_mode的相关性阈值是8192,普通是14746。并且也强制调整基音周期为15ms。
三、扩展算法
音频时间扩展(拉伸)算法,用于在保持语音音调不变的前提下增加音频时长(与之前分析的 TimeStretch 加速算法相反,后者是缩短时长)。其设计目的是应对实时语音通信中的网络抖动或缓冲不足,通过主动扩展音频来避免播放中断,同时保证听觉自然度。
音频扩展算法的本质是在不改变音调的情况下增加总时长。直接重复音频片段会导致明显的 “卡顿感”,而该算法通过复制语音的基音周期并平滑拼接实现扩展,核心原理与 “加速算法” 类似,但方向相反(加速是减少重复,扩展是增加重复)。
核心函数是PreemptiveExpand::CheckCriteriaAndStretch
PreemptiveExpand::ReturnCodes PreemptiveExpand::CheckCriteriaAndStretch(const int16_t* input,size_t input_length,size_t peak_index,int16_t best_correlation,bool active_speech,bool /*fast_mode*/,AudioMultiVector* output) const {// Pre-calculate common multiplication with `fs_mult_`.// 120 corresponds to 15 ms.size_t fs_mult_120 = static_cast<size_t>(fs_mult_ * 120);// Check for strong correlation (>0.9 in Q14) and at least 15 ms new data,// or passive speech.if (((best_correlation > kCorrelationThreshold) &&(old_data_length_per_channel_ <= fs_mult_120)) ||!active_speech) {// Do accelerate operation by overlap add.// Set length of the first part, not to be modified.size_t unmodified_length =std::max(old_data_length_per_channel_, fs_mult_120);// Copy first part, including cross-fade region.output->PushBackInterleaved(ArrayView<const int16_t>(input, (unmodified_length + peak_index) * num_channels_));// Copy the last `peak_index` samples up to 15 ms to `temp_vector`.AudioMultiVector temp_vector(num_channels_);temp_vector.PushBackInterleaved(ArrayView<const int16_t>(&input[(unmodified_length - peak_index) * num_channels_],peak_index * num_channels_));// Cross-fade `temp_vector` onto the end of `output`.output->CrossFade(temp_vector, peak_index);// Copy the last unmodified part, 15 ms + pitch period until the end.output->PushBackInterleaved(ArrayView<const int16_t>(&input[unmodified_length * num_channels_],input_length - unmodified_length * num_channels_));if (active_speech) {return kSuccess;} else {return kSuccessLowEnergy;}} else {// Accelerate not allowed. Simply move all data from decoded to outData.output->PushBackInterleaved(ArrayView<const int16_t>(input, input_length));return kNoStretch;}
}通过 “基础段保留 + 基音周期复制 + 交叉淡入淡出” 三步实现平滑扩展。
step1:确定不修改的基础段长度

unmodified_length 取 “旧数据长度” 和 “15ms” 的最大值,确保基础段包含足够的 “稳定语音帧”(15ms 是语音短时平稳性的典型帧长),作为扩展的基准。
step2:复制基础段到输出

将输入音频中 “基础段 + 一个基音周期长度” 的数据拷贝到输出,为后续插入扩展片段预留 “重叠区域”(长度为 peak_index,即基音周期)。
step3:提取待复制的基音周期片段

从基础段前一个基音周期的位置提取长度为 peak_index(一个基音周期)的片段,存入 temp_vector这是扩展的 “复制单元”,利用语音的周期性,该片段与基础段末尾的波形高度相似。
step4:交叉淡入淡出拼接,消除拼接噪声

将 temp_vector(复制的基音周期片段)与 output 末尾的重叠区域进行 “交叉淡入淡出”:
output 末尾的 peak_index 个采样点线性衰减(幅度从 1→0);
temp_vector 的 peak_index 个采样点线性增益(幅度从 0→1)。
目的:避免直接拼接导致的 “相位突变” 和 “点击噪声”,使扩展后的音频平滑过渡。
step5:复制剩余未修改的音频

将基础段之后的剩余音频拷贝到输出,完成整个扩展流程。
通过上述步骤,音频总时长会增加一个基音周期的长度(peak_index 个采样点),且因使用 “基音周期复制 + 平滑拼接”,实现了:
音调不变:复制的是完整基音周期,保留了声带振动的频率特征;
听感自然:交叉淡入淡出消除了拼接噪声,扩展部分与原始音频无缝融合;
实时性适配:仅对高相关性语音或非活动语音扩展,平衡质量与延迟。
同加速算法原理,一段音频能扩展的采样点与语音数据内容强相关。无法量化具体扩展长度。

四、关键算法
1、基音周期(Pitch Period)
语音信号中,声带振动产生的周期性(如男声基音周期约 80-120Hz,女声约 180-250Hz),是 “音调不变拉伸” 的核心 —— 复制基音周期可保证音调特征不变。
2、重叠相加(Overlap-Add, OLA)
数字信号处理中常用的信号合成技术,通过 “片段重叠 + 平滑过渡” 拼接信号,本函数的 CrossFade 是 OLA 的简化实现(线性淡入淡出)
3、抛物线拟合算法(ParabolicFit)
通过一个数学函数(抛物线方程)来“最佳吻合”一组离散数据点,从而找到最能代表这些数据的连续曲线的过程。主要方法包括基于几何距离的最小二乘法,该方法在迭代效率和精度之间取得平衡。